







通过激活引导提升语言模型的指令遵循能力:一篇 ICLR 2025 论文解读
引言
近年来,大型语言模型(Large Language Models, LLMs)的指令遵循(Instruction-Following)能力显著提升,使得它们在各种实际应用中表现出色。然而,如何让语言模型更精准地遵循用户指定的复杂指令,例如输出格式、长度限制或特定词汇的使用,仍然是一个挑战。2025 年将在 ICLR(International Conference on Learning Representations)上发表的论文《Improving Instruction-Following in Language Models through Activation Steering》提出了一种新颖的方法——激活引导(Activation Steering),通过直接干预模型的内部激活值来增强其指令遵循能力。本文将详细解读这篇论文的核心内容、方法、实验结果及其对语言模型控制的潜在影响。
Paper:https://arxiv.org/pdf/2410.12877
论文背景
语言模型的指令遵循能力通常通过指令微调(Instruction Tuning)来实现,这种方法通过在特定任务数据集上对模型进行进一步训练,使其能够更好地理解和执行用户指令。然而,指令的多样性和复杂性(例如要求输出为 JSON 格式、限定句子数量或避免使用特定词汇)使得传统微调方法在应对所有可能场景时显得不够灵活。此外,随着生成内容的增加,模型有时会出现“指令漂移”(Instruction Drift),即逐渐偏离初始指令。
为了解决这些问题,论文提出了一种基于机械解释(Mechanistic Interpretability)的激活引导方法,通过提取指令相关的向量表示(Steering Vectors),并在推理时直接干预模型的激活值,从而实现对模型输出的细粒度控制。这种方法无需对模型进行额外训练,是一种轻量且可扩展的解决方案。
核心方法:激活引导
什么是激活引导?
激活引导是一种通过直接修改语言模型在推理过程中的内部激活值(Activation Values)来控制其输出的技术。论文利用了“差异均值”(Difference-in-Means)方法,通过比较包含指令和不含指令的输入在模型残差流(Residual Stream)中的激活差异,提取出与特定指令相关的向量表示。这些向量随后被用来在推理时调整模型的激活值,引导模型生成符合指令的输出。
具体来说,激活引导的流程如下(见论文图 1):
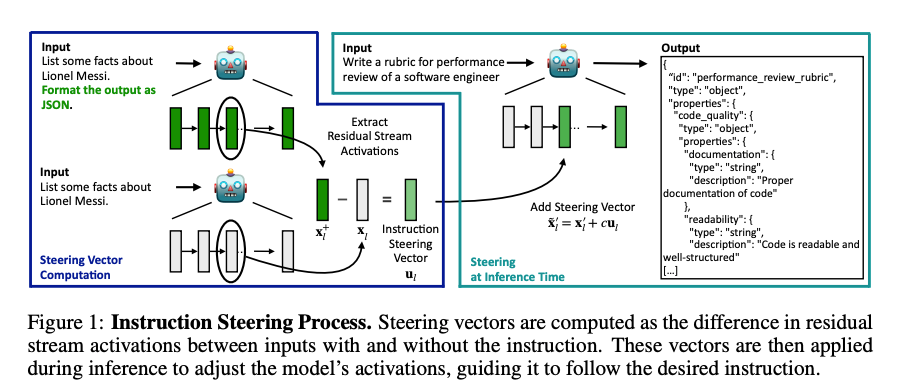
- 计算引导向量:对于一个基础查询(例如“列出关于梅西的一些事实”)和包含指令的查询(例如“以 JSON 格式列出关于梅西的一些事实”),计算两者在模型最后一个输入 token在第 l l l层 的残差流激活值的差异,得到一个引导向量。
- 应用引导向量:在推理过程中,将引导向量按一定权重( c c c)添加到模型的残差流激活值中,调整模型的生成行为。
- 层选择与权重调整:通过在验证集上进行层选择和权重调整,确保引导向量在提升指令遵循准确性的同时,尽量不影响输出质量。
指令类型
论文聚焦于三种具体的指令类型:
- 格式指令:控制输出的呈现方式,例如要求输出为 JSON 格式、用星号强调部分内容或全部小写。
- 长度指令:限制输出的长度,例如要求最多使用三句话或 300 字以上。
- 词汇指令:控制特定词汇的包含或排除,例如要求输出中包含某个关键词或避免使用某个词。
这些指令的特点是模块化、可组合,且与基础查询的内容无关,因此适合通过激活引导进行控制。
实验设计与结果
实验设置
论文使用了四种语言模型进行实验:
- Phi-3 Mini
- Gemma 2 2B 和 9B(指令微调版本和基础版本)
- Mistral 7B(指令微调版本)
实验数据基于 IFEval 数据集(Zhou et al., 2023a),包含 541 个提示,涵盖 25 种不同的指令。研究人员还生成了合成数据以避免测试信息泄露。评估指标包括指令遵循准确性(使用 IFEval 的“宽松”准确性评估脚本)和输出质量(通过 GPT-4o 生成的五道是/否问题进行评分)。
实验分为两种场景:
- 无显式指令:仅通过引导向量控制模型行为。
- 有显式指令:在输入中提供指令,并通过引导向量进一步增强指令遵循。
关键结果
1. 格式指令
- 无显式指令:当输入中不包含格式指令时,模型的指令遵循准确性通常较低(约 10%),但通过激活引导,准确性显著提升至约 30%。例如,Phi-3 在“全部小写”和“高亮文本”指令上的表现尤为突出(见图 3c)。

- 有显式指令:当输入中包含格式指令时,模型的基线准确性较高(60%-90%),但激活引导仍能进一步提升部分模型的性能,特别是在 Phi-3 和 Gemma 2 2B 上。
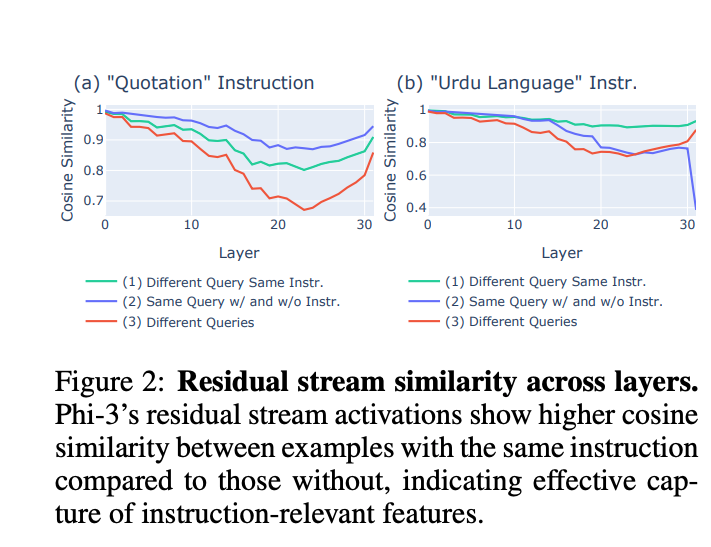
- 表示分析:通过余弦相似性分析,论文发现模型在最后一输入 token 的残差流激活中能有效捕获指令相关特征(见图 2 和图 13)。例如,“引号”指令和“乌尔都语”指令的激活表示显示出明显的区分性。
- 词汇投影:引导向量投影到词汇空间后,显示出与指令语义相关的 token(见表 1),验证了向量有效捕获了指令特征。

2. 长度指令
- 连续调制:通过调整引导向量的权重 c c c,可以控制输出的简洁或冗长程度。较大的 c c c 值使输出更简洁(见图 5a 和表 2)。例如,同一个电影剧情提示在不同权重下的输出从 15 句 324 词减少到 1 句 23 词。
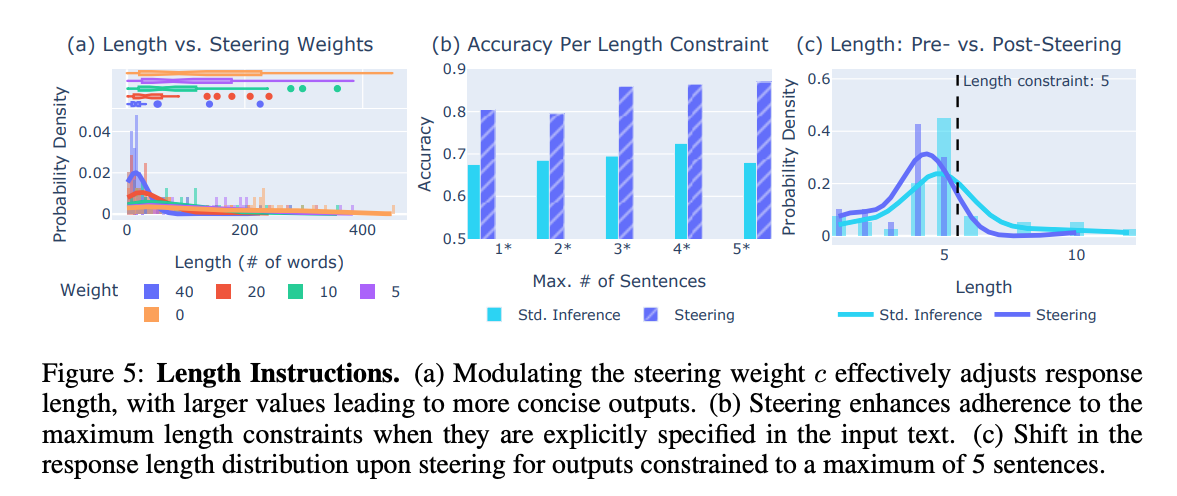
- 显式长度限制:当输入中包含明确的长度限制(如“最多 5 句话”)时,引导向量显著提高了模型遵循限制的准确性(见图 5b 和图 17b)。输出长度分布也更接近目标值(见图 5c 和图 17c)。
- 冗长输出:通过“冗长”引导向量,模型可以生成更长的输出(见图 17a),展示了激活引导在双向长度控制上的灵活性。
3. 词汇指令
- 词汇包含:通过为每个关键词生成特定的引导向量(仅需 20 个样本),模型在包含指定词汇的准确性上显著提高(见图 6a)。这些向量可以在推理时动态生成,显示了方法的高效性。

- 词汇排除:直接计算排除向量的效果不佳,因为投影到词汇空间时,排除词汇常被错误增强(见表 13)。论文提出通过减去包含向量来实现排除效果,显著提高了准确性(见图 19)。
- 质量影响:词汇指令的引导对输出质量的影响较小,质量评分变化通常在 -0.03 左右(见图 9b、9c 和图 10)。
4. 多指令引导
- 论文展示了同时引导多个指令的可行性,例如格式和长度指令的组合(见图 7a)或小写和词汇排除指令的组合(见图 7b)。通过在不同层注入多个引导向量,模型能够在多个约束上实现性能提升,尽管可能需要进一步优化以处理冲突指令。
5. 跨模型引导
- 论文发现,从指令微调模型计算的引导向量可以有效应用于基础模型(见图 8)。在 Gemma 2 2B 上,跨模型引导甚至优于同模型引导,表明指令微调模型的表示可以增强基础模型的指令遵循能力。这为跨模型的技能迁移提供了新可能性。

输出质量评估
- 质量评分:通过 GPT-4o 生成的五道是/否问题评估输出质量,论文发现激活引导通常对质量的影响较小,但在某些情况下(如格式指令)可能导致质量下降(见图 4 和图 9)。例如,Phi-3 在“全部大写”指令引导下可能生成重复 token(见表 12)。
- 权衡分析:在词汇排除任务中,论文分析了引导权重 c c c 对准确性和质量的权衡(见图 12)。更大的权重提高了准确性,但可能略微降低质量,表明需要仔细调整 c c c 值以平衡两者的表现。
方法的意义与局限性
意义
- 细粒度控制:激活引导提供了一种无需重新训练即可控制模型输出的方法,特别适用于复杂、模块化的指令。
- 高效性:引导向量计算成本低(例如词汇包含仅需 20 个样本),且可以在推理时动态生成。
- 可组合性:支持多指令同时引导,增强了方法的灵活性。
- 跨模型迁移:从指令微调模型提取的向量可以提升基础模型的性能,为模型间技能共享提供了新思路。
- 机械解释的实际应用:论文展示了如何将机械解释的洞察转化为实际的控制技术,为未来的研究奠定了基础。
局限性
- 指令漂移:尽管激活引导能缓解指令漂移,但在长生成中仍可能出现偏离。
- 质量下降:某些情况下,引导可能导致输出质量下降,例如生成重复 token 或轻微的事实错误(见表 12)。
- 冲突指令:多指令引导在处理冲突指令时可能需要进一步优化。
- 词汇排除的挑战:直接计算排除向量的效果不佳,需通过减去包含向量来间接实现。
结论与未来展望
这篇论文通过激活引导方法显著提升了语言模型的指令遵循能力,为实现更可控、可靠的语言生成提供了一种实用且可扩展的解决方案。其核心贡献在于:
- 展示了指令相关特征在模型激活空间中的线性表示。
- 验证了激活引导在格式、长度和词汇指令上的有效性。
- 证明了跨模型引导的可行性,拓展了任务迁移的可能性。
未来研究可以探索以下方向:
- 优化多指令引导以处理冲突情况。
- 改进引导权重和层的选择策略,以进一步减少质量下降。
- 扩展方法到更多类型的指令,例如语义或情感约束。
- 结合稀疏自编码器等技术,进一步提高表示提取的精度。
代码与数据
论文的代码和数据已提交为补充材料,并将在出版时开源,托管在 GitHub(https://github.com/microsoft/llm-steer-instruct)。这为研究人员复现实验或进一步开发提供了便利。
总结
《Improving Instruction-Following in Language Models through Activation Steering》是一篇具有开创性的工作,它将机械解释的理论洞察应用于实际的语言模型控制问题。通过激活引导,研究人员不仅提升了模型的指令遵循能力,还展示了跨模型迁移和多指令组合的潜力。这项技术为未来的语言模型应用提供了新的可能性,尤其是在需要细粒度控制的场景中。无论是研究人员还是开发者,这篇论文都值得深入阅读,以了解如何让语言模型更智能、更可控。
Steering Procedure”(引导程序)介绍
在论文《Improving Instruction-Following in Language Models through Activation Steering》中,2.2节“Steering Procedure”(引导程序)详细描述了如何通过激活引导(Activation Steering)来控制语言模型的输出,以增强其对特定指令的遵循能力。本节将深入剖析这一部分的原理,重点解析数学公式,并以通俗的语言解释其背后的思想和实现细节。
2.2 引导程序的原理
激活引导是一种在推理时直接干预语言模型内部激活值的技术,旨在通过修改模型的残差流(Residual Stream)激活值,引导模型生成符合特定指令的输出,而无需对模型进行重新训练或微调。其核心思想是:通过比较包含指令和不含指令的输入在模型内部激活值上的差异,提取一个与指令相关的“引导向量”(Steering Vector),然后在推理时将此向量加到模型的激活值上,以调整其生成行为。
该方法基于机械解释(Mechanistic Interpretability)的假设:语言模型在处理特定任务或指令时,会在激活空间中形成特定的线性表示(Linear Representations)。通过识别这些表示并进行干预,可以精确控制模型的行为。论文采用了一种名为“差异均值”(Difference-in-Means)的方法来提取引导向量,并通过调整权重和选择适当的层来优化引导效果。
以下是引导程序的三个主要步骤:
- 计算引导向量:通过比较包含指令和不含指令的输入的激活值差异,提取与指令相关的向量表示。
- 应用引导向量:在推理时,将引导向量按一定权重添加到模型的残差流激活值中,调整生成行为。
- 层选择与权重调整:通过实验确定最佳的干预层和权重,确保在提升指令遵循准确性的同时,尽量减少对输出质量的负面影响。
详细原理与数学公式解析
1. 计算引导向量
原理
引导向量的计算基于“差异均值”方法,其核心思想是通过对比两组输入在模型残差流中的激活值差异,提取与指令相关的特征表示。具体来说,对于一个基础查询(base query,例如“列出关于梅西的一些事实”)和包含指令的查询(例如“以 JSON 格式列出关于梅西的一些事实”),计算两者在模型最后一输入 token 的激活值差异。这种差异被认为主要反映了指令的影响,而非基础查询的内容。
数学公式
论文中定义了引导向量的计算方式如下:
设:
- x x x 表示基础查询(不含指令的输入)。
- x + x^+ x+ 表示包含指令的输入(即基础查询加上指令)。
- x i , l \mathbf{x}_{i,l} xi,l 和 x i , l + \mathbf{x}_{i,l}^+ xi,l+ 分别表示第 i i i 个样本在第 l l l 层( l ∈ { 1 , … , L } l \in \{1, \ldots, L\} l∈{1,…,L})最后一输入 token 的残差流激活值,维度为 d model d_{\text{model}} dmodel(模型的隐藏状态维度)。
- N N N 表示用于计算的样本对数量。
引导向量 u l \mathbf{u}_l ul 在第 l l l 层定义为:
u l = v l ∥ v l ∥ , where v l = 1 N ∑ i N ( x i , l + − x i , l ) . \mathbf{u}_l = \frac{\mathbf{v}_l}{\|\mathbf{v}_l\|}, \quad \text{where } \mathbf{v}_l = \frac{1}{N} \sum_i^N \left( \mathbf{x}_{i,l}^+ - \mathbf{x}_{i,l} \right). ul=∥vl∥vl,where vl=N1i∑N(xi,l+−xi,l).
公式解析:
- 差异计算: x i , l + − x i , l \mathbf{x}_{i,l}^+ - \mathbf{x}_{i,l} xi,l+−xi,l 表示包含指令的输入与不含指令的输入在第 l l l 层激活值的差异。这个差异向量捕获了指令对模型内部表示的影响。
- 均值计算:通过对 N N N 个样本对的差异求平均( 1 N ∑ i N \frac{1}{N} \sum_i^N N1∑iN),可以减少与特定基础查询相关的噪声,提取更通用的指令表示。
- 归一化:将平均差异向量 v l \mathbf{v}_l vl 归一化为单位向量 u l \mathbf{u}_l ul(通过除以其 L2 范数 ∥ v l ∥ \|\mathbf{v}_l\| ∥vl∥),确保引导向量的方向性,而不依赖于其幅度。
为什么选择最后一输入 token?
论文选择在最后一输入 token 的激活值上计算引导向量,基于以下原因:
- 最后一输入 token 的激活值通常包含了模型对整个输入序列的综合表示,尤其是在指令微调模型中,这通常对应于
<assistant>token,标志着模型从输入处理到生成输出的过渡。 - 研究表明(Todd et al., 2024; Scalena et al., 2024),最后一 token 的激活值不仅影响下一 token 的预测,还对整个生成过程有重要影响。
实现细节
- 样本选择:论文使用 IFEval 数据集中的基础查询,并通过合成方式生成包含指令的查询(见附录 C 和 D),以确保样本的多样性并避免测试信息泄露。
- 样本数量:对于词汇包含指令,仅需 20 个样本即可生成有效的引导向量,显示了方法的高效性。
2. 应用引导向量
原理
在推理时,引导向量被添加到模型的残差流激活值中,以调整生成行为。具体来说,模型在处理新输入时,会在特定层(由层选择过程确定)将引导向量按一定权重 c c c 加入到残差流中,从而引导模型生成符合指令的输出。
数学公式
设:
- x l ′ \mathbf{x}_l^\prime xl′ 表示新输入在第 l l l 层的残差流激活值。
- u l \mathbf{u}_l ul 为第 l l l 层的归一化引导向量。
- c ∈ R c \in \mathbb{R} c∈R 为引导权重,用于控制干预的强度。
- x ^ l ′ \hat{\mathbf{x}}_l^\prime x^l′ 为调整后的激活值。
调整后的激活值计算公式为:
x ^ l ′ = x l ′ + c u l . \hat{\mathbf{x}}_l^\prime = \mathbf{x}_l^\prime + c \mathbf{u}_l. x^l′=xl′+cul.
公式解析:
- 激活值调整:通过将引导向量 c u l c \mathbf{u}_l cul 加入到原始激活值 x l ′ \mathbf{x}_l^\prime xl′ 中,模型的内部表示被推向与指令相关的方向,从而影响后续的生成过程。
- 权重 c c c 的作用:权重 c c c 控制引导的强度。较大的 c c c 值会更强烈地推动模型遵循指令,但可能增加输出质量下降的风险(如生成重复 token 或不连贯内容)。
- 单层干预:论文选择在单一层进行干预(而非多层),因为研究表明(Li et al., 2024),模型在生成长序列时容易偏离指令,单层干预可以有效纠正这种偏差。
权重 c c c 的选择
权重 c c c 的选择根据指令类型有所不同:
- 格式指令:采用系统性调整方法,计算 c c c 以使调整后的激活值接近包含指令输入的平均激活值。具体公式为:
c = z ˉ − x l ′ T u l , where z ˉ = 1 N ∑ i N x i , l + T u l . c = \bar{z} - \mathbf{x}_l^{\prime \mathrm{T}} \mathbf{u}_l, \quad \text{where } \bar{z} = \frac{1}{N} \sum_i^N \mathbf{x}_{i,l}^{+\mathrm{T}} \mathbf{u}_l. c=zˉ−xl′Tul,where zˉ=N1i∑Nxi,l+Tul.
-
公式解析:
- x l ′ T u l \mathbf{x}_l^{\prime \mathrm{T}} \mathbf{u}_l xl′Tul 表示新输入激活值在引导向量方向上的投影,反映了当前激活值与指令方向的接近程度。
- z ˉ \bar{z} zˉ 是包含指令的输入激活值在引导向量方向上的平均投影,代表目标指令的“理想”激活状态。
- c c c 的计算确保调整后的激活值 x ^ l ′ \hat{\mathbf{x}}_l^\prime x^l′ 在引导向量方向上的投影接近 z ˉ \bar{z} zˉ,从而动态适应新输入,避免过强或过弱的干预。
-
长度指令:由于长度指令具有连续性(例如要求不同句子数量),论文通过实验测试不同 c c c 值的影响。例如,较大的 c c c 值使输出更简洁(见图 5a 和表 2)。
-
词汇指令:除了使用公式 (2) 计算 c c c,还通过在验证集上进行小范围网格搜索(Grid Search)微调权重,以优化引导效果。
干预位置
- 单层干预:引导向量在所有 token 位置的同一层(第 l l l 层)上添加,基于研究表明模型在生成过程中可能逐渐偏离指令(Li et al., 2024)。
- 干预时机:干预在推理的每次前向传播中进行,调整后的激活值 x ^ l ′ \hat{\mathbf{x}}_l^\prime x^l′ 用于后续的计算。
3. 层选择与权重调整
原理
不同的模型层可能对指令的表示和处理有不同的贡献,因此选择合适的干预层至关重要。此外,引导权重 c c c 的选择需要平衡指令遵循准确性和输出质量。论文通过在验证集上进行层选择和权重调整,确保干预效果最佳。
实现细节
-
层选择:
- 在模型的部分层上进行扫描(Layer Sweep),评估每层的引导效果。
- 使用验证集计算指令遵循准确性,并通过一个较小的模型(GPT-2)计算输出的困惑度(Perplexity)作为质量代理。
- 选择满足以下条件的层:
- 指令遵循准确性高于无引导的基线。
- 低困惑度输出的比例为零(即避免生成不连贯或重复内容)。
- 如果多个层具有相同的最高准确性,选择最早的层(以减少对后续计算的干扰)。
- 如果没有层能提升基线准确性,则不进行引导(见表 8 和表 9 中的“-”)。
-
权重调整:
- 对于格式指令,使用公式 (2) 动态计算 c c c。
- 对于长度指令,手动调整 c c c 值以探索不同程度的简洁或冗长(见图 5a)。
- 对于词汇指令,通过网格搜索在公式 (2) 计算的 c c c 值附近微调,以优化效果。
- 困惑度阈值(Perplexity Threshold)用于筛选权重配置,格式指令设为 2.5,词汇指令设为 4,以确保输出质量。
结果展示
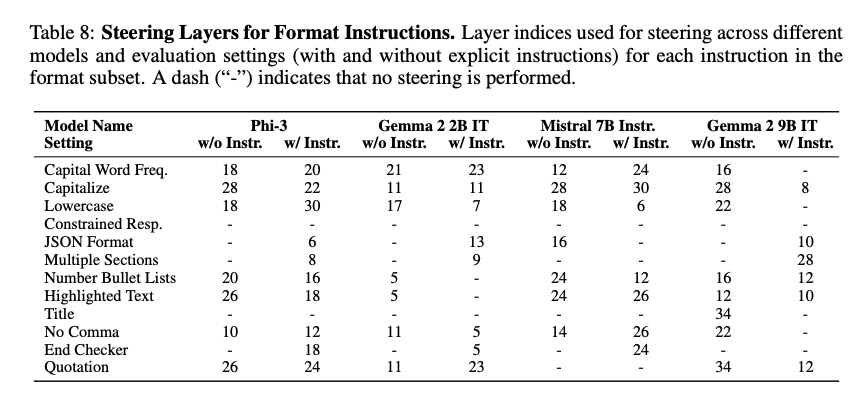
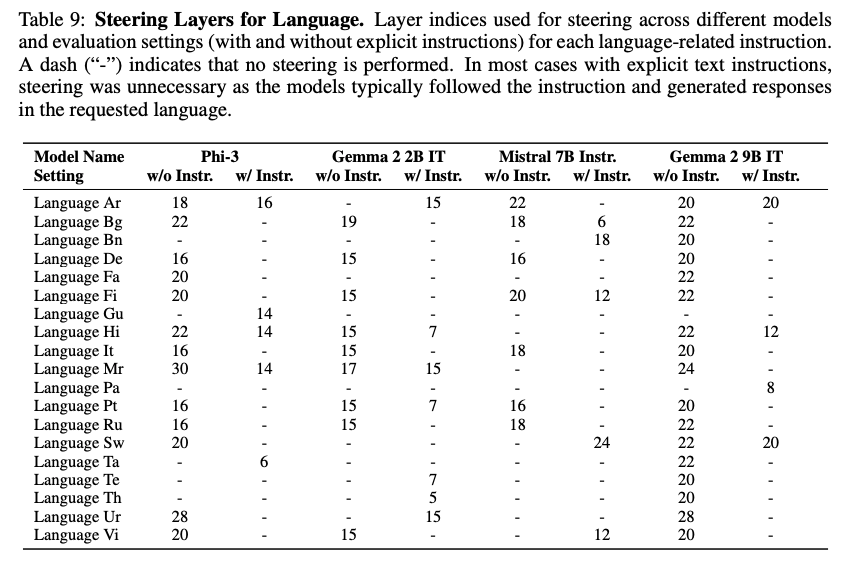
- 层选择结果:表 8 和表 9 列出了不同模型和指令的最佳干预层。例如,Phi-3 在“全部小写”指令上选择第 28 层(无显式指令时),而在“JSON 格式”指令上可能不进行引导(因为基线已表现良好)。
- 困惑度检查:图 16 展示了层选择过程中的准确性和困惑度权衡。例如,在“多段落”指令上,困惑度检查避免了选择导致质量下降的层。
通俗解释
类比
可以将激活引导想象成在开车时调整方向盘:
- 引导向量( u l \mathbf{u}_l ul)就像方向盘的调整方向,告诉模型“向这个方向走”以遵循指令。
- 权重 c c c 是你转动方向盘的力度,力度太大可能导致“翻车”(输出质量下降),力度太小则可能无法改变方向。
- 层选择 类似于选择在哪个路段调整方向,不同的路段(层)对最终路线(输出)的贡献不同。
- 差异均值方法 就像通过对比两条路线(有无指令的输入)的差异,找到正确的调整方向。
为什么有效?
- 线性表示假设:语言模型的激活空间中,指令相关信息以线性方向编码(Mikolov et al., 2013; Elhage et al., 2021)。差异均值方法通过提取这些方向,隔离了指令的影响。
- 动态调整:公式 (2) 确保引导向量适应新输入的激活状态,避免过强或过弱的干预。
- 高效性:只需少量样本(例如 20 个)即可计算引导向量,且无需修改模型权重,计算成本低。
实际应用
- 格式指令:例如,要求输出为 JSON 格式时,引导向量可以增强模型生成正确格式的能力,即使输入中没有明确指令。
- 长度指令:通过调整 c c c 值,模型可以生成更短或更长的输出,满足不同长度需求。
- 词汇指令:通过动态生成词汇包含向量,模型可以精确地在输出中加入或避免特定词汇。
总结
2.2节的引导程序提供了一种高效、可扩展的方法,通过直接干预语言模型的残差流激活值,增强其对格式、长度和词汇指令的遵循能力。其核心数学公式(公式 1 和 2)基于差异均值方法,提取指令相关表示并动态调整干预强度。通过仔细的层选择和权重调整,方法在提升准确性的同时尽量减少质量下降。以下是关键点的总结:
- 引导向量计算:通过 u l = v l ∥ v l ∥ \mathbf{u}_l = \frac{\mathbf{v}_l}{\|\mathbf{v}_l\|} ul=∥vl∥vl 和 v l = 1 N ∑ i N ( x i , l + − x i , l ) \mathbf{v}_l = \frac{1}{N} \sum_i^N \left( \mathbf{x}_{i,l}^+ - \mathbf{x}_{i,l} \right) vl=N1∑iN(xi,l+−xi,l),提取指令的线性表示。
- 激活值调整:通过 x ^ l ′ = x l ′ + c u l \hat{\mathbf{x}}_l^\prime = \mathbf{x}_l^\prime + c \mathbf{u}_l x^l′=xl′+cul,在推理时引导模型行为。
- 权重动态调整:使用 c = z ˉ − x l ′ T u l c = \bar{z} - \mathbf{x}_l^{\prime \mathrm{T}} \mathbf{u}_l c=zˉ−xl′Tul 确保干预适应新输入。
- 层选择:通过验证集上的准确性和困惑度检查,选择最佳干预层。
这一方法展示了机械解释在实际应用中的潜力,为语言模型的细粒度控制提供了新的可能性。未来可以进一步优化权重调整策略和处理冲突指令的能力,以提升方法的鲁棒性和适用性。
后记
2025年5月28日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









