







Liu H, Wang R, Shan S, et al. Deep Supervised Hashing for Fast Image Retrieval[C]. IEEE Conference on Computer Vision & Pattern Recognition. 2016.
论文概要:基于深度学习的图像检索
目录
哈希学习:
第一步,
先对原空间的样本采用度量学习(metric learning)进行降维,得到1个低维空间的实数向量表示;
度量学习阶段首先得构建学习模型,然后对模型的参数进行优化和学习。
第二步,
对得到的实数向量进行量化(即离散化)得到二进制哈希码。
在最初的工作中,作者提出在特征空间中随机选择一些超平面对空间进行划分,根据样本点落在超平面的哪一侧来决定每个bit的取值。这类方法虽然有严格的理论证明保证其效果,但是在实际操作中通常需要比较多的bit才能得到令人满意的检索效果。
在之后的工作中,为了得到编码长度更短、检索效果更好的二值码,人们进行了很多尝试,包括构建不同的目标函数、采用不同的优化方法、利用图像的标签信息、使用非线性模型等。随着研究的深入,利用二值编码进行检索的性能也逐步提升。
DSH(Deep Supervised Hashing)
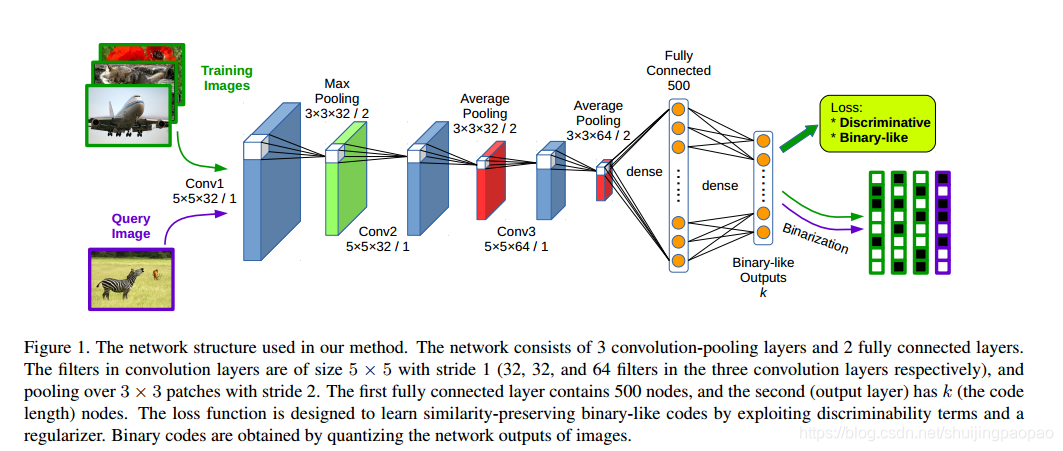
网络结构:
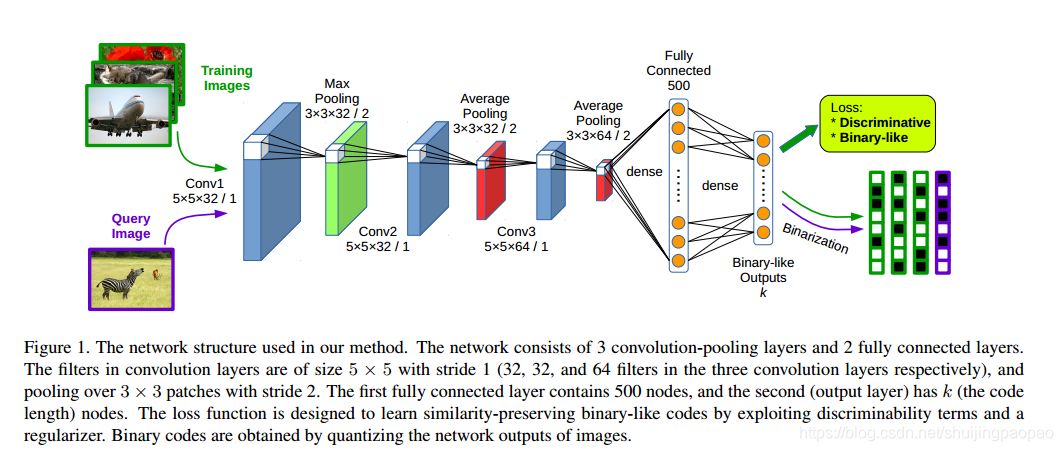
输入:
pairs of images (similar/dissimilar) as training inputs
通过设计损失函数,使得最后一层的输出Binary-like:
损失函数:
每对图片的(得到的hashcode为b1\b2,k维的±1向量,D(*)为hamming distance;两张图片相似y=1,否则为0):
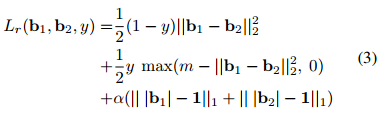
整个训练集的:
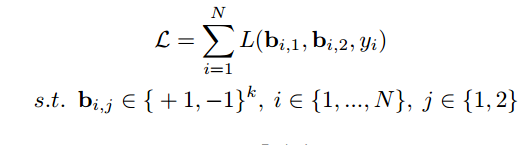
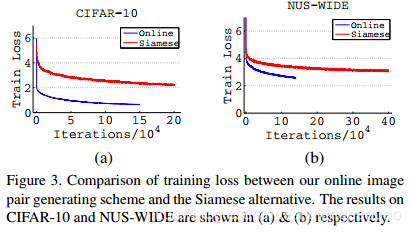
训练集:
CIFAR-10、NUS-WIDE
Loss图像:
一些问题及解答
1、如何通过深度学习获得hash code?
通过深度学习网络提取图像特征,将特征降维,然后二值化得到hash code
2、如何进行反馈学习的?
二值化得到hash code之后通过loss函数进行反馈学习。
e.g. 论文算法中的loss函数:
每对图片的(得到的hashcode为b1\b2,k维的±1向量,D(*)为hamming distance;两张图片相似y=1,否则为0):
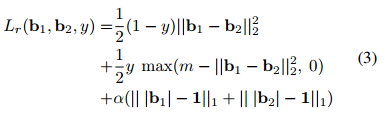
整个训练集的:
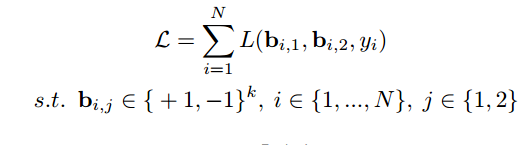
3、deep hash的过程简述:
深度学习提取特征——hash变换(实质为二值化的过程)——输出给loss函数监督学习
4、deep hash是如何实现两张图像输入的,如何控制两张图像都走完再修正参数(是否是两个图像的差得到y)
参考链接 http://blog.csdn.net/u012938704/article/details/60776220
if (sim) { // similar pairs
loss += dist_sq;
// gradient with respect to the first sample
caffe_cpu_axpby(
channels,
alpha,
diff_.cpu_data(),
Dtype(1.0),
bout + (i*channels));//计算损失函数对输入向量i的梯度
// gradient with respect to the second sample
caffe_cpu_axpby(
channels,
-alpha,
diff_.cpu_data(),
Dtype(1.0),
bout + (j*channels));//计算损失函数对输入向量j的梯度
}
else { // dissimilar pairs
loss += std::max(margin - dist_sq, Dtype(0.0));
if ((margin-dist_sq) > Dtype(0.0)) {
// gradient with respect to the first sample
caffe_cpu_axpby(
channels,
-alpha,
diff_.cpu_data(),
Dtype(1.0),
bout + (i*channels));//计算损失函数对输入向量i的梯度
// gradient with respect to the second sample
caffe_cpu_axpby(
channels,
alpha,
diff_.cpu_data(),
Dtype(1.0),
bout + (j*channels));//计算损失函数对输入向量j的梯度
}
如上述代码所述,分为两张输入图像相似与不相似的情况来简化代码,之后再进行正则化计算出整个loss。
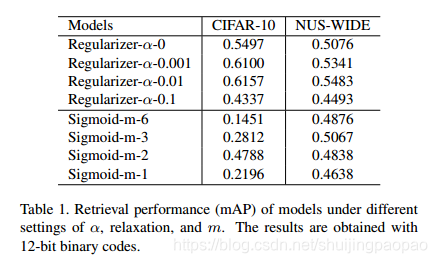
5、文章算法loss与sigmoid相比的优势
文章算法比sigmoid的方法快,同时在最后的效果上也比sigmoid好(如下图所示,文章算法的mAP比sigmoid的好)
快的原因:sigmoid是饱和非线性的,这种总非线性会降低网络的收敛速度(with such non-linear would inevitably slow down or even restrain the convergence of the network)

















 3903
3903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









