






前言
YOLO10都出来为什么还要写这篇YOLO8? 首先YOLO8作为ultralytics出品的里程碑检测网络(不局限于目标检测)有必要对其深入挖掘,其次网络作者的PK数据基本基于通用的大数据集,但当在使用者自己的应用场景数据集中其实未见的新网络会更好(例如这篇paper:Precision and Adaptability of YOLOv5 and YOLOv8 in Dynamic Robotic Environments 作者研究对YOLOv5和YOLOv8模型进行了比较分析,挑战了后者在性能指标方面优越性的普遍假设。与最初的预期相反,YOLOv5模型在物体检测任务中表现出了可比性,在某些情况下甚至更高的精度。)
整个YOLO网络发展史基本从以下3点做出改进,网络结构、loss、训练方法,本文也将从这3点进行阐述;
网络结构
整个yolo8结构可参考:YOLO8总体结构图
但图中的head结构与我看的代码中的结构略有差异,具体可以参考后面的head流程图。
网络结构中的block_n这里简述为块n。
块0(ConvModule):stem,重复1次,输出P1, 降2倍
卷积模块ConvModule(pytorch的conv2d+bn+silu),卷积k=3,s=2;卷积块默认不带偏置;
卷积s=2,所以输出map分辨率下降2倍。
stage1:块1+块2
块1(ConvModule):重复1次,输出P2, 降2倍(在此已降4倍)
卷积模块ConvModule(pytorch的conv2d+bn+silu),卷积k=3,s=2;卷积块默认不带偏置;
卷积s=2,所以输出map分辨率下降2倍,输出通道数Cout=128*width。
块2:重复3*depth次Bottleneck(有shortcut),输出hwc等于块的输入;
与YOLO5相比这里每个Bottleneck的输出能跳接到模块最后输出,丰富了特征输出;结构如下图: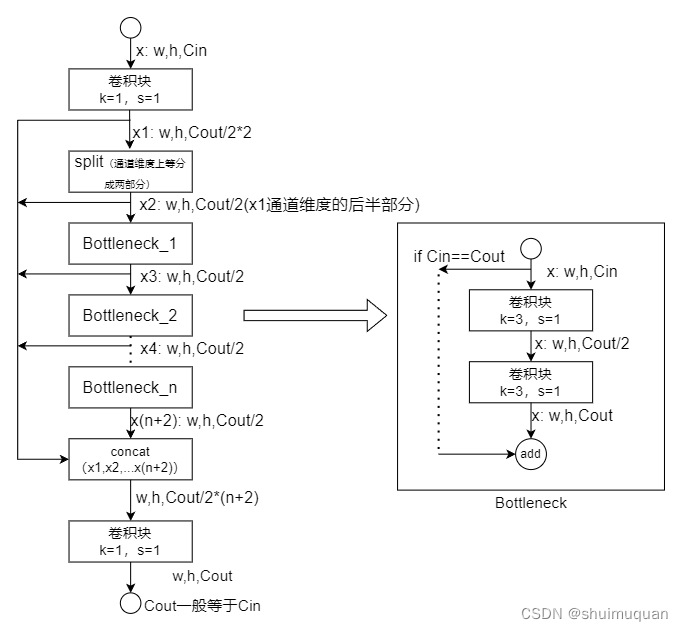
stage2:块3+块4
块3(ConvModule):重复1次,输出P3, 降2倍(在此已降8倍)
卷积模块ConvModule(pytorch的conv2d+bn+silu),卷积k=3,s=2;卷积块默认不带偏置;
卷积s=2,所以输出map分辨率下降2倍,输出通道数Cout=256*width。
块4:重复6*depth次Bottleneck(有shortcut),输出hwc等于块的输入
结构与块2所示流程图一致。
stage3:块5+块6
块5(ConvModule):重复1次,输出P4, 降2倍(在此已降16倍)
卷积模块ConvModule(pytorch的conv2d+bn+silu),卷积k=3,s=2;卷积块默认不带偏置;
卷积s=2,所以输出map分辨率下降2倍,输出通道数Cout=512*width。
块6:重复6*depth次Bottleneck(有shortcut),输出hwc等于块的输入
结构与块2所示流程图一致。
stage4:块7+块8+块9(SPPF)
块7(ConvModule):重复1次,输出P5, 降2倍(在此已降32倍)
卷积模块ConvModule(pytorch的conv2d+bn+silu),卷积k=3,s=2;卷积块默认不带偏置;
卷积s=2,所以输出map分辨率下降2倍,输出通道数Cout=1024*width。
块8:重复3*depth次Bottleneck(有shortcut),输出hwc等于块的输入
结构与块2所示流程图一致。
块9(SPPF,Spatial Pyramid Pooling,SPP的改良版,快速空间金字塔池化):
卷积块通道减半,串行3个55的maxpooling,concat这个4个中间结果,再卷积块,通道为指定输出的通道数(一般等于输入)。
SPPF在yolo5后期版本就已经有了,作用是实现局部特征和全局特征的featherMap级别的融合。3个size=55的串行池化,效果与SPP的55,99,13*13这3个size并行池化一致,但速度更快;
结构图如下:
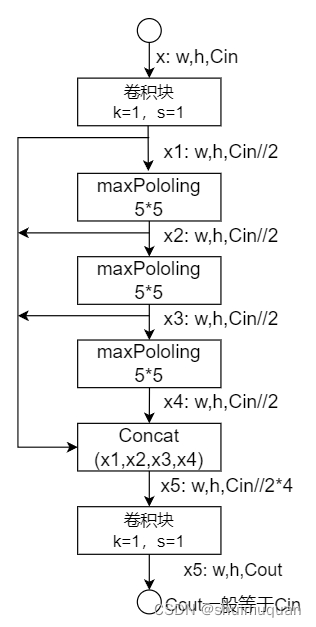
以上就是整个backbone
以下就是目标检测的neck
与yolo5一样采用PAFAN结构,相比FPN,提出自底向上路径增强,用低层精确定位信号增强整个特征金字塔,缩短从底层到顶层的信息路径:
PAFAN大致结构可以参考:PAFAN
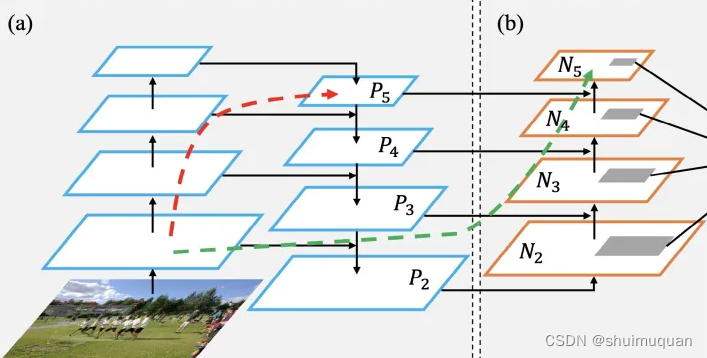
先往上融合
块10:Upsample,2倍的上采样;(分辨率1/16)
块11:Concat,块10与块6的输出在通道维度上链接(concat);
块12:C2f(结构与块2所示流程图一致),bottleneck不做shortcut;
——————
块13:Upsample,2倍的上采样;(分辨率1/8)
块14:Concat,块13与块4通道维度上链接(concat);
块15:C2f(结构与块2所示流程图一致),bottleneck不做shortcut,输出通道数Cout=256width;
输出给head
再往下融合
块16:(ConvModule):重复1次, 降2倍(分辨率1/16)
卷积模块ConvModule(pytorch的conv2d+bn+silu),卷积k=3,s=2;卷积块默认不带偏置;
卷积s=2,所以输出map分辨率下降2倍,输出通道数Cout=256width。
块17:Concat,块16与块12的输出在通道维度上链接(concat);
块18:C2f(结构与块2所示流程图一致),bottleneck不做shortcut, 输出通道数Cout=512*width;
输出给head
——————
块19:(ConvModule):重复1次, 降2倍(分辨率1/32)
卷积模块ConvModule(pytorch的conv2d+bn+silu),卷积k=3,s=2;卷积块默认不带偏置;
卷积s=2,所以输出map分辨率下降2倍,输出通道数Cout=512width。
块20:Concat,块19与块9的输出在通道维度上链接(concat);
块21:C2f(结构与块2所示流程图一致),bottleneck不做shortcut, 输出通道数Cout=1024width;
输出给head
以上就是目标检测的neck
以下就是检测头head,分类与定位回归解耦(yolo5没解耦,yolo6开始解耦)
解耦优点:
1.更精确的定位:分类和回归使用不同的网络,可以单独优化回归损失,更容易学习到准确的定位信息;
2.更丰富的表征:分类和回归使用不同的网络,可以学习到更丰富的特征表征,有利于检测;
head结构如下:
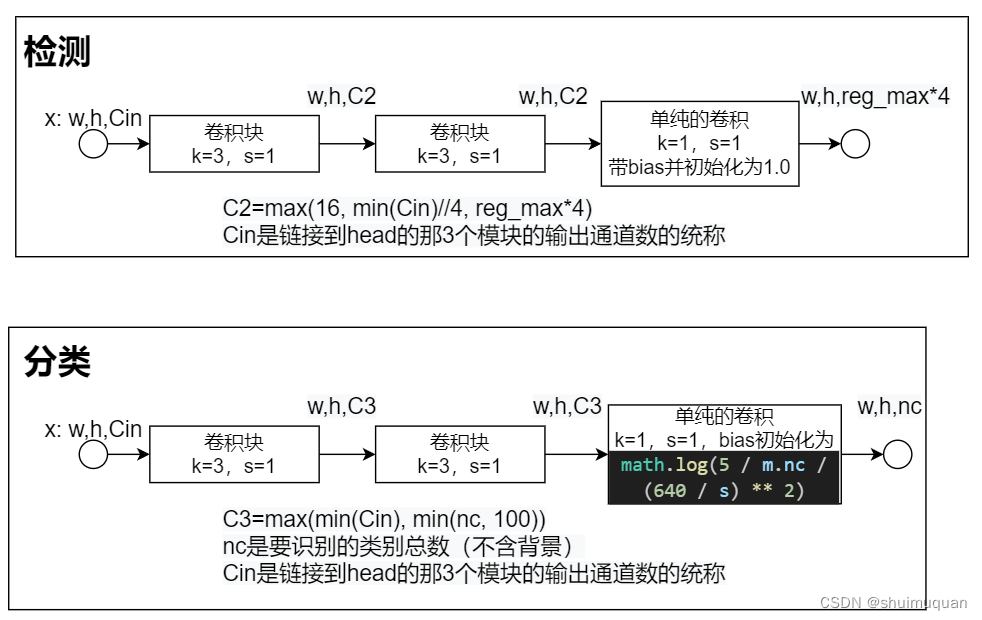
网络的3个head对应输出pred=3个tensor:[tensor1,tensor2,tensor3】
tensor1:[b, reg_max4+nc, h1, w1] (回归与分类的输出在第1为concat)
tensor2:[b, reg_max4+nc, h1/2, w1/2]
tensor3:[b, reg_max*4+nc, h1/4, w1/4]
计算损失
接下来如果是训练模式则进入计算损失:
1.将pred拆为pred_score:[b, reg_max4, hw]和pred_distri:[b, nc, hw],其中hw= h1w1+h1/2w1/2+h1/4w1/4;
2.获取3个feature map(以下简称FM)上的anchor中心点anchor_points和stride;
3.获取目标框的类别标签和box坐标(在网络输入图上的绝对坐标,x1,y1,x2,y2),为了补齐,里面可能有无效的box数据即全为0,所以用mask_gt标记真实目标框;
4.由anchor_points和pred_distri解码出预测框pred_bboxes:[b, hw, 4],x1,y1,x2,y2的形式,FM上的坐标:
pred_distri在长度为reg_max4的维度上拆成4个长度为reg_max的向量v1、v2、v3、v4,然后softmax(v) · [0,1,…,reg_max-1]
其中v为v1、v2、v3、v4的统称,softmax(v)会将向量归一化并且每个分量值大小在0~1之间,“ · ”表示向量点乘,代码中reg_max=16,所以这时的预测框左上、右下xy偏移anchor中心范围[0, 15],即预测的box长宽[0, 32],恢复到原图上最大可以预测的box长宽最大为3232=1024;
点乘如下:
向量a=(x1,y1),向量b=(x2,y2)
a·b=x1x2+y1y2=|a||b|cosθ(θ是a,b夹角)
叫作a与b的数量积或a点乘b
步骤4可参考图:https://blog.csdn.net/weixin_40723264/article/details/130929125 (如侵立删)

5. TAL(Task Alignment Learning)分配正样本算法:
参考论文:TOOD: Task-aligned One-stage Object Detection
注意:TAL算法的forward用了@torch.no_grad()修饰,即整个TAL过程不求梯度,因为本来就是要得到一个给网络输出计算损失的参考值,而计算损失后要反向传播,如果没加@torch.no_grad(),那就会因为计算损失的参考量(拟合的目标)也是来自网络输出计算来的,会有矛盾无法收敛。
输入:
sigmoid(pred_score)
pred_bboxes*stride #第4步解码出来的预测框坐标恢复到模型的输入图上
anchor_points * stride #anchor中心点也恢复到模型的输入图上
gt_labels #下面3个为上面第3步出来的结果 [b, max_num_target, 1]
gt_bboxes # [b, max_num_target, 4]
mask_gt # [b, max_num_target, 1]
5.1 get_pos_mask
5.1.1 select_candidates_in_gts,以anchor的中心是否落在目标框中为原则来为每个目标框分配anchor,可看做一张 max_num_target*num_anchor的表,被分配的anchor对应的位置赋1;为方便理解,以batch=2(第1张图3个目标框(gt1,gt2,gt3),第2张图有1个目标框gt4(gt5,gt6起到补齐作用,无效)),max_num_target=3,num_anchor=5为例,如下表有被分配到目标框(即表中的gt)的anchor赋1,其余的0:
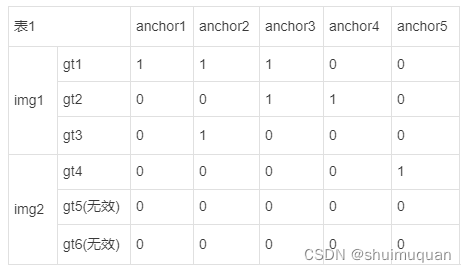
5.1.2 get_box_metrics,计算每个目标框与其分配到的anchor的度量metrics(如下面公式α=0.5,β=6):
S为在sigmoid(pred_score)中找到anchor对应的目标框的类别的分数(例如在sigmoid(pred_score)中,anchor1对应类别分数分别[0.1,0.7,0.4]且anchor1所服务的目标框的类别索引为0,则S=0.1),u是目标框与anchor的CIou;同时输出 CIou; 当类别分数值越高且CIOU越高时,t的值就越接近于1,此时预测box就与GTbox越匹配,就越符合正样本的标准.
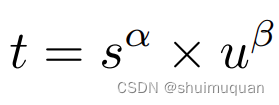
TAL官方论文中有提到,在对齐质量公式中的α、β是固定值,是由于团队对α、β的值做过学习性实验,将α、β也作为网络的一部分来优化数据。但发现随着α、β的更新,网络很容易进入局部最优状态,遂将α、β设置为固定值。但团队也指出,α、β的值可以根据具体任务来做一些微调,能够取得一些优化;
得到对其度量可如表2所示(此时表2中的anchor有了预测的类别分数和box,其实就是预测框):
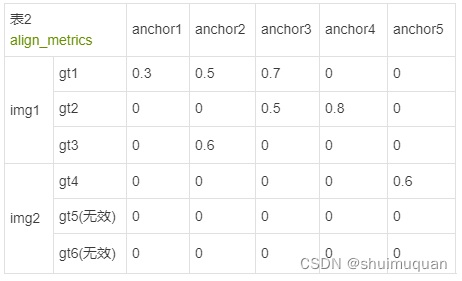
5.1.3 select_topk_candidates,为每个目标框选top_k个align_metrics最大的anchor(即预测框)和对应索引,为了容易理解,这里示例top_k=2,得到:
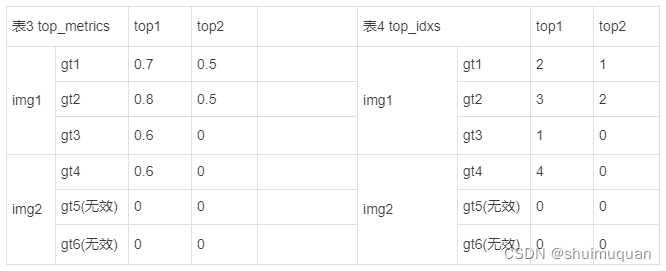
累计表4中每个anchor在top_k中的次数,例如表4左上角“2”,则在表5中gt1-anchor3的位置加1;
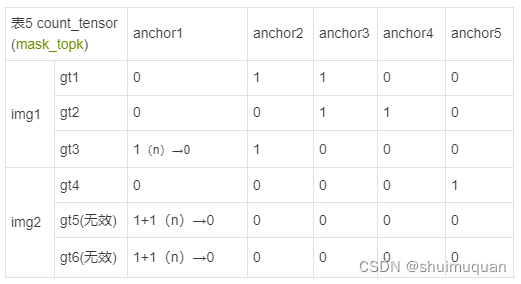
mask_topk的shape为[b, max_num_obj, num_anchor ];
即第5.1步得到mask_pos, align_metric, overlaps(即CIou)
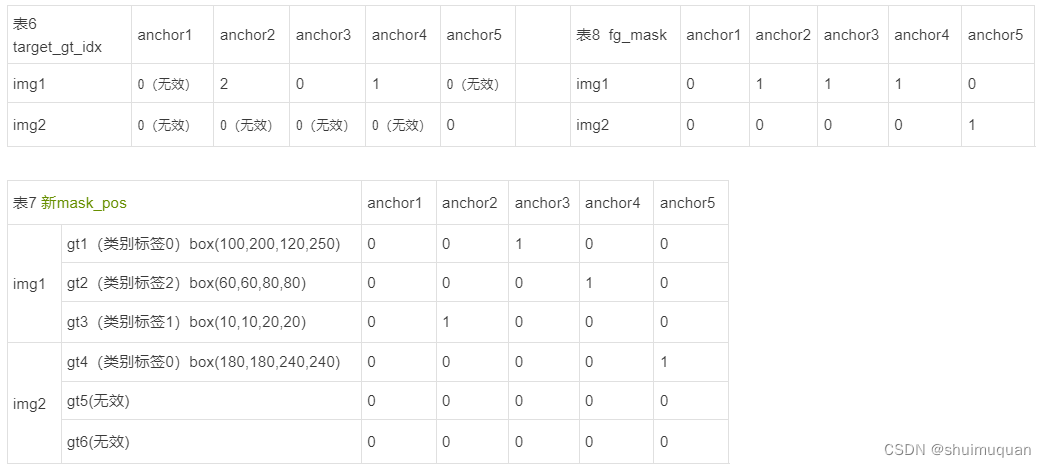
5.2 select_highest_overlaps
在1张图中对于那些同时服务多个目标框的anchor(例如表5所示的img1中的angchor3同时服务gt1和gt2),则根据CIou最大原则仅选出一个目标框被anchor(预测框)服务,即一个预测框只能对应一个目标框,但一个目标框能对应多个预测框;得到
target_gt_idx(表6):每个anchor服务的目标框的索引(从0开始);
mask_pos(表7): 对于服务多个目标框的anchor,根据CIou最大原则仅服务一个目标框的新mask_pos;
fg_mask(表8):anchor根据CIou最大原则仅服务一个目标框之后每个anchor服务的目标框数量;(数值为0或1,其实就是表示预测框是否为正样本)
简单起见,假如CIou大小比较与表3 top_metrics一样则有如下表6~8:
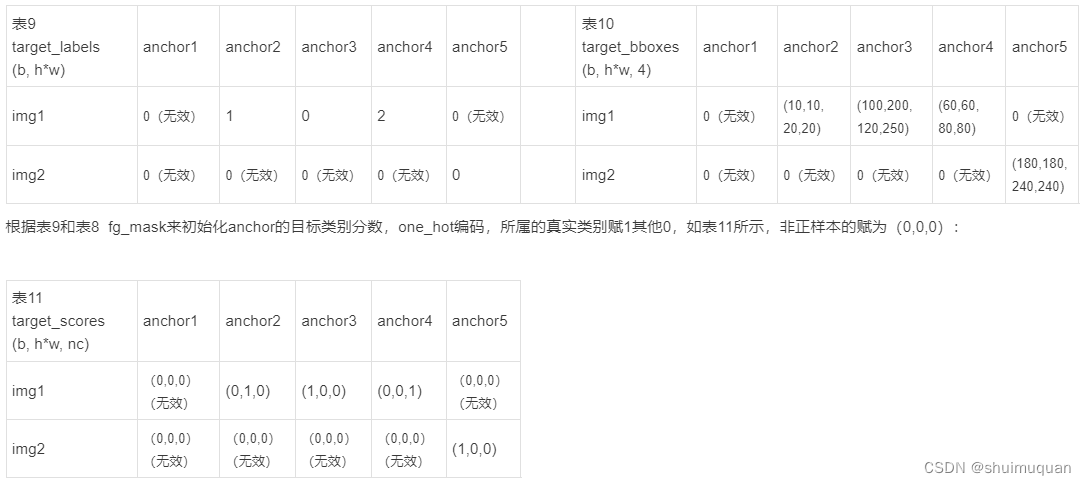
5.3 假如目标框gt1~4的真实类别标签0,2,1,0,(总共3类),根据表8如果anchor是正样本,则的类别就是其所服务的gt(表6)的类别, 回归也是往其所服务的gt的box去拟合:(在源代码中根据表8和9,表10中的0(无效)应该是gt1的box(10,10,20,20)(无效));
5.4 归一化Normalize
# Normalize
align_metric *= mask_pos #仅保留正样本与其所服务的目标框的度量
pos_align_metrics = align_metric.amax(dim=-1, keepdim=True) # b, max_num_obj 每个目标框的最大度量
pos_overlaps = (overlaps * mask_pos).amax(dim=-1, keepdim=True) # b, max_num_obj 每个目标框的最大CIou,注意最大的度量和最大的CIou不一定对应同一个anchor
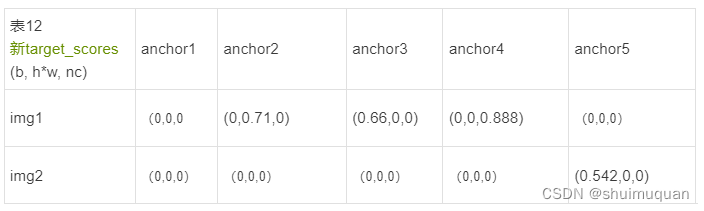
norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1) #目标框与正样本的度量乘于目标框与正样本的最大ciou再除以目标框与所有anchor的最大度量
target_scores = target_scores * norm_align_metric
得到新的target_scores,如表12,根据第6.1的分类计算损失可知这里的(0,0,0)不是表示无效,而是表示属于背景类:
最终第5步TAL算法输出:
target_labels(正样本的gt标签)[b, num_anchors];
target_bboxes(正样本的gt box)[b, num_anchors, 4];
target_scores(正样本与对应目标框计算度量后代替类别分数1)[b, num_anchors, nc];
fg_mask.bool()(正样本标记mask)[b, num_anchors];
target_gt_idx(正样本对应的gt ID)[b, num_anchors];
6. 损失计算
**6.1 类别损失cls_loss:**模型中head分类模块的输出与度量的二值交叉熵(BCEWithLogitsLoss)
target_scores_sum = max(target_scores.sum(), 1) #所有正样本的度量分数累加
# Cls loss
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE 二值交叉熵损失
附:对于BCEWithLogitsLoss损失,假如3个类别,target_scores=(0,0.7,0),网络输出经过sigmoid(sigmoid在BCEWithLogitsLoss内部操作):sigmoid(pred_scores)=(p1,p2,p3),则1个样本的多分类交叉熵损失:
-[(1-1)log(p1)+(1-0)log(1-p1) +
(0.7)log(p2)+(1-0.7)log(1-p2) +
(1-1)log(p3)+(1-0)log(1-p3) ]
6.2 如果有正样本则计算box_loss
iou_loss:
iou_loss = sum(CIou(正样本box,正样本对应的目标框box)*weight)/ target_scores_sum
weight = 正样本的target_score
dfl_loss:
计算正样本对应的目标框左上角和右下角到anchor中心点的距离后限制范围为0~15-0.01(15=max_reg-1),这里的目标框和anchor中心是在FM上的。得 到在FM上正样本的目标框左上角和右下角到anchor中心点的距离target_ltrb.
def _df_loss(pred_dist, target): 这里的target就是上面的target_ltrb输入
"""
Return sum of left and right DFL losses.
Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
https://ieeexplore.ieee.org/document/9792391
"""
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr
).mean(-1, keepdim=True)
如上代码段计算dfl,例如有一个target_ltrb为(16.7, 18.2, 26.4,28.9),则该目标框的左上偏移框(16,18,26,28),右下偏移框(17,19,27,29),左上/右下框坐标的权重计算与线性插值一样,分别为wl =(0.3, 0.8, 0.6, 0.1),wr = (0.7, 0.2, 0.4, 0.9);
网络head的输出预测box(里面的正样本)与左/右偏移框计算交叉熵,然后除以target_scores_sum;
6.3 三个损失乘于各自的加权(从加权系数大小可看出算法偏袒于box的回归):
loss[0] *= self.hyp.box # box gain 7.5
loss[1] *= self.hyp.cls # cls gain 0.5
loss[2] *= self.hyp.dfl # dfl gain 1.5
# loss = [cls_loss,iou_loss,dfl_loss]
输出loss.sum()*batch_size, , loss.detach()
后续待深挖和讨论:
TAL算法中为什么要通过Normalize来改变target_scores?
这种动态分配正样本与yolo5的静态分配正样本有什么不一样和优势?(参考其他博文)
anchor free与base anchor相比的优势?
多分类为什么要用度量的计算结果作为拟合逼近的目标??
最后的损失乘于batch_size:loss.sum()*batch_size,是为了通过这种方法使得batch_size越大允许反向传播时梯度越大吗?















 5651
5651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









