






文章目录
前言
本文主要目的为熟悉YoloV8网络结构的修改流程。
以《基于改进 YOLOv8n 航拍轻量化小目标检测算法:PECS-YOLO》
王舒梦,徐慧英,朱信忠,等.基于改进YOLOv8n航拍轻量化小目标检测算法:PECS-YOLO[J/OL].计算机工程:1-16[2024-07-
02].https://doi.org/10.19678/j.issn.1000-3428.0069353.
这篇论文为例,复现其中的模型结构创新点。
一、PECS -YOLO
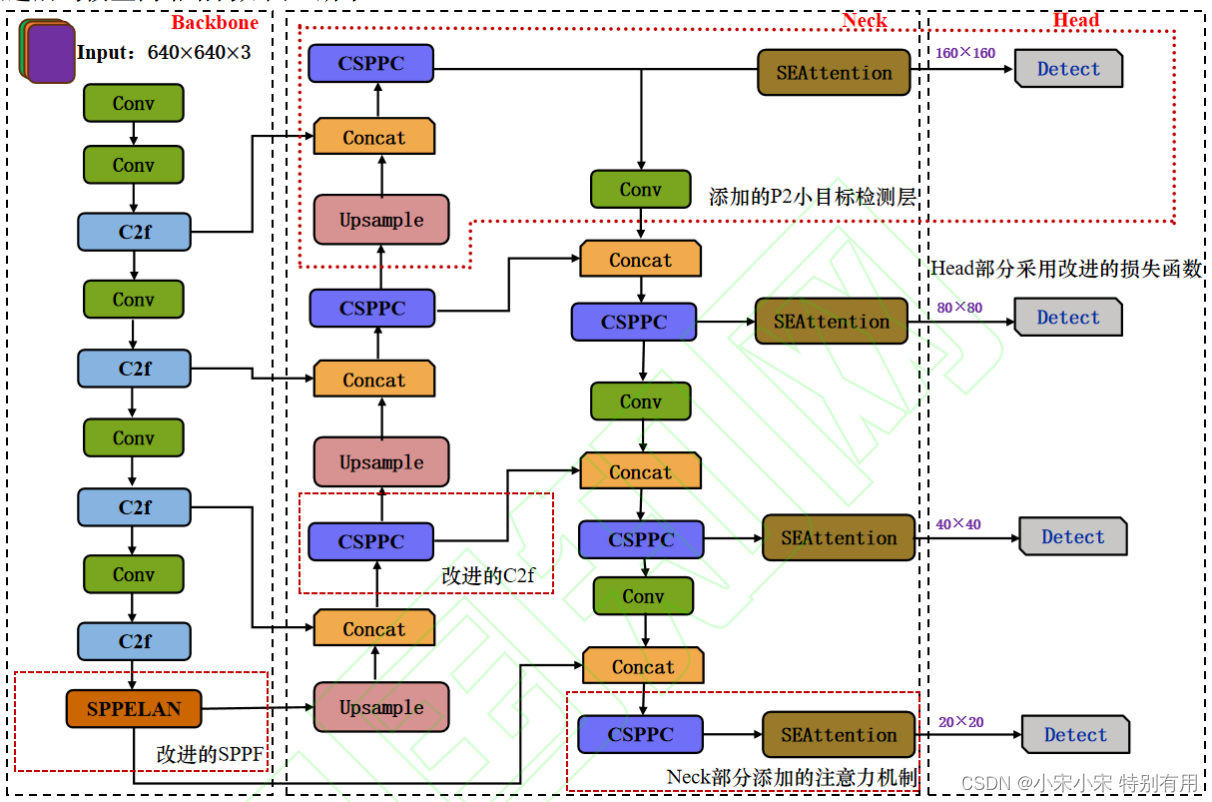
在论文中,作者对模型的更改为以下这几部分:
- 在 Neck 部分增加 P2 小目标检测层,使特征图可以获取到丰富的语义信息和空间信息,四个检测头使模型
可以进行多尺度小目标检测。- 每个检测头前加入了 SE 注意力机制,可以减少复杂环境中背景噪声的干扰。
- 以EfficiCIoU作为边界框回归的损失函数,对小目标的分类和识别更加精准。
- 将 SPP(Spatial Pyramid Pooling)与 ELAN(Efficient Layer Aggregation Network)[24]结合起来,提高了模型对不同尺度物体的识别能力。
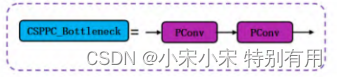
- 使用轻量化卷积 PConv 替换 Neck 中 C2f 模块中 Bottleneck 里的传统卷积核得到 CSPPC 模块,使得模型更加轻量化。
以上内容均来自论文。
改进后的模型结构如下图所示:
二、CSPPC 模块
2.1 原理讲解
作者将YoloV8模型Neck部分里的C2F进行了改进。C2F结构如下:
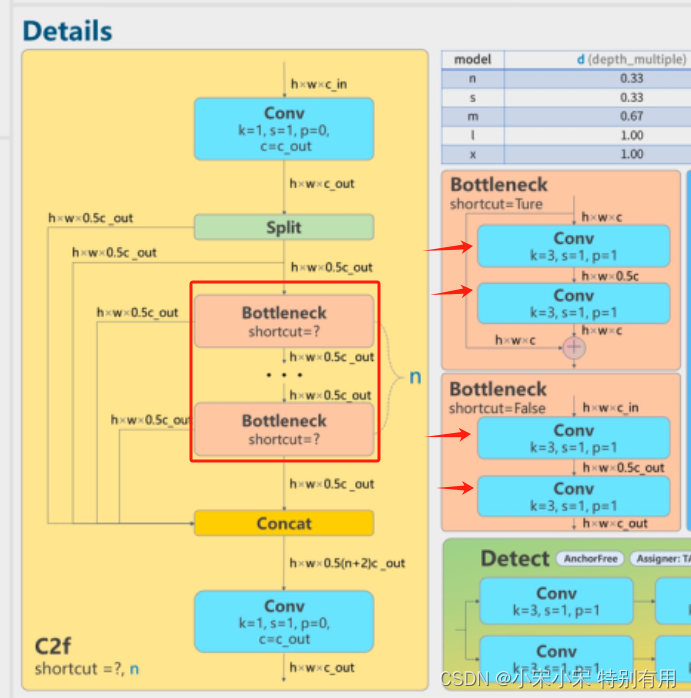
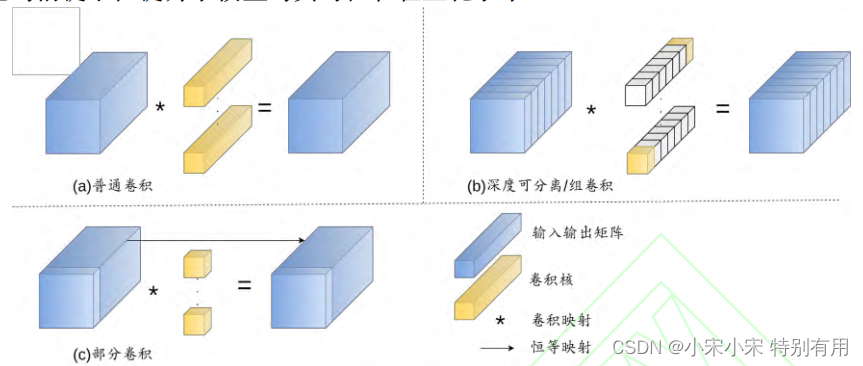
作者将C2f里面,Bottleneck部分里的普通卷积替换为了PConv,全称 Partial Convolution。这样做的目的,可以减少模型的参数量,提高计算速度。
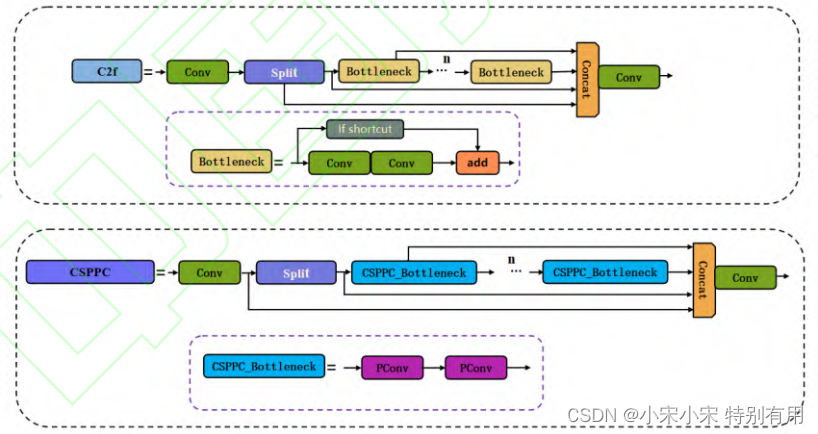
下图为改进后的对比图:
2.2 代码实现
2.2.1 模型代码
首先,从网上可以获取到PConv的实现代码。如下:
class PConv(nn.Module):
def __init__(self,dim,n_div,forward):
super(PConv, self).__init__()
self.dim_conv3 = dim // n_div
self.dim_untouched = dim - self.dim_conv3
self.partial_conv3 = nn.Conv2d(self.dim_conv3,self.dim_conv3,3,1,1,bias=False)
if forward == "slicing":
self.forward = self.forward_slicing
elif forward == "split_cat":
self.forward = self.forward_split_cat
else :
raise NotImplementedError
def forward_slicing(self,x):
x = x.clone()
x[:,:self.dim_conv3,:,:] = self.partial_conv3(x[:,:self.dim_conv3,:,:])
return x
def forward_split_cat(self,x):
x1,x2 = torch.split(x,[self.dim_conv3,self.dim_untouched],dim = 1)
x1 = self.partial_conv3(x1)
x = torch.cat((x1,x2),1)
return x
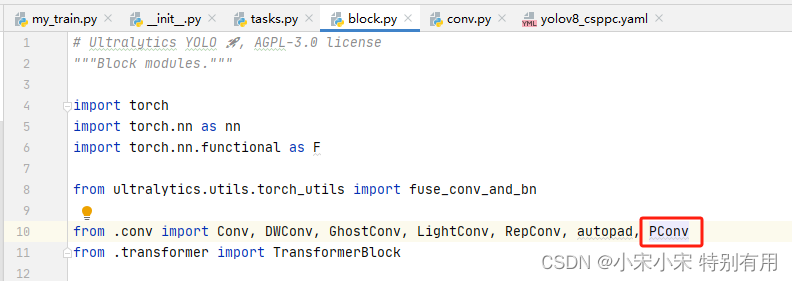
这个代码需要放在ultralytics\nn\modules\conv.py这个python文件里。
接下来,是改进后的Bottleneck部分,将普通卷积替换为上述的部分卷积(PConv)。如下图所示:
代码实现如下图所示:
class CSPPC_Bottleneck(nn.Module):
def __init__(self, dim):
super().__init__()
# 两次部分卷积
self.PConv1 = PConv(dim, n_div=4, forward='split_cat')
self.PConv2 = PConv(dim, n_div=4, forward='split_cat')
def forward(self, x):
return self.PConv2(self.PConv1(x))
这个代码需要放在ultralytics\nn\modules\block.py这个python文件里。
记得,要导入PConv这个函数。
最后,将CSPPC_Bottleneck替换掉原先的 Bottleneck即可。
代码如下:
class CSPPC(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(CSPPC_Bottleneck(self.c) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
这个代码也是需要放在ultralytics\nn\modules\block.py这个python文件里。
记得这里也要添加。
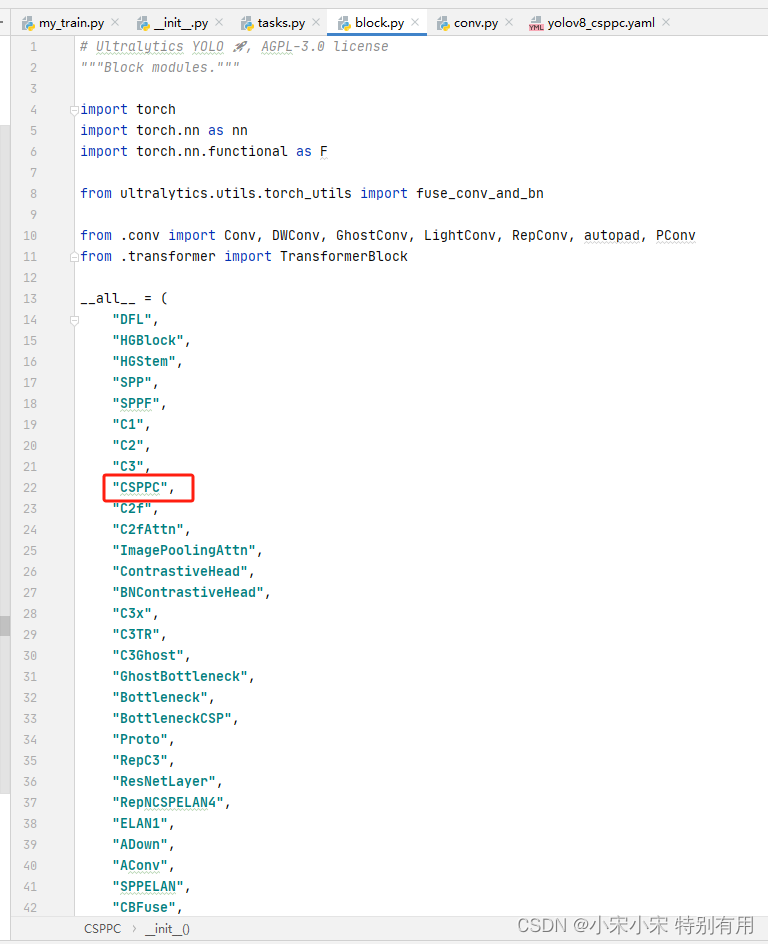
修改ultralytics\nn\modules_init_.py里的内容,相应的部位加上模块即可。
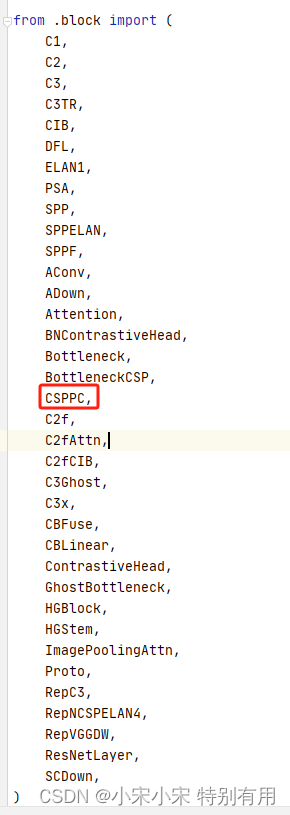
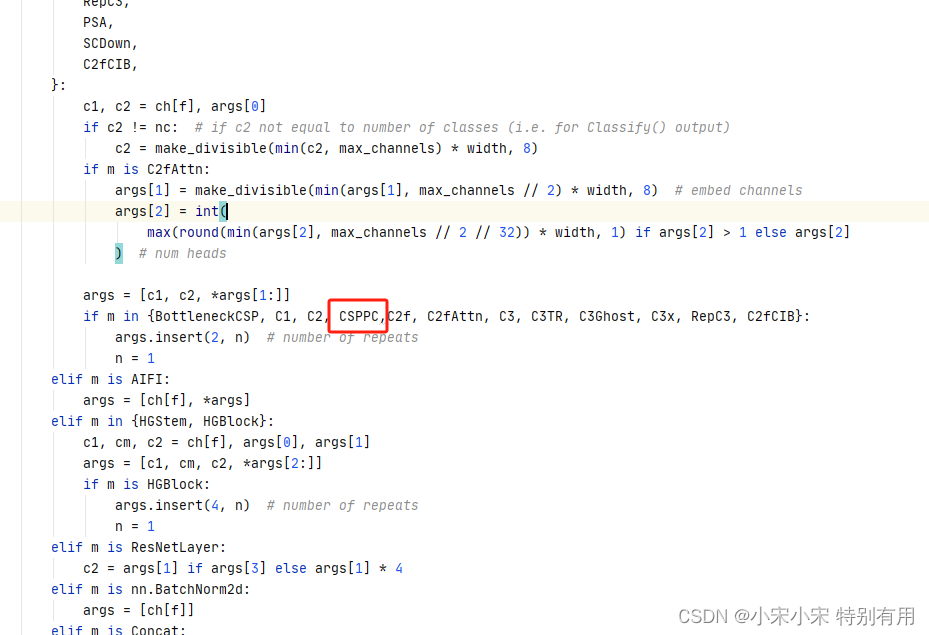
2.2.2 修改parse_model
(个人理解,哪里有C2f哪里就添加CSPPC,准不出错
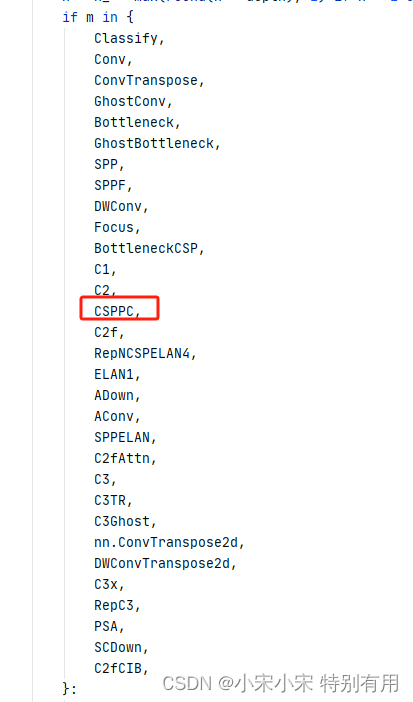
还有。
2.2.3 配置文件(.yaml)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, CSPPC, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, CSPPC, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, CSPPC, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, CSPPC, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
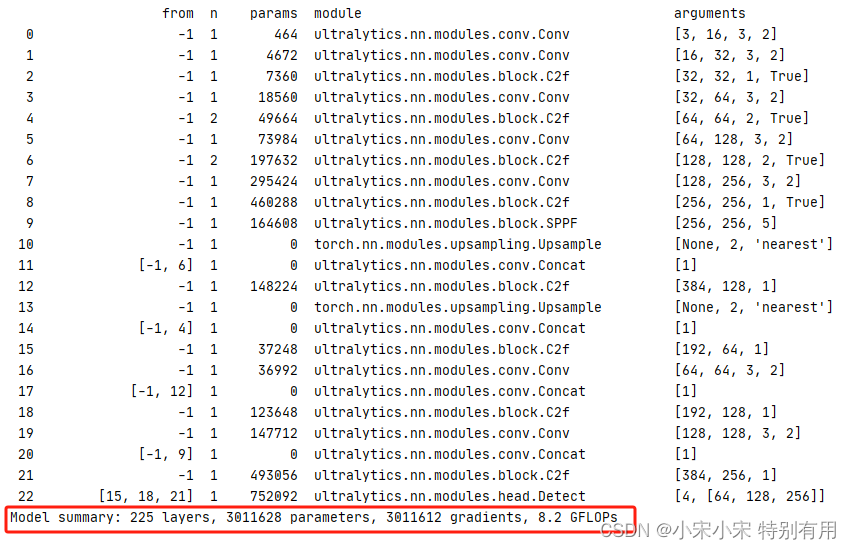
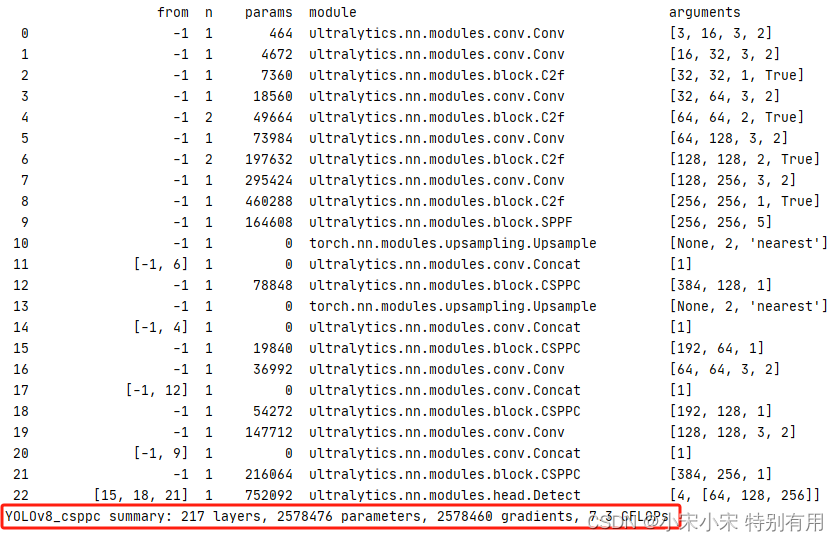
2.3 效果对比
修改前:
修改后:
三、SPPF 模块改进
在处理小目标时,感受野的大小对于模型捕捉细节的能力至关重要。SPPF(Separable Pyramid Pooling with Fusion)通过结合大核卷积和非膨胀卷积来增大感受野。然而,由于小目标的尺寸较小,大核卷积可能无法提供足够的空间分辨率来有效捕获小目标的特征,这些特征在信息融合过程中可能会被稀释,进而影响检测精度。
为了解决这一问题,本文提出了一个结构上改进的方法——SPPELAN(Spatial Pyramid Pooling with Efficient Layer Aggregation Network)。该结构结合了空间金字塔池化(SPP)和高效层聚合网络(ELAN)的注意力机制。
3.1 SPPELAN原理
如下图所示:
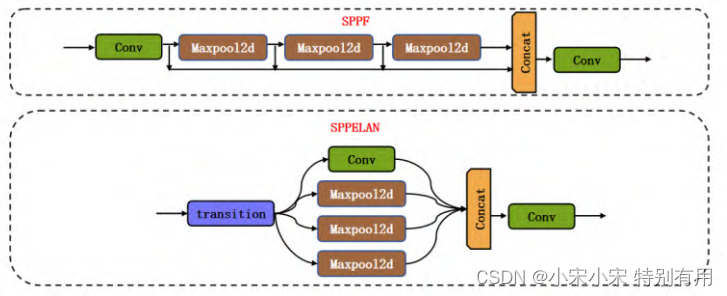
这里的SPPELAN是YOLOv9中与SPPF类似的模块,从网上查询到相关的结构如下:
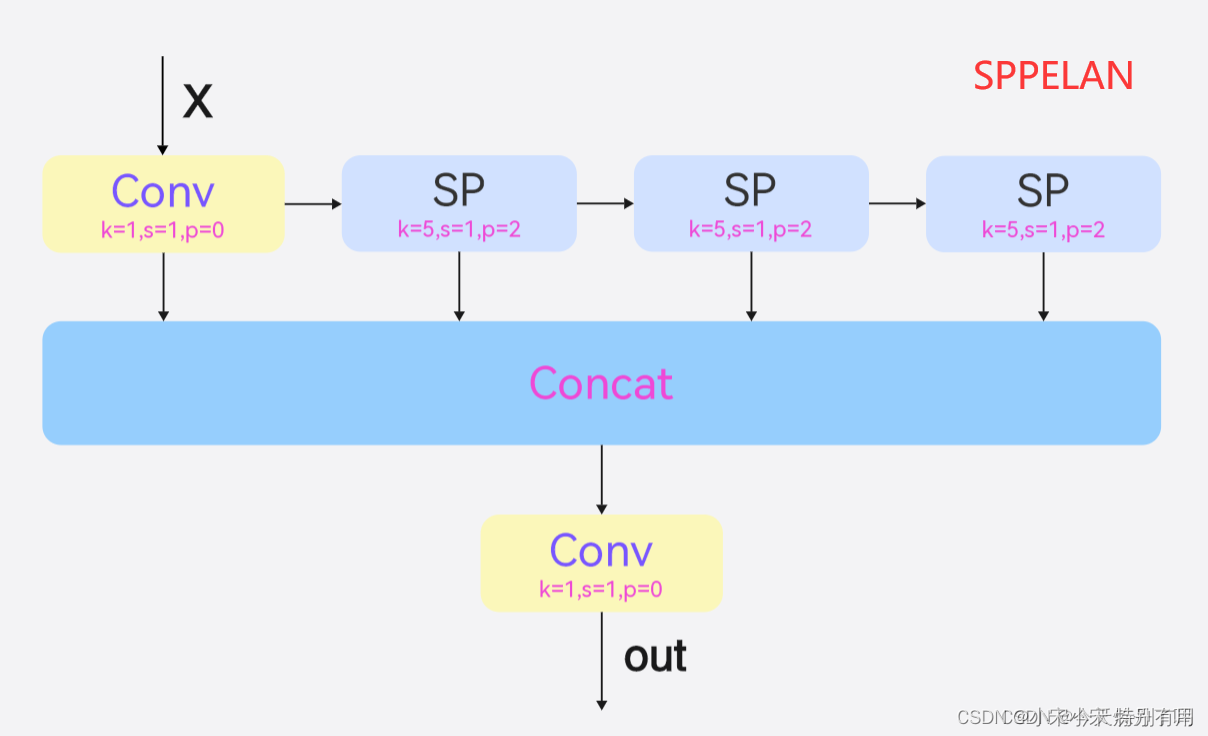
3.2 代码实现
3.2.1 模型代码
实现代码如下:
class SPPELAN(nn.Module):
"""SPP-ELAN."""
def __init__(self, c1, c2, c3, k=5):
"""Initializes SPP-ELAN block with convolution and max pooling layers for spatial pyramid pooling."""
super().__init__()
self.c = c3
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
self.cv3 = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
self.cv4 = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
self.cv5 = Conv(4 * c3, c2, 1, 1)
def forward(self, x):
"""Forward pass through SPPELAN layer."""
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])
return self.cv5(torch.cat(y, 1))
这个模块在yolov8里面已经实现过了,直接修改.yaml文件即可。
3.2.1 修改配置文件(.yaml)
在CSPPC模块改进的基础上修改。
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPELAN, [1024, 256]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, CSPPC, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, CSPPC, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, CSPPC, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, CSPPC, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
四、SE 注意力机制
在每一个检测头前添加SE 注意力机制,可以减少复杂环境中背景噪声的干扰。
在改进的模型架构中,SEAttention 加到颈部网络的每个检测头前可以减少背景噪声的干扰,增强复杂环境下小目标的识别能力
https://pan.baidu.com/s/1pCQJkd4e-nyNoheVodp_vA
4.1 SE 注意力机制原理讲解
SENet是通道注意力机制的典型实现。
2017年提出的SENet是最后一届ImageNet竞赛的冠军,其实现示意图如下所示,对于输入进来的特征层,我们关注其每一个通道的权重,对于SENet而言,其重点是获得输入进来的特征层,每一个通道的权值。利用SENet,我们可以让网络关注它最需要关注的通道。
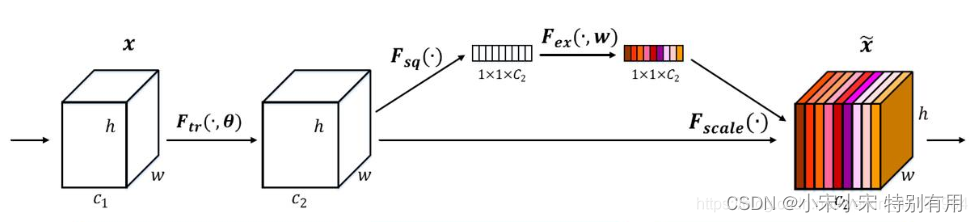
其具体实现方式就是:
1、对输入进来的特征层进行全局平均池化。
2、然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4、在获得这个权值后,我们将这个权值乘上原输入特征层即可。
4.2 代码实现
# SeNet通道注意力机制
import torch
from torch import nn
class SeNet(nn.Module):
def __init__(self, channel, ratio=16):
super(SeNet, self).__init__() # 初始化
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 平均池化
# 两次全连接
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, False),
nn.ReLU(),
nn.Linear(channel // ratio, channel, False),
nn.Sigmoid(),
)
def forward(self, x):
b, c, h, w = x.size()
# 全局平均池化
# b,c,h,w -> b,c,1,1
# b,c,1,1 -> b,c // ratio
avg = self.avg_pool(x).view([b, c])
# 两次全连接
# b,c // ratio -> b,c,1,1
fc = self.fc(avg).view([b, c, 1, 1]) # 获得权值
return x * fc # 权值乘原特征图
4.2.1 添加注意力
在ultralytics\nn\modules\attention.py路径下,创建attention.py,复制上述的代码。
打开ultralytics\nn\modules_init_.py文件,将下面这行代码,添加到__init__.py的合适位置。
from .attention import SeNet
4.2.2 修改parse_model
打开ultralytics\nn\tasks.py文件,先将SeNet模块导入,在tasks.py文件的头文件处,输入下面这段代码。
# 导入SeNet注意力函数
from ultralytics.nn.modules import SeNet
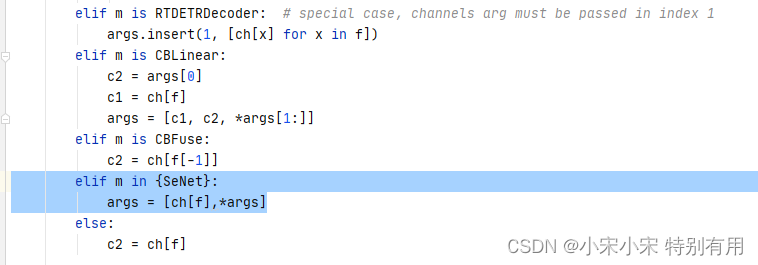
修改在ultralytics/nn/task.py中的parse_model函数【作用是解析模型结构】,在解析的地方添加如下代码:
elif m in {SeNet}:
args = [ch[f],*args]
4.2.3 配置文件(.yaml)
根据原文给的结构图,我们可以分析,这个SE注意力机制是添加在Neck部分中,每一个CSPPC的后面,即每一个检测头前面。
参考链接:YOLOv8优化:注意力系列篇 | SEAttention注意力,效果秒杀CBAM
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPELAN, [1024, 256]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, CSPPC, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, CSPPC, [256]] # 15 (P3/8-small)
- [-1, 1, SeNet, [256]] # 16
- [15, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, CSPPC, [512]] # 19 (P4/16-medium)
- [-1, 1, SeNet, [512]] # 20
- [19, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, CSPPC, [1024]] # 23 (P5/32-large)
- [-1, 1, SeNet, [1024]] # 24
- [[16, 20, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)
五、P2 小目标检测层
在 Neck 部分增加 P2 小目标检测层,使特征图可以获取到丰富的语义信息和空间信息,四个检测头使模型可以进行多尺度小目标检测。
直接修改.yaml文件。注意:在上述修改的基础上修改。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P2-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
# YOLOv8.0 backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPELAN, [1024, 256]] # 9
# YOLOv8.0-p2 head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, CSPPC, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, CSPPC, [256]] # 15 (P3/8-small)
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 16
- [[-1, 2], 1, Concat, [1]] # cat backbone P2
- [-1, 3, CSPPC, [128]] # 18 (P2/4-xsmall)
- [-1, 1, SeNet, [128]] # 19
- [18, 1, Conv, [128, 3, 2]] # 20
- [[-1, 15], 1, Concat, [1]] # cat head P3
- [-1, 3, CSPPC, [256]] # 22 (P3/8-small)
- [-1, 1, SeNet, [256]] # 23
- [22, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, CSPPC, [512]] # 26 (P4/16-medium)
- [-1, 1, SeNet, [512]] # 27
- [26, 1, Conv, [512, 3, 2]] # 28
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, CSPPC, [1024]] # 30 (P5/32-large)
- [-1, 1, SeNet, [1024]] # 31
- [[19, 23, 27, 31], 1, Detect, [nc]] # Detect(P2, P3, P4, P5)
总结
未完待续。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









