







 本文深入解析了今日头条的推荐算法,包括系统概览、内容分析、用户标签和评估分析。推荐系统通过内容特征、用户特征和环境特征来预测用户满意度。内容分析涉及文本、图片和视频,而用户标签是推荐系统的基石。评估分析强调了完备的评估体系的重要性。文章还提及了内容安全措施,如低俗内容和谣言识别。
本文深入解析了今日头条的推荐算法,包括系统概览、内容分析、用户标签和评估分析。推荐系统通过内容特征、用户特征和环境特征来预测用户满意度。内容分析涉及文本、图片和视频,而用户标签是推荐系统的基石。评估分析强调了完备的评估体系的重要性。文章还提及了内容安全措施,如低俗内容和谣言识别。
本次分享将主要介绍今日头条推荐系统概览以及内容分析、用户标签、评估分析,内容安全等原理。
如今,算法分发已经逐步成为信息平台、搜索引擎、浏览器、社交软件等几乎所有软件的标配,但同时也开始面临各种不同的质疑、挑战与误解。
2018年1月,今日头条资深算法架构师曹欢欢博士,首次公开今日头条的算法原理,以期推动整个行业问诊算法、建言算法。通过让算法透明,来消除各界对算法的误解。
据悉,今日头条的信息推荐算法自2012年9月第一版开发运行至今,已经经过四次大调整和修改。目前服务全球亿万用户。
以下为曹欢欢关于《今日头条算法原理》的分享内容(已授权):

本次分享将主要介绍今日头条推荐系统概览以及内容分析、用户标签、评估分析,内容安全等原理。

一、系统概览
推荐系统,如果用形式化的方式去描述实际上是拟合一个用户对内容满意度的函数,这个函数需要输入三个维度的变量。

第一个维度是内容。头条现在已经是一个综合内容平台,图文、视频、UGC小视频、问答、微头条,每种内容有很多自己的特征,需要考虑怎样提取不同内容类型的特征做好推荐。第二个维度是用户特征。包括各种兴趣标签,职业、年龄、性别等,还有很多模型刻划出的隐式用户兴趣等。第三个维度是环境特征。这是移动互联网时代推荐的特点,用户随时随地移动,在工作场合、通勤、旅游等不同的场景,信息偏好有所偏移。
结合三方面的维度,模型会给出一个预估,即推测推荐内容在这一场景下对这一用户是否合适。
这里还有一个问题,如何引入无法直接衡量的目标?

推荐模型中,点击率、阅读时间、点赞、评论、转发包括点赞都是可以量化的目标,能够用模型直接拟合做预估,看线上提升情况可以知道做的好不好。但一个大体量的推荐系统,服务用户众多,不能完全由指标评估,引入数据指标以外的要素也很重要。
比如广告和特型内容频控。像问答卡片就是比较特殊的内容形式,其推荐的目标不完全是让用户浏览,还要考虑吸引用户回答为社区贡献内容。这些内容和普通内容如何混排,怎样控制频控都需要考虑。
此外,平台出于内容生态和社会责任的考量,像低俗内容的打压,标题党、低质内容的打压,重要新闻的置顶、加权、强插,低级别账号内容降权都是算法本身无法完成,需要进一步对内容进行干预。
下面我将简单介绍在上述算法目标的基础上如何对其实现。
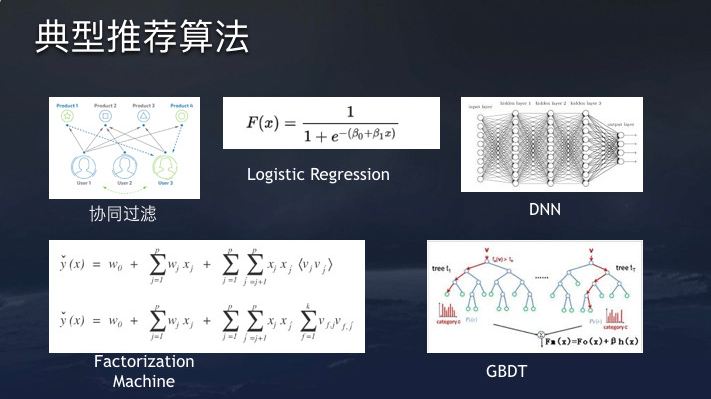
前面提到的公式y = F(Xi ,Xu ,Xc),是一个很经典的监督学习问题。可实现的方法有很多,比如传统的协同过滤模型,监督学习算法Logistic Regression模型,基于深度学习的模型,Factorization Machine和GBDT等。
一个优秀的工业级推荐系统需要非常灵活的算法实验平台,可以支持多种算法组合,包括模型结构调整。因为很难有一套通用的模型架构适用于所有的推荐场景。现在很流行将LR和DNN结合,前几年Facebook也将LR和GBDT算法做结合。今日头条旗下几款产品都在沿用同一套强大的算法推荐系统,但根据业务场景不同,模型架构会有所调整。

模型之后再看一下典型的推荐特征,主要有四类特征会对推荐起到比较重要的作用。
第一类是相关性特征,就是评估内容的属性和与用户是否匹配。显性的匹配包括关键词匹配、分类匹配、来源匹配、主题匹配等。像FM模型中也有一些隐性匹配,从用户向量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2630
2630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









