








作者:Dr. Dataman
译者:刘媛媛
过去三十年来,研究学者在图像识别算法和图像数据集方面做了许多工作,积累了宝贵的知识经验。如果你对图像训练感兴趣,但又不知道从何开始。那么,我希望这篇文章可以为你提供一个很好的开始。
这篇文章简要介绍了过往的演变,并指出了当代热点话题。阅读本文后,你将熟悉以下主题:
丨ImageNet
丨预训练模型
丨迁移学习(热门主题)
丨使用预训练模型去识别一张未知图像
丨PyTorch
一、ImageNet的起源
基于监督学习的卷积神经网络模型的训练依赖于图像数据。在2000年代初期,大多数AI研究人员专注于图像分类问题的模型算法,但是由于缺乏大规模的数据样本使其具有很大的挑战性。
研究人员需要大量的图像及其对应的标签来训练模型,于是,ImageNet数据集就此诞生。
在科学研究中,两个学科交叉时可以碰撞出新的火花。
ImageNet由斯坦福大学人工智能研究员李飞飞构思和带头。2007年,当她开始构思ImageNet的想法时,她首先去会见了普林斯顿大学教授Christiane Fellbaum—— WordNet 的创建者之一,与他讨论了ImageNet项目。
WordNet是一个自然语言处理(NLP)的词汇数据库,用于记录名词、动词、附属词和副词之间的语义关系。
它有155,327个词汇,分为175,979个同义词,称为synsets(有些词汇只有一个synset,有些有几个)。
如果将图像附在WordNet中的词上,那不是很好吗?这就是ImageNet的起源。
ImageNet将成百上千的图像与WordNet中的同义词联系起来。从那时起,ImageNet就对计算机视觉和深度学习的发展起到了重要作用。这些数据可供研究人员免费使用,用于非商业用途。
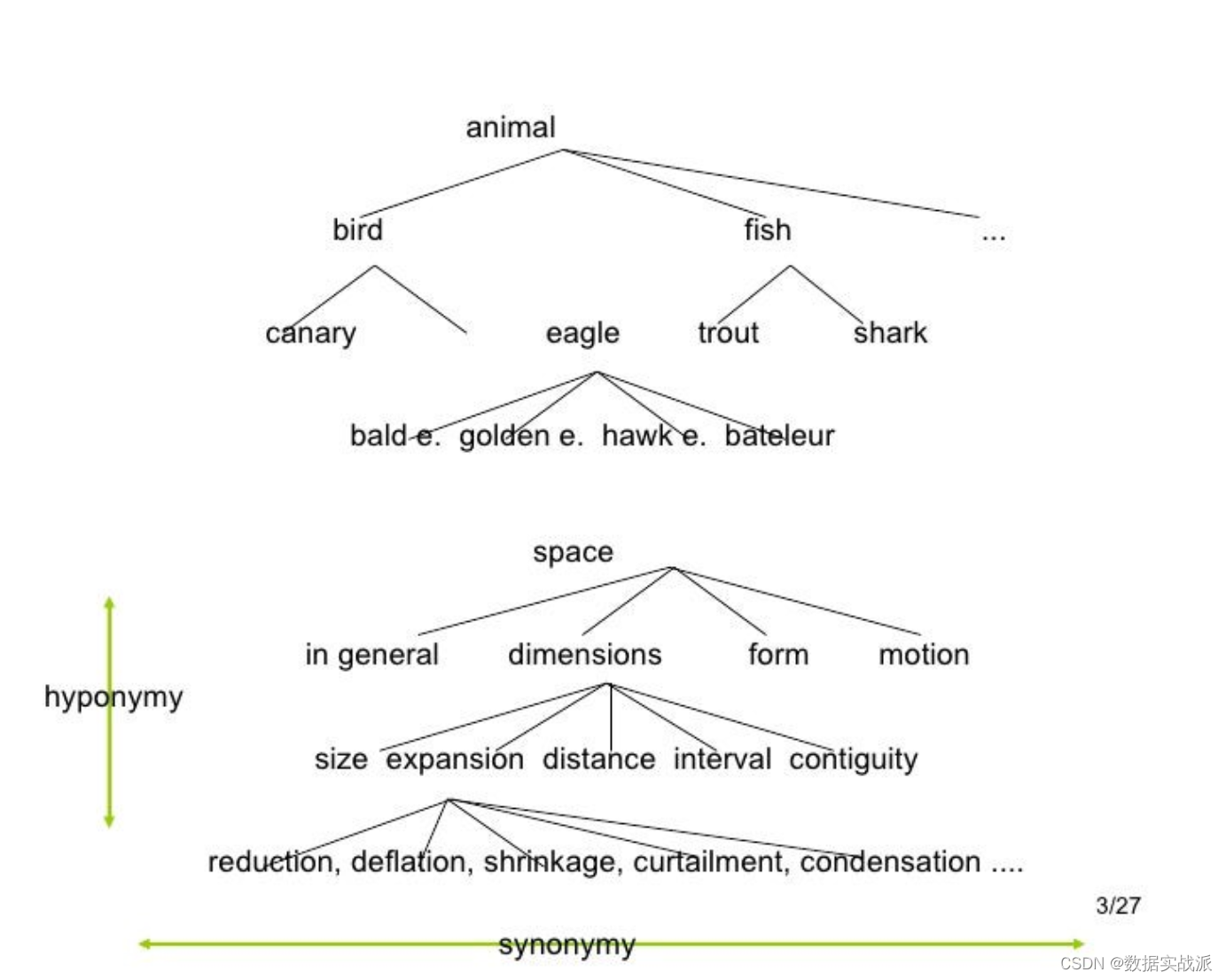
ImageNet数据库有超过1400万张图片(14,197,122),被组织成21,841个子类别。数据集中的每张图片都是由人类注释的,并经过多年的质量控制。
ImageNet中的大多数同义词是名词(80,000多个),总共有100,000多个同义词。因此,ImageNet是一个组织良好的层次结构,使其对监督机器学习任务非常有用。你可以通过ImageNet网站自己注册,免费访问Ima
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2084
2084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









