








现有的预训练模型(pre-trained models)通常针对特定类别的问题。迄今为止,对于正确的模型架构和预训练设置应该是什么,似乎学术界仍未达成共识。
谷歌团队在这个问题上迈出了重要一步:他们在Unifying Language Learning Paradigms这篇论文中提出了一个统一的预训练模型框架,该框架在数据集和设置中普遍有效。
在广泛的消融实验比较多个预训练目标之后,团队并发现这个方法在多种不同设置中优于 T5 和/或 GPT 模型,将这个ul2模型扩展到 20B 参数后,在 50 个完善的监督 NLP 任务上实现了 SOTA 性能,这些任务包括语言生成(自动和人工评估)、语言理解、文本分类、问答、常识推理、长文本推理、结构化知识基础和信息检索。
论文:https://arxiv.org/pdf/2205.05131.pdf
代码:https://github.com/google-research/google-research/tree/master/ul2
背景和动机:究竟如何选择预训练模型?
如今有大量的预训练语言模型提供给NLP 研究人员和从业者。
当面对应该使用什么模型的问题时,答案通常是取决于具体的任务。回答这个问题可能非常困难,这个问题包括了许多后续的细粒度问题,比如,“仅使用编码器还是使用编码器-解码器架构?”,“span corruption还是语言模型?”。
进一步追问,答案似乎总是取决于目标下游的任务。
本文对这一思考过程进行了质疑和反思,具体回答了为什么选择预训练语言模型要依赖于下游任务的问题。那么,如何对能在许多任务中普遍有效地模型进行预训练?
本文提出了使通用语言模型成为可能的关键一步:提出了一个统一的语言学习范式(UL2)的框架,简而言之,该框架在非常不同的任务和设置中始终有效。图1展示了UL2如何普遍良好地在各类下游任务上执行,而不像其他模型经常需要进行权衡。
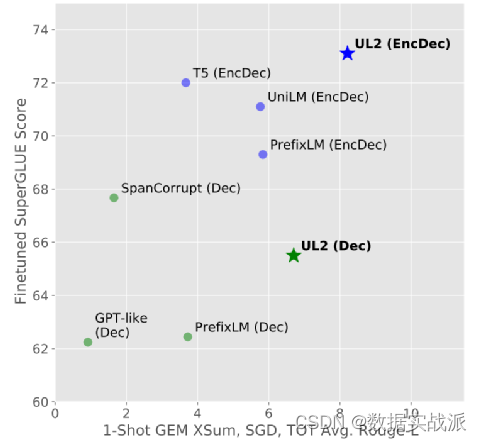
图1. UL2与其他预训练语言模型在下游任务上的对比
通用模型的吸引力是显而易见的,它的出现允许集中精力改进和扩大单一模型,而不是在N个预训练模型之间分散资源。此外,在资源受限的情况下,只有少数几个模型可以被服务(例如,在设备上),最好有一个可以在许多类型的任务上表现良好的单一预训练模型。
统一语言学习范式:任务及架构
预训练任务
许多预训练任务可以简单地表述为“输入到目标”任务,其中输入是指模型所依赖的任何形式的内存或
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









