







作为房地产分析项目的一部分,主要解决两个问题:
1.以pandas中Dataframe形式给出一组需求方的需求数量和报价和一组供给方的需求数量和报价,交易系统返回撮合成功的订单信息deal_df。
2.在实际生活中,需求方和供给方的议价能力会影响到最后成交的数量和价格,最后的结果往往是一个双方在某种程度上“妥协”的结果,我需要这个交易系统能够接受一个议价能力的参数,让系统根据议价能力调整。
Srep 1:准备数据
需求方的字段(need_df):need_price(报价),need_amount(需求量),need_is_done(交易状态标识)、need_num(身份编号)
供给方的字段(supply_df):supply_price,supply_amount,supply_is_done,supply_num(字段含义类比于需求方)
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
#-----------------------------------------------------
#20个需求方
need_df = pd.DataFrame() #空的df,连列名也不要,但是如果后期对其使用append方法的话就需要列名了直接用列名赋值
supply_df = pd.DataFrame()
need_price = [int(x) for x in np.random.rand(20)*20 + 100] #价格在100-120之间
need_amount = [int(x) for x in np.random.rand(20)*10+20] #数量在20-30之间
need_df['need_price'] = need_price
need_df['need_amount'] = need_amount
need_df['need_is_done'] = False
#sort_values方法产生一个copy
need_df = need_df.sort_values(by='need_price',ascending=True)
#排序之后index也乱了,需要重新赋值
need_df.index = range(len(need_df))
need_df['need_num'] = need_df.index
#10个供给方
supply_price = [int(x) for x in np.random.rand(10)*20 + 110] #价格在110-130之间
supply_amount = [int(x) for x in np.random.rand(10)*10+10] #数量在10-20之间
supply_df['supply_price'] = supply_price
supply_df['supply_amount'] = supply_amount
supply_df['supply_is_done'] = False
#sort_values方法产生一个copy
supply_df = supply_df.sort_values(by='supply_price',ascending=True) #从大到小
#排序之后index也乱了,需要重新赋值
supply_df.index = range(len(supply_df))
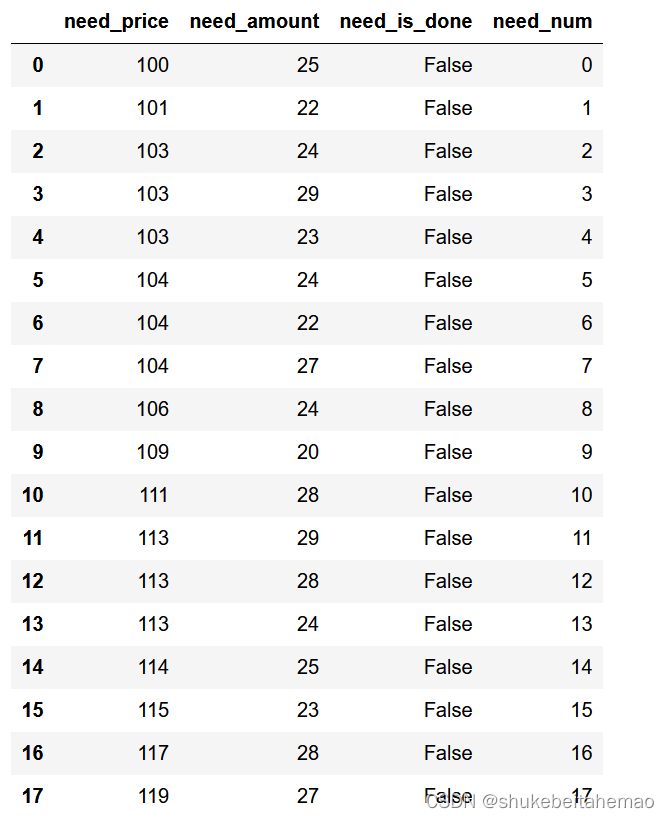
supply_df['supply_num'] = supply_df.index数据长成这个样子:
step 2:考虑一个基础的交易函数——match_making()
我们假设所有的商品都是同质的,但是出价却各有不同,需求方出高价的和供给方出低价的将优先成交,按照这个想法来设计撮合交易的步骤:
- 将需求方按照价格从高到低排列,将供给方按照价格从低到高排列
- 进入循环,取出双方交易状态为False的数据
- 取出排好序后各自的第一行数据,由需求方开始向供给方比较价格,如果需求方出价高于供给方,则交易可以进行,交易价格是供给方的出价。按照两者的数量关系,又可以分为:(1)供给方数量大于需求方,则交易数量按需求量执行,需求方的交易状态改为True (2)供给方数量小于需求方,则交易数量按照供给方数量执行,供给方的交易状态改为True (3)若数量相等,则按照供给方数量执行,双方的交易状态均改为True。在完成交易后,将交易信息整理为一个deal_df。然后检查是否满足循环退出的条件:任意一方的dataframe只剩下一行且交易状态列均为True。
- 如果需求方出价低于供给方出价,在这种情况下事实上是需求方的最高价还要低于供给方的最低价,则交易无法进行,直接退出循环。
代码实现:
def match_making(need_df,supply_df):
deal_df = pd.DataFrame(columns=['amount','price','need_num','supply_num']) #记录实际的成交信息
while True: #由于不能预先判断执行多少次循环,这里应该用while循环
#取出还没有完成交易的数据,实际上也可以在每次交易完成后将对应的数据删除,这样会加速计算
need_df = need_df[need_df.need_is_done==False] #使用df的好处是可以用.的方式操作属性
supply_df = supply_df[supply_df.supply_is_done==False]
# print('need',need_df)
# print('supply',supply_df)
#重置df的index,因为在上一步我们事实上使用的是切片的方法,导致index可能不是从0开始的
#也就是说不重置Index的话就不能以0作为索引取出第一个数据
need_df.index = range(len(need_df))
supply_df.index = range(len(supply_df))
#----------------开始询价-----------------------
#取出供需双方df的第一行数据
#宁愿使用取出数据再放回的方式,也不愿意对原来的df进行直接的更改,更看重程序的可读性而不是速度
need_num = need_df.loc[0].need_num
need_price = need_df.loc[0].need_price
need_amount = need_df.loc[0].need_amount
supply_num = supply_df.loc[0].supply_num
supply_price = supply_df.loc[0].supply_price
supply_amount = supply_df.loc[0].supply_amount
#如果需求方出价高于或等于供给方出价,则该行是可成交的,更新状态
if need_price >= supply_price:
#进一步判断数量关系
#如果需求量大于供给量:
if need_amount > supply_amount:
need_df.loc[0,'need_amount']=need_amount - supply_amount #削减需求数量
supply_df.loc[0,'supply_is_done'] = True #更改供给方的交易状态,loc是切片操作,可以影响到原值的
# 将交易信息整理为series,并合并到deal_df
se = pd.Series({
'amount':supply_amount,
'price':supply_price,
'need_num':need_num,
'supply_num':supply_num
})
#向df添加se,现在主流的应该使用concat方法了,如果用append方法的话需要设置ignore_index
deal_df = deal_df.append(se,ignore_index=True)
#如果需求量小于供给量:
elif need_amount < supply_amount:
supply_df.loc[0,'supply_amount'] = supply_amount - need_amount
need_df.loc[0,'need_is_done'] = True
se = pd.Series({
'amount':need_amount,
'price':supply_price,
'need_num':need_num,
'supply_num':supply_num
})
deal_df = deal_df.append(se,ignore_index=True)
#如果需求量等于供给量:
else:
#双方交易状态同时改为完成
need_df.loc[0,'need_is_done'] = True
supply_df.loc[0,'supply_is_done'] = True
se = pd.Series({
'amount':need_amount,
'price':supply_price,
'need_num':need_num,
'supply_num':supply_num
})
deal_df = deal_df.append(se,ignore_index=True)
#在完成交易之后判断是否达到了所有可行的交易都交易完的状态,如果是,则退出循环
#即如果需求方的df和供给方的df中的长度只有1,则市场出清
if(len(need_df)==1 and need_df.need_is_done.all()) or (len(supply_df)==1 and supply_df.supply_is_done.all()):
break
#如果需求方出价低于供给方出价(事实上是所有供给方中的最低出价),则交易结束
else:
break
return deal_df运行match_making()的结果(supply_df按价格从低到高排列,need_df从高到低):
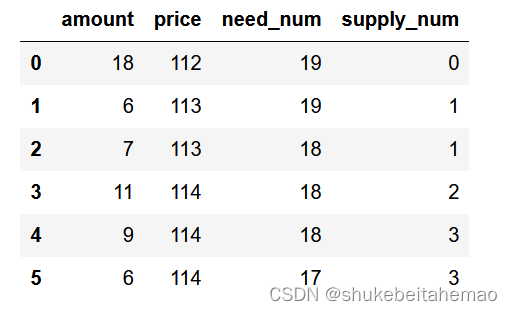
运行结果符合预期。
还可以对成交的平均价格和数量进行统计,反映有多少潜在的需求和供给没有被满足。
Step 3:考虑议价能力调整后的交易函数
假设议价能力系数取0-1,越是接近于0,则需求方的议价能力越强,越是接近于1,则供给方的议价能力越强,那么函数该怎么设计才能反映议价能力的影响呢?
我是这样考虑的:当A方相对于B方掌握完全议价能力的时候,意味着所有A方中的个体的意愿价格和意愿数量均能被满足,这是A方向B方的一种倾倒行为,或者说倾销,从数据操作上来说就是把A方的所有报价信息依次分配给B方成员承担。这个时候A方和B方均按照价格从高到低排列,然后从A方的第一个成员开始向B方倾倒订单,B方的第一个成员按照自己报出的数量和对方的价格接受交易,参考match_making函数的数据转换思路进行循环,如果A方倾倒完一轮之后还有剩余,则就剩余部分调用递归继续倾倒。于是我们就能得出当B方完全没有议价能力时候,B方中的每一个成员所接受的数量和平均价格。
那如果B方掌握了完全议价能力,B方每个成员所得到的交易数量和平均价格就是最开始的dataframe(完全议价能力意味着想卖/买多少就卖/买多少,想要什么价格就什么价格)。于是我们有了B方的每个成员在完全有议价能力和完全没有议价能力这两种情况下所得到的成交价格和数量。同样,对于A方我们也能得到这样的数据。则考虑议价能力系数后的报价可以是:
需求方报价 = (1-议价能力系数)*完全议价能力下的价格 + 议价能力系数*完全没有议价能力下的价格
供给方报价 = 议价能力系数*完全议价能力下的价格 + (1-议价能力系数)*完全没有议价能力下的价格
这个公式的设计允许当议价能力系数越低时,需求方的价格越接近于其有完全议价能力的价格,而供给方则越接近于其完全没有议价能力下的价格。
如此这般,我们就能得到经过议价能力调整后的双方报价和数量,然后再调用先前的match_making函数进行最终的撮合。我们实际上是价格,最原始的need_df和supply_df是一个天真的意愿,需求双方会掂量一下自己的议价能力修改天真的意愿,给出最终的报价和数量,然后由市场过程match_making函数进行撮合。也就是说,我们认为,议价能力反映在事先的价格和数量估计上,而不是反映为实际交易的计算过程之中。
step 3-1 pull函数的设计
该函数接受一个倾倒方的数据框out_df和被倾倒方的数据框in_df,返回的是被倾倒方在该情况下所接受的各个订单的报价和数量,需要注意这几点:(1)双方都是按照价格从高到低排列的 (2)倾倒方的所有价格和数量都需要被满足,我们调用递归来解决,结果就是在deal_df中会有一对多的关系(倾倒方为一,被倾倒方为多),这需要进一步调整。
函数实现:
#out_df的字段:out_num,out_amount,out_price,out_is_done
#in_df的字段:in_num,in_amount,in_price,in_is_done
#从out_df向in_df倾倒数据
#调整列名的部分放在函数之外
def pull(out_df,in_df):
deal_df = pd.DataFrame(columns=['amount','price','out_num','in_num'])
start_in_df = in_df
while True:
#类似于match_making函数,首先取出未完成交易的数据
out_df = out_df[out_df.out_is_done==False]
in_df = in_df[in_df.in_is_done==False]
#重置索引
in_df.index = range(len(in_df))
out_df.index = range(len(out_df))
#取出第一行数据
in_num = in_df.loc[0].in_num
in_price = in_df.loc[0].in_price
in_amount = in_df.loc[0].in_amount
out_num = out_df.loc[0].out_num
out_price = out_df.loc[0].out_price
out_amount = out_df.loc[0].out_amount
#开始询价
#如果倾倒方的数量要小于被倾倒方的数量,则倾倒方完成倾倒
if out_amount < in_amount:
out_df.loc[0,'out_is_done']=True
in_df.loc[0,'in_amount'] = in_amount - out_amount
se= pd.Series({
'amount':out_amount,
'price':out_price,
'in_num':in_num,
'out_num':out_num
})
deal_df = deal_df.append(se,ignore_index=True)
#如果倾倒方数量要大于被倾倒方数量,则被倾倒方交易完成
elif out_amount>in_amount:
in_df.loc[0,'in_is_done'] = True
out_df.loc[0,'out_amount'] = out_amount - in_amount
se= pd.Series({
'amount':in_amount,
'price':out_price,
'in_num':in_num,
'out_num':out_num
})
deal_df = deal_df.append(se,ignore_index=True)
else:
#数量相等则双方均改变状态
out_df.loc[0,'out_is_done']=True
in_df.loc[0,'in_is_done'] = True
se= pd.Series({
'amount':out_amount,
'price':out_price,
'in_num':in_num,
'out_num':out_num
})
deal_df = deal_df.append(se,ignore_index=True)
#一般情况下结束的条件是:倾倒方全部完成而被倾倒方还有剩余空间
if(len(out_df)==1 and out_df.out_is_done.all()):
break
#如果倾倒方没有倒完但是被倾倒方已经满了,则将倾倒方的剩余数据
#重置为为新的out_df,同时用最初的in_df重新倾倒
if (len(in_df)==1 and in_df.in_is_done.all()):
in_df = start_in_df
#调用递归
pull(out_df,in_df)
return deal_df尝试运行的结果(让倾倒方的总意愿数量大于被倾倒方的总意愿数量,从而看看这种情况下能否按照我们预期地实现好几轮的倾倒):
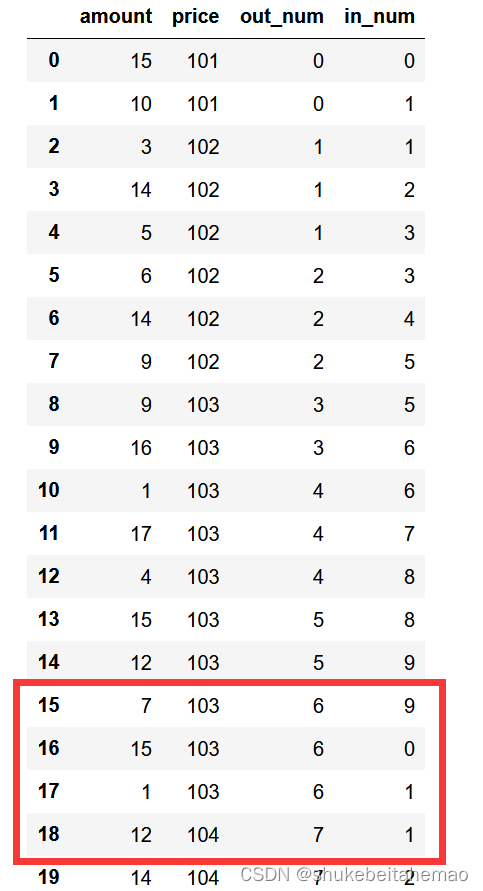
可以看到的确如我们所愿实现了一对多的关系,接下来是要整理多方(被倾倒方)的数据
step 3-2 计算某一方在两种议价能力下的报价和数量:make_balance
函数实现:
# 接受某一方的数据以及它作为被倾倒方所产生的deal_df
# 输出它产生的在两种情况下所接受的对应价格和数量
def make_balance(origin_df,deal_df):
#origin_df应该整理成和in_num一样的字段
deal_df['deal_value'] = deal_df.amount*deal_df.price
middle_df = deal_df.groupby('in_num').sum() #对groupby对象应用聚合函数
middle_df['avg_price'] = middle_df.deal_value/middle_df.amount
#in_num字段在groupy后变成index,这里需要还原
middle_df = middle_df.reset_index()
#在拼接的时候有可能会出现middle_df中不包括全部的个例的情况,这时候就会有NA,填充为0,即视为在被倾倒的情况下该个例没有机会产生交易
final_df = pd.merge(left=origin_df,right=middle_df,on='in_num',how='left').fillna(0)
# print(final_df)
return final_df结果(只展示重要的列):
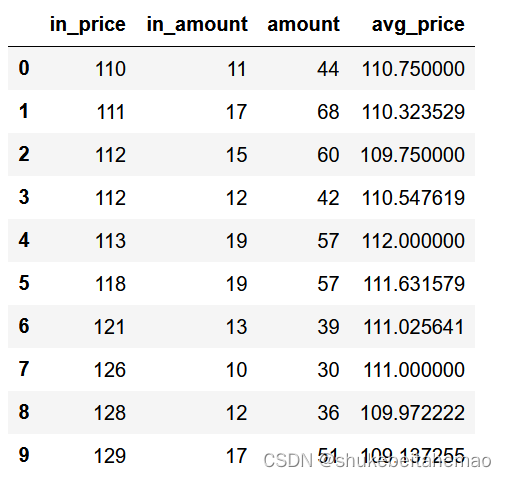
step 3-3 最终函数实现match_middle()
通过对上述函数的调用,实现设想的逻辑。它接受一个need_df,一个supply_df和一个议价能力的系数power,返回最终成交的deal_df。
#最后来一个拼接
#接受两个原始的need_df,supply_df以及一个议价能力系数
def match_middle(need_df,supply_df,power=0.5):
#首先假设从需求方向供给方倾倒,先改列名以符合函数要求
need_df_copy = need_df
out_df = need_df_copy.rename(columns={
'need_num':'out_num',
'need_amount':'out_amount',
'need_price':'out_price',
'need_is_done':'out_is_done'
})
# print('out',out_df)
supply_df_copy = supply_df
in_df = supply_df_copy.rename(columns={
'supply_num':'in_num',
'supply_amount':'in_amount',
'supply_price':'in_price',
'supply_is_done':'in_is_done'
})
#执行倾倒
deal_df = pull(out_df,in_df)
#对两种情况进行合并
need_balance_df = make_balance(in_df,deal_df)
# print('need_balance',need_balance_df)
#然后假设从供给方向需求方倾倒
need_df_copy = need_df
in_df = need_df_copy.rename(columns={
'need_num':'in_num',
'need_amount':'in_amount',
'need_price':'in_price',
'need_is_done':'in_is_done'
})
supply_df_copy = supply_df
out_df = supply_df_copy.rename(columns={
'supply_num':'out_num',
'supply_amount':'out_amount',
'supply_price':'out_price',
'supply_is_done':'out_is_done'
})
deal_df = pull(out_df,in_df)
supply_balance_df = make_balance(in_df,deal_df)
#结合议价系数对其进行调整,产生最终两方的实际成交价格和数量
need_balance_df['final_price'] = (1-power)*need_balance_df.in_price+ power*need_balance_df.avg_price
need_balance_df['final_amount'] = (1-power)*need_balance_df.in_amount + power*need_balance_df.amount
supply_balance_df['final_price'] = power*supply_balance_df.in_price+ (1-power)*supply_balance_df.avg_price
supply_balance_df['final_amount'] = power*supply_balance_df.in_amount + (1-power)*supply_balance_df.amount
#最后调用match_making函数实现真实的交易过程
final_need_df = need_balance_df.iloc[:,[3,9,10]].rename(columns={
'in_num':'need_num',
'final_price':'need_price',
'final_amount':'need_amount'
})
final_need_df['need_is_done']=False
# print('final_need',final_need_df)
final_supply_df = supply_balance_df.iloc[:,[3,9,10]].rename(columns={
'in_num':'supply_num',
'final_price':'supply_price',
'final_amount':'supply_amount'
})
final_supply_df['supply_is_done']=False
#记得将supply顺序反过来
final_supply_df = final_supply_df.sort_values(by='supply_price',ascending=True)
# print('final_supply',final_supply_df)
res = match_making(final_need_df,final_supply_df)
return res
运行的结果(默认议价能力系数为0.5):
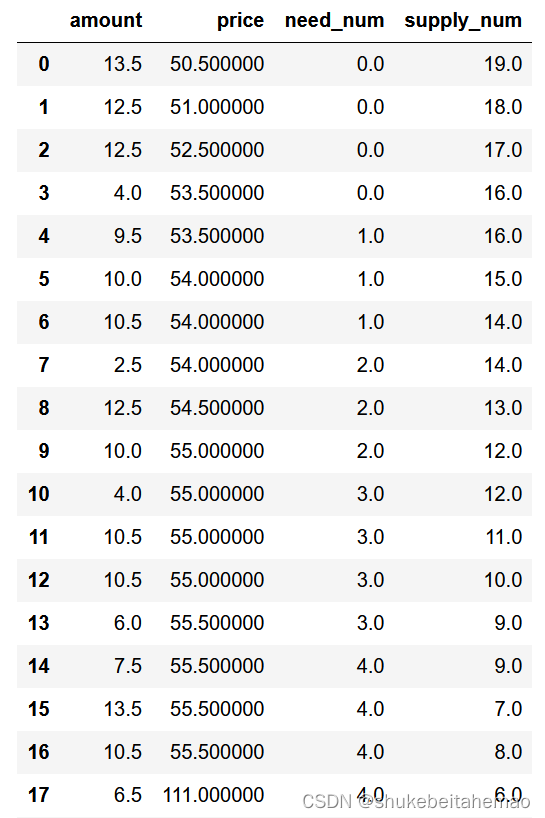
将议价能力设为0.3(需求方能力较大)的结果:
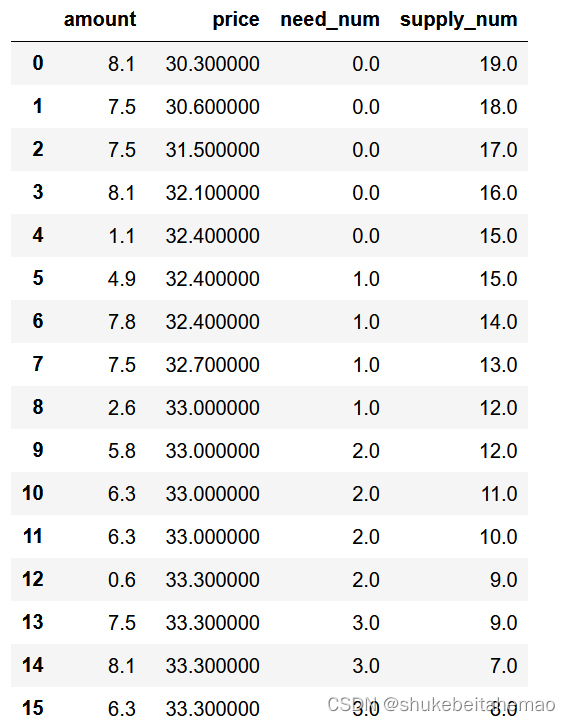
我们可以看到成交价格下降了,符合我们的预期。
反思
有益的部分和亮点:
1.通过is_done标识符结合循环实现了类似栈一样的效果
2.作为一个数据分析的项目,宁愿牺牲内存和速度,也要优先保障程序的清晰可读,所以我采取的事取出数据操作而不是直接在原表上修改
3.熟悉了递归的使用思路
4.通过议价能力系数平衡双方价格
遗留的问题:
程序中较多地使用了重新命名,有冗余;另外match_making和pull函数看起来可以进一步整合。















 1518
1518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









