







1.引言
日常生活中,数据的分布形态会对数据模拟的最终效果产生很大的影响,例如,居民收入的均值会影响到经济运行的系统性风险,同时,收入的基尼系数也会影响系统性风险(甚至影响力更大)。另外在做机器学习的时候,也需要考虑以基尼系数为指标的数据纯净度。因此,我们需要根据基尼系数来构造样本,但是python提供的抽样方法基本上是基于某种特定类型的分布的,而不是基于基尼系数的,我们的需求是:指定一个基尼系数gini_index,指定样本大小n,指定最小值min和最大值max,要求其在min-max区间内抽出n个数,这n个数的gini_index为x。 但是经过一番实际操作,我考虑的抽样方法均不能实现指定最大最小值,只能实现指定数据的均值。
2.考虑思路
2.1 概率分布函数导出法
容易想到,一个基尼系数高的数据分布可能是类似于正态分布但是其分布函数向左偏,反之则向右偏。那么某一个gini系数就对应着一个具有偏度p的正态分布概率密度函数。在x轴上截取一段x1-x2,使之对应的曲线下面积接近于1(舍掉那些概率极小的x),将这个x1-x2区间映射为min-max,就很容易依据这个函数来抽样了。但问题是我没找到构造具有某个特定偏度的正态分布函数的方法,网上的资料都是如何计算的,因此这条路只能放弃。
2.2 幂函数导出法
观察基尼系数的图示定义,基尼系数可以由洛伦兹曲线来表示:
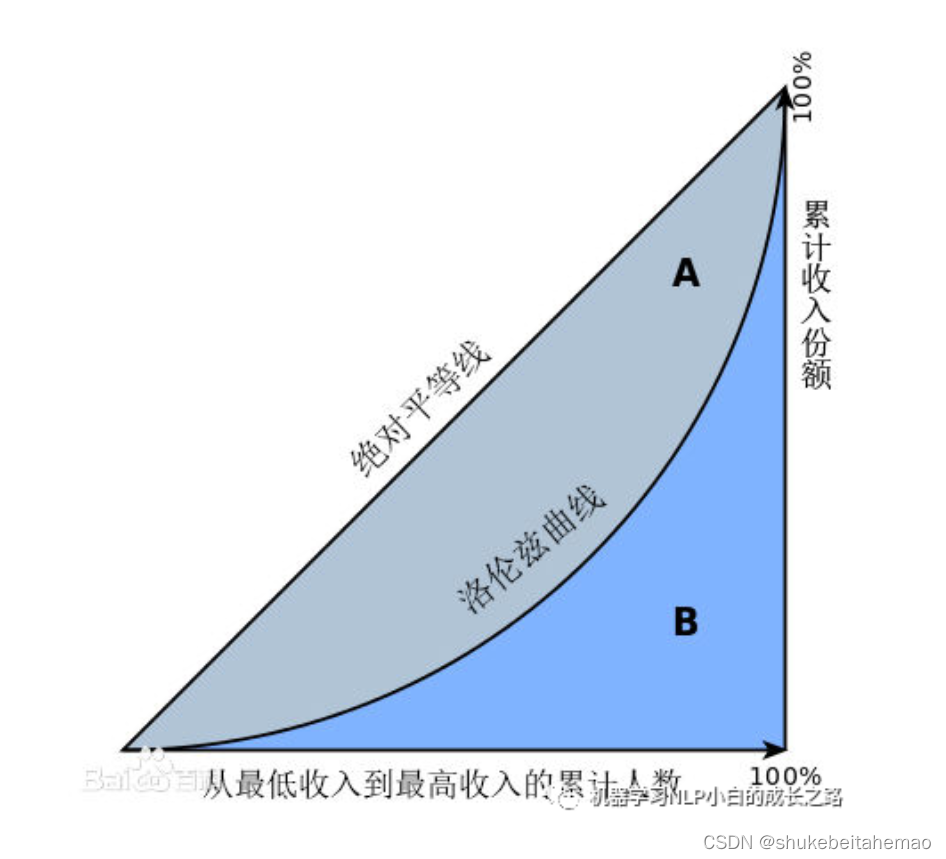
即基尼系数=图中灰色部分面积/整个三角形面积。这个形态实际上可以由一族通过点(1,1)的幂函数y=x^a来刻画,不同的a对应着不同的灰色部分面积,从而也就对应着不同的基尼系数。容易通过积分得知a和基尼系数的关系:a = (1+gini_index)/(1-gini_index),在根据指定的gini_index算出a之后,在0-1区间内均匀取n个样本点,第k个样本所占总量(样本数乘以平均值)的份额为第k个点对应的曲线高度减去第k-1个点所对应的曲线高度,从而每一个点占总量的比例就得知了,这个方法没有办法指定最大最小值,但是是容易实现的,这里就不放代码了。更让我感兴趣的第三种方法,第三种方法很笨,甚至不一定能成功抽样,但却让我觉得很有收获,我愿称之为逼近尝试法。
2.3 逼近尝试法
所谓尝试,就是不知道什么原理,就是不断瞎碰,总结一些规律;所谓逼近,就是通过一些办法减小误差,不指望通过公式一步到位构造出正确的答案。
最开始的想法是,给定均值,在均值上给一个从某种分布形态中采样的随机数,从而得到基于均值的随机数,最后算一下n个这样的随机数的gini_index,看看能否有一些规律。经过反复尝试,发现基于正态分布的随机数比较容易得出指定的gini_index:
数据 = norm(指定的样本均值,k个样本均值)*j + 样本均值
这其中的影响因素是k和j,经过观察,发现,在j取0-300的情况下,若想贴近基尼系数0.x,则k最少应该取x-1,这样我们就有很大的把握能贴近gini_index。然后我们在0-300之间遍历j值,在10%的偏差范围内,一般能够选择出在偏差范围内的j值,这样i和j就确定下来了。
在确定了i和j之后,就可以进行抽样,一次抽n个,但是抽出的结果依然不能保证真的贴近我们想要的基尼系数,也就是说,需要反复抽样以提升成功率,但究其根本还是不能完全保证抽样成功,这就是这个方法的愚蠢之处,为此,需要指定执行时间,超时则终止过程,承认抽样失败。
以下是实现的代码:
2.3.1 计算基尼系数的代码
#计算基尼系数
def gini(x):
total = 0
for i, xi in enumerate(x[:-1], 1):
# print(i,xi)
total += np.sum(np.abs(xi - x[i:]))
return total / (len(x)**2 * np.mean(x)) 2.3.2 给定样本平均数,正态分布的平均数和标准差以及样本量,令j从0遍历至300,输出此时j和gini_index的元组构成的列表。
其中,我们指定最小值为0.
def cal_j_to_gini(avg,np_a,np_d,num):
ll = []
for j in range(300):
ls = []
for i in range(num):
#在平均数的基础上加上j倍的正态分布随机数,和0取较大值
ls.append(max(np.random.normal(np_a,np_d)*j+avg,0))
gin = gini(np.array(ls)) #需要转为array形式才能为gini函数所识别
#对于每一个j值,都去看看算出来的基尼系数为多少
ll.append((j,gin))
return ll
2.3.3 在cal_j_to_gini函数执行后,从其结果中找出在偏差范围内的j值。
def funcs(cc,gini_index):
for x in cc:
if x[1]<=gini_index*1.1 and x[1]>=gini_index*0.9:
return x[0]
return 02.3.4 为了保险起见,如果一次给定的i值没有找到很好的j值,就把i加1或者减1,再试一次,输出最后的i和j
#如果funcs函数没有gini_index参数,它甚至不能引用函数里面的参数Gini_index
#如果嵌套函数的内嵌函数中有隐式的参数调用,则这个参数不能引用位于同一环境中的变量
def cccc(avg,gini_index,num):
gini_index = gini_index
cc = cal_j_to_gini(avg,avg,avg*(int(gini_index*10)-1),num)
res = funcs(cc,gini_index)
if res != 0:
return (int(gini_index*10)-1,res)
else:
cc = cal_j_to_gini(avg,avg,avg*(int(gini_index*10)-2),num)
res = funcs(cc,gini_index)
if res != 0:
return (int(gini_index*10)-2,res)
else:
cc = cal_j_to_gini(avg,avg,avg*(int(gini_index*10)),num)
res = funcs(cc,gini_index)
if res != 0:
return (int(gini_index*10),res)
else:
return (0,0)
2.3.5 合成一个最终的函数,该函数有具体的i和j,反复抽样,符合结果则成功,超时则退出。
#cccc函数能够大体上确定j值,现在根据j值来构造合理的序列
#但是第一步cccc函数无返回值也是很有可能的
#现在来正式进行构造
def get_gini_data(avg,gini_index,num):
start_time = time.time()
avg=avg
gini_index=gini_index
num = num
a=[]
j = cccc(avg,gini_index,num)
if j[0]==0 and j[1]==0:
return [0]
else:
while True:
end_time = time.time()
if end_time - start_time > 10:
print('构造超时!')
break
ls = []
for i in range(num):
ls.append(max(np.random.normal(avg,avg*j[0])*j[1]+avg,0))
gin = gini(np.array(ls))
if gin<=gini_index*1.1 and gin>=gini_index*0.9:
a = ls
break
return a
试用结果:
需要注意的是,这里实现程序的超时退出其实并不是真的完整地对程序的执行时间进行了计时,因为执行计时的时间的程序本身也在耗时。更加严格的方式是使用多线程或者多进程,即调用threading或者multiprocess模块(调用signal模块设置定时器在windows系统下是没有用的,因为windows系统不支持signal.SIGALRM信号),而我使用的是JupyterNotebook环境,它调用多线程还有点麻烦,所以还是走个捷径直接用time模块来做。
虽然不能“构造”出min-max范围内的数据,但是可以在随机数出现之后将其在min-max范围之外的数据筛掉,在上述程序中我们指定了最小值0,这个操作方式大体上是可以成功的,如果不追求一定成功的话,那我们也算是实现了最初的目标了。
3.总结
(1)数学不好就要吃大亏,要是擅长公式推导就能省下很多的尝试步骤
(2)但是拼拼凑凑,大体上也能用,解决问题的办法不止一种。















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









