







今天试验 TensorFlow 2.x , Keras 的 SimpleRNN 和 LSTM,发现同样的输入、同样的超参数设置、同样的参数规模,LSTM 的训练时长竟然远少于 SimpleRNN。
模型定义:
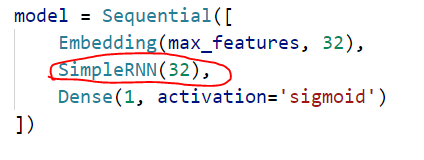
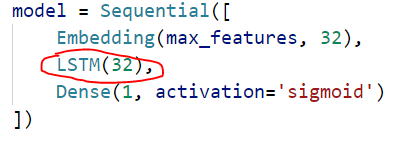
训练参数都这样传入:

我们知道,LSTM 是修正了的 SimpleRNN(我随意想出来的词,“修正”),或者说,是在 SimpleRNN 基础之上又添加了别的措施使模型能考虑到超长序列的标记之间的依赖。 缓解了梯度消失和梯度爆炸的问题。
所以,LSTM 比 SimpleRNN 是多了很多参数矩阵的,且每一步也多了一些计算。而训练过程既有前向,又有反向,不管哪个过程,理论上 LSTM都是比SimpleRNN要花更多时间的,那么为什么我在使用 TensorFlow with Keras 时会出现相反的情况呢?
训练情况(第一个 epoch):
SimpleRNN 的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5169
5169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









