







本次介绍的是怎样通过对训练数据进行缩减以及召回而加快网络训练速度,《Accelerating Deep Learning with Shrinkage and Recall》。
这篇文章给人的感受就是:想法很简单,实现的也很粗糙。但是,问题的角度比较新颖,而且感觉有很大空间可以继续挖掘。
Motivation
深度神经网络训练比较慢,原因基本可以归为2个方面:模型太大 和 数据太多。这里文章就把目光抛向了“数据”,一方面我们需要大数据来学习更多的东西和避免过拟合,另一方面大量的数据又极大地增加了训练的时间。
了解过SVM的都知道真正影响最后学习结果的其实只有一部分“支持向量”点,即SVM的训练过程使用了缩减技术,减少了实际的训练数据量。在LASSO算法中也使用了类似功能的筛选算法。
受到上述两种方法的启发,文章就设想在神经网络上进行类似的 数据缩减。
实现
整个实现非常之简单,如下图。下图红色框起来的部分就是本文算法比一般神经网络训练多的部分。

从上图可以看出,其思路就是:每一次epoch,都会计算每一个样本的误差,对误差排序,误差较小的一些样本就不再参与下一个epoch。当一个epoch中样本数量小于一定阈值时,再初始化为全部样本参与训练。这就是 缩减 和 召回 。
备注: 实际当中,这种缩减和召回的策略,文章是在batch的层次上操作的。下图的类正弦曲线,就显示了这种周期变化的训练策略:
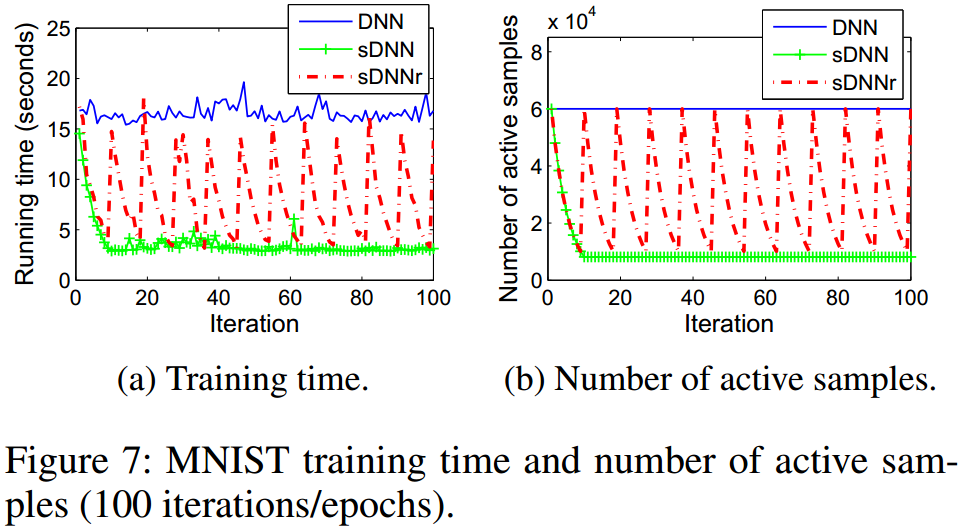
下表红色部分,是作者在MNIST上面分别测试了3种简单的神经网络,红色部分是性能变化。
















 4907
4907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









