







一篇讲如何设计轻量级网络的文章,来自Google,方法和创新不是很多,但实验太充分。不愧是谷歌,财大气粗,实验随便跑。
文章链接: 《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
文章共从三点来探讨网络加速,下面依次介绍这三点以及部分关键性的实验。
Depthwise Separable Convolution
想要明白这一节,前提还是要清楚常见的卷积实现方式,即caffe采用的im2col + GEMM。 具体可参考知乎上的一个高票回答,图示很清楚,
https://www.zhihu.com/question/28385679?sort=created。
所谓的Depthwise Separable Convolution,就是将传统的卷积按照下面的图示拆分成两个级联的卷积。
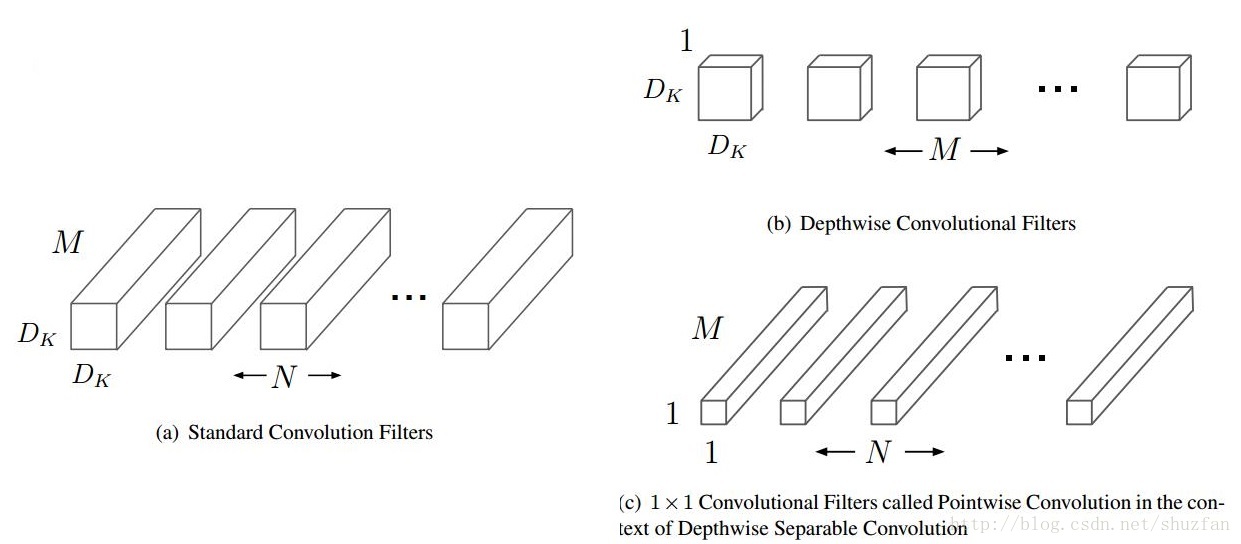
下面还是用公式说明一下:
假设输入 \(X\in R^{D_F\times D_F\times M}\), 一共有 \(N\)个 \(D_K\times D_K \times M\)大小的卷积核,再假设卷积stride=1且存在padding,即保证输出大小与输入一致。
首先,通过im2col将输入展开重排成一个大矩阵 \(\hat X\in R^{D_F^2\times D_K^2M}\), 卷积核也被整理成了一个矩阵 \(W \in R^{D_K^2M\times N}\), 于是输出直接通过GEMM矩阵乘法计算:\(output = \hat X \times W\).
至于Depthwise Separable Convolution,则是将上述的卷积拆分成两个卷积同时保证输出大小不变,具体地:
(1)拆分卷积1 如上图b, 该卷积层共有 \(M\) 个 \(D_K\times D_K\times 1\)的卷积核。 M是输入feature map的通道数,注意这里的卷积计算采用了类似于caffe中的Group操作。即第\(M_i\) 个卷积核只对输入feature map的第 \(i\) 个通道进行卷积。 最后的输出和输入的大小一致;
(2)拆分卷积2 如上图c,为了使得输出通道数为N,这里采用 \(N\) 个 \(1\times 1\times M\) 卷积,最后的输出变为 \(D_F\times D_F\times N\)。
通过这种操作,acc只下降了1%,但参数量和计算量都得到了大幅下降:

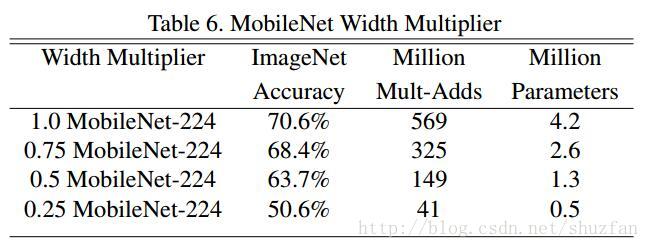
Width Multiplier: Thinner Models
增加了一个超参数 \(\alpha \in[0,1]\) 来控制feature map的通道数,\(alpha\) 越小,则模型越小。
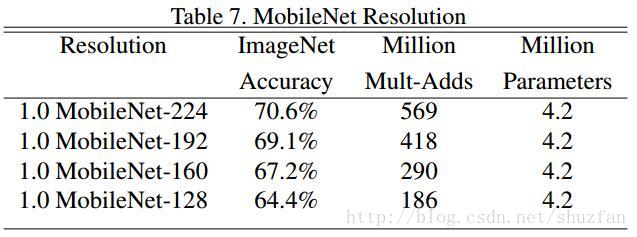
Resolution Multiplier: Reduced Representation
增加了一个超参数 \(\rho\) 来控制输入图像的分辨率,\(\rho\) 越小,则输入图像越小。
Experiments
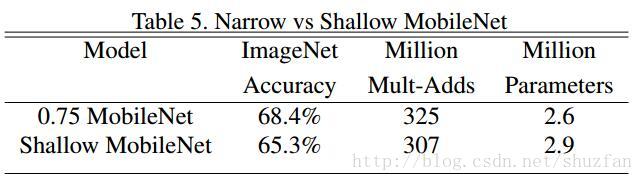
(1)网络变深往往比网络变宽带来的效果好。
如下图,Shallow表示砍掉几层网络,0.75表示每层的feature map的通道数只有原来的75%.
(2) 网络性能和计算量呈现Log线性关系。
如下图,横坐标表示 乘加计算量。
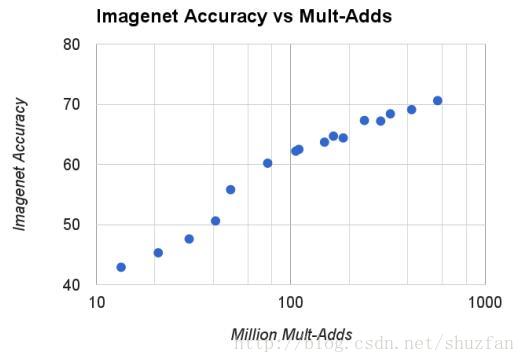
(3) 参数量、分辨率与模型性能的关系


















 1727
1727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









