







FSRCNN仍然是由港中文大学的Dong Chao, Tang XiaoOu等人做出来的文章,是SRCNN(将CNN引入超分辨率处理的开山之作)之后的又一力作。
该文章发表在CVPR2016上的文章,声称能在CPU上进行实时处理视频超分辨率。
最近发现论文写作真的跟作者风格很有关,Tang的ScSR,SRCNN,FSRCNN写得都很通俗易懂,让人有种恍然大悟的感觉。不过在CNN之前的一些传统SR method,Elad.M大牛写的文章就很晦涩,经常得反复看才能懂=。=
论文链接:https://arxiv.org/abs/1608.00367
项目首页:http://mmlab.ie.cuhk.edu.hk/projects/FSRCNN.html
FSRCNN改进之处
- 并不是将三次插值后的图像当做输入,而是直接将LR图像丢入到网络中,最后选用deconv进行放大
- 在映射Layer进行了改进,先shrink再将其复原
- 更多的映射layer和更小的kernel
- 共享其中的mapping layer,如果需要训练不同的upscale model,最后仅需要fine-tuning最后的deconvLayer
问题:在SRCNN中到底是什么拖慢了重建速度呢?
1.一般网络都直接对Interpolated LR投入到网络中,这便带来复杂的计算开销,假设要放大n倍,那么计算复杂度则上升到了n^2。
2. 非线性层映射的参数太过臃肿。
解决办法:
1. 取消ILR输入,而是采用LR输入,在最后引用deconv
2. 改进mapping layer
SRCNN和FSRCNN的对比图例:
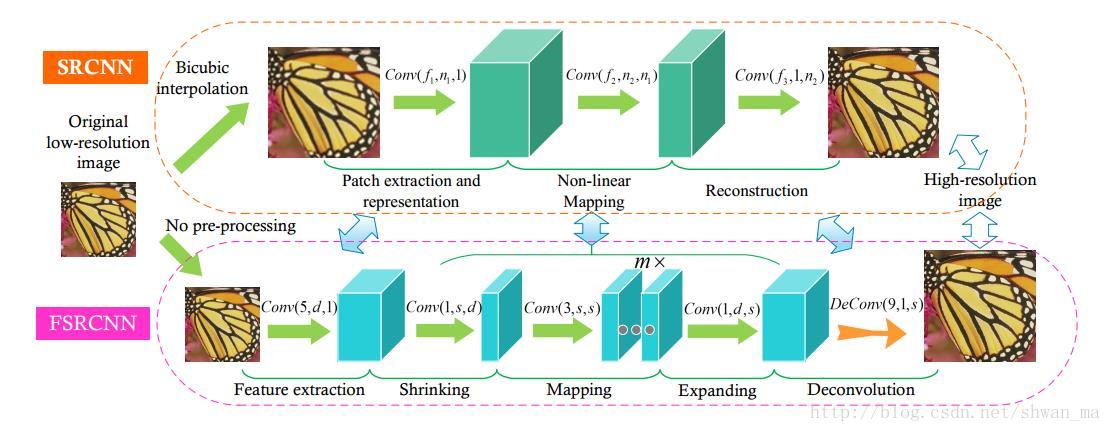
可以看到3个明显不同的地方:
First, FSRCNN adopts the original low-resolution image as input without bicubic interpolation. A deconvolution layer is introduced at the end of the network to perform upsampling
Second, The non-linear mapping step in SRCNN is replaced by three steps in FSRCNN, namely the shrinking, mapping, and expanding step.
Third, FSRCNN adopts smaller filter sizes and a deeper network structure.
FSRCNN结构
这部分作者介绍的很详细,如何调参说的很清楚,先赞一个。
1.Feature extraction
在SRCNN中,feature extraction选的kernel size 为9,然而SRCNN是针对ILR(插值后的低分辨率图像)进行操作的。而FSRCNN则是对LR进行操作,因此在选取kernel的时候,可以选取小的一点。作者选取为5x5
2.Shrinking
在mapping过程中,一般是将LR feature进行map到HR feature中,因此LR feature maps的维数一般非常高。作者通过选取1x1的卷积核进行降维,从而减少后面的计算量。
3.Non-linear mapping
在SRCNN中,作者选取了一个5x5的map layer,然而5x5会带来比较大的计算量,作者将选取3x3的kernel,通过m个3x3的卷积layer进行串联。
4.Expanding
作者发现低维度的HR dimension带来的重建效果并不是特别好,因此作者通过1x1的卷积layer,对HR dimension进行扩维,类似于Shringk的反操作。
5.Deconvolution
转置卷积则是实行上采样操作。这个操作可以看作是conv的逆操作,因为stride=k时的cov卷积操作会将feature map缩水k倍。所以stride为k的deconv则会将feature map进行放大k倍。
6. PRelu
作者定义了一个激活函数PRelu activation function as f(xi) =max(xi; 0) + aimin(0; xi),
where xi is the input signal of the activation f on the i-th channel,
and ai is the coefficient of the negative
We choose PReLU mainly to avoid the“dead features” [11] caused by zero gradients in ReLU.
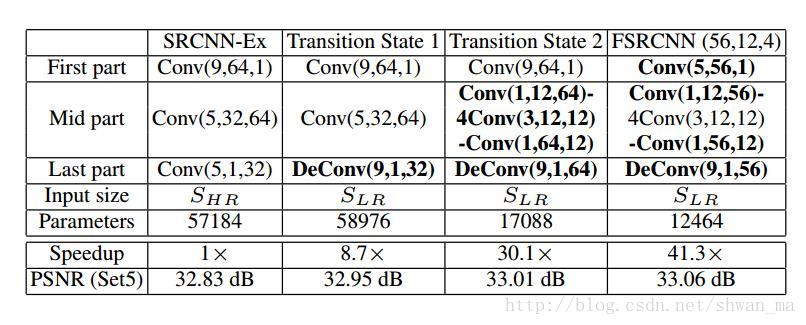
FSRCNN参数表:
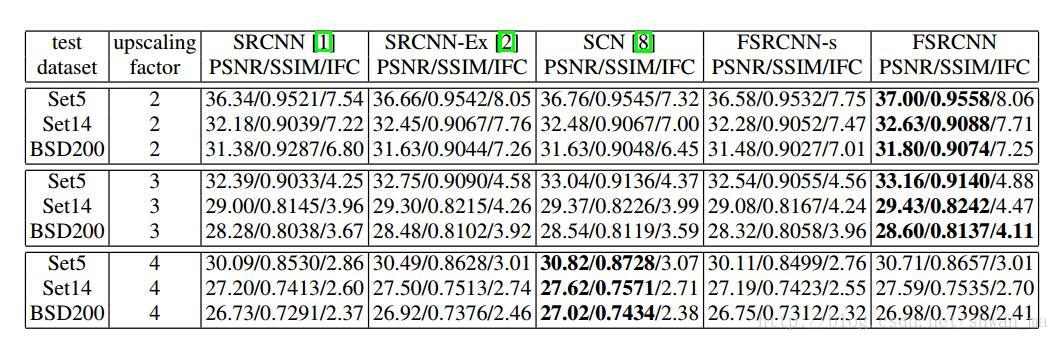
实验结果:
训练集:之前传统SR method基本都在Set91上训练,但是对CNN来说,Set91并不够去训练大的网络结构。由于BSD500是jpeg格式,存在压缩所以也不适合做训练dataset。本文提出general-100 + Set91进行充当训练集。并且进行数据增强,1)downscale 0.9, 0.8, 0.7 and 0.6。 2) Rotation 90,180,270。因此我们将会得到20倍的训练数据。
测试集和validation: Set5 [15], Set14[9] and BSD200 [25] dataset for testing,Another 20 images from the validation set of the BSD500 dataset are selected for validation















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









