







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在第 6 章“理解循环网络”中,我们概述了几种类型的循环模型,具体取决于输入-输出组合。其中之一是间接多对多或序列对序列(seq2seq),其中输入序列被转换为另一个不同的输出序列,不一定与输入具有相同的长度。机器翻译是最流行的 seq2seq 任务类型。输入序列是一种语言的句子的单词,输出序列是翻译成另一种语言的同一个句子的单词。比如我们可以翻译英文序列旅游景点到德国旅游景点。不仅输出句子的长度不同,而且输入和输出序列的元素之间没有直接对应关系。特别地,一个输出元素对应于两个输入元素的组合。
使用单个神经网络实现的机器翻译称为神经 机器翻译( NMT )。其他类型的间接多对多任务包括语音识别,我们采用不同时间范围的音频输入并将它们转换为文本转录,问答聊天机器人,其中输入序列是文本问题的单词和输出序列是该问题的答案和文本摘要,其中输入是文本文档,输出是文本内容的简短摘要。
在本章中,我们将介绍注意力机制——一种用于 seq2seq 任务的新型算法。它允许直接访问输入序列的任何元素。这与循环神经网络( RNN ) 不同,后者将整个序列总结在一个隐藏状态向量中,并将最近的序列元素优先于旧的序列元素。
本章将涵盖以下主题:
- 介绍 seq2seq 模型
- 关注 Seq2seq
- 了解transformers
- Transformer 语言模型:
- BERT
- Transformer-XL
- XLNet
介绍 seq2seq 模型
Seq2seq 或编码器-解码器(参见https://arxiv.org/abs/1409.3215https://arxiv.org/abs/1409.3215上的神经网络的序列到序列学习),模型使用 RNN 的方式特别适合解决具有间接多对多关系的任务输入和输出。在另一篇开创性论文《 Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》中也提出了类似的模型(更多信息请访问https://arxiv.org/abs/1406.1078)。下面是 seq2seq 模型的示意图。输入序列 [ A , B , C , <EOS>] 被解码为输出序列 [ W , X , Y , Z , <EOS> ]:
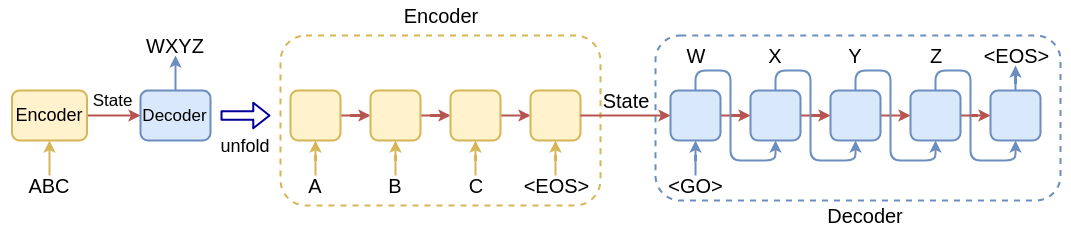
该模型由两部分组成: 编码器 和解码器。以下是推理部分的工作原理:
- 编码器是一个 RNN。原始论文使用 LSTM,但 GRU 或其他类型也可以。就其自身而言,编码器以通常的方式工作——它读取输入序列,一次一个步骤,并在每一步之后更新其内部状态。一旦到达特殊的<EOS>(序列结束)符号,编码器将停止读取输入序列。如果我们假设我们使用文本序列,我们将使用词嵌入向量作为每一步的编码器输入,<EOS>符号表示句子的结束。编码器输出被丢弃并且在 seq2seq 模型中没有任何作用,因为我们只对隐藏的编码器状态感兴趣。
- 编码器 完成后,我们将向解码器发送信号,以便它可以使用特殊的 <GO> 输入信号开始生成输出序列。编码器也是一个 RNN(LSTM 或 GRU)。编码器和解码器之间的链接是最近的编码器内部状态向量h t(也称为思想向量),它在解码器的第一个步骤中作为递归关系提供。解码器在步骤t+1的输出y t+ 1是输出序列的一个元素。我们将在步骤t+2将其用作输入,然后我们将生成新的输出,依此类推(这种类型的模型称为自回归 )。在文本序列的情况下,解码器输出是词汇表中所有单词的 softmax。在每一步中,我们选取概率最高的单词,并将其作为下一步的输入。一旦<EOS> 成为最可能的符号,解码就完成了。
模型的训练是有监督的,模型需要既知道输入序列又知道其对应的目标输出序列(例如,多语言的相同文本)。我们将输入序列提供给解码器,生成思想向量ht,并使用它来启动解码器的输出序列生成。但是,解码器使用了一种称为教师强制的过程——步骤t的解码器输入不是步骤t-1的解码器输出。相反,步骤t的输入始终是步骤t-1目标序列中的正确字符。例如,假设直到步骤t的正确目标序列是 [ W, X , Y ],但当前解码器生成的输出序列是 [ W , X , Z ]。使用教师强制,步骤t+1的解码器输入将是Y而不是Z。换句话说,解码器学习在给定目标值 [..., t] 的情况下生成目标值 [t+1, ...]。我们可以这样想:解码器的输入是目标序列,而它的输出(目标值)是相同的序列,但向右移动了一个位置。
总而言之,seq2seq 模型通过将输入序列编码为固定长度的状态向量,然后使用该向量作为基础来生成输出序列,从而解决了输入/输出序列长度变化的问题。我们可以通过说它试图最大化以下概率来形式化这一点:
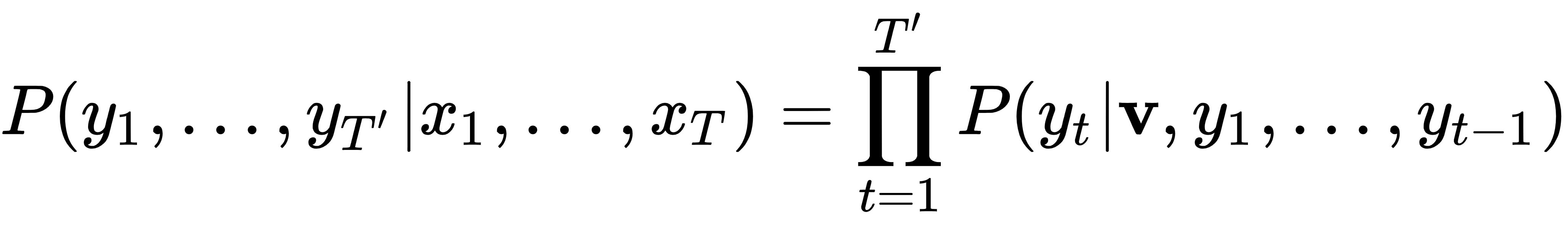
这等效于以下内容:
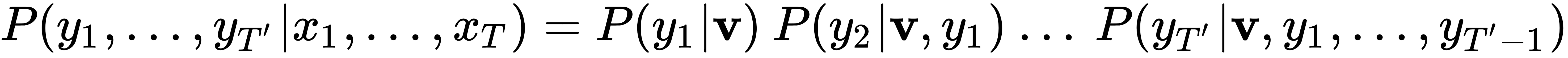
让我们更详细地看一下这个公式的元素:
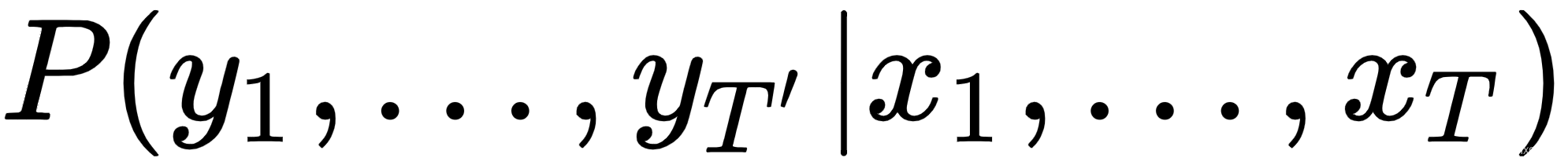 是条件概率,其中
是条件概率,其中 是长度为 T 的输入序列,
是长度为 T 的输入序列, 是长度为T'的输出序列。
是长度为T'的输出序列。 - 元素v 是输入序列(思想向量)的定长编码。
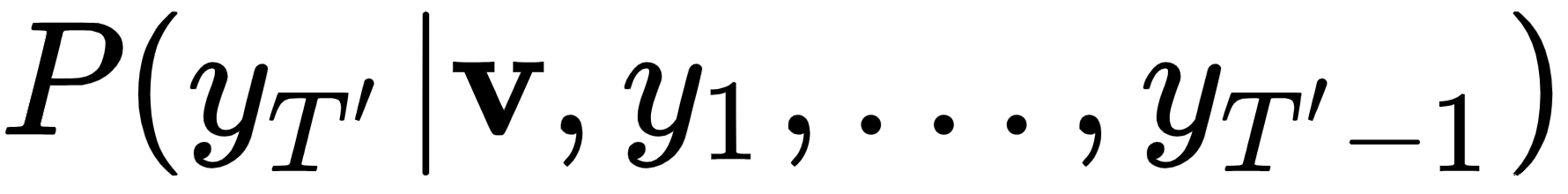 是给定先前单词y以及向量v的输出单词y T'的概率。
是给定先前单词y以及向量v的输出单词y T'的概率。
原始的 seq2seq 论文介绍了一些 技巧 来增强模型的训练和性能:
- 编码器和解码器是两个独立的 LSTM。在 NMT 的情况下,这使得使用相同的编码器训练不同的解码器成为可能。
- 该论文作者的实验表明,堆叠 LSTM 的性能优于单层 LSTM。
- 输入序列被反向馈送到解码器。例如,ABC -> WXYZ将变为CBA -> WXYZ。没有明确解释为什么会这样,但作者分享了他们的直觉:由于这是一个逐步的模型,如果序列是正常顺序的,源句中的每个源词将与其对应的源词相去甚远输出句子中的单词。如果我们反转输入序列,输入/输出词之间的平均距离不会改变,但第一个输入词将非常接近第一个输出词。这将有助于模型在输入和输出序列之间建立更好的通信。
- 除了<EOS>和<GO>之外,该模型还使用了以下两个特殊符号(我们已经在第 7 章“理解循环网络”的实现文本分类部分中遇到过它们):
- -未知:它用于替换稀有单词,以使词汇大小不会太大。
- <PAD>:出于性能原因,我们必须使用固定长度的序列来训练模型。然而,这与现实世界的训练数据相矛盾,其中序列可以具有任意长度。为了解决这个问题,较短 的序列用特殊的 <PAD> 符号填充。
现在我们已经介绍了基本的 seq2seq 模型架构,我们将学习如何使用注意力机制对其进行扩展。
Seq2seq with attention
解码器必须仅 根据思想向量生成整个输出序列。为此,思想向量必须对输入序列的所有信息进行编码;然而,编码器是一个 RNN,我们可以预期它的隐藏状态将携带更多关于最新序列元素的信息,而不是最早的。使用 LSTM 单元并反转输入会有所帮助,但不能完全阻止它。正因为如此,思想向量成为了瓶颈。因此, seq2seq 模型适用于短句,但长句的性能下降。
Bahdanau attention
我们可以借助注意力机制 (参见https://arxiv.org/abs/1409.0473上的联合学习对齐和翻译的神经机器翻译)解决这个问题,这是 seq2seq 模型的扩展,它提供了一种方法解码器与所有编码器隐藏状态一起工作,而不仅仅是最后一个。
除了解决瓶颈问题外,注意力机制还有其他一些优势。一方面,立即访问所有先前的状态有助于防止梯度消失问题。它还允许对 结果进行一些解释,因为我们可以看到解码器关注的输入部分。
下图显示了注意力是如何工作的: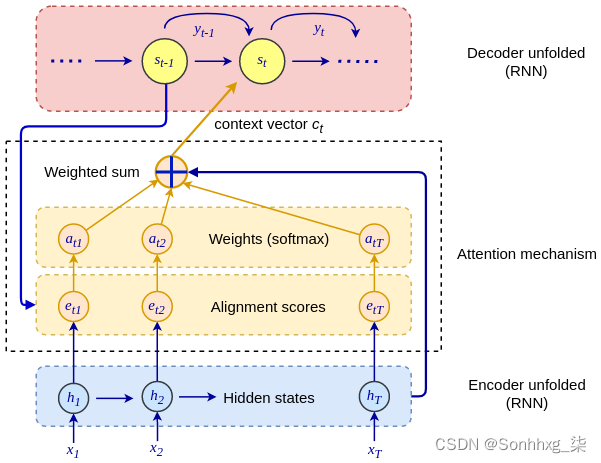
别担心——它看起来比实际更可怕。我们将从上到下浏览此图:注意力机制通过在编码器和解码器之间插入一个额外的上下文向量c t来工作。在时间t的隐藏解码器状态s t现在不仅是隐藏状态和解码器在步骤t-1输出的函数,而且是上下文向量c t的函数:
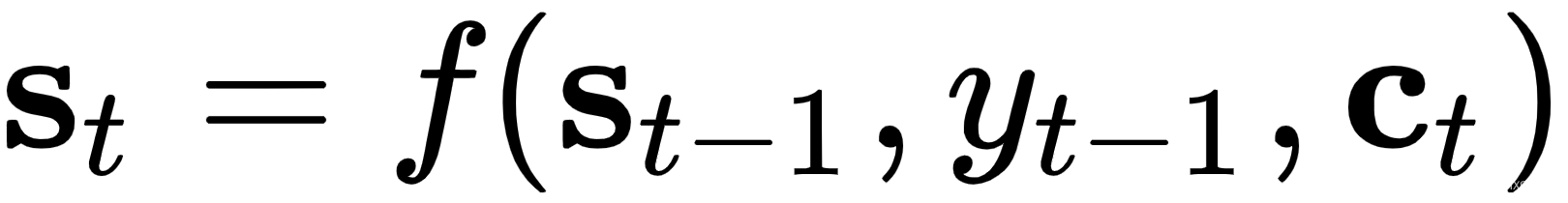
每个解码器步骤都有一个唯一的上下文向量,一个解码器步骤的上下文向量只是所有编码器隐藏状态的加权和。通过这种方式,编码器可以在每个输出步骤t访问所有输入序列状态,这消除了将源序列的所有信息编码为固定长度向量的必要性,就像常规 seq2seq 模型所做的那样:
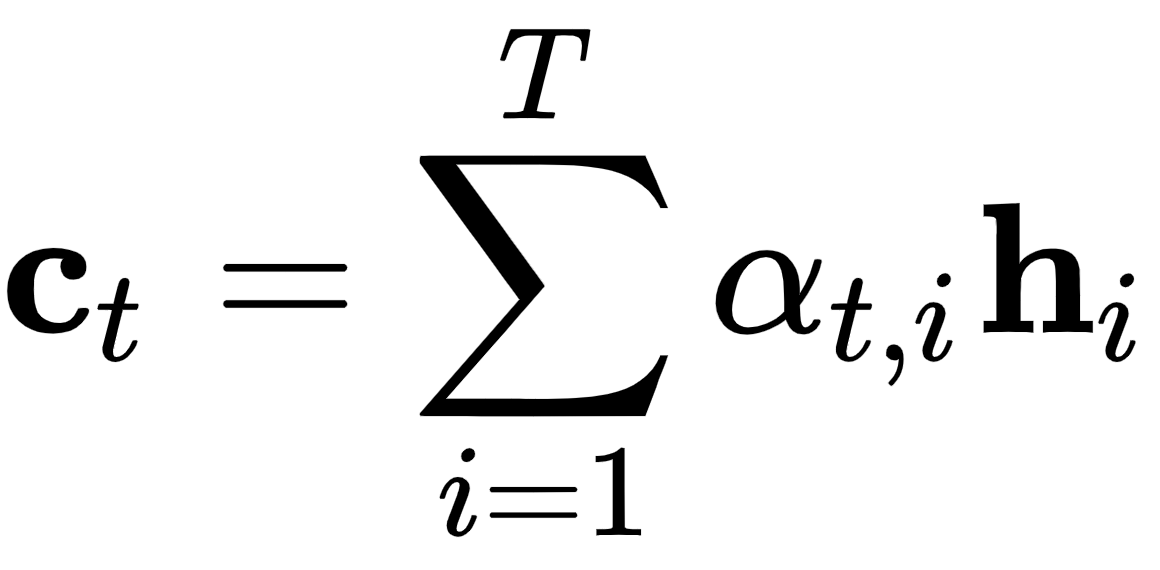
让我们更详细地讨论这个公式:
- c t是总输出T '中解码器输出步骤t的上下文向量。
- h i是T个总输入步骤中编码器步骤i的隐藏状态。
- α t,i是在当前解码器步骤t的上下文中与h i 相关的标量权重。
请注意,α t,i对于编码器和解码器步骤都是唯一的——也就是说,输入序列状态将根据当前输出步骤具有不同的权重。例如,如果输入和输出序列的长度为 10,则权重将由 10 × 10 矩阵表示,总共 100 个权重。这意味着注意力机制将根据输出序列的当前状态,将解码器的注意力(明白吗?)集中在输入序列的不同部分。如果α t,i很大,那么解码器在步骤t会非常关注h i 。
但是我们如何计算权重α t,i呢?首先,我们 应该提到,解码器在步骤t的所有α t,i之和为 1。我们可以在注意力机制之上使用 softmax 操作来实现这一点:
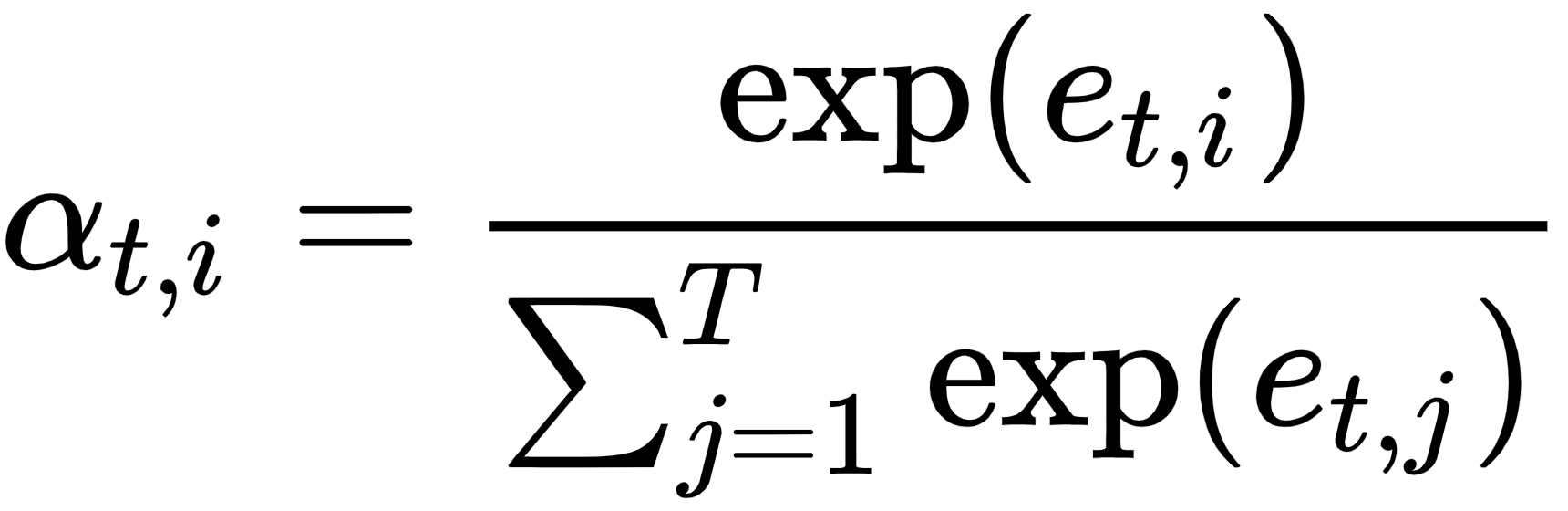
这里,e t,k 是一个对齐模型,它表示位置k附近的输入序列元素与位置t的输出匹配(或对齐)的程度。这个分数(由权重α t,i表示)基于之前的解码器状态s t-1(我们使用s t-1因为我们还没有计算s t),以及编码器状态h i:
![]()
在这里,a(而不是 alpha)是一个可微函数,它与系统的其余部分一起通过反向传播进行训练。不同的函数满足这些要求,但是论文的作者选择了所谓的additive attention,它在addition的帮助下结合了s t-1和h i 。它以两种形式存在:
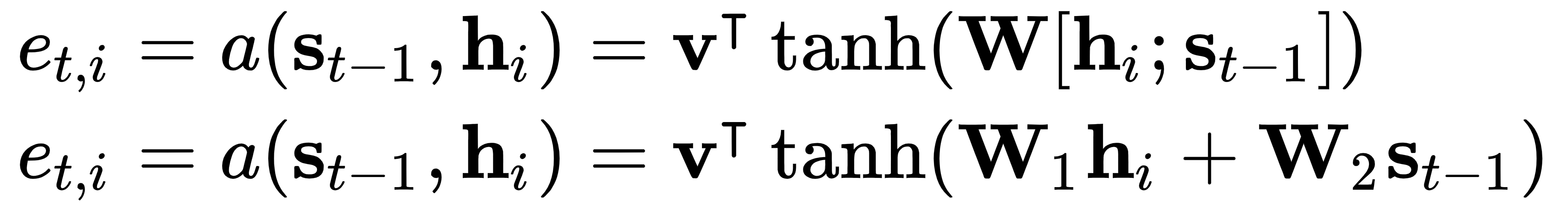
在第一个公式中,W是一个权重矩阵,应用于连接的 vect或s s t-1 a n d h i,而v是一个权重向量。第二个公式类似,但这次我们有单独的全连接层(权重矩阵W 1和W 2),我们将s t-1和h i相加。在这两种情况下,对齐模型都可以表示为具有一个隐藏层的简单前馈网络。
现在我们知道了c t和α t,i的公式,让我们将后者替换为前者:
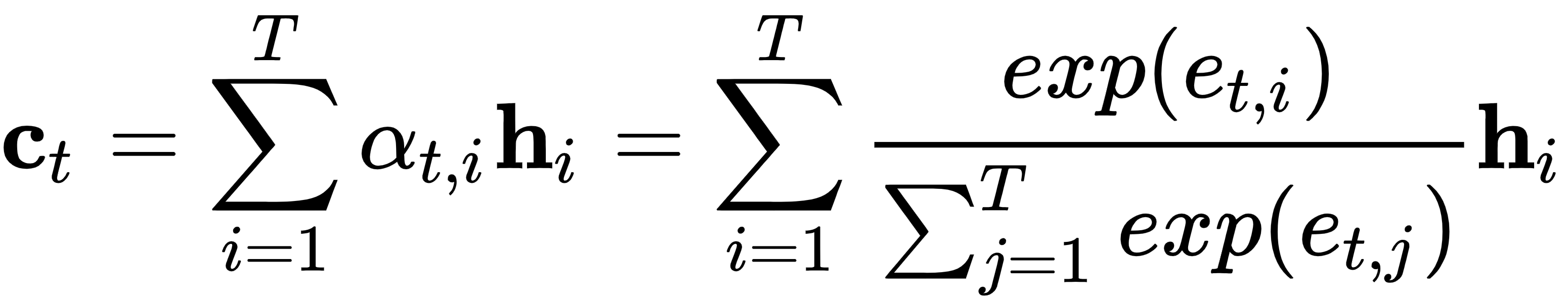
作为结论,让我们一步一步地总结注意力算法如下:
- 向编码器输入输入序列并计算隐藏状态集
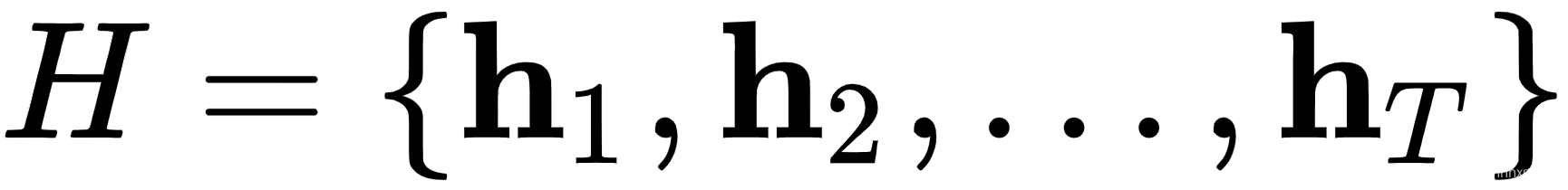 。
。 - 计算对齐分数
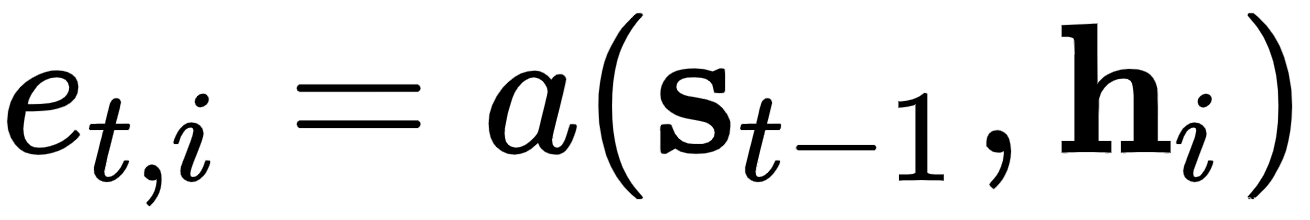 ,它使用前面步骤s t-1中的解码器状态。如果t = 1,我们将使用最后一个编码器状态h T作为初始隐藏状态。
,它使用前面步骤s t-1中的解码器状态。如果t = 1,我们将使用最后一个编码器状态h T作为初始隐藏状态。 - 计算权重
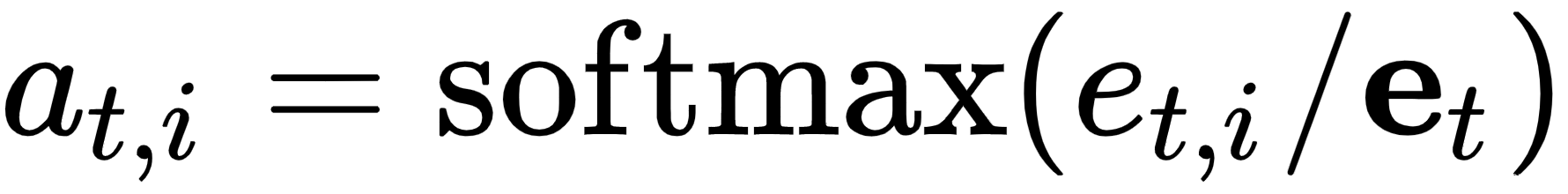 。
。 - 计算上下文向量
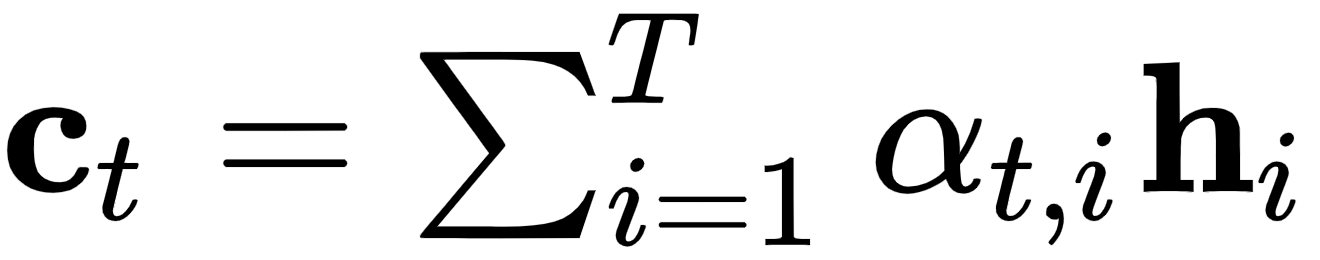 。
。 - 根据连接向量s t-1和c t以及前一个解码器输出y t-1计算隐藏状态
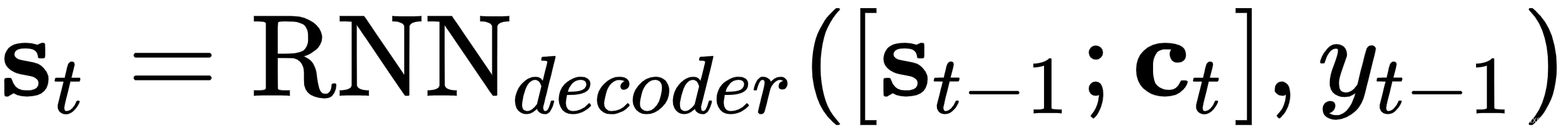 。此时,我们可以计算最终输出y t。在我们需要对下一个词进行分类的情况下,我们将使用 softmax 输出,其中W y是权重矩阵。
。此时,我们可以计算最终输出y t。在我们需要对下一个词进行分类的情况下,我们将使用 softmax 输出,其中W y是权重矩阵。 - 重复步骤 2-6,直到序列结束。
接下来,我们将介绍一种稍微改进的注意力机制,称为 Luong attention。
Luong attention
Luong attention(参见https://arxiv.org/abs/1508.04025上的基于注意力的神经机器翻译的有效方法)介绍了对 Bahdanau attention 的一些改进。最值得注意的是,对齐分数e t取决于解码器隐藏状态s t,而不是Bahdanau attention 中的 s t-1。为了更好地理解这一点,让我们比较这两种算法:
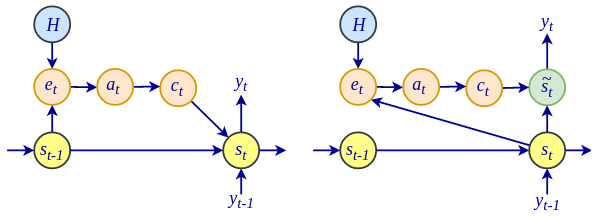
让我们一步一步地执行 Luong attention:
1.向编码器输入输入序列并计算编码器隐藏状态集![]() 。
。
2.根据前一个解码器隐藏状态s t-1和前一个解码器输出y t-1计算解码器隐藏状态![]() (但不是上下文向量)。
(但不是上下文向量)。
3.计算对齐分数![]() ,它使用当前步骤s t中的解码器状态。除了additive attention,Luong attention 论文还提出了两种乘法注意力:
,它使用当前步骤s t中的解码器状态。除了additive attention,Luong attention 论文还提出了两种乘法注意力:
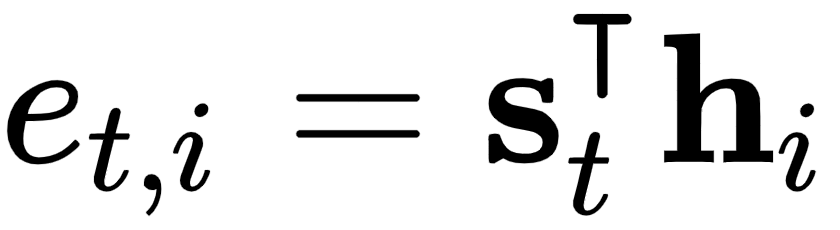 :没有任何参数的基本点积。在这种情况下,向量s和h需要具有相同的大小。
:没有任何参数的基本点积。在这种情况下,向量s和h需要具有相同的大小。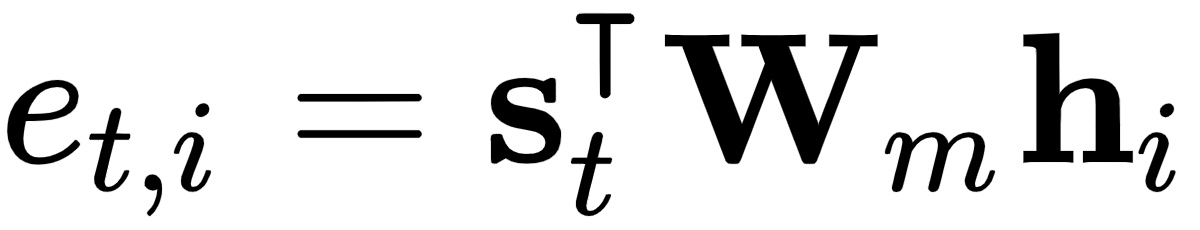 :这里,W m是注意力层的可训练权重矩阵。
:这里,W m是注意力层的可训练权重矩阵。
向量乘法 作为 对齐分数测量有一个直观的解释——正如我们在第 1 章,神经网络的基本要素中提到的,点积作为向量之间的相似性测量。因此,如果向量相似(即对齐),则相乘的结果将是一个很大的值, 注意力将集中在当前的t,i关系上。
4.计算权重![]() 。
。
5.计算上下文向量![]() 。
。
6.根据级联向量c t和s t计算向量![]() 。此时,我们可以计算最终输出y t。在分类的情况下,我们将使用
。此时,我们可以计算最终输出y t。在分类的情况下,我们将使用![]() ,其中W y是权重矩阵。
,其中W y是权重矩阵。
7重复步骤 2-7 ,直到序列结束。
接下来,让我们讨论一些更多的注意力变体。我们将从硬注意力和软注意力开始,这与我们计算上下文向量 c t的方式有关。到目前为止,我们已经描述了软注意力,其中 c t 是输入序列的所有隐藏状态的加权和。通过高度关注,我们仍然计算权重α t,i,但我们只采用 具有最大关联权重α t,imax的隐藏状态h imax 。然后,选择的状态h imax 作为上下文向量。起初,hard attention 似乎有点违反直觉——在所有这些努力使解码器能够访问所有输入状态之后,为什么再次将其限制为单个状态?然而,硬注意力首先是在图像识别任务的背景下引入的,其中输入序列表示同一图像的不同区域。在这种情况下,在多个区域或单个区域之间进行选择更有意义。与软注意力不同,硬注意力是一个随机过程,不可微分。因此,后退阶段使用一些技巧来工作(这超出了本书的范围)。
局部注意力代表了软注意力和硬注意力之间的折衷。尽管这些机制考虑了所有输入隐藏向量(全局)或仅考虑单个输入向量,但局部注意力采用一个向量窗口,围绕给定的输入序列位置,然后仅在该窗口上应用软注意力。但是我们如何根据当前的输出步长t来确定窗口p t的中心(称为对齐位置)?最简单的方法是假设源序列和目标序列大致单调对齐——即设置p t = t——遵循输入和输出序列位置与同一事物相关的逻辑。
接下来,我们将通过介绍注意力机制的一般形式来总结到目前为止所学的知识。
General attention
尽管我们已经在 NMT 的背景下讨论了注意力机制,但它是一种通用的深度学习技术,可以应用于任何 seq2seq 任务。假设我们正在全神贯注地工作。在这种情况下,我们可以将向量s t-1视为针对键值对数据库执行的查询,其中键是向量,隐藏状态h i是值。这些通常缩写为Q、K和V,您可以将它们视为向量矩阵。键Q和值VLuong 和 Bahdanau 的注意力是同一个向量——也就是说,这些注意力模型更像Q / V,而不是Q / K / V。一般注意力机制使用所有三个组件。
下图说明了这种新的普遍关注: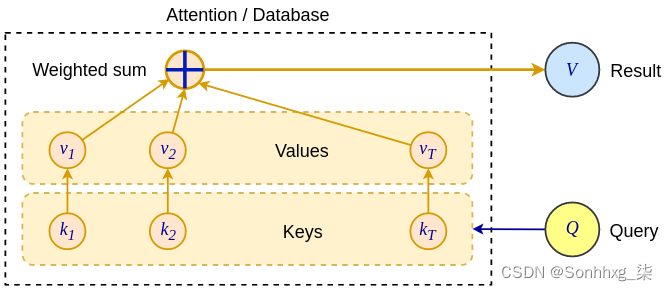
General attention
当我们对数据库执行查询 ( q = s t-1 ) 时,我们将收到一个匹配项——具有最大权重α t,imax的键k imax。隐藏在这个键后面的是向量v imax = h imax,这是我们感兴趣的实际值。但是,所有值都参与的软注意力呢?我们可以在相同的查询/键/值术语中进行思考,但查询结果不是单个值,而是所有具有不同权重的值。我们可以使用新的符号编写一个广义的注意力公式(基于上下文向量c t公式):
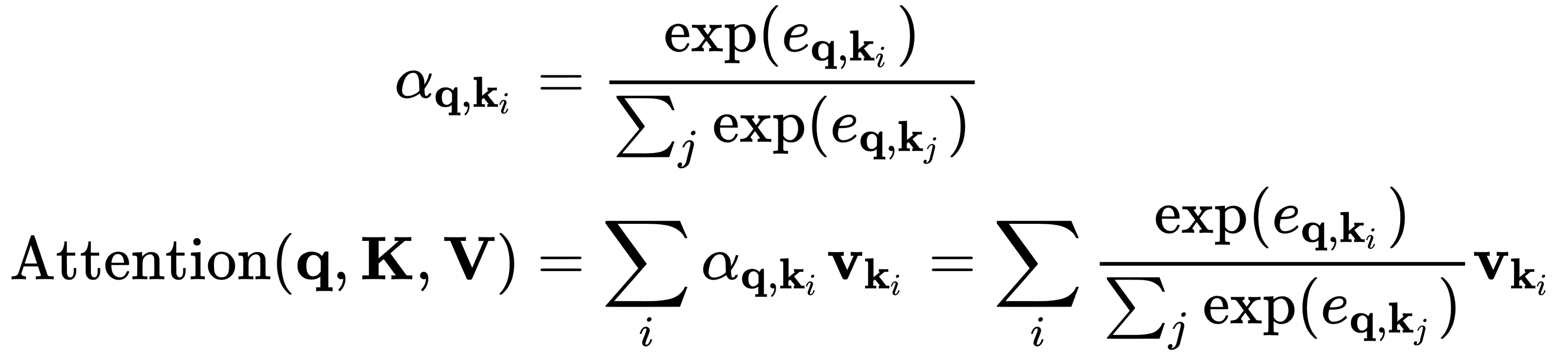
在此通用注意中,数据库的查询、键和向量不一定以顺序方式相关。换句话说,数据库不必包含不同步骤的隐藏 RNN 状态,而是可以包含任何类型的信息。我们对 seq2seq 模型背后的理论的介绍到此结束。我们将在下一节中使用这些知识,我们将在其中实现一个简单的 seq2seq NMT 示例。
用注意力实现 seq2seq
在本节中,我们将使用 PyTorch 1.3.1 在 seq2seq 注意力模型的帮助下实现一个简单的 NMT 示例。为了澄清,我们将实现一个 seq2seq 注意力模型,就像我们在介绍 seq2seq 模型 部分中介绍的那样,我们将使用 Luong attention 对其进行扩展。模型编码器将输入一种语言的文本序列(句子),解码器将输出翻译成另一种语言的相应序列。
让我们从训练集开始。它由大量法语和英语句子组成,存储在一个文本文件中。该类( torch.utils.data.Dataset的子类NMTDataset )实现了必要的数据预处理。它创建了一个词汇表,其中包含数据集中所有可能单词的整数索引。为简单起见,我们不会使用嵌入向量,而是将单词及其数值表示形式提供给网络。此外,我们不会将数据集拆分为训练和测试部分,因为我们的目标是演示 seq2seq 模型的工作。该类输出源-目标元组句子,其中每个句子由该句子中单词索引的一维张量表示。
实现编码器
接下来,让我们继续实现编码器。
我们将从构造函数开始:
class EncoderRNN(torch.nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 为输入词嵌入
self.embedding = torch.nn.Embedding(input_size, hidden_size)
# 实际的 rnn CELL
self.rnn_cell = torch.nn.GRU(hidden_size, hidden_size)入口点是self.embedding模块。它将获取每个单词的索引,并返回其分配的嵌入向量。我们不会使用预训练的词向量(例如 GloVe),但是,嵌入向量的概念是相同的——只是我们将用随机值初始化它们,然后我们将在此过程中与其余的词向量一起训练它们。模型。然后,我们有torch.nn.GRURNN 单元本身。
接下来,让我们实现该EncoderRNN.forward方法(请记住缩进):
def forward(self, input, hidden):
# 通过嵌入
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
# 通过RNN
output, hidden = self.rnn_cell(output, hidden)
return output, hidden它表示对序列元素的处理。首先,我们获得embedded词向量,然后将其输入 RNN 单元。
我们还将实现该EncoderRNN.init_hidden方法,该方法创建一个与隐藏 RNN 状态大小相同的空张量。这个张量作为序列开头的第一个 RNN 隐藏状态(请记住缩进):
def init_hidden ( self ):
return torch.zeros( 1 , 1 , self .hidden_size , device =device)现在我们已经实现了编码器,让我们继续解码器的实现。
实现解码器
让我们实现这个DecoderRNN类——一个没有注意的基本解码器。同样,我们将从构造函数开始:
class DecoderRNN(torch.nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
# 为当前输入词嵌入
self.embedding = torch.nn.Embedding(output_size, hidden_size)
# 解码器单元
self.gru = torch.nn.GRU(hidden_size, hidden_size)
# 当前输出字
self.out = torch.nn.Linear(hidden_size, output_size)
self.log_softmax = torch.nn.LogSoftmax(dim=1)它类似于编码器——我们有初始self.embedding词嵌入和self.gruGRU 单元。我们还有带激活的全连接层,它将输出序列中的预测词。 self.out self.log_softmax
我们将继续使用该DecoderRNN.forward方法(请记住缩进):
def forward(self, input, hidden, _):
# 通过嵌入
embedded = self.embedding(input).view(1, 1, -1)
embedded = torch.nn.functional.relu(embedded)
# 通过RNN cell
output, hidden = self.rnn_cell(embedded, hidden)
# 产生输出字
output = self.log_softmax(self.out(output[0]))
return output, hidden, _它从embedded作为 RNN 单元的输入的向量开始。该模块返回其新hidden状态和output表示预测单词的张量。该方法接受 void 参数_,因此它可以匹配注意力解码器的接口,我们将在下一节中实现。
用注意力实现解码器
接下来,我们将AttnDecoderRNN使用 Luong attention 实现解码器。这也可以与EncoderRNN.
我们将从AttnDecoderRNN.__init__方法开始:
class AttnDecoderRNN(torch.nn.Module):
def __init__(self, hidden_size, output_size, max_length=MAX_LENGTH,
dropout=0.1):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.max_length = max_length
# 为输入词嵌入
self.embedding = torch.nn.Embedding(self.output_size,
self.hidden_size)
self.dropout = torch.nn.Dropout(dropout)
# 注意力部分
self.attn = torch.nn.Linear(in_features=self.hidden_size,
out_features=self.hidden_size)
self.w_c = torch.nn.Linear(in_features=self.hidden_size * 2,
out_features=self.hidden_size)
# RNN
self.rnn_cell = torch.nn.GRU(input_size=self.hidden_size,
hidden_size=self.hidden_size)
# 输出词
self.w_y = torch.nn.Linear(in_features=self.hidden_size,
out_features=self.output_size)像往常一样,我们有self.embedding,但这一次,我们还将添加self.dropout以防止过度拟合。全连接层self.attn和self.w_c 层与注意力机制有关,我们将在查看AttnDecoderRNN.forward方法时学习如何使用它们,接下来会介绍。 AttnDecoderRNN.forward实现了我们在Seq2seq with attention部分中描述的 Luong 注意算法。让我们从方法声明和参数预处理开始:
def forward ( self , input , hidden , encoder_outputs):
embedded = self .embedding(input).view( 1 , 1 , - 1 )
embedded = self .dropout(embedded)接下来,我们将计算当前隐藏状态 ( hidden= s t )。请记住缩进,因为此代码仍然是AttnDecoderRNN.forward方法的一部分:
rnn_out , hidden = self .rnn_cell(embedded , hidden)然后,我们将按照乘法注意力公式计算对齐分数 ( alignment_scores= e t,i )。这里,torch.mm是矩阵乘法,encoder_outputs是编码器输出(惊喜!):
alignment_scores = torch.mm( self.attn (hidden)[ 0 ] , encoder_outputs.t())接下来,我们将在分数上计算 softmax 以产生注意力权重 ( attn_weights= a t,i ):
attn_weights = torch.nn.functional.softmax(alignment_scores , dim = 1 )然后,我们将按照注意力公式计算上下文向量 ( c_t= c t ):
c_t = torch.mm(attn_weights , encoder_outputs)接下来,我们将通过连接当前隐藏状态和上下文向量来计算修改后的状态向量 ( hidden_s_t = ![]() ):
):
hidden_s_t = torch.cat([hidden[ 0 ] , c_t] , dim = 1 )
hidden_s_t = torch.tanh( self .w_c(hidden_s_t))最后,我们将计算下一个预测词:
output = torch.nn.functional.log_softmax(self.w_y(hidden_s_t), dim=1)我们应该注意,torch.nn.functional.log_softmax在常规 softmax 之后应用对数。此激活函数与负对数似然损失函数结合使用torch.nn.NLLLoss。
最后,该方法返回output、 hidden 和attn_weights.。稍后,我们将使用attn_weights可视化输入和输出句子之间的注意力(方法AttnDecoderRNN.forward到此结束):
return output, hidden, attn_weights接下来,我们来看看训练过程。
训练和评估
接下来,让我们实现这个train功能。它类似于我们在前几章中实现的其他此类功能;但是,它考虑了输入的顺序性质和我们在Seq2eq with attention部分中描述的教师强制原则。为简单起见,我们一次只训练一个序列(大小为 1 的小批量)。
首先,我们将在训练集上启动迭代,设置初始序列张量,并重置梯度:
def train(encoder, decoder, loss_function, encoder_optimizer, decoder_optimizer, data_loader, max_length=MAX_LENGTH):
print_loss_total = 0
# 在数据集上迭代
for i, (input_tensor, target_tensor) in enumerate(data_loader):
input_tensor = input_tensor.to(device).squeeze(0)
target_tensor = target_tensor.to(device).squeeze(0)
encoder_hidden = encoder.init_hidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = torch.Tensor([0]).squeeze().to(device)编码器和解码器参数是EncoderRNN和AttnDecoderRNN(或DecoderRNN)的实例,loss_function代表损失(在我们的例子中,torch.nn.NLLLoss),encoder_optimizer并且decoder_optimizer (名称不言自明)是的实例torch.optim.Adam,并且data_loader是一个torch.utils.data.DataLoader,它包装了一个实例NMTDataset。
接下来,我们将进行实际训练:
with torch.set_grad_enabled(True):
# 将序列通过编码器并在每个步骤中存储ei
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(
input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]
# 使用 GO_token 启动解码器
decoder_input = torch.tensor([[GO_token]], device=device)
# 使用最后一个编码器隐藏状态启动解码器
decoder_hidden = encoder_hidden
# 教师强制:将目标作为下一个输入
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
loss += loss_function(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()让我们更详细地讨论一下:
- 我们将完整序列提供给编码器,并将隐藏状态保存在encoder_outputs列表中。
- GO_token我们以作为输入来启动解码器序列。
- 我们使用解码器来生成序列的新元素。遵循teacher forcing 原则,decoder每一步的输入都来自真实的目标序列decoder_input = target_tensor[di]。
- encoder_optimizer.step()我们分别用和训练编码器和解码器decoder_optimizer.step()。
与 类似train,我们有一个evaluate函数,它接受一个输入序列并返回其翻译后的对应物及其伴随的注意力分数。我们不会在这里包含完整的实现,但我们将专注于编码器/解码器部分。代替教师强制,decoder每一步的输入是上一步的输出词:
# 使用最后一个编码器隐藏状态启动解码器
decoder_input = torch.tensor([[GO_token]], device=device) # GO
# 使用最后一个编码器隐藏状态启动解码器
decoder_hidden = encoder_hidden
decoded_words = []
decoder_attentions = torch.zeros(max_length, max_length)
# 生成输出序列(与教师强制相反)
for di in range(max_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
decoder_attentions[di] = decoder_attention.data
# 获取概率最高的输出词索引
_, topi = decoder_output.data.topk(1)
if topi.item() != EOS_token:
decoded_words.append(dataset.output_lang.index2word[topi.item()])
else:
break
# 使用最新的输出词作为下一个输入
decoder_input = topi.squeeze().detach()当我们运行完整的程序时,它会显示几个示例翻译。它还将显示输入和输出序列元素之间的注意力分数图,如下所示:
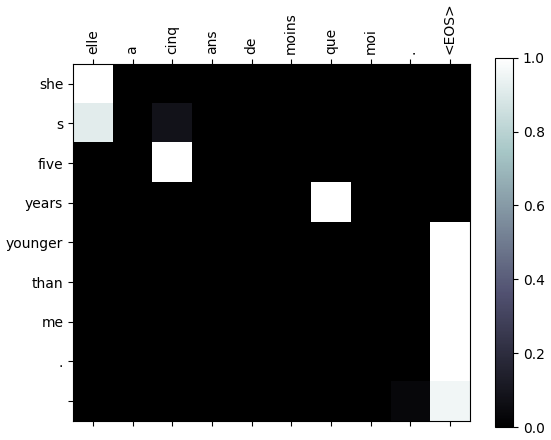
例如,我们可以看到输出词 she 将注意力集中在输入词 elle (法语中的she )上。如果我们没有注意机制,只依靠最后一个编码器隐藏状态来启动翻译,那么输出可能 很容易就是她比我小五岁。由于 elle这个词 离句子末尾最远,因此很难仅在最后一个编码器隐藏状态中对其进行编码。
在下一节中,我们将抛开 RNN,介绍 Transformer——一个完全基于注意力机制的 seq2seq 模型。
了解transformers
我们在本章的大部分时间里都在宣传注意力机制的优势。但是我们仍然在 RNN 的上下文中使用注意力——从这个意义上说,它是在这些模型的核心循环性质之上的补充。既然注意力这么好,有没有办法在没有RNN部分的情况下单独使用它?事实证明是有的。论文Attention is all you need ( https://arxiv.org/abs/1706.03762 ) 介绍了一种新的架构,称为带有编码器和解码器的转换器,它仅依赖于注意力机制。首先,我们将把注意力集中在变压器注意力(双关语)机制上。
The transformer attention
在关注整个模型之前,我们先来看看transformer attention是如何实现的: 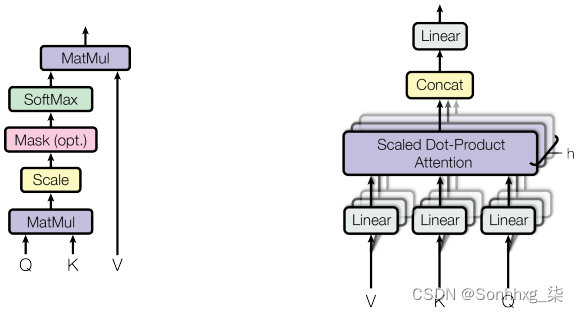
Transformer 使用点积注意力(上图的左侧图),它遵循我们在Seq2seq with attention部分中介绍的一般注意力过程(正如我们已经提到的,它不限于 RNN 模型)。我们可以用下面的公式来定义它:
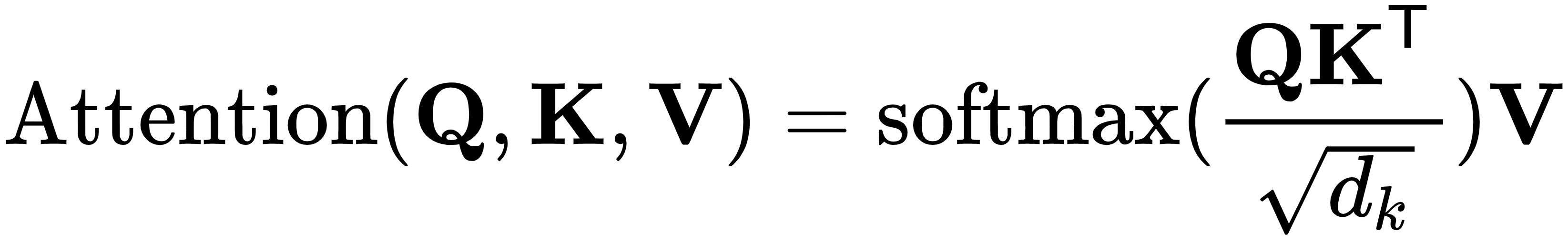
1.在实践中,我们将同时计算一组查询的注意力函数,打包在矩阵Q中。在这种情况下,键K 、值V和结果也是矩阵。让我们更详细地讨论公式的步骤:
使用矩阵乘法匹配查询Q和数据库(键K)以产生对齐分数 ![]()
假设我们想将m个不同的查询匹配到一个具有n 个值的数据库,并且查询键向量长度为 d k。然后,我们有一个矩阵 ![]() 编辑 ,每行有一个d k维查询,总共m行。类似地,我们有一个矩阵
编辑 ,每行有一个d k维查询,总共m行。类似地,我们有一个矩阵 ![]() 编辑 ,每行有一个d k维键,总共n行。然后,输出矩阵将有
编辑 ,每行有一个d k维键,总共n行。然后,输出矩阵将有 ![]() 编辑 ,其中一行包含单个查询对数据库所有键的对齐分数:
编辑 ,其中一行包含单个查询对数据库所有键的对齐分数:
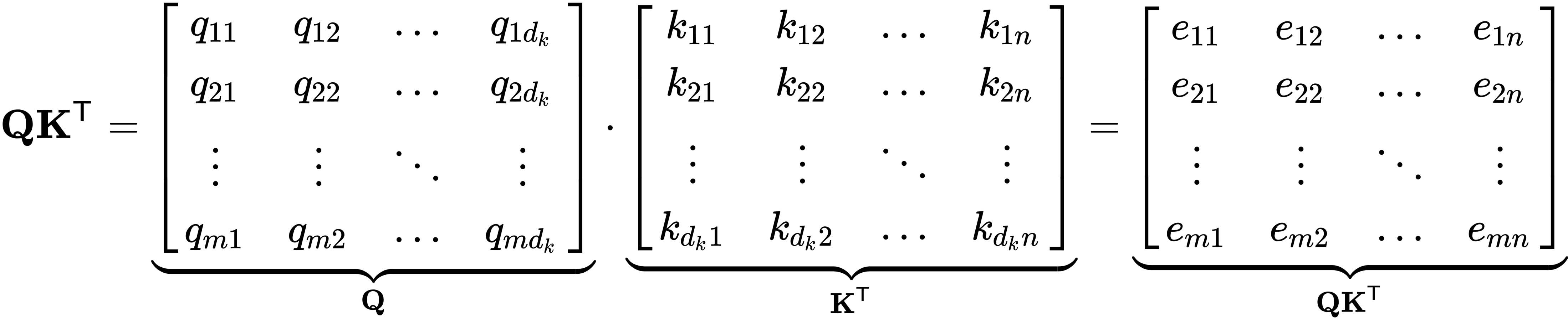
2.换句话说,我们可以在单个矩阵-矩阵乘法中将多个查询与多个数据库键匹配。在 NMT 的上下文中,我们可以以相同的方式计算目标句子的所有单词相对于源句子的所有单词的对齐分数。
用缩放对齐分数 ![]() ,其中d k是矩阵K中关键向量的向量大小,也等于 Q中查询向量的大小 (类似地,d v 是关键向量 V的向量大小) . 该论文的作者怀疑,对于较大的d k值,点积的幅度会增大,并在梯度极小的区域推动 softmax,这会导致臭名昭著的梯度消失问题,因此需要对结果进行缩放。
,其中d k是矩阵K中关键向量的向量大小,也等于 Q中查询向量的大小 (类似地,d v 是关键向量 V的向量大小) . 该论文的作者怀疑,对于较大的d k值,点积的幅度会增大,并在梯度极小的区域推动 softmax,这会导致臭名昭著的梯度消失问题,因此需要对结果进行缩放。
3.沿着矩阵的行使用 softmax 操作计算注意力分数(我们稍后会讨论掩码操作): 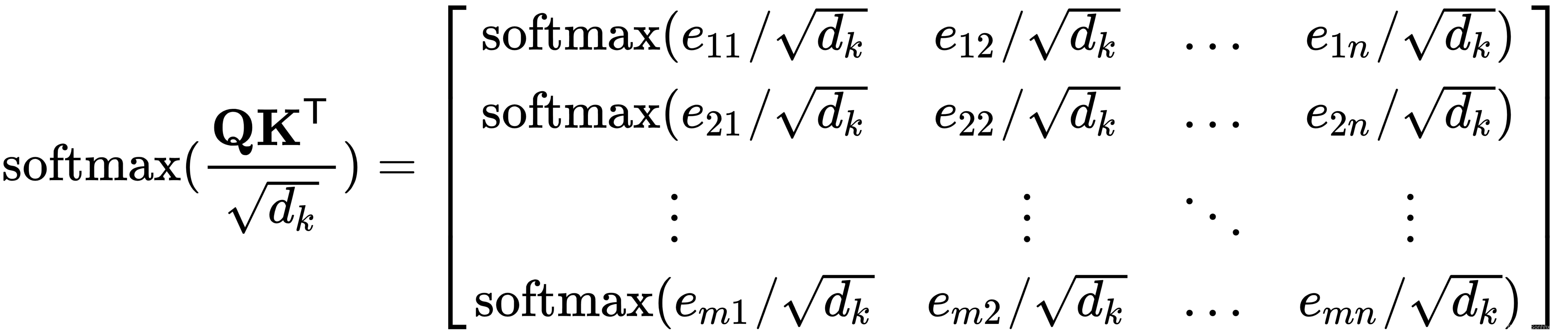
4.通过将注意力分数乘以值V来计算最终的注意力向量: 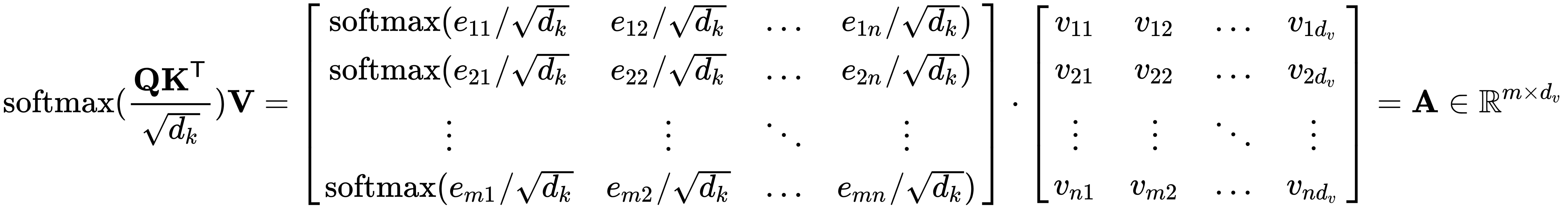
我们可以调整这种机制以同时使用硬注意力和软注意力。
作者还提出了多头注意力(参见上图的右侧图)。 我们不是使用具有d模型维键的单个注意函数,而是将键、查询和值线性投影h次,以产生这些值的h个不同的d k - 、d k -和d v -维投影。然后,我们在新创建的向量上应用单独的并行注意力函数(或头),从而产生单个d v 每个头的维输出。最后,我们连接头部输出以产生最终的注意力结果。多头注意力允许每个头关注序列的不同元素。同时,该模型将头部的输出组合在一个单一的内聚表示中。更准确地说,我们可以用下面的公式来定义它:

让我们从头开始更详细地看一下:
- 每个头接收初始Q、K和V的线性投影版本。投影分别用可学习的权重矩阵W i Q、W i K和W i V计算。请注意,我们为每个组件(Q,K,V)和每个头i设置了一组单独的权重。为了满足从d模型到d k和d v的转换,这些矩阵的维数是
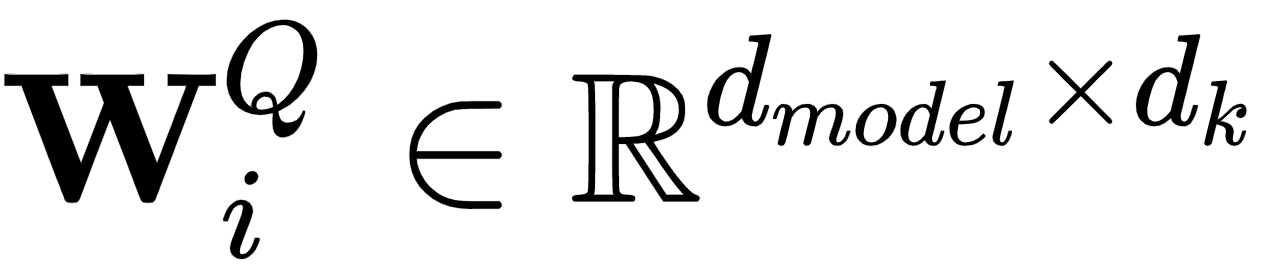 ,
, 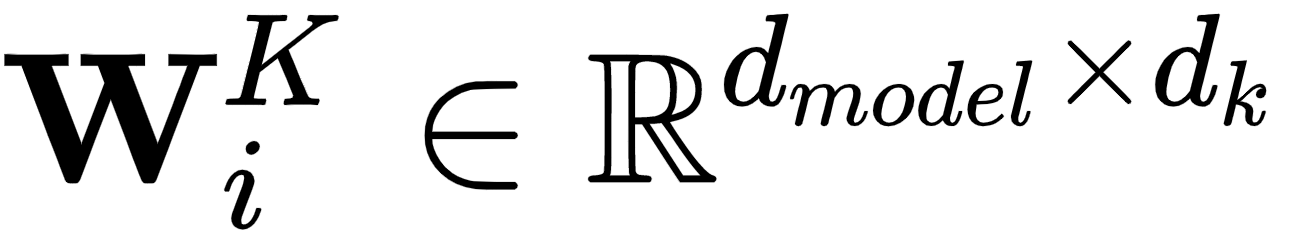 , 和
, 和 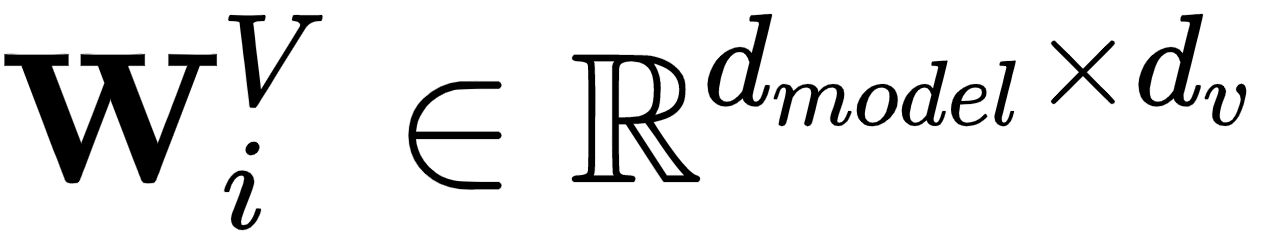 .
. - 一旦Q、K和V被转换,我们就可以使用我们在本节开头描述的常规注意力模型来计算每个头部的注意力。
- 最终的注意力结果是连接头输出头i上的线性投影(可学习权重的权重矩阵W O ) 。
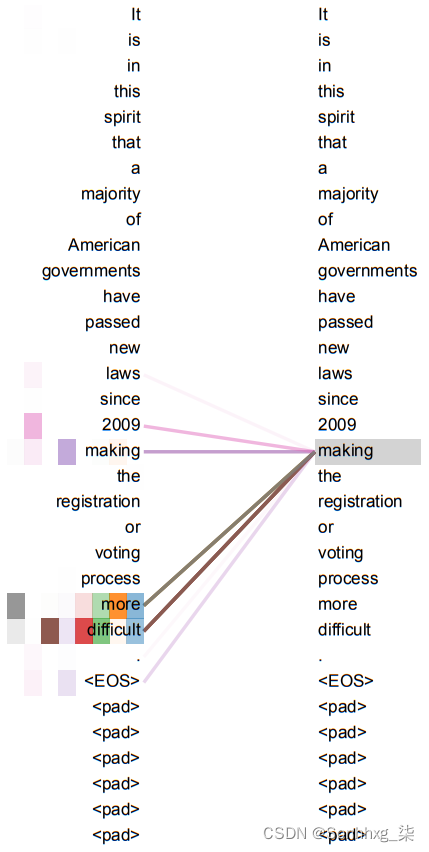
到目前为止,我们已经展示了对不同输入和输出序列的关注。例如,我们已经看到,在 NMT 中,翻译句子的每个单词都与源句子的单词相关。Transformer模型还依赖于自注意力(或内部注意力),其中查询Q与键K和向量V属于同一数据集的查询数据库。换句话说,在 self-attention 中,源和目标是相同的序列(在我们的例子中,是同一个句子)。自注意力的好处并不是立即显而易见的,因为没有直接的任务可以应用它。在直观的层面上,它可以让我们看到相同序列的单词之间的关系。例如,下图展示了动词making的多头自注意力(不同颜色代表不同的头)。许多注意力头都注意到了对制作的遥远依赖,完成了短语制作......更困难:
Transformer 模型使用 self-attention 作为编码器/解码器 RNN 的替代品,下一节将详细介绍。
The transformer model
现在我们熟悉了多头注意力,让我们关注完整的transformer模型,从下图开始:
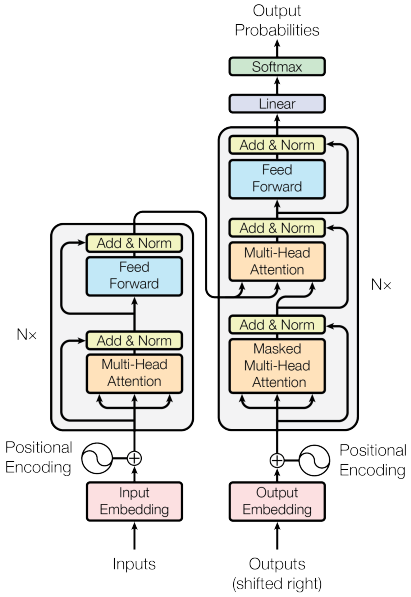
它看起来很吓人,但不要担心——它比看起来更容易。我们将从编码器(上图的左侧组件)开始:
- 它从一个单热编码词的输入序列开始,这些词被转换为d模型维嵌入向量。嵌入向量进一步乘以
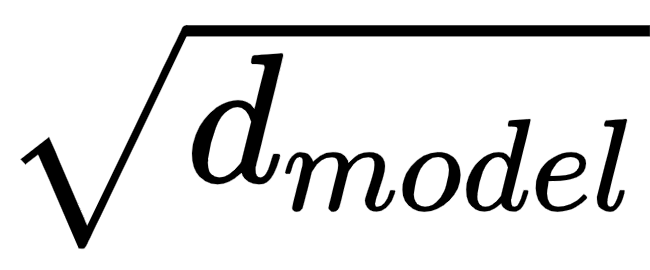 。
。 - Transformer 不使用 RNN,因此它必须以其他方式传达每个序列元素的位置信息。我们可以通过使用位置编码来增加每个嵌入向量来明确地做到这一点。简而言之,位置编码是一个与嵌入向量具有相同长度d模型的向量。位置向量(按元素)添加到嵌入向量中,结果在编码器中进一步传播。论文作者为位置向量的每个元素i引入了以下函数,当当前单词在序列中的位置为pos时:
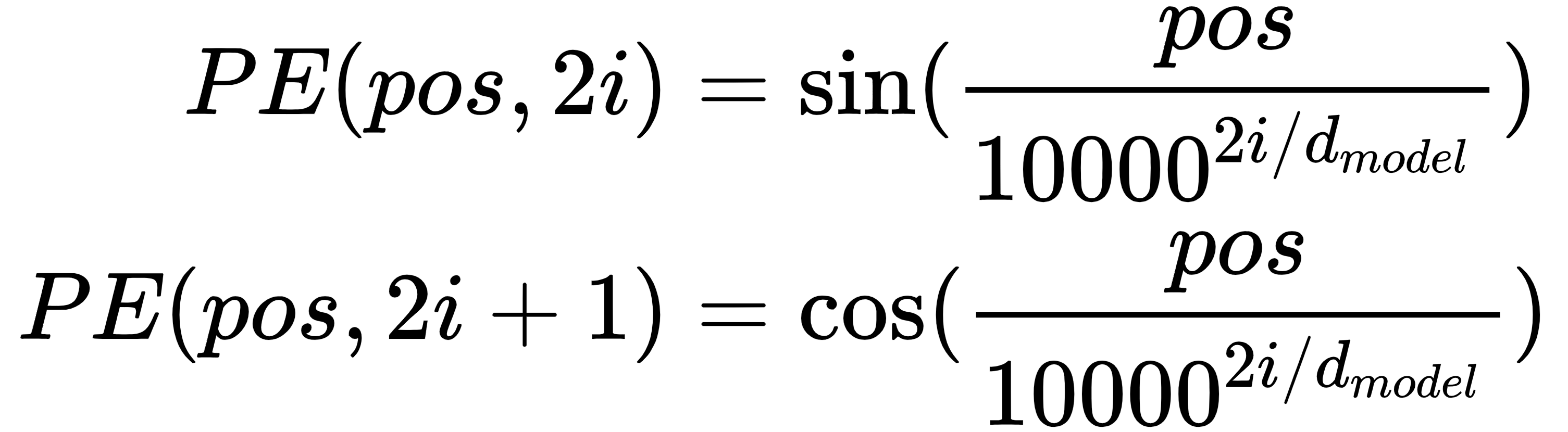
位置编码的每个维度对应一个正弦曲线。波长形成从 2π 到 10000 · 2π 的几何级数。作者假设该函数将允许模型轻松学习通过相对位置参与,因为对于任何固定的偏移量k,PE pos+k可以表示为PE pos的线性函数。
- 编码器的其余部分由N = 6 个相同的块组成。每个块有两个子层:
- 一种多头自注意力机制,就像我们在标题为Transformer attention的部分中描述的那样。由于自注意力机制适用于整个输入序列,因此编码器在设计上是双向的。一些算法仅使用编码器变压器部分,称为变压器编码器。
- 一个简单的全连接前馈网络,由以下公式定义:
![]()
该网络分别应用于每个序列元素x。它在不同的位置使用相同的参数集(W 1、W 2、b 1和b 2),但在不同的编码器块中使用不同的参数。
每个子层(多头注意力和前馈网络)在其自身周围都有一个残差连接,并以对该连接及其自身输出和残差连接之和的归一化结束。因此,每个子层的输出如下:
![]()
规范化技术在论文层规范化( https://arxiv.org/abs/1607.06450 ) 中进行了描述。
接下来我们看decoder,它和encoder有点类似:
- 步骤t的输入是解码器自己在步骤t-1预测的输出字。输入词使用与编码器相同的嵌入向量和位置编码。
- 解码器继续使用一堆N = 6 个相同的块,这些块有点类似于编码器块。每个块由三个子层组成,每个子层采用残差连接和归一化。子层是:
- 多头自注意力机制。编码器自注意力可以关注序列的所有元素,无论它们是在目标元素之前还是之后。但是解码器只有部分生成的目标序列。所以这里的self-attention只能关注前面的序列元素。这是通过屏蔽掉(设置为 -∞)softmax 输入中的所有值来实现的,这些值对应于非法连接:
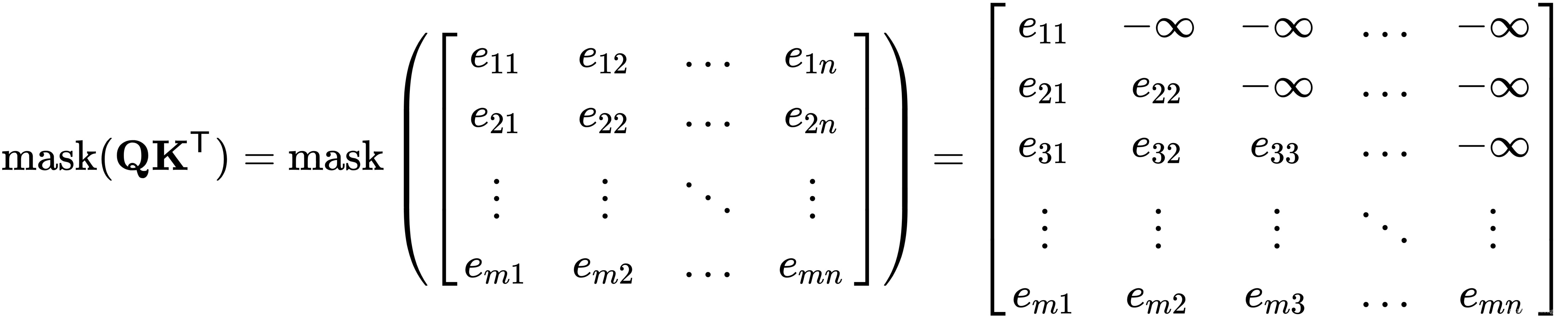
- 多头自注意力机制。编码器自注意力可以关注序列的所有元素,无论它们是在目标元素之前还是之后。但是解码器只有部分生成的目标序列。所以这里的self-attention只能关注前面的序列元素。这是通过屏蔽掉(设置为 -∞)softmax 输入中的所有值来实现的,这些值对应于非法连接:
掩码使解码器单向(与双向编码器不同)。与解码器一起工作的算法称为变压器解码器算法。
- 一种常规的注意力机制,其中查询来自前一个解码器层,键和值来自前一个子层,表示步骤t-1处理后的解码器输出。这允许解码器中的每个位置参与输入序列中的所有位置。这模仿了典型的编码器-解码器注意机制,我们在Seq2seq with attention部分中讨论过。
- 前馈网络,类似于编码器中的前馈网络。
- 解码器以一个全连接层结束,然后是一个 softmax,它产生句子中最可能的下一个单词。
Transformer 使用 dropout 作为正则化技术。它在每个子层的输出中添加 dropout,然后再将其添加到子层输入并进行归一化。它还将 dropout 应用于编码器和解码器堆栈中嵌入和位置编码的总和。
最后,让我们总结一下 self-attention 相对于我们在Seq2seq with attention部分中讨论的 RNN 注意模型的好处。自注意力机制的关键优势是可以立即访问输入序列的所有元素,而不是 RNN 模型的瓶颈思想向量。此外——以下是论文的直接引用——自注意力层将所有位置与恒定数量的顺序执行操作连接起来,而循环层需要O(n)顺序操作。
在计算复杂度方面,当序列长度n小于表示维度d时,自注意力层比循环层更快,这通常是机器翻译中最先进模型使用的句子表示的情况,例如 word-piece(参见Google 的神经机器翻译系统:Bridging the Gap between Human and Machine Translation at https://arxiv.org/abs/1609.08144)和字节对(参见Neural Machine Translation of Rare Words with Subword Units在https://arxiv.org/abs/1508.07909) 陈述。为了提高涉及非常长序列的任务的计算性能,可以将自注意力限制为仅考虑输入序列中以相应输出位置为中心的大小为r的邻域。
我们对变压器的理论描述到此结束。在下一节中,我们将从头开始实现一个转换器。
实施变压器
在本节中,我们将在 PyTorch 1.3.1 的帮助下实现转换器模型。由于示例相对复杂,我们将通过使用基本训练数据集对其进行简化:我们将训练模型以复制随机生成的整数值序列——即源序列和目标序列相同且转换器将学习复制输入序列作为输出。我们不会包含完整的源代码,但您可以在Advanced-Deep-Learning-with-Python/transformer.py at master · PacktPublishing/Advanced-Deep-Learning-with-Python · GitHub找到它。
首先,我们将从实用函数开始clone,它接受一个实例torch.nn.Module并生成n相同模块的相同深层副本(不包括原始源实例):
def clones(module: torch.nn.Module, n: int):
return torch.nn.ModuleList([copy.deepcopy(module) for _ in range(n)])有了这个简短的介绍,让我们继续多头注意力的实现。
多头注意力
在本节中,我们将按照变压器注意力部分的定义来实现多头注意力。我们将从常规缩放点积注意力的实现开始:
def attention(query, key, value, mask=None, dropout=None):
"""Scaled Dot Product Attention"""
d_k = query.size(-1)
# 1) 和 2) 使用缩放分数计算对齐
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 3) 计算注意力分数(softmax)
p_attn = torch.nn.functional.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
# 4) 将注意力分数应用于值
return torch.matmul(p_attn, value), p_attn提醒一下,此函数实现了公式 ![]()
,其中Q = query、K =key和V = value。如果 amask可用,它也将被应用。
接下来,我们将多头注意力机制实现为torch.nn.Module. 提醒一下,实现遵循以下公式:

我们将从__init__方法开始:
class MultiHeadedAttention(torch.nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"""
:param h: 头数
:param d_model: 查询/键/值向量长度
"""
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# 我们假设 d_v 总是等于 d_k
self.d_k = d_model // h
self.h = h
# 创建 4 个全连接层
# 3 用于查询/键/值投影
# 1 连接所有头的输出
self.fc_layers = clones(torch.nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = torch.nn.Dropout(p=dropout)接下来,让我们实现该MultiHeadedAttention.forward方法(请记住缩进):
def forward(self, query, key, value, mask=None):
if mask is not None:
# 相同的掩码应用于所有 h 头。
mask = mask.unsqueeze(1)
batch_samples = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
projections = list()
for l, x in zip(self.fc_layers, (query, key, value)):
projections.append(
l(x).view(batch_samples, -1, self.h, self.d_k).transpose(1, 2)
)
query, key, value = projections
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value,
mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(batch_samples, -1, self.h * self.d_k)
return self.fc_layers[-1](x)我们迭代Q / K / V向量及其参考投影,并使用以下代码段self.fc_layers生成Q / K / V : projections
l(x).view(batch_samples , - 1 , self .h , self .d_k).transpose( 1 , 2 )然后,我们使用我们首先定义的函数对投影应用常规注意力attention,最后,我们连接多个头的输出并返回结果。现在我们已经实现了多头注意力,让我们继续实现编码器。
编码器
在本节中,我们将实现编码器,它由几个不同的子组件组成。让我们从主要定义开始,然后深入了解更多细节:
class Encoder(torch.nn.Module):
def __init__(self, block: EncoderBlock, N: int):
super(Encoder, self).__init__()
self.blocks = clones(block, N)
self.norm = LayerNorm(block.size)
def forward(self, x, mask):
"""遍历所有块并规范化"""
for layer in self.blocks:
x = layer(x, mask)
return self.norm(x)这相当简单:编码器由self.blocks:的N堆叠实例组成EncoderBlock,其中每个实例都用作下一个的输入。它们之后是LayerNorm归一化(我们在变压器模型部分self.norm讨论了这些概念)。该方法将数据张量和 的实例作为输入,该实例阻止了一些输入序列元素。正如我们在变压器模型部分中讨论的那样,掩码仅与模型的解码器部分相关,其中序列的未来元素尚不可用。在编码器中,掩码仅作为占位符存在。 forward x mask
我们将省略LayerNorm(知道它是编码器末尾的规范化就足够了)的定义,我们将专注于EncoderBlock:
class EncoderBlock(torch.nn.Module):
def __init__(self,
size: int,
self_attn: MultiHeadedAttention,
ffn: PositionwiseFFN,
dropout=0.1):
super(EncoderBlock, self).__init__()
self.self_attn = self_attn
self.ffn = ffn
# 创建 2 个子层连接
# 1 用于 self-attention
# 1 用于 FFN
self.sublayers = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
x = self.sublayers[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayers[1](x, self.ffn)提醒一下,每个编码器块由两个子层(self.sublayers用熟悉的clones函数实例化)组成:一个多头自注意力self_attn(一个实例MultiHeadedAttention),然后是一个简单的全连接网络ffn(一个实例PositionwiseFFN)。每个子层都被它的残差连接包裹着,这个残差连接是用SublayerConnection类来实现的:
class SublayerConnection(torch.nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = torch.nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))残差连接还包括归一化和dropout(根据定义)。提醒一下,它遵循公式 ![]() ,但为了代码的简单性,self.norm先来鼠后。该SublayerConnection.forward短语将数据张量x和作为输入sublayer,它是MultiHeadedAttentionor的一个实例PositionwiseFFN。我们可以在方法中看到这种动态EncoderBlock.forward。
,但为了代码的简单性,self.norm先来鼠后。该SublayerConnection.forward短语将数据张量x和作为输入sublayer,它是MultiHeadedAttentionor的一个实例PositionwiseFFN。我们可以在方法中看到这种动态EncoderBlock.forward。
我们尚未定义的唯一组件是PositionwiseFFN,它实现了公式 ![]() 。让我们添加这个缺失的部分:
。让我们添加这个缺失的部分:
class PositionwiseFFN(torch.nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout=0.1):
super(PositionwiseFFN, self).__init__()
self.w_1 = torch.nn.Linear(d_model, d_ff)
self.w_2 = torch.nn.Linear(d_ff, d_model)
self.dropout = torch.nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(torch.nn.functional.relu(self.w_1(x))))我们现在已经实现了编码器及其所有构建块。在下一节中,我们将继续解码器的定义。
解码器
在本节中,我们将实现解码器。它遵循与编码器非常相似的模式:
class Decoder(torch.nn.Module):
def __init__(self, block: DecoderBlock, N: int, vocab_size: int):
super(Decoder, self).__init__()
self.blocks = clones(block, N)
self.norm = LayerNorm(block.size)
self.projection = torch.nn.Linear(block.size, vocab_size)
def forward(self, x, encoder_states, source_mask, target_mask):
for layer in self.blocks:
x = layer(x, encoder_states, source_mask, target_mask)
x = self.norm(x)
return torch.nn.functional.log_softmax(self.projection(x), dim=-1)它包括self.blocks:的N实例DecoderBlock,其中每个块的输出用作下一个块的输入。这些之后是self.norm规范化( 的一个实例LayerNorm)。最后,为了产生最可能的词,解码器有一个额外的全连接层,带有 softmax 激活。请注意,该方法需要一个额外的参数Decoder.forward,它表示编码器的注意力向量。然后将其传递给实例。encoder_statesencoder_statesDecoderBlock
接下来,让我们实现DecoderBlock:
class DecoderBlock(torch.nn.Module):
def __init__(self,
size: int,
self_attn: MultiHeadedAttention,
encoder_attn: MultiHeadedAttention,
ffn: PositionwiseFFN,
dropout=0.1):
super(DecoderBlock, self).__init__()
self.size = size
self.self_attn = self_attn
self.encoder_attn = encoder_attn
self.ffn = ffn
# Create 3 sub-layer connections
# 1 for the self-attention
# 1 for the encoder attention
# 1 for the FFN
self.sublayers = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, encoder_states, source_mask, target_mask):
x = self.sublayers[0](x, lambda x: self.self_attn(x, x, x, target_mask))
x = self.sublayers[1](x, lambda x: self.encoder_attn(x, encoder_states, encoder_states, source_mask))
return self.sublayers[2](x, self.ffn)这类似于EncoderBlock,但有一个实质性区别:虽然仅EncoderBlock依赖于自我注意机制,但在这里我们将自我注意与来自编码器的常规注意结合起来。这反映在模块中,然后是方法的参数,以及编码器注意力值的附加值。我们可以在方法中看到多种注意力机制的组合。请注意,用于查询/键/值,而用作查询以及键和值。通过这种方式,常规注意力在编码器和解码器之间建立了联系。encoder_attnencoder_statesforwardSublayerConnectionDecoderBlock.forwardself.self_attnxself.encoder_attnxencoder_states
解码器实现到此结束。我们将在下一节继续构建完整的变压器模型。
把它们放在一起
我们将继续EncoderDecoder主课:
class EncoderDecoder(torch.nn.Module):
def __init__(self,
encoder: Encoder,
decoder: Decoder,
source_embeddings: torch.nn.Sequential,
target_embeddings: torch.nn.Sequential):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.source_embeddings = source_embeddings
self.target_embeddings = target_embeddings
def forward(self, source, target, source_mask, target_mask):
encoder_output = self.encoder(
x=self.source_embeddings(source),
mask=source_mask)
return self.decoder(
x=self.target_embeddings(target),
encoder_states=encoder_output,
source_mask=source_mask,
target_mask=target_mask)它结合了Encoder、Decoder和source_embeddings/target_embeddings(我们将在本节后面关注嵌入)。该EncoderDecoder.forward方法获取源序列并将其提供给self.encoder. 然后,self.decoder从前面的输出步骤x=self.target_embeddings(target)、编码器状态encoder_states=encoder_output以及源掩码和目标掩码中获取其输入。使用这些输入,它会生成序列的预测下一个元素(单词),这也是该forward方法的返回值。
接下来,我们将实现该build_model函数,它将我们迄今为止实现的所有内容组合成一个连贯的模型:
def build_model(source_vocabulary: int,
target_vocabulary: int,
N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""构建完整的变压器模型"""
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFFN(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
encoder=Encoder(EncoderBlock(d_model, c(attn), c(ff), dropout), N),
decoder=Decoder(DecoderBlock(d_model, c(attn), c(attn),c(ff),
dropout), N, target_vocabulary),
source_embeddings=torch.nn.Sequential(
Embeddings(d_model, source_vocabulary), c(position)),
target_embeddings=torch.nn.Sequential(
Embeddings(d_model, target_vocabulary), c(position)))
# 这在他们的代码中很重要。
# 用 Glorot / fan_avg 初始化参数。
for p in model.parameters():
if p.dim() > 1:
torch.nn.init.xavier_uniform_(p)
return model除了熟悉的MultiHeadedAttentionand PositionwiseFFN,我们还创建了position变量(PositionalEncoding类的一个实例)。这个类实现了我们在变压器模型部分中描述的 正弦位置编码(我们不会在这里包含完整的实现)。现在让我们专注于实例化:我们已经熟悉编码器和解码器,所以那里没有惊喜。但是嵌入更有趣。以下代码实例化了源嵌入(但这也适用于目标嵌入):EncoderDecoder
source_embeddings=torch.nn.Sequential(Embeddings(d_model, source_vocabulary), c(position))我们可以看到它们是两个组件的顺序列表:
- 类的一个实例Embeddings,它只是torch.nn.Embedding进一步乘以的组合
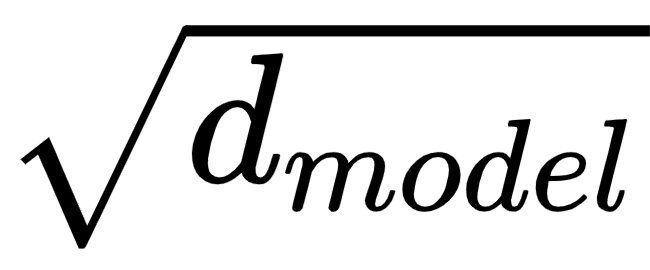 (我们将在此处省略类定义)
(我们将在此处省略类定义) - 位置编码c(position),将位置正弦数据添加到嵌入向量
一旦我们以这种方式对输入数据进行了预处理,它就可以作为编码器/解码器核心部分的输入。
到此结束我们对变压器的实现。我们在这个例子中的目标是为变压器注意力和变压器模型部分的理论基础提供补充。因此,我们将重点放在代码中最相关的部分,省略了一些普通的代码部分,其中主要是随机数字序列的数据生成器和实现训练的函数。尽管如此,我还是鼓励读者逐步浏览完整的示例,以便他们更好地了解变压器的工作方式。 RandomDataset train_model
在下一节中,我们将讨论一些基于我们迄今为止介绍的注意力机制的最先进的语言模型。
Transformer language models
在第 6 章,语言 建模中,我们介绍了几种不同的语言模型(word2vec、Gl oVe 和 fastText),它们使用词的上下文(其周围的词)来创建词向量(嵌入)。这些模型有一些共同的属性:
- 它们是上下文无关的(我知道它与前面的陈述相矛盾),因为它们根据每个单词在训练文本中的所有出现来创建每个单词的单个全局词向量。例如,lead在词组lead the way和lead atom中可以有完全不同的含义,但模型会尝试将这两个含义嵌入到同一个词向量中。
- 它们是无位置的,因为它们在训练嵌入向量时没有考虑上下文单词的顺序。
相比之下,可以创建基于转换器的语言模型,它们既依赖于上下文又依赖于位置。这些模型将为单词的每个唯一上下文生成不同的单词向量,同时考虑当前上下文单词及其位置。这导致了经典模型和基于变压器的模型之间的概念差异。由于诸如 word2vec 之类的模型创建了静态上下文无关和位置无关的嵌入向量,我们可以丢弃该模型并仅在后续下游任务中使用这些向量。但是 Transformer 模型会根据上下文创建动态向量,因此,我们必须将其作为任务管道的一部分。
在以下部分中,我们将讨论一些最新的基于变压器的模型。
BE
来自转换器( BERT )的双向编码器表示(请参阅https://arxiv.org/abs/1810.04805上的 BERT:用于语言理解的深度双向转换器的预训练)模型具有非常具有描述性的名称。让我们看一下提到的一些元素:
- 编码器表示:此模型仅使用我们在变压器模型部分中描述的变压器架构的多层编码器部分的输出。
- 双向:编码器具有固有的双向特性。
为了获得一些观点,让我们用L表示转换器块的数量,用H表示隐藏大小(之前用d model表示),用A表示自注意力头的数量。论文作者实验了两种 BERT 配置:BE RT BASE(L = 12,H = 768,A = 12,总参数 = 110M)和 BERT LARGE(L = 24,H = 1024,A = 16,总参数) = 340M)。
为了更好地理解 BERT 框架,我们将从训练开始,它有两个步骤:
- 预训练:模型通过不同的预训练任务在未标记数据上进行训练。
- 微调:使用预训练参数初始化模型,然后在特定下游任务的标记数据集上微调所有参数。
我们可以看到下图中的步骤:
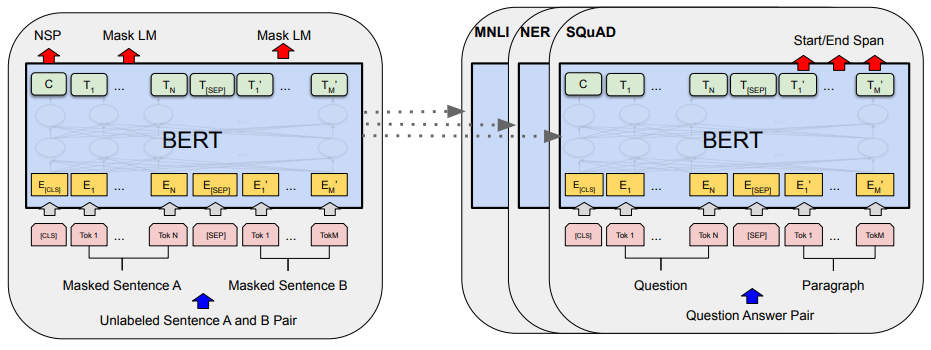
这些图表将作为下一部分的参考,敬请期待更多详细信息。现在,我们知道Tok N代表 one-hot-encoded 输入标记,E代表标记嵌入,T代表模型输出向量就足够了。
现在我们对 BERT 有了一个概述,让我们看看它的组成部分。
输入数据表示
在进入每个训练步骤之前,让我们讨论两个步骤共享的输入和输出数据表示。与 fastText 有点相似(参见 第 6 章,语言建模),BERT 使用一种称为 WordPiece 的数据驱动的标记化算法(https://arxiv.org/abs/1609.08144 )。这意味着,它不是完整单词的词汇表,而是在迭代过程中创建子词令牌的词汇表,直到该词汇表达到预定大小(在 BERT 的情况下,大小为 30,000 个令牌)。这种方法有两个主要优点:
- 它允许我们控制字典的大小。
- 它通过将未知词分配给最接近的现有字典子词标记来处理未知词。
BERT 可以处理各种下游任务。为此,作者引入了一种特殊输入数据表示,它可以明确地将以下内容表示为单输入标记序列:
- 单个句子(例如,在分类任务中,如情感分析)
- 一对句子(例如,在问答题中)
在这里,句子不仅指语言句子,还可以指任意长度的任何连续文本。
该模型使用两个特殊标记:
- 每个序列的第一个标记始终是一个特殊的分类标记 ( [CLS])。这个token对应的隐藏状态被用作分类任务的聚合序列表示。例如,如果我们想对序列应用情感分析,对应于[CLS]输入标记的输出将代表模型的情感(正面/负面)输出。
- 句子对被打包成一个单一的序列。第二个特殊标记( [SEP]) 标记了两个输入句子之间的边界(在我们有两个 的情况下)。我们在每个标记的附加学习分割嵌入的帮助下进一步区分句子,指示它属于句子 A 还是句子 B。因此,输入嵌入是标记嵌入、分割嵌入和位置嵌入的总和。在这里,令牌和位置嵌入的用途与它们在常规转换器中的用途相同。
下图显示了特殊标记以及输入嵌入: 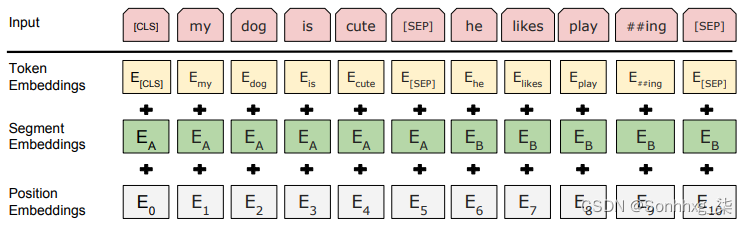
现在我们知道了输入是如何处理的,让我们看一下预训练步骤。
预训练
预训练步骤在来自转换器的双向编码器表示中图表的左侧进行了说明。该论文的作者使用两个无监督的训练任务来训练 BERT 模型:掩码语言建模( MLM ) 和下一句预测( NSP )。
我们将从 MLM 开始,其中模型呈现一个输入序列,其目标是预测该序列中的缺失词。在这种情况下,BERT 充当去噪自动编码器,因为它试图重建其故意损坏的输入。 MLM 在本质上类似于 word2vec 模型的 CBOW 目标(参见第 6 章,语言建模)。 为了解决这个任务,BERT 编码器的输出使用带有 softmax 激活的全连接层进行扩展,以在给定输入序列的情况下生成最可能的单词。通过随机屏蔽 15%(根据论文)的 WordPiece 标记来修改每个输入序列。 为了更好地理解这一点,我们将使用论文本身的一个例子:假设未标记的句子是my dog is hairy,并且在随机掩码过程中,我们选择了第四个标记(对应于hairy),我们的掩码过程可以通过以下几点进一步说明:
- 80% 的时间:用标记替换单词[MASK]——例如,my dog is hairy → my dog is [MASK]。
- 10% 的时间:用随机词替换这个词——例如,my dog is hairy → my dog is apple。
- 10% 的时间:保持这个词不变my dog is hairy → my dog is hairy。这样做的目的是使表示偏向于实际观察到的单词。
我们需要这种 80/10/10 分布的主要原因有两个:
- 令牌在[MASK]预训练和微调之间造成了不匹配(我们将在下一节中讨论),因为它只出现在前者中而不出现在后者中——也就是说,微调任务将为模型提供输入没有[MASK]令牌的序列。然而,该模型经过预训练以预期[MASK],可能导致未定义行为的序列。
- BERT 假设预测的 token 是相互独立的。为了理解这一点,让我们假设模型试图重建我 [MASK] 的 [MASK]输入序列。BERT 可以预测我和我的自行车一起骑自行车的句子,这是一个有效的句子。但是因为模型没有关联两个蒙面词,所以没有什么能阻止它预测我骑着自行车去游泳,这是无效的。
使用 80/10/10 分布,transformer编码器不知道它将被要求预测哪些词或哪些词已被随机词替换,因此它被迫保留每个输入标记的分布上下文表示。此外,由于随机替换只发生在所有标记的 1.5%(即 15% 的 10%)上,这似乎不会损害模型的语言理解能力。
MLM 的一个缺点是,由于该模型仅预测每批中 15% 的单词,因此它可能比使用所有单词的预训练模型收敛得更慢。
接下来,让我们继续 NSP。作者认为,许多重要的下游任务,例如问答( QA ) 和自然语言推理( NLI ),都是基于对两个句子之间关系的理解,而语言建模并未直接捕捉到这一点。
| Premise | Hypothesis | Label |
| I am running | I am sleeping | contradiction |
| I am running | I am listening to music | neutral |
| I am running | I am training | entailment |
为了训练一个理解句子关系的模型,我们预训练下一个句子预测任务,该任务可以从任何单语语料库中轻松生成。具体来说,每个输入序列都由一个起始[CLS]标记组成,后跟两个连接的句子 A 和 B,它们由[SEP]标记分隔(参见来自转换器的双向编码器表示中的图表)。在为每个预训练示例选择句子 A 和 B 时,50% 的情况下,B 是 A 之后的实际下一个句子IsNext(标记为NotNext)。正如我们所提到的,模型在相应的输入IsNext上输出/NotNext 标签。[CLS]
使用以下示例说明 NSP 任务:
- [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] 标签为IsNext。
- [CLS] the man [MASK] to the store [SEP] penguins [MASK] are flight ##less [SEP]带有标签的鸟NotNext。注意##less 标记的使用,它是 WordPiece 标记化算法的结果。
接下来,我们来看看微调步骤。
微调
微调任务跟在预训练任务之后,除了输入预处理之外,这两个步骤非常相似。我们没有创建掩码序列,而是简单地为 BERT 模型提供特定于任务的未修改输入和输出,并以端到端的方式微调所有参数。因此,我们在微调阶段使用的模型与我们将在实际生产环境中使用的模型相同。
下图展示了如何使用 BERT 解决几种不同类型的任务:
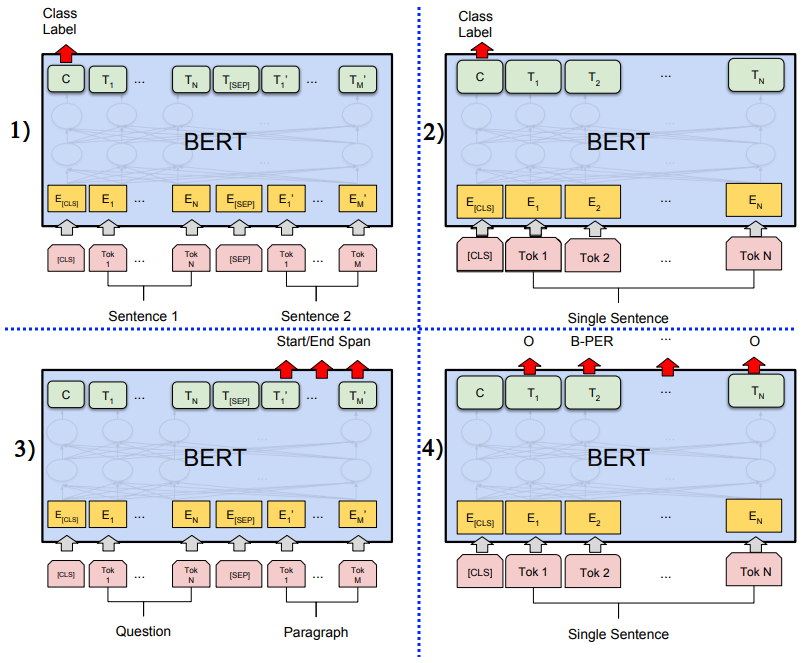
让我们讨论一下:
- 左上角的场景说明了如何将BERT用于句子对分类任务,例如NLI。简而言之,我们用两个连接的句子给模型喂食,只看[CLS]令牌输出分类,这将输出模型结果。例如,在 NLI 任务中,目标是预测第二个句子相对于第一个句子是蕴涵、矛盾还是中性。
- 右上角的场景说明了如何将BERT用于单句分类任务,例如情感分析。这与句子对分类非常相似。
- 左下角的场景说明了如何在斯坦福问答数据集(SQuAD v1.1,https ://rajpurkar.github.io/SQuAD-explorer/explore/1.1/dev/)上使用BERT。假设序列 A 是一个问题,序列 B 是来自 Wikipedia 的包含答案的段落,目标是预测该段落中答案的文本跨度(开始和结束)。我们引入了两个新向量:一个开始向量
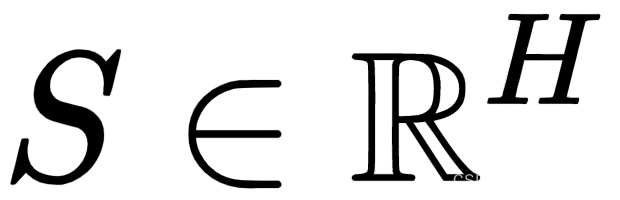 和一个结束向量
和一个结束向量 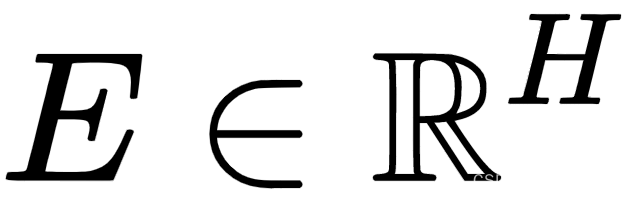 ,其中H是模型的隐藏大小。每个单词i作为答案跨度的开始(或结束)的概率被计算为其输出向量T i和 S(或E ),然后是对序列B :
,其中H是模型的隐藏大小。每个单词i作为答案跨度的开始(或结束)的概率被计算为其输出向量T i和 S(或E ),然后是对序列B : 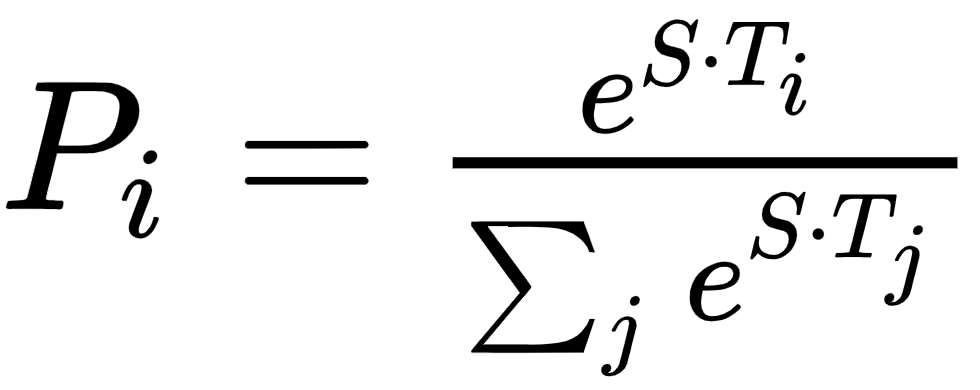 的所有单词的 softmax 。从位置i开始并跨越到j的候选跨度的分数计算为
的所有单词的 softmax 。从位置i开始并跨越到j的候选跨度的分数计算为 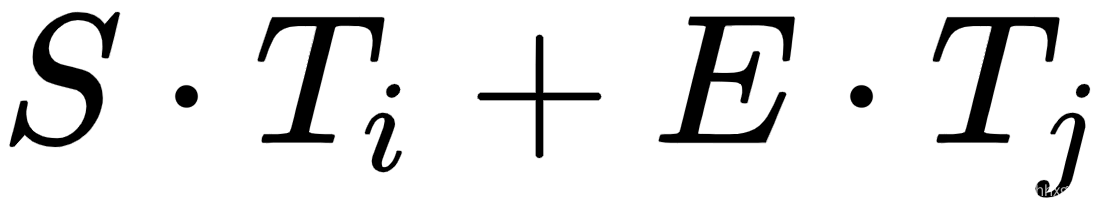 。输出候选者是得分最高的那个,其中
。输出候选者是得分最高的那个,其中 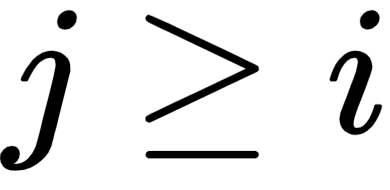 。
。 - 右下角的场景说明了如何使用BERT进行命名实体识别( NER ),其中每个输入标记都被分类为某种类型的实体。
这结束了我们专门介绍 BERT 模型的部分。提醒一下,它基于变压器编码器。在下一节中,我们将讨论变压器解码器模型。
Transformer-XL
在本节中,我们将讨论对普通转换器的改进,称为转换器-XL,其中 XL 代表超长(请参阅Transformer- XL :超越固定长度上下文的注意力语言模型,网址为https://arxiv. org/abs/1901.02860)。为了理解改进常规变压器的必要性,让我们讨论一下它的一些限制,其中之一来自变压器本身的性质。基于 RNN 的模型具有(至少在理论上)传达任意长度序列信息的能力,因为内部 RNN 状态会根据所有先前的输入进行调整。但是transformer的self-attention没有这样的循环成分,完全被限制在当前输入序列的范围内。如果我们有无限的内存和计算,一个简单的解决方案是处理整个上下文序列。但在实践中,我们的资源有限,因此我们将整个文本分成更小的段,并仅在每个段内训练模型,如下图(a)所示:
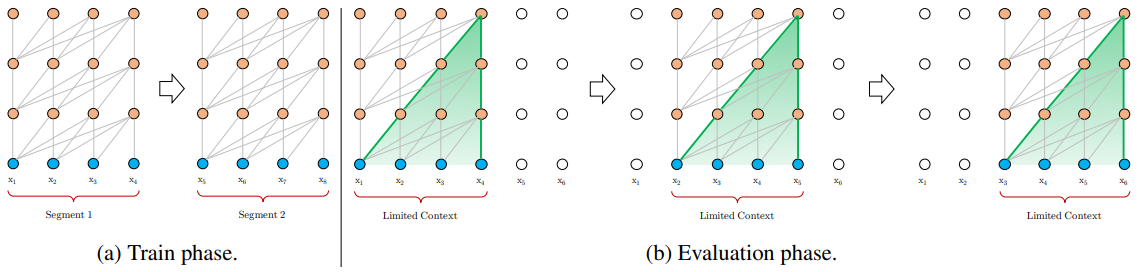
横轴表示输入序列 [ x 1 ,..., x 4 ],纵轴表示堆叠的解码器块。请注意,元素x i只能关注元素 ![]() 。那是因为transformer-XL 基于 Transformer 解码器(并且不包括编码器),不像 BERT,它基于编码器。所以transformer-XL解码器和全解码器是不一样的编码器-解码器转换器,因为它无法像常规解码器那样访问编码器状态。从这个意义上说,transformer-XL 解码器与一般的 Transformer 编码器非常相似,除了它是单向的,因为输入序列掩码。Transformer-XL 是自回归模型的一个示例。
。那是因为transformer-XL 基于 Transformer 解码器(并且不包括编码器),不像 BERT,它基于编码器。所以transformer-XL解码器和全解码器是不一样的编码器-解码器转换器,因为它无法像常规解码器那样访问编码器状态。从这个意义上说,transformer-XL 解码器与一般的 Transformer 编码器非常相似,除了它是单向的,因为输入序列掩码。Transformer-XL 是自回归模型的一个示例。
如上图所示,最大可能的依赖长度上限为段长度,尽管注意力机制通过允许立即访问序列的所有元素来帮助防止梯度消失,但转换器无法充分利用这一优势,因为有限的输入段。此外,通常通过选择连续的符号块而不考虑句子或任何其他语义边界来分割文本,该论文的作者将其称为上下文碎片。引用论文本身,该模型缺乏预测前几个符号所需的上下文信息,导致优化效率低下和性能低下。
香草变压器的另一个问题在评估过程中表现出来,如上图右侧所示。在每一步,模型都将完整的序列作为输入,但只进行一次预测。为了预测下一个输出,变换器右移一个位置,但新段(与最后一段相同,除了最后一个值)必须在整个输入序列上从头开始处理。
现在我们已经确定了变压器模型的一些问题,让我们看看如何解决它们。
具有状态重用的段级重复
Transformer-XL 在 Transformer 模型中引入了递归关系。在训练期间,模型为当前段缓存其状态,当它处理下一个段时,它可以访问该缓存(但固定)的值,如下图所示:
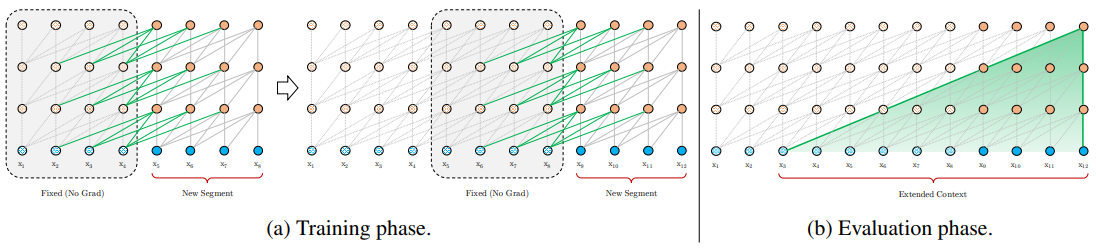
在训练期间,梯度不会通过缓存段传播。让我们形式化这个概念(我们将使用论文中的符号,它可能与本章前面的符号略有不同)。我们将用 和 表示长度为 L 的两个连续片段,用表示第τ个片段的第n个块隐藏状态,其中d是隐藏维度(相当于d模型)。为了澄清,是一个有L行的矩阵,其中每一行包含输入序列的每个元素的d维自注意力向量。那么,n第τ+1段的第 1 层隐藏状态是通过以下步骤产生的: 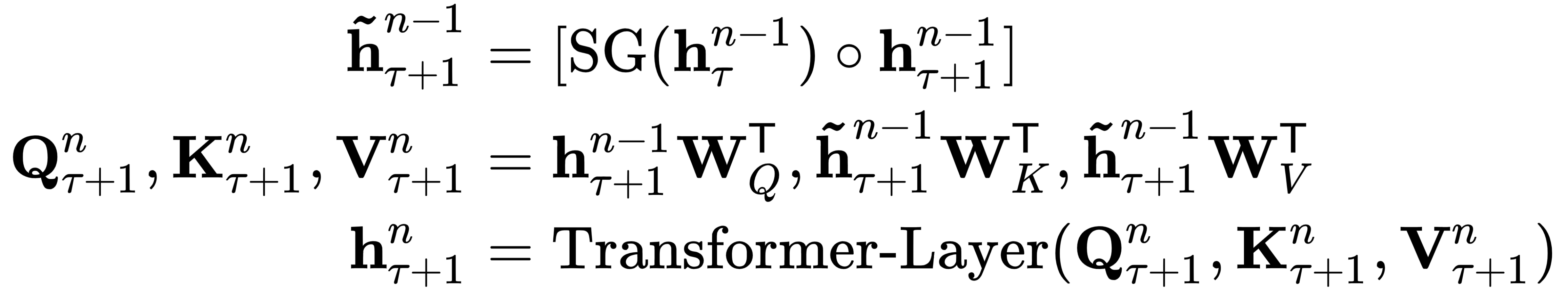 这里,
这里, ![]() 指的是停止梯度,W *是指模型参数(以前用W *表示),
指的是停止梯度,W *是指模型参数(以前用W *表示), ![]() 是指两个隐藏序列沿长度维度的串联。为了澄清,连接的隐藏序列是一个具有2L行的矩阵,其中每一行包含组合输入序列 τ 和 τ+1 的一个元素的d维自注意力向量。该论文很好地解释了上述公式的复杂性,因此以下解释包含一些直接引用。与标准变压器相比,关键的区别在于关键
是指两个隐藏序列沿长度维度的串联。为了澄清,连接的隐藏序列是一个具有2L行的矩阵,其中每一行包含组合输入序列 τ 和 τ+1 的一个元素的d维自注意力向量。该论文很好地解释了上述公式的复杂性,因此以下解释包含一些直接引用。与标准变压器相比,关键的区别在于关键![]() 和价值
和价值![]() 以扩展上下文为条件
以扩展上下文为条件![]() ,因此
,因此![]() 从前一个段缓存(在上图中以绿色路径显示)。通过将这种递归机制应用于语料库的每两个连续片段,它实质上在隐藏状态中创建了片段级的递归。因此,所使用的有效上下文可以远远超出两个部分。但是,请注意,每个段之间的循环依赖关系
从前一个段缓存(在上图中以绿色路径显示)。通过将这种递归机制应用于语料库的每两个连续片段,它实质上在隐藏状态中创建了片段级的递归。因此,所使用的有效上下文可以远远超出两个部分。但是,请注意,每个段之间的循环依赖关系![]() 向下
向下![]() 移动一层。因此,最大可能的依赖长度相对于层数和段长度线性增长 - 即O ( N × L ),如上图的阴影区域所示。
移动一层。因此,最大可能的依赖长度相对于层数和段长度线性增长 - 即O ( N × L ),如上图的阴影区域所示。
除了实现超长上下文和解决碎片之外,递归方案带来的另一个好处是评估速度显着加快。具体来说,在评估期间,可以重用来自先前片段的表示,而不是像普通模型那样从头开始计算。
最后,请注意,递归方案不需要仅限于前一段。理论上,我们可以在 GPU 内存允许的范围内缓存尽可能多的先前段,并在处理当前段时将它们全部重用作为额外的上下文。
递归方案将需要一种新方法来编码序列元素的位置。接下来让我们看看这个话题。
相对位置编码
普通变压器输入增加了正弦位置编码(请参阅变压器模型部分),这些编码仅在当前段内相关。以下公式显示了如何用当前的位置编码示意性地计算状态![]() 和
和![]() :
:
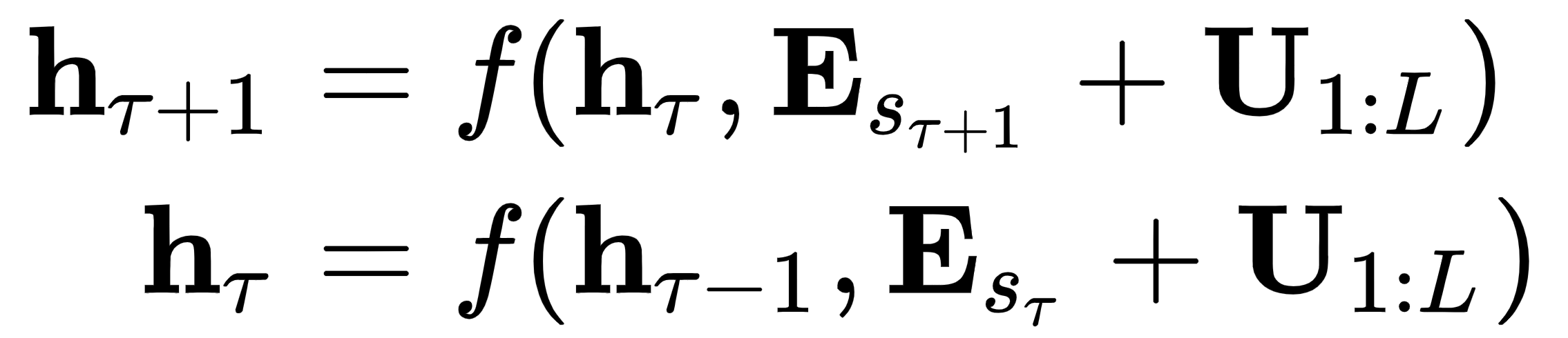
这里,![]() 是s τ的词嵌入序列,f是变换函数。我们可以看到我们对
是s τ的词嵌入序列,f是变换函数。我们可以看到我们对![]() 和
和![]() 使用了相同的位置编码。正因为如此,模型无法区分相同位置的两个元素在不同序列
使用了相同的位置编码。正因为如此,模型无法区分相同位置的两个元素在不同序列![]() 和
和![]() 中的位置。为了避免这种情况,论文的作者提出了一种新型的相对位置编码方案。他们观察到,当查询向量(或查询矩阵)
中的位置。为了避免这种情况,论文的作者提出了一种新型的相对位置编码方案。他们观察到,当查询向量(或查询矩阵)![]() 关注关键向量
关注关键向量![]() 时,它不需要知道每个关键向量的绝对位置来识别片段的时间顺序。相反,知道每个关键向量
时,它不需要知道每个关键向量的绝对位置来识别片段的时间顺序。相反,知道每个关键向量![]() 与其自身
与其自身![]() 之间的相对距离就足够了——即i-j。
之间的相对距离就足够了——即i-j。
建议的解决方案是创建一组相对位置编码![]() ,其中第i行的每个单元格表示第i个元素与序列的其余元素之间的相对距离。R使用与以前相同的正弦公式,但这次使用的是相对位置而不是绝对位置。这个相对距离是动态注入的(而不是作为输入预处理的一部分),这使得查询向量可以区分
,其中第i行的每个单元格表示第i个元素与序列的其余元素之间的相对距离。R使用与以前相同的正弦公式,但这次使用的是相对位置而不是绝对位置。这个相对距离是动态注入的(而不是作为输入预处理的一部分),这使得查询向量可以区分 ![]() 和
和 ![]() 的位置。为了理解这一点,让我们从Transformer attention部分中的 product absolute position attention 公式开始,可以分解如下:
的位置。为了理解这一点,让我们从Transformer attention部分中的 product absolute position attention 公式开始,可以分解如下:
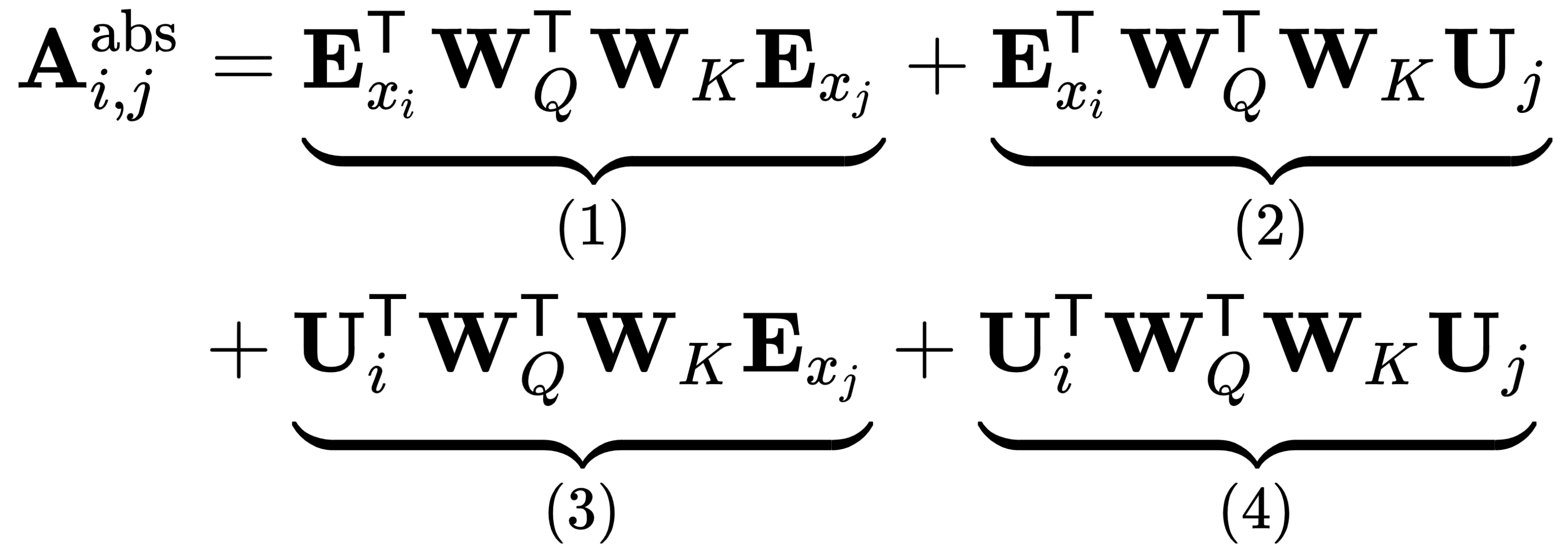
让我们讨论这个公式的组成部分:
- 表示有多少单词i关注单词j ,无论它们的当前位置如何(基于内容的寻址) - 例如,单词轮胎与单词car有多少关联。
- 反映有多少单词i关注位置j中的单词,无论该单词是什么(内容相关的位置偏差)——例如,如果单词i是cream,我们可能想要检查单词j = i的概率- 1是冰。
- 此步骤与第 2 步相反。
- 指示位置i中的单词应该注意位置j中的单词的程度,而不管这两个单词是什么(全局定位偏差)——例如,对于相距较远的位置,此值可能较低。
在transformer-XL中,这个公式被修改为包含相对位置嵌入: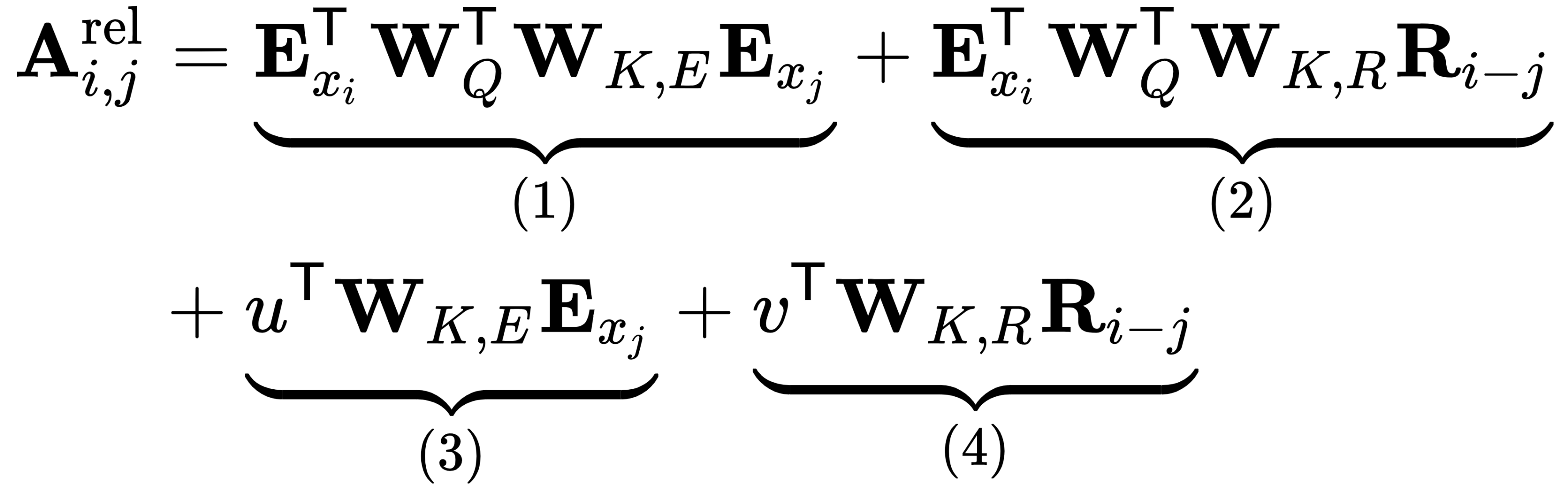
让我们概述一下绝对位置公式的变化:
- 将用于计算项 (2) 和 (4) 中的关键向量的绝对位置嵌入U j的所有出现替换为其相对对应物R i-j。
- 将第 (3) 项中的查询替换
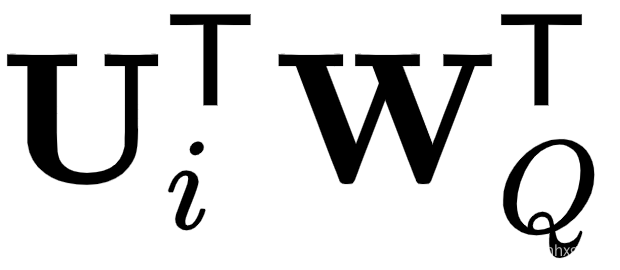 为可训练参数
为可训练参数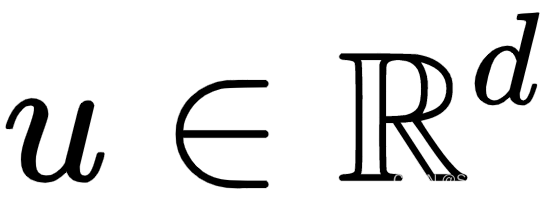 。这背后的原因是所有查询位置的查询向量都是相同的;因此,无论查询位置如何,对不同单词的注意力偏差都应该保持不变。类似地,
。这背后的原因是所有查询位置的查询向量都是相同的;因此,无论查询位置如何,对不同单词的注意力偏差都应该保持不变。类似地,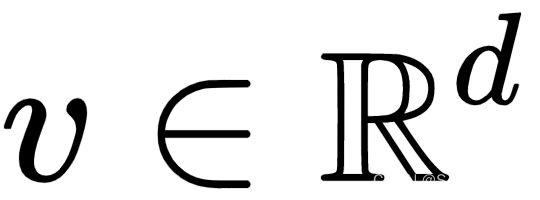 可训练参数
可训练参数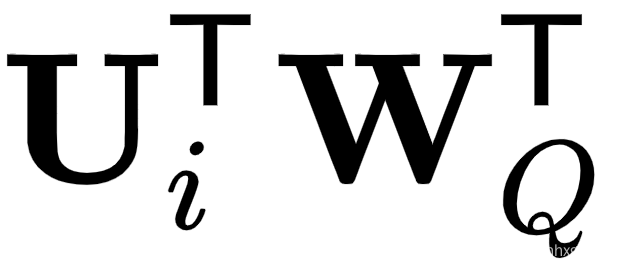 替换项 (4)。
替换项 (4)。 - 将W K分成两个权重矩阵W K,E和W K,R以生成单独的基于内容和基于位置的关键向量。
回顾一下,段级递归和相对位置编码是transformer-XL对普通transformer的主要改进。在下一节中,我们将看看transformer-XL 的另一个改进。
XLNet
作者指出,与单向自回归模型(例如transformer-XL)相比,具有去噪自编码预训练的双向模型(例如 BERT)实现了更好的性能。但正如我们在来自转换器的双向编码器表示的预训练小节中提到的那样,令牌引入了预训练和微调步骤之间的差异。为了克服这些限制,transformer-XL 的作者提出了 XLNet (参见XLNet:Generalized Autoregressive Pretraining for Language Understanding at https://arxiv.org/abs/1906.08237 ):一种广义自回归[MASK]预训练机制,通过在分解顺序的所有排列上最大化预期似然性来学习双向上下文。为了澄清,XLNet 建立在transformer-XL 的transformer 解码器模型之上,并在自回归预训练步骤中引入了一种基于智能排列的双向上下文流机制。
下图说明了模型如何处理具有不同分解顺序的相同输入序列。具体来说,它显示了一个带有两个堆叠块和段级递归(mem字段)的转换器解码器: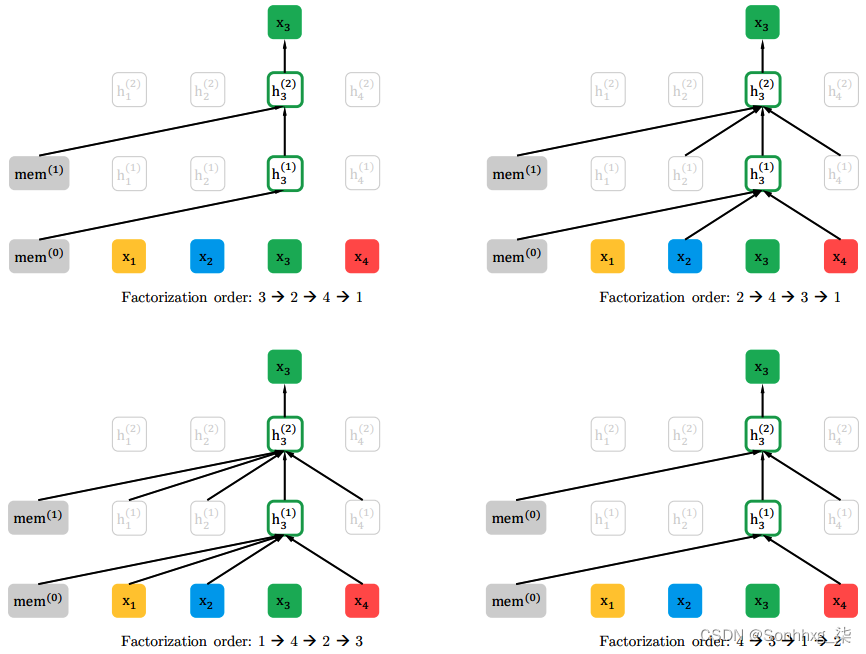
有T!在长度为T的序列上执行有效的自回归分解的不同顺序。假设我们有一个长度为 4 的 [ x 1 , x 2 , x 3 , x 4 ] 输入序列。该图显示了可能的 4 个中的四个!= 该序列的 24 个分解顺序(从左上角顺时针开始):[ x 3 , x 2 , x 4 , x 1 ], [ x 2 , x 4 , x 3 , x 1 ], [ x 4 , × 3 , ×1 , x 2 ] 和 [ x 1 , x 4 , x 2 , x 3 ]。请记住,自回归模型只允许当前元素关注序列的前面元素。因此,在正常情况下, x 3将只能关注x 1和x 2。但是 XLNet 算法不仅使用常规序列训练模型,还使用该序列的不同分解顺序来训练模型。因此,模型将看到所有四个分解顺序以及原始输入。例如,使用 [ x 3 , x 2, x 4 , x 1 ], x 3将无法处理任何其他元素,因为它是第一个元素。或者,使用 [ x 2 , x 4 , x 3 , x 1 ],x 3将能够处理x 2和x 4。在以前的情况下,x 4将无法访问。图中的黑色箭头表示x 3可以关注的元素,具体取决于分解顺序(不可用元素没有箭头)。
但是这怎么能起作用,如果序列不按其自然顺序,那么当序列失去意义时,训练的意义何在?为了回答这个问题,让我们记住,transformer 没有隐式循环机制,相反,我们使用显式位置编码来传达元素的位置。我们还要记住,在常规的 Transformer 解码器中,我们使用自注意力掩码来限制对当前元素之后的序列元素的访问。当我们用另一个分解顺序输入一个序列时,比如说[ x 2 , x 4 , x 3 , x 1],序列的元素将保持其原始位置编码,并且转换器不会丢失其正确顺序。事实上,输入仍然是原始序列 [ x 1 , x 2 , x 3 , x 4 ],但具有更改的注意掩码以仅提供对元素x 2和x 4的访问。
为了形式化这个概念,让我们引入一些符号:![]() 是长度为T的索引序列 [1, 2, . . . , T ];
是长度为T的索引序列 [1, 2, . . . , T ]; ![]() 是的一个排列
是的一个排列 ![]() ;
;![]() 是该排列的第t个元素;
是该排列的第t个元素;![]() 是该排列的前t-1 个元素,并且
是该排列的前t-1 个元素,并且![]() 是给定当前排列
是给定当前排列![]() (自回归任务,它是模型的输出)下一个单词
(自回归任务,它是模型的输出)下一个单词![]() 的概率分布,其中 θ 是模型参数。那么,置换语言建模目标如下:
的概率分布,其中 θ 是模型参数。那么,置换语言建模目标如下: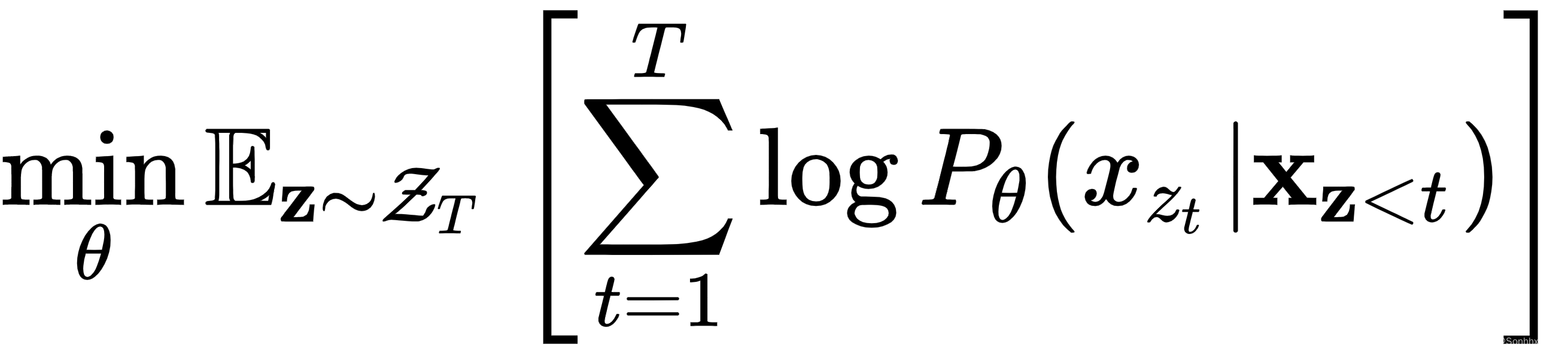
它一次对输入序列的不同分解顺序进行采样,并尝试最大化概率![]() ——即增加模型预测正确单词的机会。参数 θ 在所有分解阶数之间共享;因此,模型将能够看到每一个可能的元素
——即增加模型预测正确单词的机会。参数 θ 在所有分解阶数之间共享;因此,模型将能够看到每一个可能的元素![]() ,从而模拟双向上下文。同时,这仍然是一个自回归函数,不需要[MASK]令牌。
,从而模拟双向上下文。同时,这仍然是一个自回归函数,不需要[MASK]令牌。
我们还需要一块来充分利用基于排列的预训练。我们将从定义下一个单词的概率分布开始![]() ,给定当前排列
,给定当前排列![]() (自回归任务,它是模型的输出)
(自回归任务,它是模型的输出)![]() ,它只是模型的 softmax 输出:
,它只是模型的 softmax 输出:
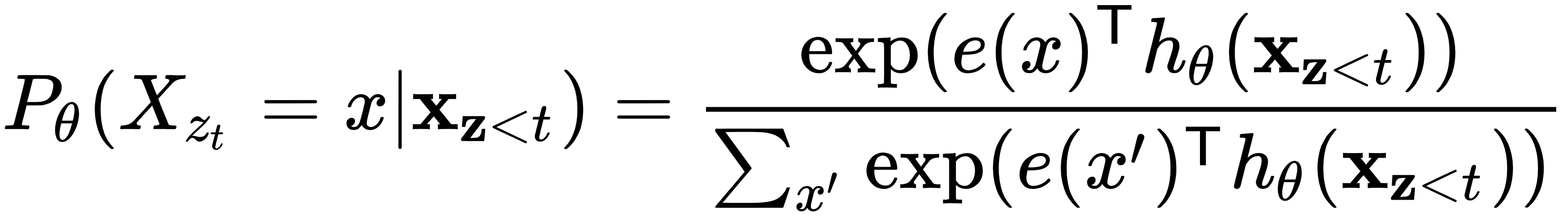
在这里,![]() 作为查询,
作为查询,![]() 是转换器在适当掩码后产生的隐藏表示,作为键值数据库。
是转换器在适当掩码后产生的隐藏表示,作为键值数据库。
接下来,假设我们有两个分解顺序![]() 和
和![]() ,其中前两个元素相同,后两个元素交换。我们还假设t = 3——也就是说,模型必须预测序列的第三个元素。由于
,其中前两个元素相同,后两个元素交换。我们还假设t = 3——也就是说,模型必须预测序列的第三个元素。由于![]() ,我们可以看到
,我们可以看到![]() 在两种情况下都是相同的。因此,
在两种情况下都是相同的。因此,![]() 。但这不是一个有效的结果,因为在第一种情况下,模型应该预测x 4,而在第二种情况下,应该预测x 1。让我们记住,虽然我们预测x 1和x 4在位置 3,它们仍然保持其原始位置编码。因此,我们可以更改当前公式以包含预测元素的位置信息(对于x 1和x 4将不同),但排除实际单词。换句话说,我们可以将模型的任务从预测下一个词修改为预测下一个词,假设我们知道它的位置。这样,两个样本分解顺序的公式就会不同。修改后的公式如下:
。但这不是一个有效的结果,因为在第一种情况下,模型应该预测x 4,而在第二种情况下,应该预测x 1。让我们记住,虽然我们预测x 1和x 4在位置 3,它们仍然保持其原始位置编码。因此,我们可以更改当前公式以包含预测元素的位置信息(对于x 1和x 4将不同),但排除实际单词。换句话说,我们可以将模型的任务从预测下一个词修改为预测下一个词,假设我们知道它的位置。这样,两个样本分解顺序的公式就会不同。修改后的公式如下:
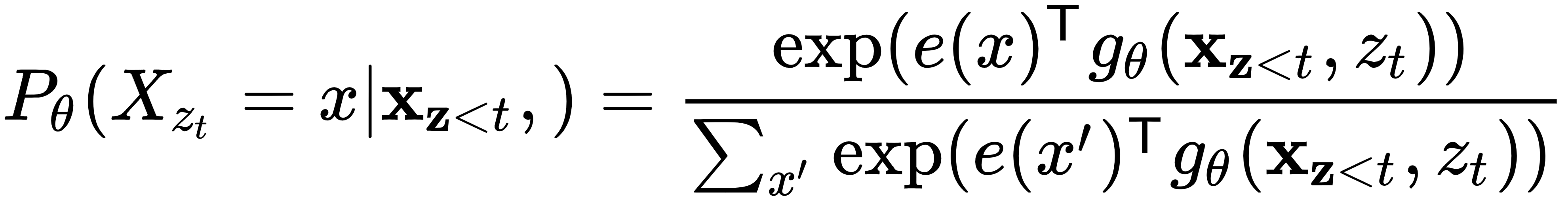
这里,![]() 是 新的transformer函数,它也包含了位置信息
是 新的transformer函数,它也包含了位置信息![]() 。该论文的作者提出了一种称为双流自我注意的特殊机制来解决这个问题。顾名思义,它由两种组合的注意力机制组成:
。该论文的作者提出了一种称为双流自我注意的特殊机制来解决这个问题。顾名思义,它由两种组合的注意力机制组成:
- 内容表示
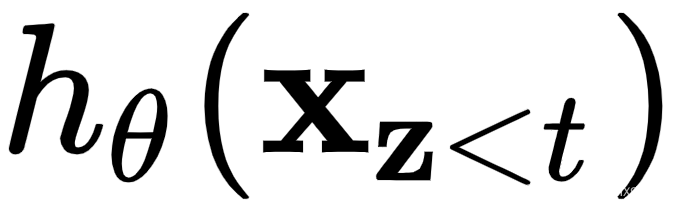 ,也就是我们已经熟悉的注意力机制。这种表示对上下文和内容本身都进行了编码。
,也就是我们已经熟悉的注意力机制。这种表示对上下文和内容本身都进行了编码。 - 查询表示
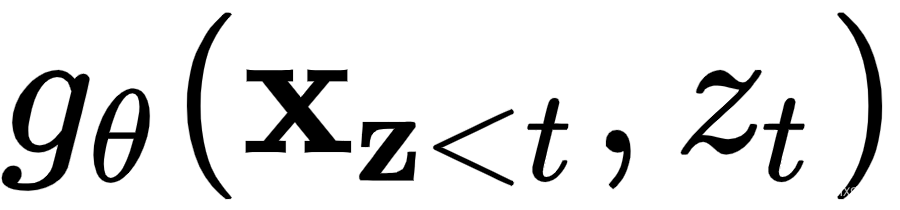 ,它只能访问上下文信息
,它只能访问上下文信息 和位置
和位置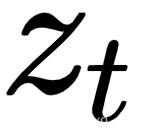 ,而不是内容
,而不是内容 ,正如我们之前提到的。
,正如我们之前提到的。
我鼓励您查看原始论文以获取更多详细信息。在下一节中,我们将实现一个 Transformer 语言模型的基本示例。
使用转换器语言模型生成文本
在本节中,我们将借助 Hugging Face 发布的transformers2.1.1库( 🤗 Transformers ) 实现一个基本的文本生成示例。这是一个维护良好且流行的开源包,它实现了不同的转换器语言模型,包括 BERT、transformer-XL、XLNet、OpenAI GPT、GPT-2 等。我们将使用预训练的 Transformer-XL 模型根据初始输入序列生成新文本。目标是让您简要了解该库:
1.让我们从导入开始:
import torch
from transformers import TransfoXLLMHeadModel, TransfoXLTokenizerTransfoXLLMHeadModel和TransfoXLTokenizer短语是transformer-XL语言模型及其对应的分词器的实现。
2.接下来,我们将初始化设备并实例model化tokenizer. 请注意,我们将使用transfo-xl-wt103库中提供的预训练参数集:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 实例化预训练模型特定的分词器和模型本身
tokenizer = TransfoXLTokenizer.from_pretrained('transfo-xl-wt103')
model = TransfoXLLMHeadModel.from_pretrained('transfo-xl-wt103').to(device)3.然后,我们将指定初始序列,对其进行标记,并将其转换为模型兼容的输入tokens_tensor,其中包含标记列表:
text = "The company was founded in"
tokens_tensor = \
torch.tensor(tokenizer.encode(text)) \
.unsqueeze(0) \
.to(device)4.接下来,我们将使用这个标记来启动一个循环,模型将在其中生成序列的新标记:
mems = None # 递归机制
predicted_tokens = list()
for i in range(50): # stop at 50 predicted tokens
# Generate predictions
predictions, mems = model(tokens_tensor, mems=mems)
# 获取最可能的词索引
predicted_index = torch.topk(predictions[0, -1, :], 1)[1]
# 从索引中提取词
predicted_token = tokenizer.decode(predicted_index)
# break if [EOS] reached
if predicted_token == tokenizer.eos_token:
break
# 存储当前token
predicted_tokens.append(predicted_token)
# 将新token附加到现有序列
tokens_tensor = torch.cat((tokens_tensor, predicted_index.unsqueeze(1)), dim=1)我们从初始的记号序列开始循环tokens_tensor。该模型使用它来生成predictions(词汇表所有标记的 softmax)和mems(存储递归关系的先前隐藏解码器状态的变量)。我们提取最可能单词的索引predicted_index并将其转换为词汇标记predicted_token。然后,我们将它附加到现有tokens_tensor的并使用新序列再次启动循环。循环在 50 个令牌之后或[EOS]达到特殊令牌时结束。
5.最后,我们将显示结果:
print('Initial sequence: ' + text)
print('Predicted output: ' + " ".join(predicted_tokens))程序的输出如下:
Initial sequence: The company was founded in Predicted output: the United States .
通过这个例子,我们结束了一个关于注意力模型的长章。
概括
在本章中,我们专注于 seq2seq 模型和注意力机制。首先,我们讨论并实现了一个常规的循环编码器-解码器 seq2seq 模型,并学习了如何用注意力机制补充它。然后,我们讨论并实现了一种纯粹基于注意力的模型,称为Transformer。我们还在他们的上下文中定义了多头注意力。接下来,我们讨论了转换器语言模型(例如 BERT、transformerXL 和 XLNet)。transformers最后,我们使用该库实现了一个简单的文本生成示例。



















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











