







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
一般来说,数据工程是指跨组织的数据和数据流的管理和组织。它涉及数据收集、处理、版本控制、数据治理和分析。围绕数据处理平台、数据湖、数据集市、数据仓库和数据流的开发和维护是一个巨大的话题。这是有助于成功的重要实践大数据和机器学习( ML ) 项目。在本章中,您将了解数据工程的 ML 特定主题。
大量 ML 教程/书籍以干净的数据集和 CSV 文件开始,用于构建模型。现实世界是不同的。数据有多种形式和大小,您必须制定明确的策略来大规模收集、处理和准备数据。本章将讨论可以为 ML 项目中的数据工程提供基础的开源工具。您将学习如何在 Kubernetes 平台上安装开源工具集,以及这些工具如何使您和您的团队更加高效和敏捷。
在本章中,您将了解以下主题:
- 配置 Keycloak 进行身份验证
- 配置开放数据中心组件
- 了解和使用 JupyterHub IDE
- 了解 Apache Spark 的基础知识
- 了解 Open Data Hub 如何按需提供 Apache Spark 集群
- 从 Jupyter Notebook 编写和运行 Spark 应用程序
技术要求
本章包括一些动手设置和练习。您将需要一个使用Operator Lifecycle Manager配置的正在运行的 Kubernetes 集群。第 3 章“探索 Kubernetes”中介绍了构建这样的 Kubernetes 环境。在尝试本章中的技术练习之前,请确保您的 Kubernetes 集群上安装了一个正常工作的 Kubernetes 集群和开放数据中心( ODH )。第 4 章“机器学习平台剖析”中介绍了 ODH 的安装。您可以在https://github.com/PacktPublishing/Machine-Learning-on-Kubernetes找到与本书相关的所有代码。
配置 Keycloak 进行身份验证
在你面前开始使用您平台的任何组件,您需要配置身份验证系统以与平台组件相关联。如第 4 章机器学习平台剖析中所述,您将使用开源软件 Keycloak 来提供身份验证服务。
第一步,从chapter5/realm-export.json中导入配置,该配置可在与本书相关的代码库中找到。此文件包含关联平台组件的 OAuth2 功能所需的配置。
尽管这本书无论如何都不是 Keycloak 指南,但我们将提供一些基本定义,让您了解 Keycloak 服务器的高级分类:
- 领域:钥匙斗篷领域是管理属于同一域的用户、角色、组和客户端应用程序的对象。一台 Keycloak 服务器可以有多个领域,因此您有多组配置,例如一个领域用于内部应用程序,一个领域用于外部应用程序。
- 客户:客户是可以请求用户身份验证的实体。Keycloak 客户端对象是与领域相关联。我们平台中所有需要单点登录( SSO ) 的应用程序都将在 Keycloak 服务器中注册为客户端。
- 用户和组:这两个术语是不言自明的,您将在以下步骤中创建一个新用户并使用它来登录不同的软件平台的。
下一步是配置 Keycloak 为我们的 ML 平台组件提供 OAuth 功能。
导入 ODH 组件的 Keycloak 配置
在这个部分,您将导入客户端和组配置到运行在 Kubernetes 集群上的 Keycloak 服务器上。以下步骤会将所有内容导入 Keycloak 服务器的主域:
1.使用用户名admin和密码admin登录到您的 Keycloak 服务器。单击管理标题下左侧边栏上的导入链接:
图 5.1 – Keycloak Master 领域
2.点击屏幕上的选择文件按钮,如下:
图 5.2 – Keycloak 导入配置页面
3.选择第5 章/realm-export.json文件从弹出窗口。之后,为If a resource exists下拉选项选择Skip ,然后单击Import:
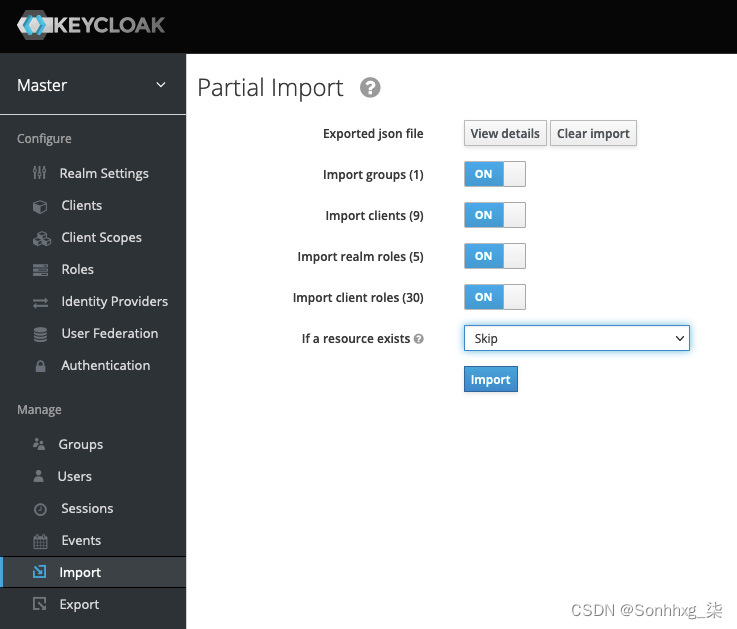
图 5.3 – Keycloak 导入配置页面
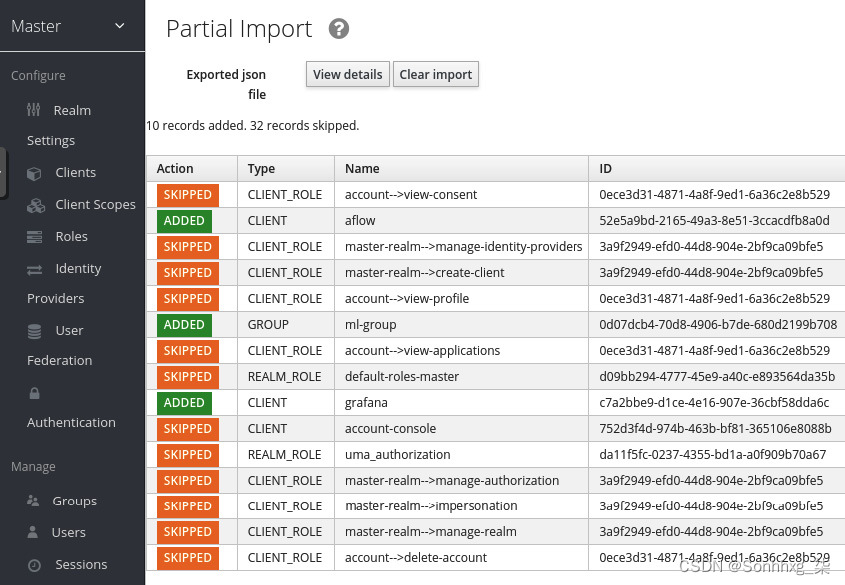
图 5.4 – Keycloak 导入配置结果页面
5.证实那通过单击左侧菜单上的Clients项创建了四个客户端。应存在以下客户端 ID:aflow、mflow、grafana和jhub。aflow客户端用于平台的工作流引擎,它是Apache Airflow的一个实例。mflow客户端用于模型注册和训练跟踪工具,是一个MLflow的实例。grafana客户端用于监控 UI 和是Grafana的一个实例。最后,jhub客户端用于JupyterHub服务器实例。
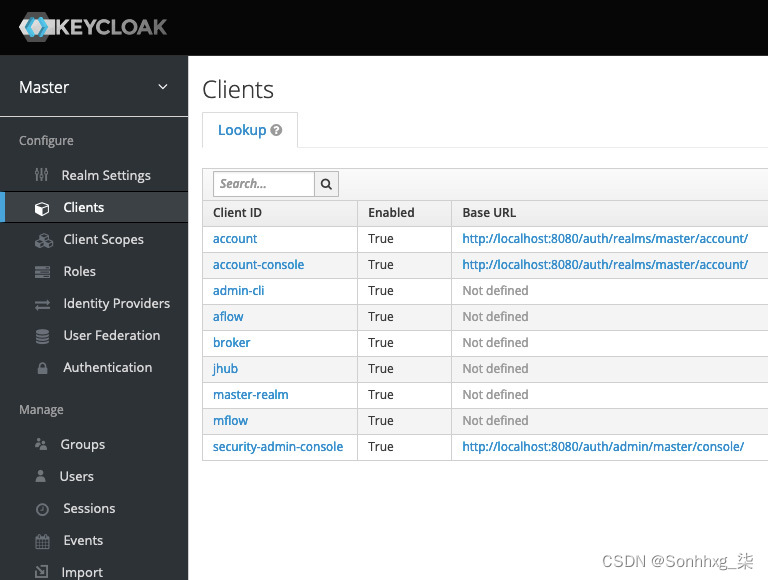
图 5.5 – Keycloak 客户端页面
6.验证一个通过单击左侧面板上的Groups链接创建了名为ml-group的组:
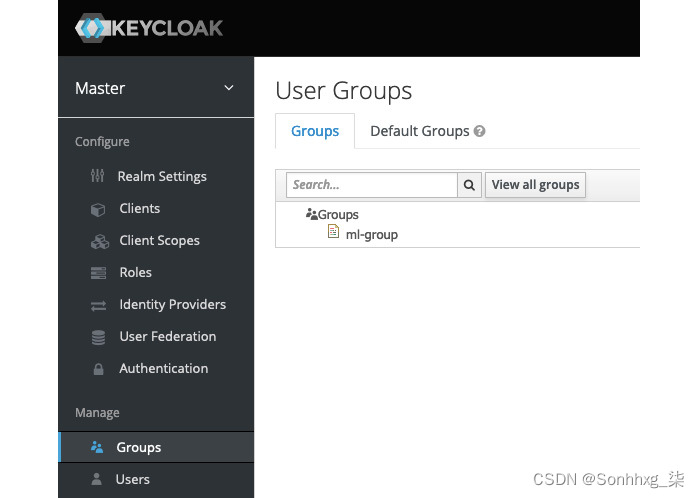
图 5.6 – Keycloak 组页面
您将使用此用户组来创建平台用户。
做得好!您刚刚为 ML 平台配置了多个 Keycloak 客户端。下一步是在 Keycloak 中创建一个用户,您将在本书的其余部分使用该用户。请务必注意,Keycloak 可以与您的企业目录或任何其他数据库并将它们用作用户的来源。请记住,我们在这里使用的领域配置非常基础,不建议用于生产用途。
创建 Keycloak 用户
在本节中,您将创建一个新用户并将新创建的用户与上一节中导入的组相关联。将用户与组相关联提供了不同 ODH 软件所需的角色:
1.在 Keycloak 页面的左侧,单击“用户”链接进入该页面。要添加新用户,请单击右侧的添加用户按钮:

图 5.7 – Keycloak 用户列表
2.添加用户名mluser并确保User Enabled和Email Verified切换按钮设置为ON。在Groups中,选择ml-group组并填写Email、First Name和Last Name字段,如图 5.8所示,然后点击保存按钮:
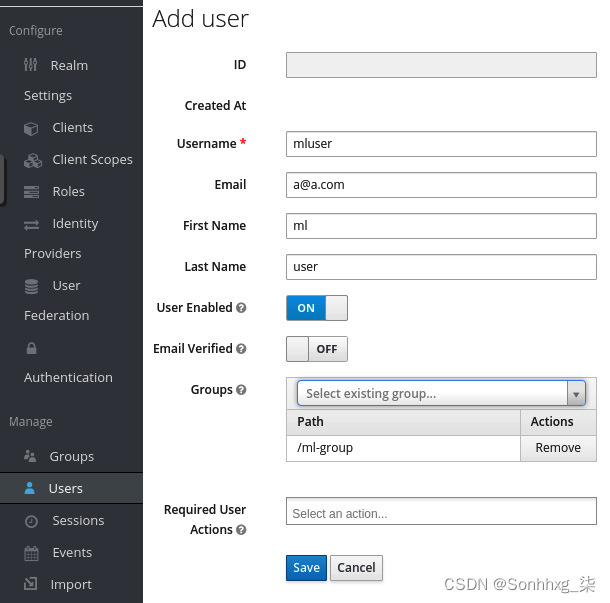
图 5.8 – Keycloak 添加用户页面
3.单击凭据选项卡为您的用户设置密码:
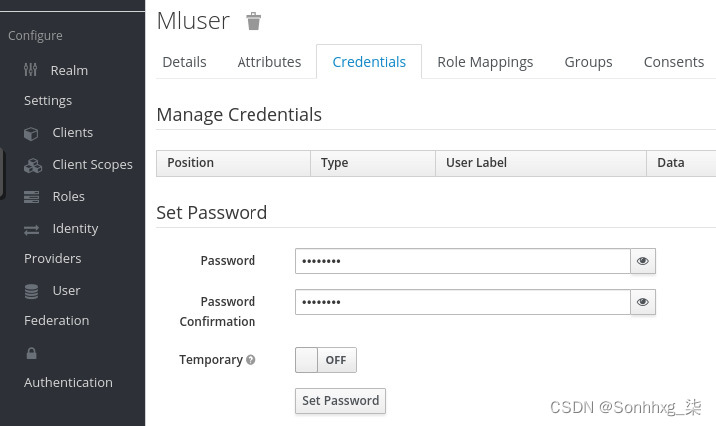
图 5.9 – Keycloak Credentials 页面
4.输入您选择的密码,然后禁用临时标志,然后点击设置密码按钮。
您刚刚在 Keycloak 中创建并配置了一个用户。您的 Keycloak 服务器现在已准备好供 ML 平台组件使用。下一步是探索组件为 ML 项目中的所有角色提供主要编码环境的平台。
配置 ODH 组件
在第 4 章,机器学习平台剖析中,您已经安装了 ODH 算子。使用ODH 操作员,您现在将配置一个 ODH 实例,该实例将自动安装 ML 平台的组件。ODH执行Kustomize脚本以安装 ML 平台的组件。作为本书代码的一部分,我们提供了模板来安装和配置运行平台所需的所有组件。
您还可以通过清单文件配置 ODH 操作员为您安装的组件。您可以将特定配置传递给清单并选择您需要的组件。本书的代码存储库manifests/kfdef/ml-platform.yaml中提供了一个这样的清单。此 YAML 文件是为 ODH 操作员配置的,以发挥其魔力并安装我们需要成为平台一部分的软件。您将需要对此文件进行一些修改,您将在下一节中看到。
该文件定义了您平台的组件以及这些组件获取设置的位置:
- Name:定义组件的名称。
- repoRef:此部分包含path属性,您可以在其中定义配置此组件所需的文件的相对路径位置。
- 参数:此部分包含将用于配置组件的参数。请注意,在以下示例中,需要根据您的配置更改KEYCLOAK_URL和JUPYTERHUB_HOST的 IP 地址。
- 叠加层:ODH运算符包含每个组件的默认配置集。覆盖提供了一种进一步调整默认配置的方法。覆盖列表是一组文件夹,与清单文件位于同一位置。ODH 操作员将从这些覆盖文件夹中读取文件并即时合并它们以生成最终配置。您可以在代码存储库的manifests/jupytherhub/overlays文件夹中找到 JupyterHub 的覆盖。
- Repos:此配置部分特定于每个清单文件,并适用于清单中的所有组件。它定义了包含此清单文件引用的所有文件的 Git 存储库的位置和版本。如果您希望清单引用您自己的安装文件,您需要在此处引用正确的 Git 存储库(包含您的文件的存储库)。
图 5.10显示了包含 JupyterHub 组件定义的清单文件部分:
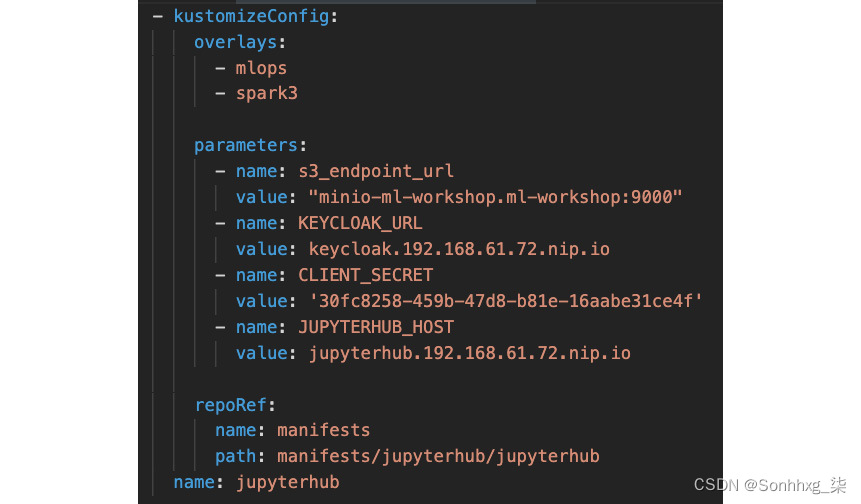
图 5.10 – ODH 清单文件中的一个组件
您将使用提供的清单文件来创建 ML 平台的实例。您还可以通过修改此文件来调整配置或添加或删除平台的组件。但是,对于书中的练习,我们不推荐除非您被指示这样做,否则更改此设置。
现在您已经看到了 ODH 清单文件,是时候充分利用它在 Kubernetes 上创建您的第一个 ML 平台了。
安装 ODH
在我们可以之前安装平台的数据工程组件,我们首先需要创建一个ODH的实例。ODH 实例是相关工具集的精选集合,可用作 ML 平台的组件。尽管 ML 平台可能包含 ODH 提供的组件以外的组件,但可以说 ODH 的一个实例是 ML 平台的一个实例。您也可以在同一个 Kubernetes 集群上运行多个 ODH 实例,只要它们运行在各自独立的 Kubernetes 命名空间上即可。当您组织中的多个团队或部门共享一个 Kubernetes 集群时,这很有用。
以下是在 Kubernetes 集群上创建 ODH 实例所需遵循的步骤:
1.使用以下命令在 Kubernetes 集群中创建一个新的命名空间:
kubectl create ns ml-workshop您应该看到以下响应:

图 5.11 – Kubernetes 集群中的新命名空间
kubectl get pods -n operators您应该看到以下响应。确保状态显示Running:

图 5.12 – ODH 运营商的状态
3.获取您的minikube环境的 IP 地址。这个 IP 地址将用于为平台的不同组件创建入口,就像我们为 Keycloak 所做的那样。请注意,每个minikube实例的 IP 可能不同,具体取决于您的底层基础设施:
minikube ip此命令应为您提供minikube集群的 IP 地址。
4.打开manifests/kfdef/ml-platform.yaml文件并将以下参数的值更改为您的minikube实例的 NIP ( nip.io ) 域名。只替换域名的IP地址部分。例如,KEYCLOAK_URL keycloak.<IP Address>.nip.io应该变成keycloak.192.168.61.72.nip.io。请注意,这些参数可能在此文件中不止一处被引用。在完整的 Kubernetes 环境中,<IP 地址>应该是您的 Kubernetes 集群的域名:
- KEYCLOAK_URL
- JUPYTERHUB_HOST
- AIRFLOW_HOST
- MINIO_HOST
- MLFLOW_HOST
- GRAFANA_HOST
5.使用以下命令将清单文件应用到您的 Kubernetes 集群:
kubectl create -f manifests/kfdef/ml-platform.yaml -n ml-workshop您应该看到以下响应:

图 5.13 – 为 ODH 组件应用清单的结果
6.使用以下命令开始观察在ml-workshop命名空间中创建的 pod。安装所有组件需要一段时间。几分钟后,所有 Pod 将处于运行状态。在创建 pod 时,您可能会看到一些 pod 抛出错误。这是正常的,因为某些 pod 依赖于其他 pod。请耐心等待所有组件聚集在一起,pod 将进入运行状态:
watch kubectl get pods -n ml-workshop当所有 pod 都在运行时,您应该会看到以下响应:
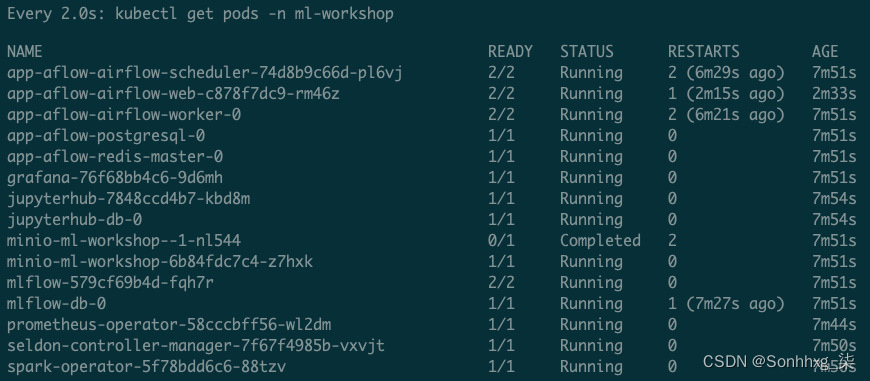
图 5.14 – 显示在 Kubernetes 集群上运行的 ODH 组件的 CLI 响应
所以呢这个命令有作用吗?开放数据中心( ODH ) 操作员使用您在步骤 5中创建的kfdef 自定义资源定义( CRD ) 。然后操作员遍历 CRD 中的每个应用程序对象,并创建所需的 Kubernetes 对象来运行这些应用程序。在您的集群中创建的 Kubernetes 对象包括多个 Deployment、Pod、Services、Ingress、ConfigMap、Secrets 和 PersistentVolumeClaims。您还可以运行以下命令来查看在ml-workshop命名空间中创建的所有对象:
kubectl get all -n ml-workshop您应该会看到ODH 操作员在ml-workshop命名空间中创建的所有对象。
恭喜!您刚刚创建了一个新的 ODH 实例。现在您已经了解了从清单文件创建 ML 平台实例的过程,是时候看看数据工程师将用于他们的平台的每个组件了。活动。
MINIKUBE 使用 PODMAN 驱动程序
笔记那对于在 Linux中使用podman驱动程序的一些minikube设置,由于线程数的限制,Spark 运算符可能会失败。要解决此问题,您需要在minikube配置中使用kvm2驱动程序。您可以通过将--driver=kvm2参数添加到您的minikube 启动命令来执行此操作。
了解和使用 JupyterHub
木星笔记本已成为为 ML 项目编写代码的非常流行的工具。JupyterHub 是一种软件,可促进计算环境的自助配置,包括启动预配置的 Jupyter Notebook 服务器并在 Kubernetes 平台上配置相关的计算资源。数据工程师和数据科学家等按需最终用户可以配置自己的 Jupyter Notebook 实例,专供他们使用。如果请求用户已经拥有他/她自己的 Jupyter Notebook 运行实例,则集线器只会将用户引导到现有实例,避免重复环境。从最终用户的角度来看,整个交互是无缝的。您将在本章的下一部分看到这一点。
当用户请求 JupyterHub 中的环境时,他们还可以选择预配置的硬件资源大小,例如 CPU、内存和存储。这为开发人员、数据工程师和数据科学家提供了一种灵活的方式,可以为给定任务提供适量的计算资源。底层 Kubernetes 平台促进了这种资源的动态分配。
不同的用户可能需要不同的框架、库和编码环境风格。一些数据科学家可能想使用 TensorFlow,而另一些数据科学家则想使用 scikit-learn 或 PyTorch。一些数据工程师可能更喜欢使用 pandas,而另一些可能需要在 PySpark 中运行他们的数据管道。在 JupyterHub 中,他们可以为此类场景配置多个预定义环境。然后,用户可以在请求新环境时选择预定义配置。这些预定义的环境实际上是容器镜像。这意味着平台运营商或平台管理员可以准备几个预定义的容器镜像,作为最终用户的计算环境。此功能还支持环境标准化。在不同的开发人员计算机上,您必须处理多少次不同版本的库?环境的标准化可以减少与库版本不一致相关的问题的数量,并且通常可以减少它适用于我的机器问题。
图 5.15显示配置新 JupyterHub 的三步过程环境:

图 5.15 – 在 JupyterHub 中创建新环境的工作流程
现在您知道 JupyterHub 可以做什么,让我们看看它的实际应用。
验证 JupyterHub 安装
每一个数据团队中的工程师遵循配置环境的简单和标准工作流程。不再需要手动安装和摆弄他们的工作站配置。这对于自治团队来说非常有用,并且肯定会帮助您提高团队的速度。
ODH 操作员已经在前面的部分中为您安装了 JupyterHub。现在,作为数据工程师,您将启动一个新的 Jupyter Notebook 环境,并编写您的数据管道:
1.使用以下命令获取在 Kubernetes 环境中创建的入口对象。我们正在运行这个命令来查找 JupyterHub 的 URL:
kubectl get ingress -n ml-workshop您应该看到以下示例响应。记下HOSTS列中显示的 JupyterHub URL:

图 5.16 – 集群中的所有入口
2.从运行 minikube 的同一台机器上打开浏览器并导航到 JupyterHub URL。该 URL 类似于 https://jupyterhub.<MINIKUBE IP ADDRESS>.nip.io。此 URL 将带您到用于执行 SSO 身份验证的 Keycloak 登录页面。确保在此 URL 中将 IP 地址替换为您的 minikube IP 地址:
图 5.17 – JupyterHub 的 SSO 挑战
3.输入mluser作为用户名,然后输入您为此用户设置的任何密码,然后单击Sign In。
你会查看 JupyterHub 服务器的登录页面,您可以在其中选择要使用的笔记本容器映像以及所需的预定义计算资源大小。
笔记本图像部分包含您使用代码存储库的manifests/jupyterhub-images文件夹中的 ODH 清单配置的标准笔记本。
容器大小下拉菜单允许您根据需要选择合适的环境大小。此配置也通过manifests/jupyterhub/jupyterhub/overlays/mlops/jupyterhub-singleuser-profiles-sizes-configmap.yaml清单文件控制。
我们鼓励您查看这些文件以熟悉可以为每个清单设置的配置。
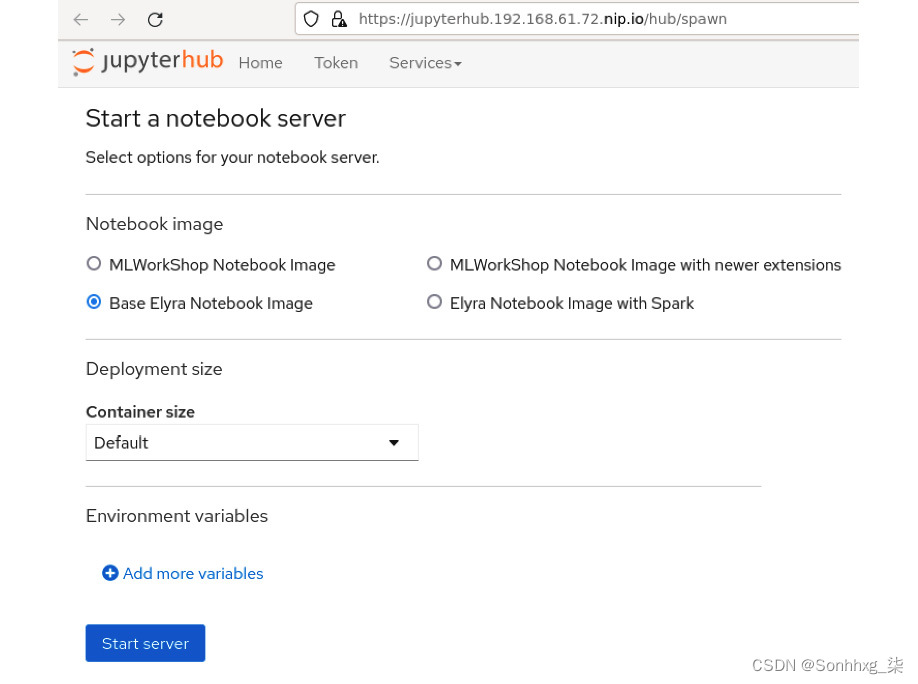
图 5.18 – JupyterHub 登陆页面
选择Base Elyra Notebook Image和默认容器大小并点击Start server。
4.通过发出以下命令来验证是否已为您的用户创建了一个新 pod。Jupyter Notebook 实例名称以jupyter-nb- 开头,并以用户的用户名作为后缀。这允许为每个用户使用唯一的笔记本 pod 名称:
kubectl get pods -n ml-workshop | grep mluser您应该看到以下响应:

图 5.19 – JupyterHub 创建的 Jupyter Notebook pod
5.恭喜!您现在正在 Kubernetes 平台上运行自己的自配置 Jupyter Notebook 服务器。

图 5.20 – Jupyter Notebook 登陆页面
6.现在,让我们停止笔记本服务器。点击文件 > Hub 控制面板菜单选项,进入Hub 控制面板页面,如下所示:
图 5.21 – 用于查看集线器控制面板的菜单选项
7.点击停止我的服务器按钮。这就是您停止 Jupyter Notebook 实例的方式。您可能希望稍后重新启动它以执行后续步骤。
图 5.22 – 集线器控制面板
8.通过发出以下命令来验证是否已为您的用户销毁了新的 pod:
kubectl get pods -n ml-workshop | grep mluser此命令应该没有输出,因为 Jupyter Notebook pod 已被 JupyterHub 销毁。
我们留给您探索您的环境中笔记本配置的不同部分。您将在后面的部分中使用这个 Jupyter notebook 编写代码本章和本书的后面几章,所以如果你只是想继续阅读,你不会错过任何东西。
运行你的第一个 Jupyter 笔记本
现在你的 Jupyternotebook 正在运行,是时候编写Hello World 了!程序。在本书的代码库中,我们提供了一个这样的程序,在接下来的步骤中,您将使用 Git 签出代码并运行该程序。在我们开始这些步骤之前,请确保您可以使用浏览器访问您的 Jupyter 笔记本,如上一节所述:
1.单击 Jupyter 笔记本左侧菜单上的 Git 图标。图标是从上数第三个。它将显示三个用于不同操作的按钮。单击克隆存储库按钮:

图 5.23 – Jupyter notebook 中的 Git 操作
2.在Clone a repo弹出窗口中框,输入本书代码存储库的位置GitHub - PacktPublishing/Machine-Learning-on-Kubernetes: Machine Learning on Kubernetes, published by packt,然后点击CLONE。

图 5.24 – Git 克隆 Jupyter 笔记本中的存储库
3.你会看见将代码存储库克隆到 Jupyter 笔记本的文件系统中。如图 5.25所示,导航到chapter5/helloworld.ipynb文件并在笔记本中打开它。单击顶部栏上的小播放图标以运行单元格:

图 5.25 – Jupyter 环境中的笔记本
4.瞧!您刚刚在运行在 Kubernetes 上的自配置 Jupyter Notebook 服务器中执行了 Python 代码。
5.通过选择文件 > 集线器控制面板菜单选项关闭您的笔记本电脑。单击停止我的服务器按钮以关闭您的环境。请注意,ODH 将保存您的磁盘,下次启动笔记本时,您保存的所有文件都将可用。
恭喜!轮到你了可以在平台上运行您的代码。接下来,我们将为 Apache Spark 引擎更新一些基础知识。
了解 Apache Spark 的基础知识
Apache Spark 是一个开放的源数据为分布式大规模数据处理而设计的处理引擎。这意味着,如果您有较小的数据集,例如 10 甚至几百 GB,则经过调整的传统数据库可能会提供更快的处理时间。Apache Spark 的主要区别在于它能够执行内存中的中间计算,这使得 Apache Spark 比 Hadoop MapReduce 快得多。
Apache Spark 旨在提高速度、灵活性和易用性。Apache Spark 提供了 70 多个高级数据处理运算符,使数据工程师可以轻松构建数据应用程序,因此可以轻松使用 Apache Spark API 编写数据处理逻辑。灵活意味着 Spark 作为一个统一的数据处理引擎工作,可以处理多种类型的数据工作负载,例如批处理应用程序、流应用程序、交互式查询,甚至 ML 算法。
图 5.26显示了 Apache Spark 组件:

图 5.26 – Apache Spark 组件
了解 Apache Spark 作业执行
大多数数据工程师现在知道 Apache Spark 是一个大规模并行数据处理引擎。它是 Apache 软件基金会最成功的项目之一。Spark 传统上运行在由多个虚拟机( VM ) 组成的集群上,或者裸机服务器。然而,随着容器和 Kubernetes 的普及,Spark 增加了对在 Kubernetes 上的容器上运行 Spark 集群的支持。
在 Kubernetes 上运行 Spark 有两种最常见的方式。第一种方式,也是原生方式,是使用 Kubernetes 引擎本身来编排 Kubernetes worker pod。在这种方法中,Spark 集群实例始终在运行,并且 Spark 应用程序被提交到 Kubernetes API,后者将调度提交的应用程序。我们不会深入研究它是如何实现的。第二种方法是通过 Kubernetes 运营商。Operator 利用 Kubernetes CRD 在 Kubernetes 中本地创建 Spark 对象。在这种方法中,Spark 集群由 Spark 操作员动态创建。操作员无需将 Spark 应用程序提交到现有集群,而是按需启动 Spark 集群。
Spark 集群遵循管理器/工作器架构。Spark 集群管理器知道工作人员的位置以及可供工作人员使用的资源。Spark 集群管理应用程序将运行的工作节点集群的资源。每个工作人员都有一个或多个执行器,它们通过执行器运行分配的作业。
Spark 应用程序有两部分,驱动程序组件和数据处理逻辑。驱动程序组件负责执行数据处理操作的流程。驱动程序运行首先与集群管理器对话,以找出哪些工作节点将运行应用程序逻辑。驱动程序将所有应用程序操作转换为任务,对其进行调度,并将任务直接分配给工作节点上的执行程序进程。一个执行器可以运行与同一个 Spark 上下文相关联的多个任务。
如果您的应用程序要求您收集计算结果并将它们合并,则驱动程序将负责此活动。作为一名数据工程师,所有这些活动都是通过 SparkSession 对象从您那里抽象出来的。您只需要编写数据处理逻辑。我们提到 Apache Spark 的目标是简单吗?
图 5.27展示了 Spark driver、Spark cluster manager 和 Spark worker 之间的关系节点:
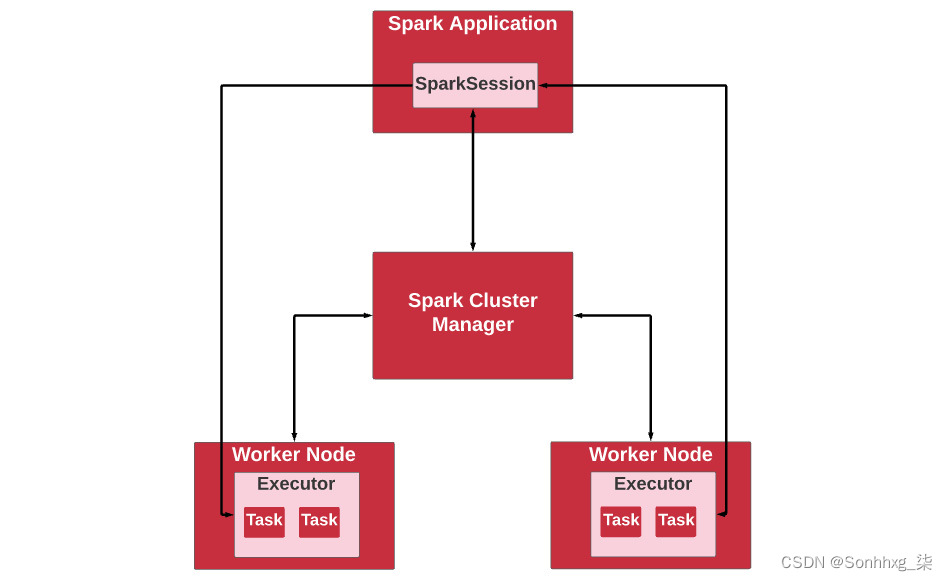
图 5.27 – Apache Spark 组件之间的关系
了解 ODH 如何按需配置 Apache Spark 集群
我们有谈过关于 ODH 如何让您创建一个动态且灵活的开发环境来使用 Jupyter Notebook 编写数据管道等代码。我们注意到,数据开发人员需要与 IT 进行交互才能在 Apache Spark 等数据处理集群上获得时间。这些交互降低了团队的敏捷性,这是 ML 平台解决的问题之一。为了遵守这种情况,ODH 提供了以下组件:
- 生成 Apache Spark 集群的 Spark 运算符。在本书中,我们对 ODH 和 radanalytics 提供的原始 Spark 运算符进行了分叉,以遵循 Kubernetes API 的最新更改。
- JupyterHub 中的一项功能,可在用户创建某些笔记本环境时向 Spark 操作员发出新 Spark 集群的请求。
作为一名数据工程师,当您使用某些笔记本图像启动新的笔记本环境时,JupyterHub 不仅会生成一个新的笔记本服务器,它还会通过 Spark 运算符为您创建专用的 Apache Spark 集群。
创建 Spark 集群
我们先来看看Spark 算子如何在 Kubernetes 集群上工作。ODH 创建 Spark 控制器。您可以在名称radanalyticsio-spark-cluster下的chapter5/ml-platform.yaml文件中看到配置,如图 5.28所示。您可以看到这是另一组 Kubernetes YAML 文件定义自定义资源定义( CRD )、所需角色和 Spark 操作员部署。所有这些文件都在本书代码库的manifests/radanalyticsio文件夹中。

图 5.28 - 安装 Spark 操作符的清单部分的片段
当您需要启动 Apache Spark 集群时,您可以通过创建 Kubernetes 自定义资源来实现称为SparkCluster。收到请求后,Spark Operator 将根据所需的配置配置一个新的 Spark 集群。以下步骤将向您展示在您的平台上配置 Spark 集群的步骤:
kubectl get pods -n ml-workshop | grep spark-operator您应该看到以下响应:

图 5.29 – Spark 操作员吊舱
2.使用chapter5/simple-spark-cluster.yaml中的文件创建一个带有一个工作节点的简单 Spark 集群。您可以看到该文件正在请求一个具有一个主节点和一个工作节点的 Spark 集群。通过这个自定义资源,您可以设置多个 Spark 配置,我们将在下一节中看到:
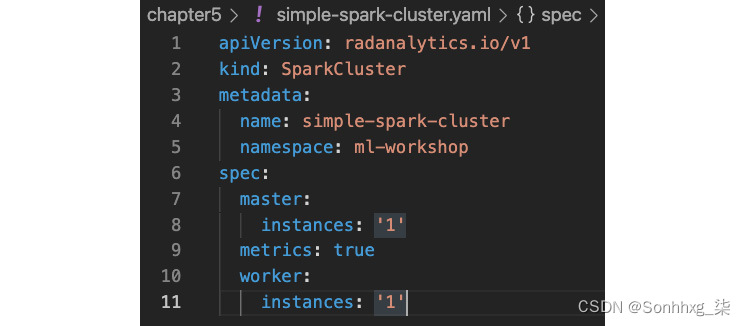
图 5.30 – Spark 自定义资源
通过运行以下命令在您的 Kubernetes 集群中创建此 Spark 集群自定义资源。Spark 算子在 Kubernetes 平台中不断扫描这个资源,并自动创建一个新的 Apache Spark 集群实例对于每个给定的 Spark 集群自定义资源:
kubectl create -f chapter5/simple-spark-cluster.yaml -n ml-workshop您应该看到以下响应:

图 5.31 – 创建 Spark 集群的响应
3.验证 Spark 集群 pod 是否在您的集群中运行:
kubectl get pods -n ml-workshop | grep simple-spark您应该看到以下响应。Spark 操作员创建了两个 Pod,一个用于 Spark 主节点,另一个用于工作节点。工作 pod 的数量取决于SparkCluster资源中实例参数的值。Pod 第一次进入运行状态可能需要一些时间:

图 5.32 – 正在运行的 Spark 集群 pod 列表
现在,您知道 Spark 运算符如何在 Kubernetes 集群上工作了。下一步是查看 JupyterHub 如何配置为在配置时动态请求集群给你一个新的笔记本。
了解 JupyterHub 如何创建 Spark 集群
简单地说,JupyterHub做你做过的事上一节。JupyterHub 在 Kubernetes 中创建SparkCluster资源,以便 Spark 操作员可以配置 Apache Spark 集群以供您使用。这个SparkCluster资源配置是一个 Kubernetes ConfigMap文件,可以在manifests/jupyterhub/jupyterhub/base/jupyterhub-spark-operator-configmap.yaml中找到。在该文件中查找sparkClusterTemplate ,如图 5.33所示。您可以看到它看起来像您在上一节中创建的文件:
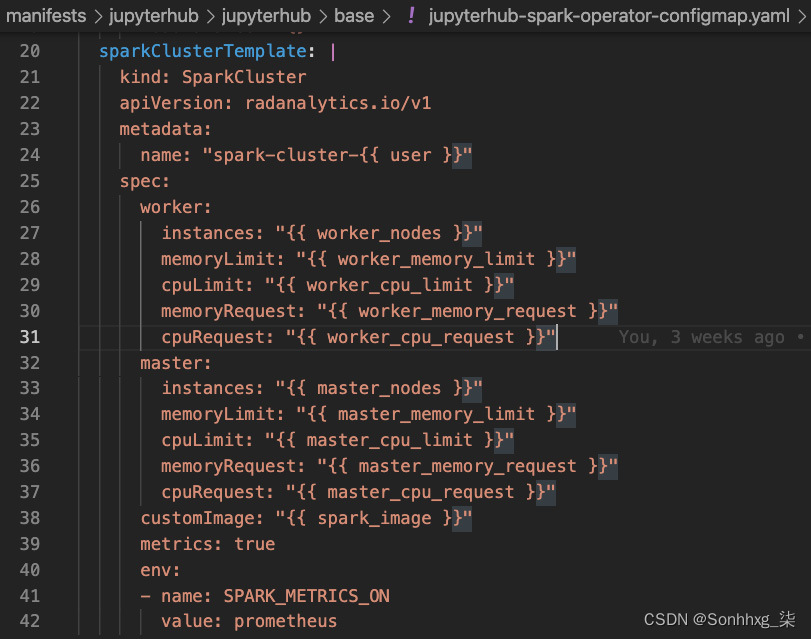
图 5.33 – Spark 资源的 JupyterHub 模板
一些你可能已经注意到这是一个模板,它需要此模板中提到的特定变量的值。{{ user }}和{{ worker_nodes }}等变量。回想一下,我们曾提到 JupyterHub 在为您的笔记本配置容器时创建SparkCluster请求。JupyterHub 使用此文件作为模板,并在创建笔记本时填写值。JupyterHub 如何决定创建 Spark 集群?这个配置是称为配置文件,可作为manifests/jupyterhub/jupyterhub/overlays/spark3/jupyterhub-singleuser-profiles-configmap.yaml中的ConfigMap文件使用。这看起来像图 5.33中所示的文件。
您可以看到image字段指定了将触发此配置文件的容器镜像的名称。因此,作为数据工程师,当您从 JupyterHub 登录页面选择此笔记本图像时,JupyterHub 将应用此配置文件。配置文件中的第二件事是env部分,它指定将推送到笔记本容器实例的环境变量。配置对象定义值那将应用于资源键中提到的模板:
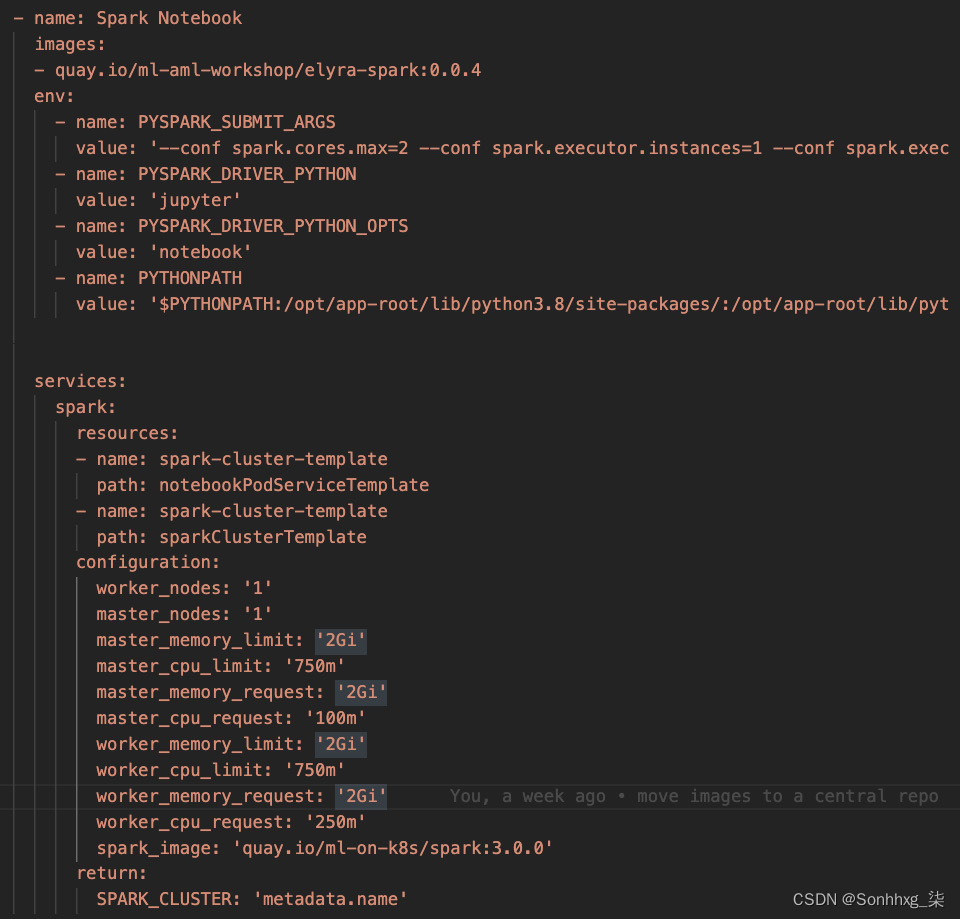
图 5.34 – Spark 资源的 JupyterHub 配置文件
您可能会欣赏,在幕后做了很多工作来为您和您的团队提供简化的体验,并且在真正意义上的开源中,您可以配置所有内容,甚至在出现时回馈项目有任何修改或者新的功能。
在下一节中,您将看到在运行这些组件的平台上编写和运行 Spark 应用程序是多么容易。
从 Jupyter Notebook 编写和运行 Spark 应用程序
在你面前运行以下步骤,请确保您掌握了我们在本章上一节中介绍的组件及其交互:
1.通过运行以下命令验证 Spark 操作员 pod 是否正在运行:
kubectl get pods -n ml-workshop | grep spark-operator您应该看到以下响应:
图 5.35 – Spark 操作员吊舱
2.通过运行以下命令验证 JupyterHub pod 是否正在运行:
kubectl get pods -n ml-workshop | grep jupyterhub您应该看到以下响应:

图 5.36 – JupyterHub 吊舱
3.在启动 notebook 之前,让我们通过运行以下命令删除您在前面部分中创建的 Spark 集群。这是为了演示 JupyterHub 会自动为您创建一个新的 Spark 集群实例:
kubectl delete sparkcluster simple-spark-cluster -n ml-workshop4.登录到您的 JupyterHub 服务器。请参阅本章前面的验证 JupyterHub 配置部分。您将获得服务器的登录页面。选择Elyra Notebook Image with Spark image 和Small容器尺寸。这个与您在manifests/jupyterhub/jupyterhub/overlays/spark3/jupyterhub-singleuser-profiles-configmap.yaml文件中配置的图像相同。
5点击启动服务器:
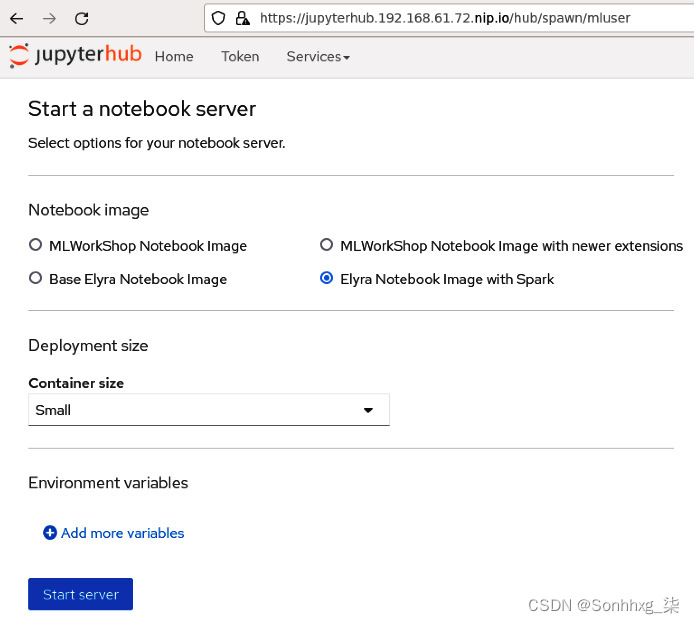
图 5.37 – JupyterHub 登陆页面显示 Elyra Notebook Image with Spark
你刚刚启动的 notebook 也会触发为你创建一个专用的 Spark 集群。Notebook 启动可能需要一些时间,因为它必须等待 Spark 集群准备好。
另外,您可能已经注意到您在jupyterhub-singleuser-profiles-configmap.yaml文件中配置的镜像是quay.io/ml-aml-workshop/elyra-spark:0.0.4,而我们选择的名称是带有 Spark 的 Elyra Notebook Image和它们不一样。图片与描述性文本的映射在manifests/jupyterhub-images/elyra-notebook-spark3-imagestream.yaml文件中配置。您会发现 JupyterHub 上显示的描述性文本降落来自此文件的注释部分的页面。如果您想使用特定的库添加您自己的图像,您只需在此处添加另一个文件,您的团队就可以使用它。JupyterHub 的这一特性实现了笔记本容器镜像的标准化,这使得团队中的每个人都可以拥有相同的环境配置和相同的库集。
6.笔记本启动后,验证是否为您配置了 Spark 集群。请注意,这是此笔记本用户的 Spark 集群,仅供此用户使用:
kubectl get pods -n ml-workshop | grep mluser您应该看到以下响应。响应包含一个 notebook pod 和两个 Spark pod;带一点-m字符的是主人,而另一个是工人。请注意您的用户名 ( mluser ) 如何与 pod 名称相关联:

图 5.38 – Jupyter Notebook 和 Spark 集群 pod
现在,您团队中的每个人都将拥有自己的开发人员环境,其中包含专用的 Spark 实例来编写和测试数据处理代码。
7.Apache Spark 提供了一个 UI,您可以通过它监控应用程序和数据处理作业。ODH 配置的 Spark 集群提供了这个 GUI,它是可在https://spark-cluster-mluser.192.168.61.72.nip.io获得。确保将 IP 地址更改为您的 minikube IP 地址。您可能还会注意到,您用于登录 JupyterHub 的用户名mluser是 URL 的一部分。如果您使用了不同的用户名,您可能需要相应地调整 URL。
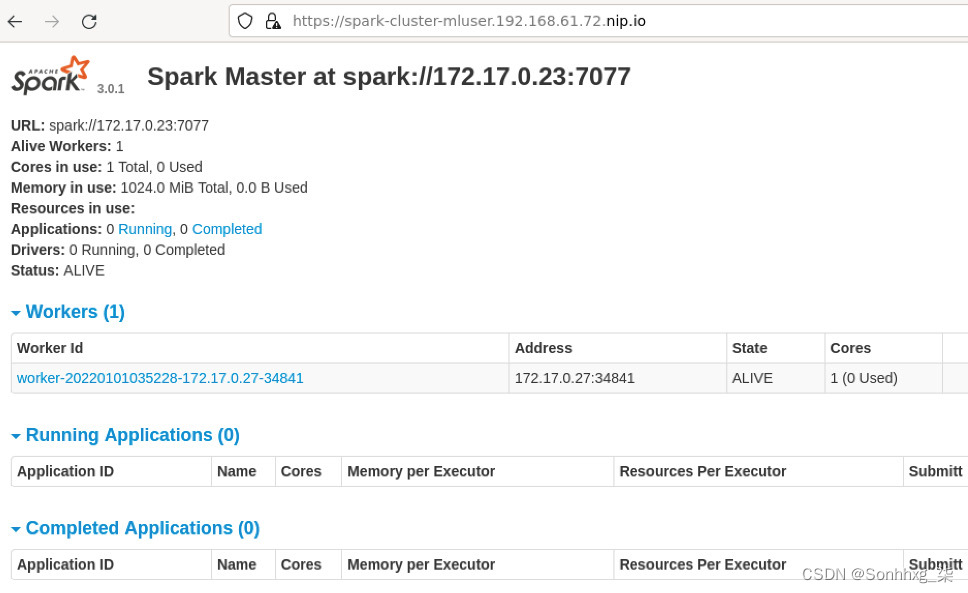
图 5.39 – Spark UI
上面的 UI 中提到了集群中有一个 Worker,可以点击 Worker 节点查看在 Worker 节点内部运行的 Executor。如果您想刷新对 Spark 集群的了解,请参阅本章前面的了解 Apache Spark 基础部分。
8.从您的笔记本打开chapter5/hellospark.ipynb文件。这是一个计算给定数组平方的非常简单的工作。请记住,Spark 将自动安排作业并将其分配给执行者。笔记本这里是 Spark Driver 程序,它与 Spark 集群对话,所有这些都是通过SparkSession对象抽象出来的。
在此笔记本的第二个代码单元中,您正在创建一个SparkSession对象。getOrCreateSparkSession实用程序函数将连接到平台为您提供的 Spark 集群。
最后一个单元格是您的数据处理逻辑所在的位置。在此示例中,逻辑是获取数据并计算数组中每个元素的平方。处理完数据后,collect方法会将响应带给在笔记本中 Spark 应用程序中运行的驱动程序。
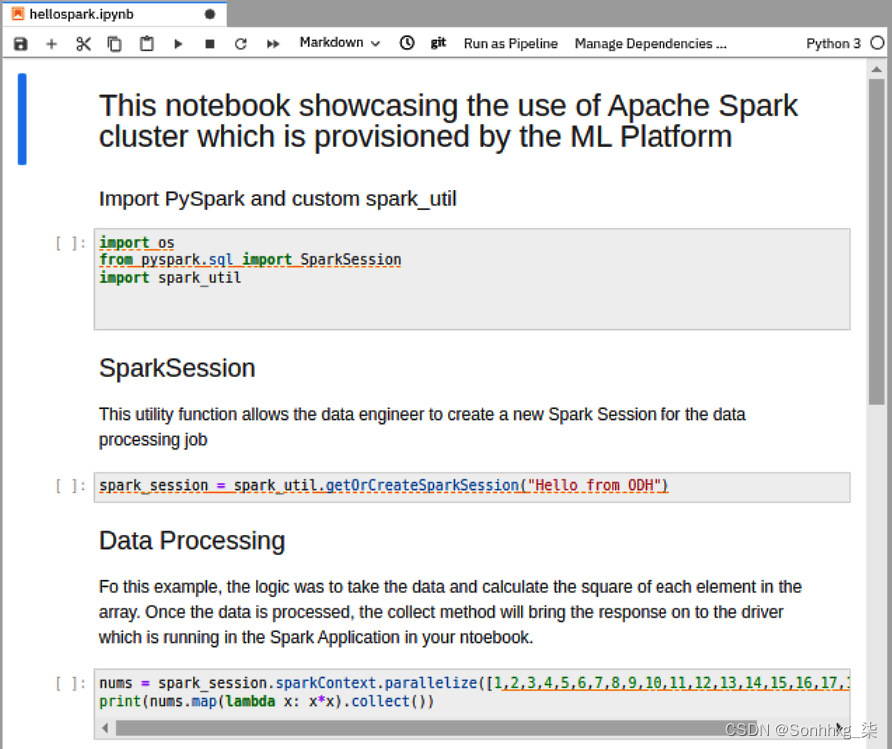
图 5.40 – 带有简单 Spark 应用程序的笔记本
单击“运行”>“运行所有单元”菜单选项,笔记本将连接到火花集群,并提交并执行您的作业。
9.在作业进行期间,在https://spark-cluster-mluser.192.168.61.72.nip.io打开 Spark UI 。请记住根据您的设置调整 IP 地址,然后单击此页面上正在运行的应用程序标题下的应用程序 ID标题表。
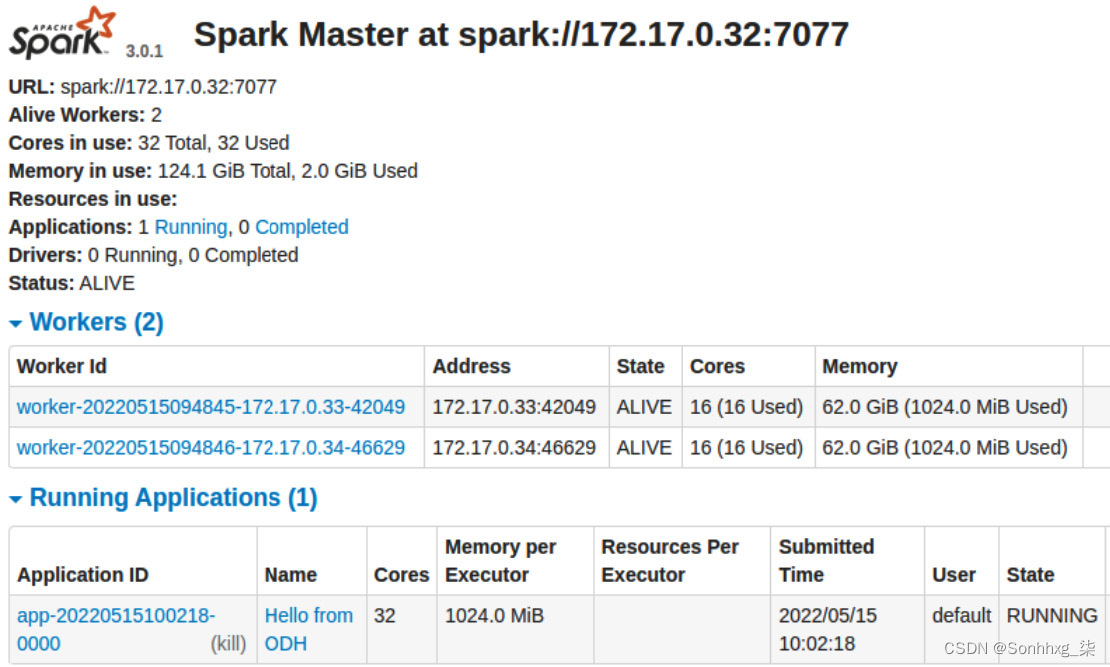
图 5.41 – Apache Spark UI
10.导航到 Spark 应用程序的详细信息页面。请注意,应用程序标题Hello from ODH具有到过在你的笔记本中设置。单击应用程序详细信息 UI链接:
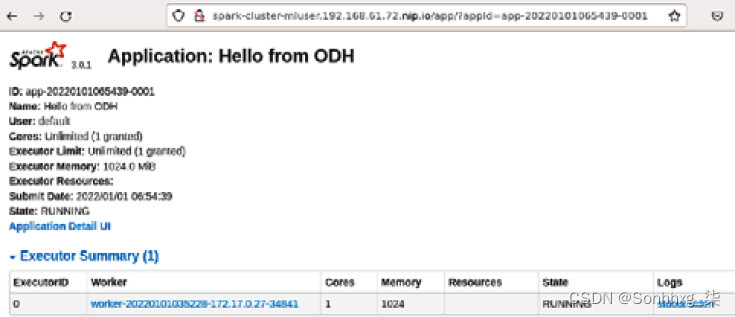
图 5.42 – Spark UI 显示提交的 Spark 作业
您应该会看到一个页面,其中显示了您刚刚从 Jupyter 笔记本在 Spark 集群上执行的作业的详细指标:
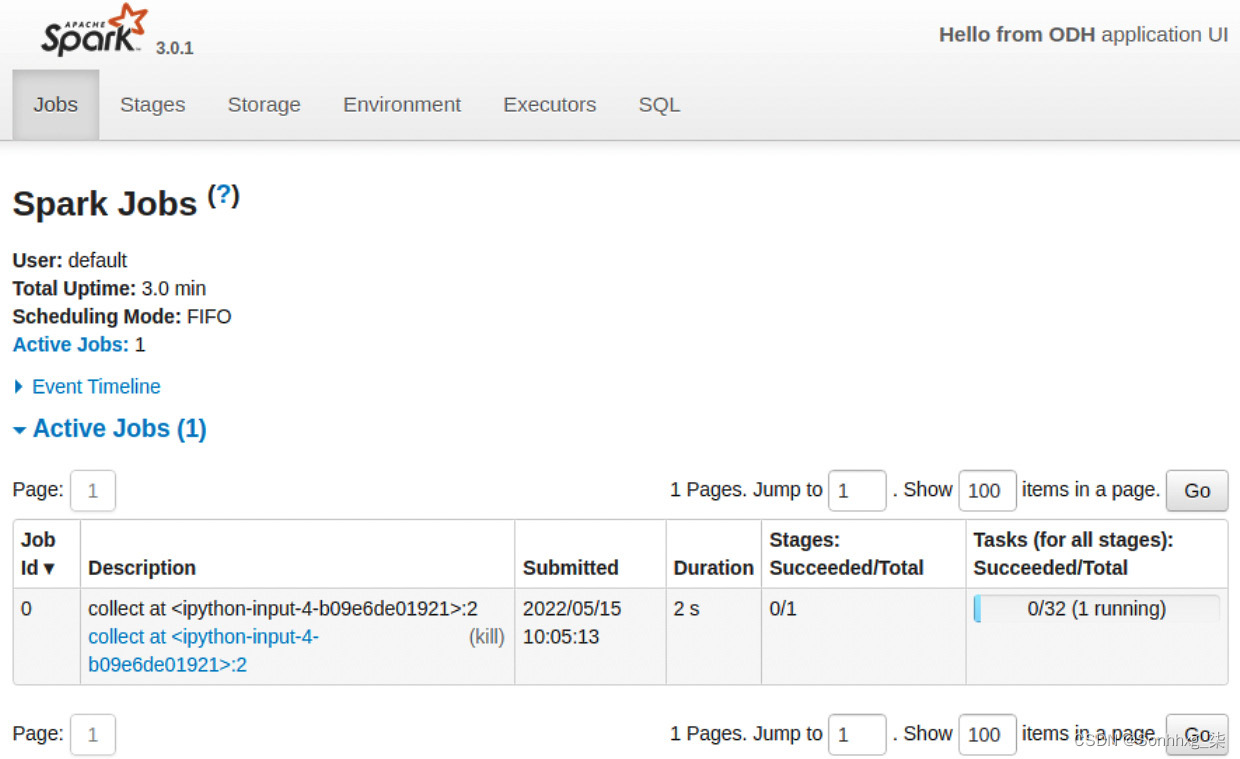
图 5.43 – Spark UI 显示提交的作业详细信息
11.一旦您是完成工作后,转到文件 > 集线器控制面板菜单选项,然后单击停止我的服务器按钮:
图 5.44 – Jupyter Notebook 控制面板
12.通过发出以下命令验证 Spark 集群是否已终止:
kubectl get pods -n ml-workshop | grep 用户
您应该看不到响应,因为 pod 已被集群上的 Spark 操作员终止。
您终于在 Kubernetes 上运行的按需临时 Spark 集群中运行了基本数据处理作业。请注意,您已经通过在 Kubernetes 上运行的 Jupyter 笔记本完成了所有这些操作。
借助平台中的这种能力,数据工程师可以直接执行庞大的数据处理任务从浏览器。此功能还使他们能够轻松地相互协作,为您的 ML 项目提供转换、清洁的高质量数据。
概括
在本章中,您刚刚创建了您的第一个 ML 平台。您已通过 ODH Kubernetes 操作员配置了 ODH 组件。您已经看到数据工程师角色将如何使用 JupyterHub 来配置 Jupyter 笔记本和 Apache Spark 集群实例,同时平台自动提供环境配置。您还看到了该平台如何通过容器镜像实现操作环境的标准化,从而带来一致性和安全性。您已经了解了数据工程师如何从 Jupyter 笔记本运行 Apache Spark 作业。
所有这些功能都允许数据工程师以自给自足的方式自主工作。您已经看到所有这些组件都可以自主和按需使用。该平台的弹性和自助服务性质将使团队在响应数据和机器学习世界不断变化的需求的同时提高生产力和敏捷性。
在下一章中,您将看到数据科学家如何从该平台中受益并提高效率。
















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











