







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
PySpark、Pandas UDF 和 Pandas 函数 API
Spark Core 和 Spark SQL
让我们首先考虑一下幕后的新事物。Spark Core 和 Spark SQL 引擎中引入了许多更改,以帮助加快查询速度。加快查询的一种方法是使用动态分区修剪来读取更少的数据。另一个是在执行期间调整和优化查询计划。
动态分区修剪
动态分区修剪 (DPP)背后的想法是跳过查询结果中不需要的数据。DPP 最佳的典型场景是当您连接两个表时:一个事实表(在多个列上分区)和一个维度表(未分区),如图 12-1所示。通常,过滤器位于表的未分区一侧(Date在我们的例子中)。例如,考虑对两个表的这个常见查询,Sales并且Date:
-- In SQL
SELECT * FROM Sales JOIN ON Sales.date = Date.date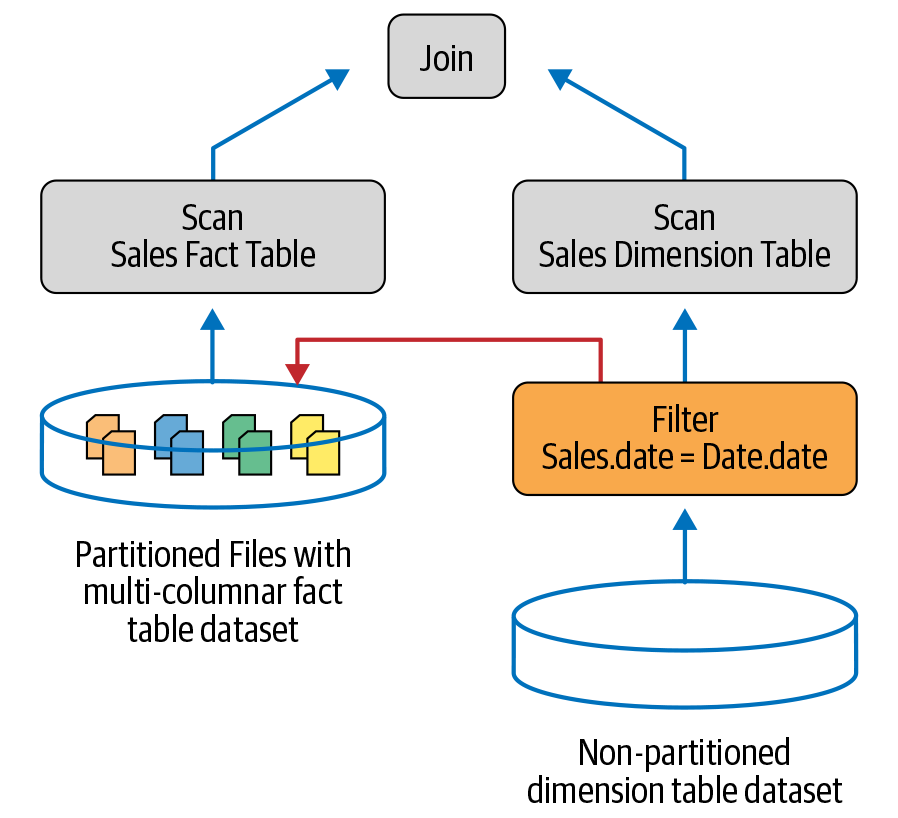
图 12-1。动态过滤器从维度表注入到事实表中
DPP 中的关键优化技术是从维度表中取出过滤器的结果,作为扫描操作的一部分注入到事实表中,以限制读取的数据,如图 12-1所示。
考虑一个维度表小于事实表的情况,我们执行一个连接,如图 12-2所示。在这种情况下,Spark 很可能会进行广播连接(在第 7 章中讨论过)。在此连接期间,Spark 将执行以下步骤以最小化从较大的事实表中扫描的数据量:
-
在连接的维度方面,Spark 将从维度表构建一个哈希表,也称为构建关系,作为此过滤器查询的一部分。
-
Spark 会将这个查询的结果插入到哈希表中,并将其分配给一个广播变量,该变量被分发给这个连接操作所涉及的所有执行器。
-
在每个执行器上,Spark 将探测广播的哈希表以确定要从事实表中读取哪些相应的行。
-
最后,Spark 会将这个过滤器动态注入到事实表的文件扫描操作中,并重用来自广播变量的结果。这样,作为对事实表的文件扫描操作的一部分,只扫描与过滤器匹配的分区,并且只读取需要的数据。
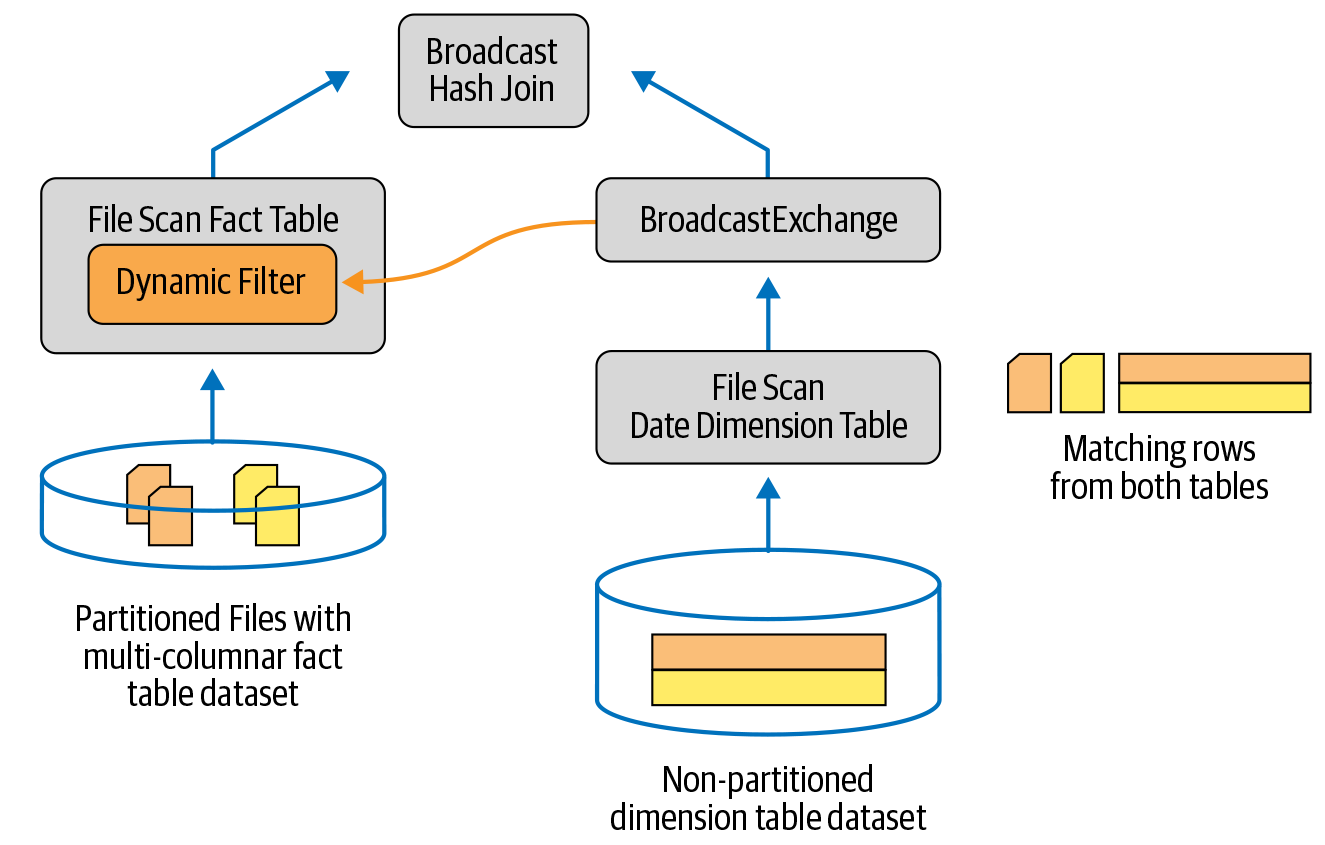
图 12-2。Spark 在广播连接期间将维度表过滤器注入事实表
默认情况下启用,因此您不必显式配置它,当您在两个表之间执行连接时,所有这些都会动态发生。通过 DPP 优化,Spark 3.0 可以更好地处理星型模式查询.
自适应查询执行
Spark 3.0 优化查询性能的另一种方式是在运行时调整其物理执行计划。自适应查询执行 (AQE)根据在查询执行过程中收集的运行时统计信息重新优化和调整查询计划。它尝试在运行时执行以下操作:
-
通过减少 shuffle 分区的数量来减少 shuffle 阶段的 reducer 的数量。
-
优化查询的物理执行计划,例如在适当的地方将 a 转换
SortMergeJoin为 aBroadcastHashJoin。 -
在连接期间处理数据倾斜。
所有这些自适应措施都发生在运行时执行计划的过程中,如图 12-3所示。要在 Spark 3.0 中使用 AQE,请将配置设置spark.sql.adaptive.enabled为true.
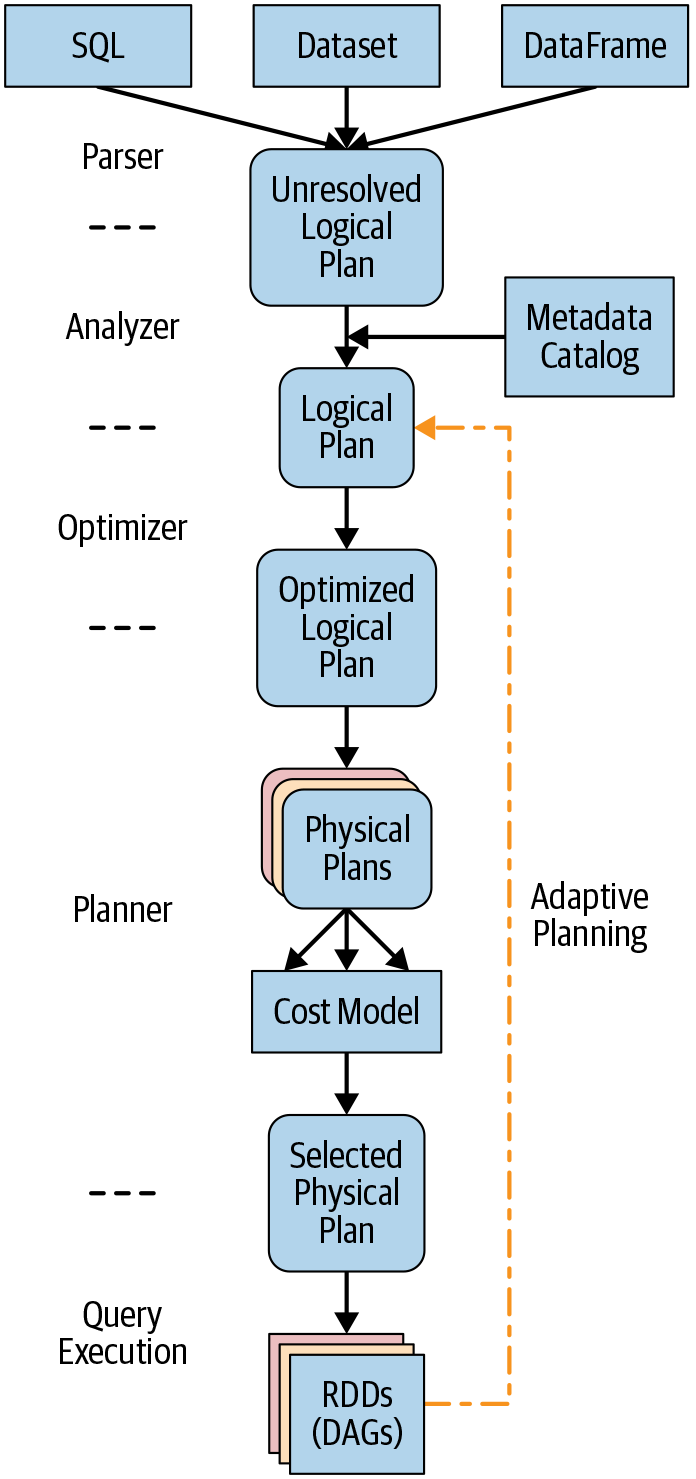
图 12-3。AQE 在运行时重新检查并重新优化执行计划
AQE 框架
查询中的 Spark 操作是流水线化的,并在并行进程中执行,但是 shuffle 或广播交换会破坏这条流水线,因为需要一个阶段的输出作为下一个阶段的输入(参见第 3章中的“步骤 3:理解 Spark 应用程序概念” 2 )。这些断点在查询阶段称为具体化点,它们提供了重新优化和重新检查查询的机会,如图 12-4 所示。
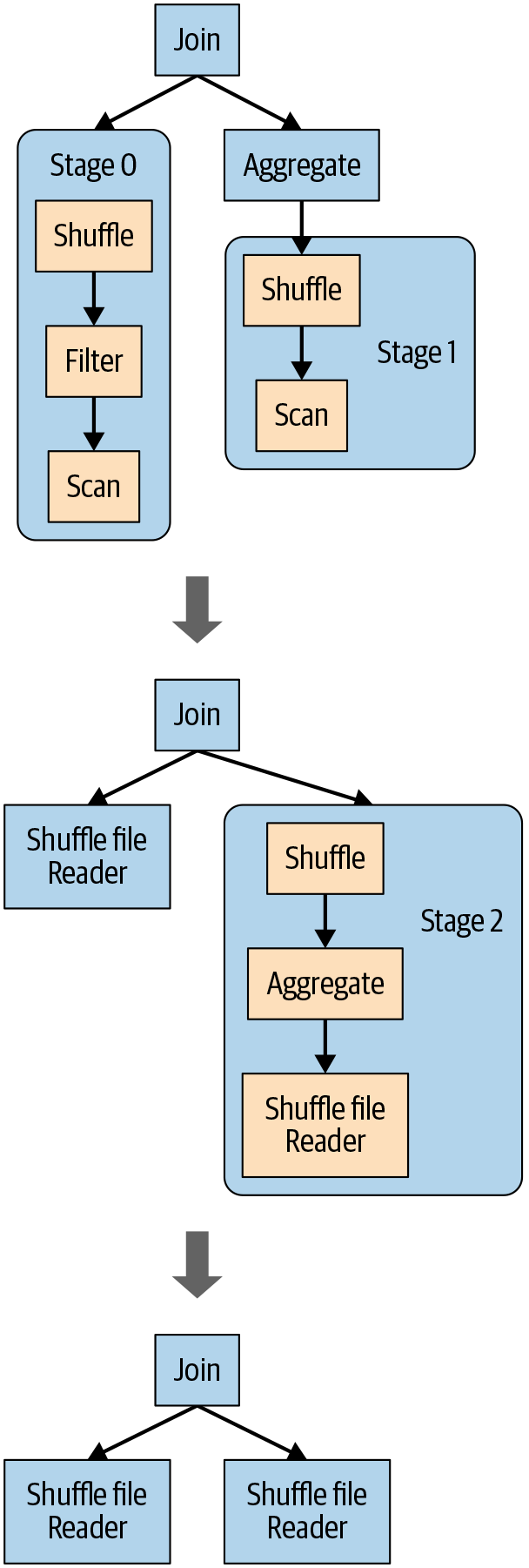
图 12-4。在 AQE 框架中重新优化的查询计划
以下是 AQE 框架迭代的概念步骤,如图所示:
-
执行每个阶段的所有叶节点,例如扫描操作。
-
一旦物化点完成执行,它就会被标记为完成,并且在执行期间获得的所有相关统计信息都会在其逻辑计划中更新。
-
根据这些统计数据,例如读取的分区数、读取的数据字节数等,框架再次运行 Catalyst 优化器以了解是否可以:
-
合并分区数量以减少读取 shuffle 数据的 reducer 数量。
-
将基于读取的表大小的排序合并连接替换为广播连接。
-
尝试修复倾斜连接。
-
创建一个新的优化逻辑计划,然后是一个新的优化物理计划。
-
重复此过程,直到执行了查询计划的所有阶段。
简而言之,这种重新优化是动态完成的,如图 12-3所示,目标是动态合并 shuffle 分区,减少读取 shuffle 输出数据所需的 reducer 数量,在适当的情况下切换连接策略,并修复任何倾斜连接。
两个 Spark SQL 配置决定了 AQE 如何减少 reducer 的数量:
-
spark.sql.adaptive.coalescePartitions.enabled(设置为true) -
spark.sql.adaptive.skewJoin.enabled(设置为true)
在撰写本文时,Spark 3.0 社区博客、文档和示例尚未公开发布,但在发布时它们应该已经公开。如果您希望了解这些功能如何在幕后工作,这些资源将使您能够获得更详细的信息——包括如何注入 SQL 连接提示,接下来将讨论.
SQL 连接提示
除了现有BROADCAST的连接提示之外,Spark 3.0 还为所有Spark 连接策略添加了连接提示(请参阅第 7 章中的“一系列 Spark 连接”)。此处提供了每种连接类型的示例。
随机排序合并连接 (SMJ)
使用这些新提示,您可以向 Spark 建议它SortMergeJoin在连接表时执行 aa和b或customers和orders,如以下示例所示。您可以在注释块SELECT内的语句中添加一个或多个提示:/*+ ... */
SELECT /*+ MERGE(a, b) */ id FROM a JOIN b ON a.key = b.key
SELECT /*+ MERGE(customers, orders) */ * FROM customers, orders WHERE
orders.custId = customers.custId广播哈希连接 (BHJ)
同样,对于广播哈希联接,您可以向 Spark 提供您更喜欢广播联接的提示。例如,这里我们广播 table ato join with tableb和 table customersto join with table orders:
SELECT /*+ BROADCAST(a) */ id FROM a JOIN b ON a.key = b.key
SELECT /*+ BROADCAST(customers) */ * FROM customers, orders WHERE
orders.custId = customers.custId随机散列连接 (SHJ)
您可以以类似的方式提供提示来执行随机散列连接,尽管这比前两种支持的连接策略更不常见:
SELECT /*+ SHUFFLE_HASH(a, b) */ id FROM a JOIN b ON a.key = b.key
SELECT /*+ SHUFFLE_HASH(customers, orders) */ * FROM customers, orders WHERE
orders.custId = customers.custId随机复制嵌套循环连接 (SNLJ)
最后,shuffle-and-replicate 嵌套循环连接遵循类似的形式和语法:
SELECT /*+ SHUFFLE_REPLICATE_NL(a, b) */ id FROM a JOIN b目录插件 API 和 DataSourceV2
不仅限于 Hive 元存储和目录,Spark 3.0 的实验性 DataSourceV2 API 扩展了 Spark 生态系统并为开发人员提供了三个核心功能。具体来说,它:
-
允许插入外部数据源以进行目录和表管理
-
支持使用 ORC、Parquet、Kafka、Cassandra、Delta Lake 和 Apache Iceberg 等支持的文件格式将谓词下推到其他数据源。
-
为 sinks 和 sources 的数据源的流式处理和批处理提供统一的 API
针对希望扩展 Spark 使用外部源和接收器的能力的开发人员,Catalog API 提供 SQL 和编程 API,以从指定的可插入目录创建、更改、加载和删除表。目录提供了在不同级别执行的功能和操作的分层抽象,如图 12-5所示。
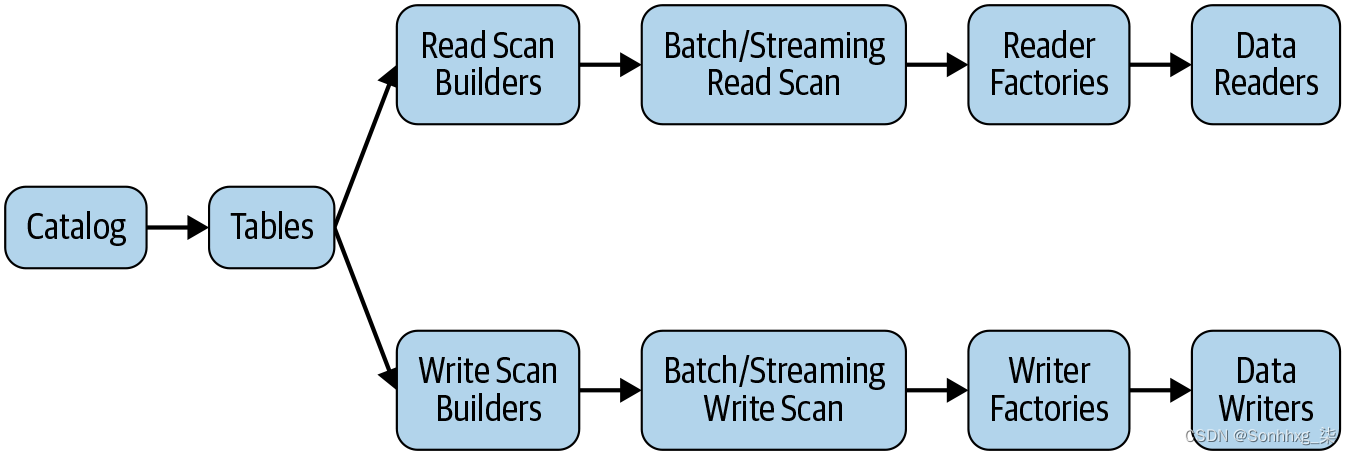
图 12-5。目录插件 API 的分层功能级别
Spark 和特定连接器之间的初始交互是解析与其实际Table对象的关系。Catalog定义如何在此连接器中查找表。此外,Catalog可以定义如何修改自己的元数据,从而启用CREATE TABLE,等操作ALTER TABLE。
例如,在 SQL 中,您现在可以发出命令来为您的目录创建名称空间。要使用可插入目录,请在spark-defaults.conf文件中启用以下配置:
spark.sql.catalog.ndb_catalog com.ndb.ConnectorImpl # connector implementation
spark.sql.catalog.ndb_catalog.option1 value1
spark.sql.catalog.ndb_catalog.option2 value2在这里,数据源目录的连接器有两个选项:option1->value1和option2->value2. 一旦它们被定义,Spark 或 SQL 中的应用程序用户可以使用DataFrameReader和DataFrameWriterAPI 方法或具有这些定义选项的 Spark SQL 命令作为数据源操作的方法。例如:
-- In SQL
SHOW TABLES ndb_catalog;
CREATE TABLE ndb_catalog.table_1;
SELECT * from ndb_catalog.table_1;
ALTER TABLE ndb_catalog.table_1// In Scala
df.writeTo("ndb_catalog.table_1")
val dfNBD = spark.read.table("ndb_catalog.table_1")
.option("option1", "value1")
.option("option2", "value2")虽然这些目录插件 API 扩展了 Spark 将外部数据源用作接收器和源的能力,但它们仍处于试验阶段,不应在生产中使用。其使用的详细指南超出了本书的范围,但如果您想将自定义连接器写入外部数据源作为目录来管理您的外部表及其相关联,我们鼓励您查看发布文档以获取更多信息元数据。
笔记
加速器感知调度器
Project Hydrogen是一项将 AI 和大数据结合在一起的社区计划,它具有三个主要目标:实现屏障执行模式、加速器感知调度和优化数据交换。在 Apache Spark 2.4.0 中引入了屏障执行模式的基本实现。在 Spark 3.0 中,已经实现了一个基本调度程序,以利用硬件加速器,例如 Spark 以独立模式部署的目标平台上的 GPU、YARN 或 Kubernetes。
为了让 Spark 以有组织的方式利用这些 GPU 来处理使用它们的专门工作负载,您必须通过配置指定可用的硬件资源。然后,您的应用程序可以在发现脚本的帮助下发现它们。启用 GPU 使用是 Spark 应用程序中的三个步骤:
-
编写一个发现脚本,发现每个 Spark 执行器上可用的底层 GPU 的地址。此脚本在以下 Spark配置中设置:
spark.worker.resource.gpu.discoveryScript=/path/to/script.sh -
为您的 Spark 执行器设置配置以使用这些发现的 GPU:
spark.executor.resource.gpu.amount=2 spark.task.resource.gpu.amount=1 -
编写 RDD 代码以利用这些 GPU 完成您的任务:
import org.apache.spark.BarrierTaskContext val rdd = ... rdd.barrier.mapPartitions { it => val context = BarrierTaskContext.getcontext.barrier() val gpus = context.resources().get("gpu").get.addresses // launch external process that leverages GPU launchProcess(gpus) }
笔记
这些步骤仍处于试验阶段,在未来的 Spark 3.x 版本中将继续进行进一步的开发,以支持在命令行(使用
spark-submit)和 Spark 任务级别无缝发现 GPU 资源。
结构化流
为了检查您的结构化流作业在执行过程中如何应对数据的起伏和流动,Spark 3.0 UI 在我们在第 7 章中探讨的其他选项卡旁边有一个新的结构化流式处理选项卡。此选项卡提供两组统计信息:有关已完成流式查询作业的汇总信息(图 12-6)和有关流式查询的详细统计信息,包括输入速率、处理速率、输入行数、批处理持续时间和操作持续时间(图12-7 )。
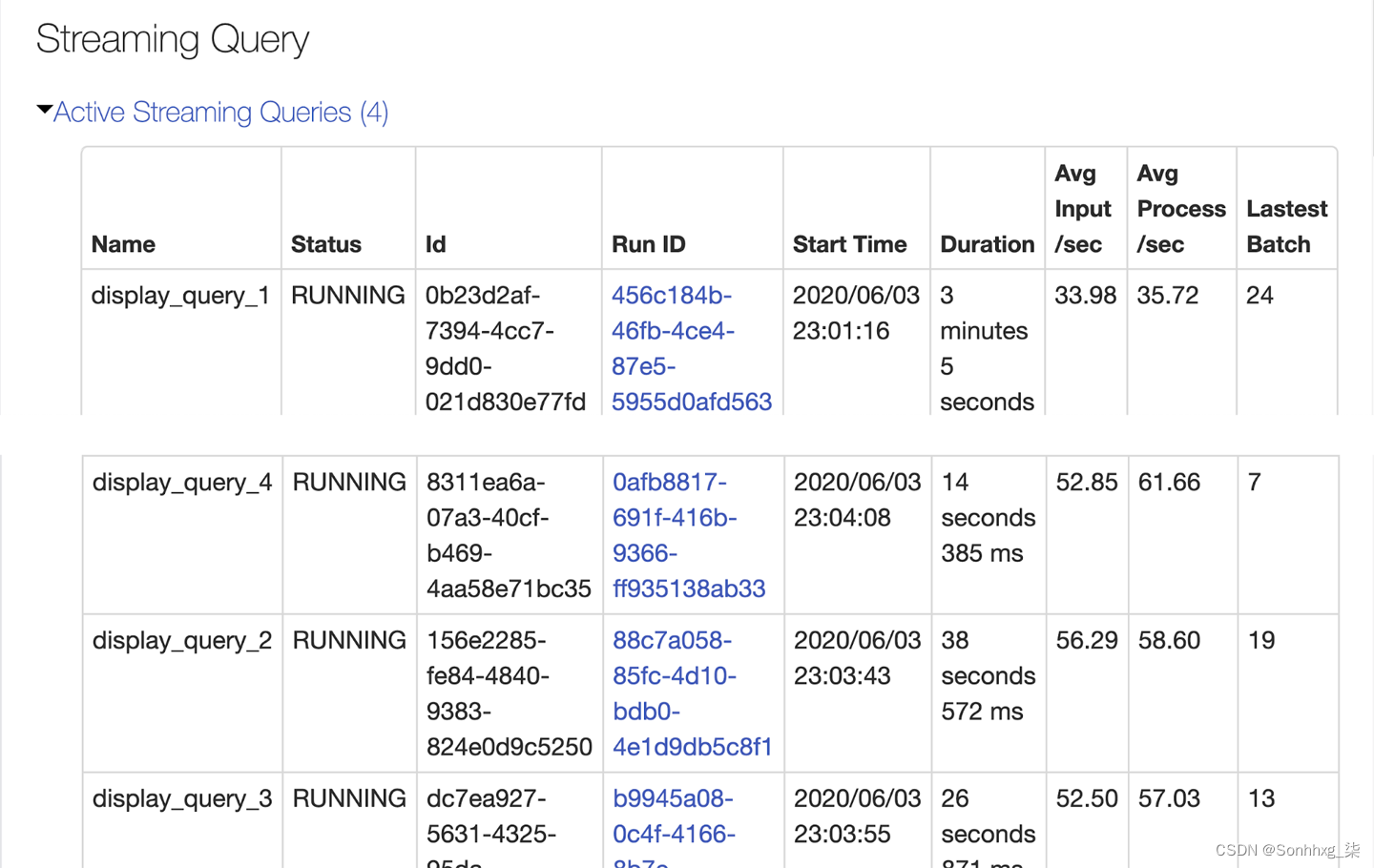
图 12-6。结构化流式处理选项卡显示已完成流式处理作业的汇总统计信息
笔记
图12-7的屏幕截图是使用 Spark 3.0.0-preview2 截取的;在最终版本中,您应该会在 UI 页面上的名称标识符中看到查询名称和 ID。
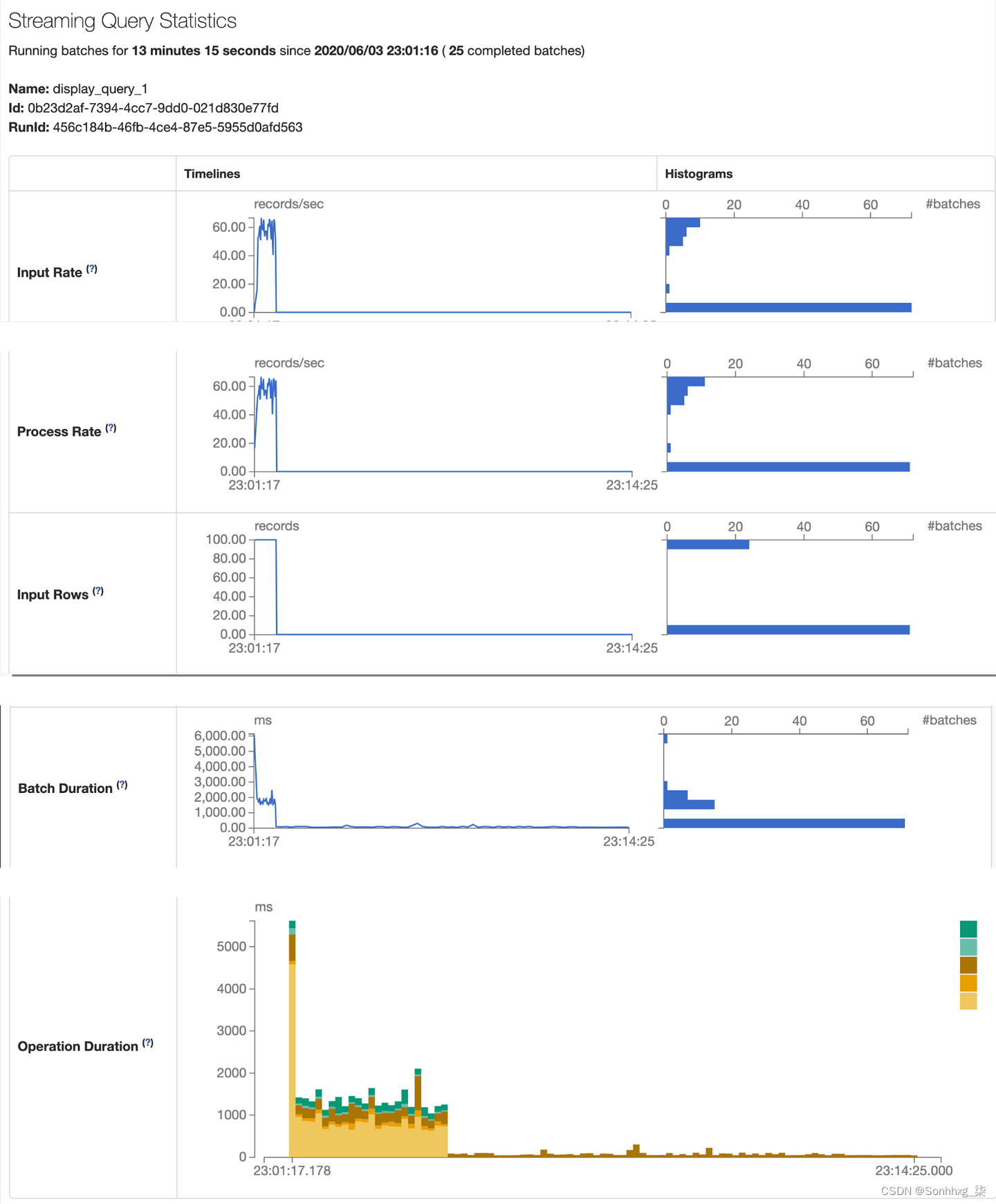
图 12-7。显示已完成流式传输作业的详细统计信息
无需配置;所有配置都直接从 Spark 3.0 安装中运行,具有以下默认值:
-
spark.sql.streaming.ui.enabled=true -
spark.sql.streaming.ui.retainedProgressUpdates=100 -
spark.sql.streaming.ui.retainedQueries=100
PySpark、Pandas UDF 和 Pandas 函数 API
Spark 3.0 需要 pandas 0.23.2 或更高版本才能使用任何与 pandas 相关的方法,例如DataFrame.toPandas()或SparkSession.createDataFrame(pandas.DataFrame)。
此外,它需要 PyArrow 版本 0.12.1 或更高版本才能使用 PyArrow 功能,例如pandas_udf()、DataFrame.toPandas()和SparkSession.createDataFrame(pandas.DataFrame),并将spark.sql.execution.arrow.enabled配置设置为true。下一节将介绍 Pandas UDF 中的新功能。
使用 Python 类型提示重新设计的 Pandas UDF
Spark 3.0 中的 Pandas UDF 通过利用Python 类型提示进行了重新设计。这使您能够自然地表达 UDF,而无需求值类型。Pandas UDF 现在更加“Pythonic”,可以自己定义 UDF 应该输入和输出的内容,而不是@pandas_udf("long", PandasUDFType.SCALAR)像在 Spark 2.4 中那样指定它。
这是一个例子:
# Pandas UDFs in Spark 3.0
import pandas as pd
from pyspark.sql.functions import pandas_udf
@pandas_udf("long")
def pandas_plus_one(v: pd.Series) -> pd.Series:
return v + 1这种新格式提供了一些好处,例如更容易进行静态分析。您可以像以前一样应用新的 UDF:
df = spark.range(3)
df.withColumn("plus_one", pandas_plus_one("id")).show()
+---+--------+
| id|plus_one|
+---+--------+
| 0| 1|
| 1| 2|
| 2| 3|
+---+--------+Pandas UDF 中的迭代器支持
Pandas UDF 非常常用于加载模型并为单节点机器学习和深度学习模型执行分布式推理。但是,如果模型非常大,那么 Pandas UDF 会为同一个 Python 工作进程中的每个批次重复加载相同的模型,开销很大。
在 Spark 3.0 中,Pandas UDF 可以接受 or 的迭代器pandas.Series,如下pandas.DataFrame所示:
from typing import Iterator
@pandas_udf('long')
def pandas_plus_one(iterator: Iterator[pd.Series]) -> Iterator[pd.Series]:
return map(lambda s: s + 1, iterator)
df.withColumn("plus_one", pandas_plus_one("id")).show()
+---+--------+
| id|plus_one|
+---+--------+
| 0| 1|
| 1| 2|
| 2| 3|
+---+--------+有了这种支持,您可以只加载一次模型,而不是为迭代器中的每个系列加载它。以下伪代码说明了如何执行此操作:
@pandas_udf(...)
def predict(iterator):
model = ... # load model
for features in iterator:
yield model.predict(features)新的 Pandas 函数 API
Spark 3.0 引入了一些新类型的 Pandas UDF,当你想对整个 DataFrame 应用函数而不是按列应用函数时,它们很有用,例如第 11 章mapInPandas()中介绍的。这些将 的迭代器作为输入并输出 的另一个迭代器:pandas.DataFramepandas.DataFrame
def pandas_filter(
iterator: Iterator[pd.DataFrame]) -> Iterator[pd.DataFrame]:
for pdf in iterator:
yield pdf[pdf.id == 1]
df.mapInPandas(pandas_filter, schema=df.schema).show()
+---+
| id|
+---+
| 1|
+---+您可以通过在配置pandas.DataFrame中指定它来控制它的大小。spark.sql.execution.arrow.maxRecordsPerBatch请注意,与大多数 Pandas UDF 不同,输入大小和输出大小不必匹配。
笔记
Spark 3.0 还引入了 cogrouped map Pandas UDF。该applyInPandas()函数采用两个pandas.DataFrame共享一个公共密钥的 s 并将一个函数应用于每个 cogroup。然后将返回pandas.DataFrame的 s 组合为单个 DataFrame。和 一样mapInPandas(),返回的长度没有限制pandas.DataFrame。这是一个例子:
df1 = spark.createDataFrame(
[(1201, 1, 1.0), (1201, 2, 2.0), (1202, 1, 3.0), (1202, 2, 4.0)],
("time", "id", "v1"))
df2 = spark.createDataFrame(
[(1201, 1, "x"), (1201, 2, "y")], ("time", "id", "v2"))
def asof_join(left: pd.DataFrame, right: pd.DataFrame) -> pd.DataFrame:
return pd.merge_asof(left, right, on="time", by="id")
df1.groupby("id").cogroup(
df2.groupby("id")
).applyInPandas(asof_join, "time int, id int, v1 double, v2 string").show()
+----+---+---+---+
|time| id| v1| v2|
+----+---+---+---+
|1201| 1|1.0| x|
|1202| 1|3.0| x|
|1201| 2|2.0| y|
|1202| 2|4.0| y|
+----+---+---+---+改变的功能
列出 Spark 3.0 中的所有功能更改将使这本书变成几英寸厚的砖。因此,为简洁起见,我们将在此处提及一些值得注意的内容,并让您在发布后立即查阅 Spark 3.0 的发行说明以获取完整的详细信息和所有细微差别。
支持和弃用的语言
Spark 3.0 支持 Python 3 和 JDK 11,需要 Scala 2.12 版本。不推荐使用早于 3.6 和 Java 8 的所有 Python 版本。如果您使用这些已弃用的版本,您将收到警告消息。
对 DataFrame 和 Dataset API 的更改
在以前的 Spark 版本中,Dataset 和 DataFrame AP 已弃用该unionAll()方法。在 Spark 3.0 中,这已被逆转,unionAll()现在是该union()方法的别名。
此外,早期版本的 Spark 会Dataset.groupByKey()生成一个分组数据集,其中的键被错误地命名为value当键是非结构类型(int、string、array等)时。因此,ds.groupByKey().count()查询中的聚合结果在显示时看起来违反直觉,例如(value, count). 这已被纠正以产生(key, count)更直观的结果。例如:
// In Scala
val ds = spark.createDataset(Seq(20, 3, 3, 2, 4, 8, 1, 1, 3))
ds.show(5)
+-----+
|value|
+-----+
| 20|
| 3|
| 3|
| 2|
| 4|
+-----+
ds.groupByKey(k=> k).count.show(5)
+---+--------+
|key|count(1)|
+---+--------+
| 1| 2|
| 3| 3|
| 20| 1|
| 4| 1|
| 8| 1|
+---+--------+
only showing top 5 rows但是,如果您愿意,可以通过设置为 来保留旧spark.sql.legacy.dataset.nameNonStructGroupingKeyAsValue格式true。
DataFrame 和 SQL 解释命令
为了更好的可读性和格式,Spark 3.0 引入了显示 Catalyst 优化器生成的计划的不同视图的功能。选项包括(默认)、、、、和。这是一个简单的 例子:DataFrame.explain(FORMAT_MODE)FORMAT_MODE"simple""extended""cost""codegen""formatted"
// In Scala
val strings = spark
.read.text("/databricks-datasets/learning-spark-v2/SPARK_README.md")
val filtered = strings.filter($"value".contains("Spark"))
filtered.count()# In Python
strings = spark
.read.text("/databricks-datasets/learning-spark-v2/SPARK_README.md")
filtered = strings.filter(strings.value.contains("Spark"))
filtered.count()// In Scala
filtered.explain("simple")# In Python
filtered.explain(mode="simple")
== Physical Plan ==
*(1) Project [value#72]
+- *(1) Filter (isnotnull(value#72) AND Contains(value#72, Spark))
+- FileScan text [value#72] Batched: false, DataFilters: [isnotnull(value#72),
Contains(value#72, Spark)], Format: Text, Location:
InMemoryFileIndex[dbfs:/databricks-datasets/learning-spark-v2/SPARK_README.md],
PartitionFilters: [], PushedFilters: [IsNotNull(value),
StringContains(value,Spark)], ReadSchema: struct<value:string>// In Scala
filtered.explain("formatted")# In Python
filtered.explain(mode="formatted")
== Physical Plan ==
* Project (3)
+- * Filter (2)
+- Scan text (1)
(1) Scan text
Output [1]: [value#72]
Batched: false
Location: InMemoryFileIndex [dbfs:/databricks-datasets/learning-spark-v2/...
PushedFilters: [IsNotNull(value), StringContains(value,Spark)]
ReadSchema: struct<value:string>
(2) Filter [codegen id : 1]
Input [1]: [value#72]
Condition : (isnotnull(value#72) AND Contains(value#72, Spark))
(3) Project [codegen id : 1]
Output [1]: [value#72]
Input [1]: [value#72]-- In SQL
EXPLAIN FORMATTED
SELECT *
FROM tmp_spark_readme
WHERE value like "%Spark%"
== Physical Plan ==
* Project (3)
+- * Filter (2)
+- Scan text (1)
(1) Scan text
Output [1]: [value#2016]
Batched: false
Location: InMemoryFileIndex [dbfs:/databricks-datasets/
learning-spark-v2/SPARK_README.md]
PushedFilters: [IsNotNull(value), StringContains(value,Spark)]
ReadSchema: struct<value:string>
(2) Filter [codegen id : 1]
Input [1]: [value#2016]
Condition : (isnotnull(value#2016) AND Contains(value#2016, Spark))
(3) Project [codegen id : 1]
Output [1]: [value#2016]
Input [1]: [value#2016]要查看其他格式模式的实际效果,您可以尝试本书的GitHub存储库中的 notebook 。另请查看从 Spark 2.x 到 Spark 3.0的迁移指南.
概括
本章简要介绍了 Spark 3.0 中的新特性。我们冒昧地提到了一些值得注意的高级功能。它们在引擎盖下运行,而不是在 API 级别。特别是,我们研究了动态分区修剪 (DPP) 和自适应查询执行 (AQE),这两种优化可提高 Spark 在执行时的性能。我们还探索了实验性 Catalog API 如何将 Spark 生态系统扩展到自定义数据存储,用于批处理和流数据的源和接收器,并研究了 Spark 3.0 中的新调度程序,该调度程序使其能够利用执行程序中的 GPU。
作为对第 7 章中 Spark UI 讨论的补充,我们还向您展示了新的 Structured Streaming 选项卡,提供有关流式作业的累积统计信息、额外的可视化以及每个查询的详细指标。
Spark 3.0 中不推荐使用低于 3.6 的 Python 版本,并且重新设计了 Pandas UDF 以支持 Python 类型提示和迭代器作为参数。有 Pandas UDF 可以转换整个 DataFrame,以及将两个cogrouped DataFrame 组合成一个新的 DataFrame。
为了提高查询计划的可读性,并在 SQL 中显示逻辑和物理计划的不同层次和细节。此外,SQL 命令现在可以为 Spark 支持的整个连接系列提供连接提示。DataFrame.explain(FORMAT_MODE)EXPLAIN FORMAT_MODE
虽然我们无法在这个简短的章节中列举 Spark 最新版本中的所有更改,但我们强烈建议您在 Spark 3.0 发布时查看发行说明以了解更多信息。此外,为了快速总结面向用户的更改以及如何迁移到 Spark 3.0 的详细信息,我们建议您查看迁移指南。

















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











