







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在上一章中,我们介绍了一些用于从文本中提取信息的技术。这些技术实施起来可能很复杂,也可能很慢。如果应用程序要求提取的信息可供用户阅读,那么这些技术非常棒。如果我们希望提取信息作为中间处理步骤的一部分——例如,为分类器构建特征——那么我们不需要提取可读信息。正如我们在第5章和第7章中看到的,简单地使用我们的词汇将创建大量的特征。因此,我们希望降低数据的维数。这就是分布式语义的用武之地。
分布语义学是使用统计分布对语言元素的研究,以表征文档(例如,电子邮件)、言语行为(例如,口语或书面句子)或其元素(例如,短语、单词)之间的相似性。这个领域的想法来自 20 世纪上半叶的语言学家 John R. Firth。他注意到语义是如何依赖于上下文的,并创造了经常重复的引用,“你会知道它所保留的公司的一个词。”
这个想法是,您可以将一个词表示为它出现的上下文的概率分布。这些词将存在于一个向量空间中,其中维度与这些上下文相关联。例如,“医生”在医疗维度上的价值将大于在财务维度上的价值。但是,“银行”在金融维度和地质维度上会有更大的价值。但是,我们不能简单地使用手动选择的上下文。这些也必须从数据中学习。通常,我们通过查看彼此出现的单词来学习上下文。这种反复来回意味着大多数此类算法会迭代,直到找到最适合数据的模型。这些方法是一种聚类。事实上,我们可以在文本数据上使用更通用的聚类算法,尽管它们可能效果不佳。
在以下示例中,我们有一个文档术语矩阵,其中行是文档,列是术语。这些值可以是二进制的,表示单词的存在,或者一个术语出现的次数,或者它们可以是 TF.IDF 值。我们将在本章中使用 TF.IDF 值。一旦我们有了这样一个矩阵,我们就会想把我们的文档映射到一个维度更少的空间。这会将文档聚类为主题。
我们将使用 Python 库 scikit-learn 来介绍这些技术。这个库将允许我们比 Spark 的实现更容易地检查这些模型的内部数据。
K-均值
作为主题建模的第一次尝试,让我们尝试一种经典的聚类技术——K-Means,如图 10-1所示。假设我们在向量空间中有许多数据点。我们可以K在向量空间中选取点,称为质心,并将每个数据点分配给最近的质心。我们想要找到K最小化数据点与其质心之间距离的点。
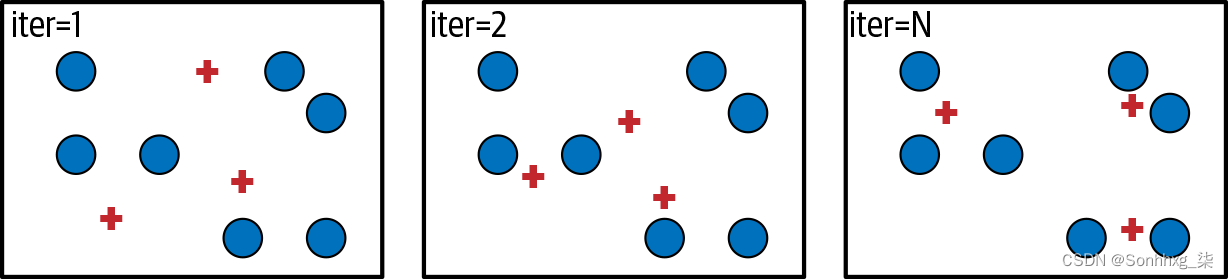
图 10-1。K-Means 的简单可视化
在我们的情况下,我们在由 TF.IDF 值定义的向量空间中有文档。当我们找到我们的K观点时,我们可以说每一个都K代表一个主题。让我们看一个例子。
首先,让我们构建我们的数据集。我们将使用布朗语料库,它是来自报纸、期刊和学术机构的文章、期刊和报告的集合。它是自 1960 年代以来一直用于 NLP 的经典数据集。
from collections import defaultdict, Counter, OrderedDict
import numpy as np
import pandas as pd
import scipy.sparse as sparse
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
from nltk.corpus import stopwords
from nltk.corpus import brown
en_stopwords = set(stopwords.words('english'))def detokenize(sentence):
text = ''
for token in sentence:
if text and any(c.isalnum() for c in token):
text += ' '
text += token
return text我们将要删除标点符号和停用词,以便我们的算法只使用“有用”的词。
def process(sentence):
terms = []
for term in sentence:
term = term.lower()
if term not in en_stopwords and term.isalnum():
terms.append(term)
return terms让我们收集我们的文档。我们的文件将是术语列表。
docs = OrderedDict()
for fid in brown.fileids():
docs[fid] = brown.sents(fid)现在我们将构建索引。这类似于我们在探索信息检索时所做的。
ix2doc = list(docs)
doc2ix = {fid: i for i, fid in enumerate(ix2doc)}
vocabulary = set()
term_counts = defaultdict(Counter)
document_counts = Counter()
for fid, doc in docs.items():
unique_terms = set()
for sentence in doc:
sentence = process(sentence)
term_counts[fid].update(sentence)
unique_terms.update(sentence)
document_counts.update(unique_terms)
vocabulary.update(unique_terms)
ix2term = sorted(list(vocabulary))
term2ix = OrderedDict()
for i, term in enumerate(ix2term):
term2ix[term] = i现在我们有了索引,让我们为 TF 和 IDF 构建一个矩阵。
term_count_mat = sparse.dok_matrix((len(doc2ix), len(term2ix)))
for fid, i in doc2ix.items():
for term, count in term_counts[fid].items():
j = term2ix[term]
term_count_mat[i, j] = count
term_count_mat = term_count_mat.todense()
doc_count_vec = np.array(
[document_counts[term] for term in term2ix.keys()])tf = np.log(term_count_mat + 1)
idf = len(doc2ix) / (1 + doc_count_vec)
tfidf = np.multiply(tf, idf)
tfidf.shape(500, 40881)
对于如此小的数据集,这是一个相当大的矩阵。除了空间效率问题之外,拥有这么多维度可能会降低某些算法的性能。这是分布式语义可以提供帮助的时候。
现在,我们可以建立我们的模型了。
from sklearn.cluster import KMeans
K = 6
clusters = ['cluster#{}'.format(k) for k in range(K)]
model = KMeans(n_clusters=K, random_state=314)
clustered = model.fit_transform(tfidf)
clustered.shape(500, 6)
我们可以看到我们现在已经使用我们的六个质心对文档进行了聚类。这些质心中的每一个都是我们词汇表的向量。我们可以看看哪些词对我们的质心影响最大。我们将为此使用词云,如图 10-2所示。
model.cluster_centers_.shape(6, 40881)
cluster_term = pd.DataFrame(
model.cluster_centers_.T, index=ix2term, columns=clusters)
cluster_term = np.round(cluster_term, decimals=4)font = {'weight' : 'bold', 'size' : 22}
fig, axs = plt.subplots(K // 2, 2, figsize=(10, 8))
k = 0
for i in range(len(axs)):
for j in range(len(axs[i])):
wc = WordCloud(colormap='Greys', background_color='white')
im = wc.generate_from_frequencies(cluster_term[clusters[k]])
axs[i][j].imshow(im, interpolation='bilinear')
axs[i][j].axis("off")
axs[i][j].set_title(clusters[k], **font)
k += 1
plt.tight_layout()
plt.show()
图 10-2。从质心构建的词云
我们可以在这里看到一些可识别的主题。集群 #5 似乎是关于数学主题的。集群 #3 似乎是关于食物准备,特别是巴氏杀菌。
K-Means 不会对我们的数据做很多假设——它只是试图找到K. K-Means 的一个缺点是它倾向于创建相同大小的集群。这是对自然语料库的不切实际的期望。此外,如果描述文档之间的相似性,我们不会有太多的障碍。让我们尝试一种算法,该算法做出更多假设,但这将为我们提供一种查看这些文档之间相似性的方法。
潜在语义索引
潜在语义索引 (LSI)是一种使用以下方法分解文档术语矩阵的技术奇异值分解(SVD)。在 SVD 中,我们将一个矩阵分解为三个矩阵。
Σ是降序奇异值的对角矩阵。我们可以取 top K,这可以作为原始矩阵的近似值。的第一K列U是文档在K维度空间中的表示。的第一K列是维度空间V中项的表示。K这使我们能够比较文档和术语的相似性。通常为组件选择更大的数字,因为维度Σ越多,我们可以用来逼近原始矩阵的维度就越多。所以我们将K在这里设置为更高的数字。
from sklearn.decomposition import TruncatedSVD
K = 100
clusters = ['cluster#{}'.format(k) for k in range(K)]
model = TruncatedSVD(n_components=K)
clustered = model.fit_transform(tfidf)让我们看看K我们保留的奇异值。
model.singular_values_array([3529.39905473, 3244.51395305, 3096.10335704, 3004.8882987 ,
2814.77858204, 2778.96902533, 2754.2942512 , 2714.32865945,
2652.4119094 , 2631.64362227, 2578.41230573, 2496.86392987,
2478.31563312, 2466.82942537, 2465.83674175, 2450.22361278,
2426.99364435, 2417.13989816, 2407.40572992, 2394.21460258,
2379.89976747, 2369.78970648, 2344.36252585, 2337.77090924,
2324.76055049, 2319.07434771, 2308.81232676, 2304.85707171,
2300.6888689 , 2299.08592131, 2292.18931562, 2281.59638332,
2280.80535179, 2276.55977269, 2265.29827699, 2264.49999278,
2259.19162875, 2253.20088136, 2249.34547946, 2239.31921392,
2232.24240145, 2221.95468155, 2217.95110287, 2208.94458997,
2199.75216312, 2195.85509817, 2189.76213831, 2186.64540094,
2178.92705724, 2170.98276352, 2164.19734464, 2159.85021389,
2154.82652164, 2145.5169884 , 2142.3070779 , 2138.06410065,
2132.8723198 , 2125.68060737, 2123.13051755, 2121.25651627,
2119.0925646 , 2113.46585963, 2102.77888039, 2101.07116001,
2094.0766712 , 2090.41516403, 2086.00515811, 2080.55424737,
2075.54071367, 2070.03500007, 2066.78292077, 2064.93112208,
2056.24857815, 2052.96995192, 2048.62550688, 2045.18447518,
2038.27607405, 2032.74196113, 2026.9687453 , 2022.61629887,
2018.05274649, 2011.24594096, 2009.64212589, 2004.15307518,
2000.17006712, 1995.76552783, 1985.15438092, 1981.71380603,
1977.60898352, 1973.78806955, 1966.68359784, 1962.29604116,
1956.62028269, 1951.54510897, 1951.25219946, 1943.75611963,
1939.85749385, 1933.30524488, 1928.57205628, 1919.57447254])模型的components_是 的最高K对角线值Σ。那么现在,让我们看看分布在组件上的术语,如表 10-1所示。
cluster_term = pd.DataFrame(model.components_.T, index=ix2term, columns=clusters)
cluster_term = np.round(cluster_term, decimals=4)
cluster_term.loc[['polynomial', 'cat', 'frankfurter']]| term | cluster#0 | cluster#1 | ... | cluster#98 | cluster#99 |
|---|---|---|---|---|---|
| polynomial | 0.0003 | 0.0012 | ... | 0.0077 | -0.0182 |
| cat | 0.0002 | 0.0018 | ... | 0.0056 | -0.0026 |
| frankfurter | 0.0004 | 0.0018 | ... | -0.0025 | -0.0025 |
该表表示单词在每个集群上的分布。
由于我们没有阻止我们的话,让我们看看我们是否可以从“多项式”的向量中找到“多项式”。我们将为此使用余弦相似度。余弦相似度是一种查看两个向量之间相似度的技术。这个想法是我们想要查看两个向量之间的角度。如果它们是平行的,相似度应该是1;如果它们是正交的,则相似度应为0;如果它们朝相反的方向前进,则相似度应为–1。所以我们想看看它们之间夹角的余弦值。两个向量的点积等于两个向量的大小乘以它们之间夹角的余弦的乘积。因此,我们可以将点积除以幅度的乘积。
SciPy 有一个余弦距离函数,它是我们刚刚定义的余弦相似度减一。我们想要相似性,所以我们必须撤消它。
from scipy.spatial.distance import cosine
def cossim(u, v):
return 1 - cosine(u, v)polynomial_vec = cluster_term.iloc[term2ix['polynomial']]
similarities = cluster_term.apply(
lambda r: cossim(polynomial_vec, r), axis=1)similarities.sort_values(ascending=False)[:20]polynomial 1.000000
nilpotent 0.999999
diagonalizable 0.999999
commute 0.999999
polynomials 0.999999
subspace 0.999999
divisible 0.999998
satisfies 0.999998
differentiable 0.999998
monic 0.999998
algebraically 0.999998
primes 0.999996
spanned 0.999996
decomposes 0.999996
scalar 0.999996
commutes 0.999996
algebra 0.999996
integers 0.999991
subspaces 0.999991
exponential 0.999991
dtype: float64我们看到“多项式”非常接近,许多其他以数学为主题的词也是如此。这是人们在提到分布式语义捕获时经常使用的“语义”。我们可以将这些表示用作特征。语料库越大越多样化,这些表示就越普遍适用。
现在让我们为我们的 LSI 模型构建词云,如图 10-3所示。我们将只看第一个和最后三个,因为我们的集群比我们的 K-Means 模型多得多。
chosen_ix = [0, 97, 1, 98, 2, 99]
fig, axs = plt.subplots(3, 2, figsize=(10, 8))
k = 0
for i in range(len(axs)):
for j in range(len(axs[i])):
wc = WordCloud(colormap='Greys', background_color='white')
im = wc.generate_from_frequencies(cluster_term[clusters[chosen_ix[k]]])
axs[i][j].imshow(im, interpolation='bilinear')
axs[i][j].axis("off")
axs[i][j].set_title(clusters[chosen_ix[k]], **font)
k += 1
plt.tight_layout()
plt.show()集群 #2 似乎与医学主题有关。其他的似乎信息量不大。这是有道理的,因为这是原始矩阵的近似值,而不是矩阵的聚类。不过,这确实减少了尺寸,因此我们仍然可以将其用于下游处理。
可以直接解决我们的数据由与文档术语相关的一些特征组成的想法。

图 10-3。从术语分布构建的词云
非负矩阵分解
在非负矩阵分解 (NMF)中,我们假设文档项矩阵是其他两个矩阵的乘积。这些矩阵相乘的维度将有我们的集群。这将为我们提供一个文档矩阵和一个术语矩阵,每个矩阵都具有跨集群的分布。
X=D · T
如果我们有M文档和N术语,并且我们想要K集群,X那么 是一个MxN矩阵,D是一个MxK矩阵,并且T是一个KxM矩阵。在 scikit-learn 中,这些矩阵是近似的,因为没有封闭形式的方法来计算这些矩阵。让我们尝试一些玩具数据的示例。
from sklearn.decomposition import NMF
我们将创建我们的随机矩阵,然后分成两个簇。
np.random.seed(314)
X = np.array(np.random.randint(1, 20, size=21).reshape(7, 3))
m = NMF(n_components=2, init='random', random_state=314)
D = m.fit_transform(X)
T = m.components_
Xarray([[ 9, 14, 10],
[11, 15, 17],
[ 8, 3, 8],
[17, 4, 13],
[ 8, 5, 1],
[ 5, 14, 9],
[17, 16, 10]])
现在,两个矩阵的乘积应该近似于原始矩阵。
X_hat = np.dot(D, T)
X_hatarray([[ 8.82168512, 13.8817222 , 10.31193979],
[12.94642621, 16.30109226, 13.58360985],
[ 8.89151218, 3.59533529, 6.43588552],
[17.69416104, 4.46299878, 11.78275144],
[ 5.8818731 , 3.5849985 , 4.71678044],
[ 5.32011204, 14.21139378, 8.44192057],
[14.75882004, 14.50332786, 13.93210152]])
这看起来很接近,但让我们看看绝对百分比误差。
100 * np.abs(X - X_hat) / Xarray([[ 1.98127639, 0.84484142, 3.11939786],
[ 17.69478376, 8.67394839, 20.09641264],
[ 11.14390221, 19.8445095 , 19.55143095],
[ 4.08330023, 11.57496939, 9.3634505 ],
[ 26.47658629, 28.30002998, 371.67804413],
[ 6.40224086, 1.50995555, 6.20088253],
[ 13.1834115 , 9.35420086, 39.32101525]])
大多数误差小于 15%。但是,有一些特别严重的错误。与所有这些方法一样,您需要根据自己的需要进行调整。没有一种万能的。
让我们在 TF.IDF 矩阵上运行它。
model = NMF(n_components=100, init='nndsvdar', random_state=314)# 这需要几分钟
D = model.fit_transform(tfidf)
T = model.components_现在让我们得到我们的近似值tfidf。
tfidf_hat = np.dot(D, T)现在我们可以计算我们的绝对百分比误差。由于我们的矩阵有零,我们需要添加一个软糖因子以避免被零除。
abs_pct_error = 100 * np.abs(tfidf - tfidf_hat + 1) / (tfidf + 1)
np.median(np.array(abs_pct_error))76.86063392886243
这个错误似乎很高,但让我们看看它是如何将这些术语聚集在一起的。
cluster_term = pd.DataFrame(
model.components_.T,
index=ix2term,
columns=clusters)
cluster_term = np.round(cluster_term, decimals=4)
polynomial_vec = cluster_term.iloc[term2ix['polynomial']]
similarities = cluster_term.apply(
lambda r: 1-cosine(polynomial_vec, r), axis=1)
similarities.sort_values(ascending=False)[:20]satisfies 1.0
polynomial 1.0
polynomials 1.0
spanned 1.0
divisible 1.0
differentiable 1.0
subspace 1.0
scalar 1.0
monic 1.0
commutes 1.0
commute 1.0
nilpotent 1.0
decomposes 1.0
algebraically 1.0
algebra 1.0
primes 1.0
integers 1.0
exponential 1.0
expressible 1.0
subspaces 1.0
dtype: float64似乎它已成功地将相似的单词组合在一起。现在让我们看一下词云,如图10-4所示。
chosen_ix = [0, 97, 1, 98, 2, 99]
fig, axs = plt.subplots(3, 2, figsize=(10, 8))
k = 0
for i in range(len(axs)):
for j in range(len(axs[i])):
wc = WordCloud(colormap='Greys', background_color='white')
im = wc.generate_from_frequencies(
cluster_term[clusters[chosen_ix[k]]])
axs[i][j].imshow(im, interpolation='bilinear')
axs[i][j].axis("off")
axs[i][j].set_title(clusters[chosen_ix[k]], **font)
k += 1
plt.tight_layout()
plt.show()
图 10-4。从 NMF 集群构建的词云
看起来 Cluster #1 与医学术语有关,而 Cluster #97 与舞蹈有关。
潜在狄利克雷分配(LDA)
潜在狄利克雷分配 (LDA)背后的想法是文档是基于一组主题生成的。在这个过程中,我们假设每个文档都分布在主题上,并且每个主题都分布在术语上。每个文档和每个单词都是通过对这些分布进行采样而生成的。LDA 学习器向后工作并尝试识别观察到的最可能的分布。
这是一组比我们以前的技术复杂得多的假设。这是因为它试图对术语生成过程进行建模,而不是仅仅减少向量模型中的维度。
让我们看一个例子。
from sklearn.decomposition import LatentDirichletAllocation
model = LatentDirichletAllocation(
n_components=K,
random_state=314,
max_iter=100)
# 这可能需要几分钟
clustered = model.fit_transform(tfidf)
cluster_term = pd.DataFrame(
model.components_.T,
index=ix2term,
columns=clusters)
cluster_term = np.round(cluster_term, decimals=4)让我们看看哪些词最接近“多项式”,就像我们对其他技术所做的那样。
polynomial_vec = cluster_term.iloc[term2ix['polynomial']]
similarities = cluster_term.apply(
lambda r: 1-cosine(polynomial_vec, r),
axis=1)
similarities.sort_values(ascending=False)[:20]polynomial 1.0
secants 1.0
diagonalizable 1.0
hino 1.0
secant 1.0
nilpotent 1.0
invariant 1.0
congruence 1.0
jastrow 1.0
szold 1.0
commute 1.0
polynomials 1.0
involution 1.0
kayabashi 1.0
subspace 1.0
galaxies 1.0
quadric 1.0
jo 1.0
beckett 1.0
tangents 1.0
dtype: float64这似乎没有其他技术的结果那么集中。我们来看看词云,如图10-5所示。
chosen_ix = [0, 97, 1, 98, 2, 99]
fig, axs = plt.subplots(3, 2, figsize=(10, 8))
k = 0
for i in range(len(axs)):
for j in range(len(axs[i])):
wc = WordCloud(colormap='Greys', background_color='white')
im = wc.generate_from_frequencies(
cluster_term[clusters[chosen_ix[k]]])
axs[i][j].imshow(im, interpolation='bilinear')
axs[i][j].axis("off")
axs[i][j].set_title(clusters[chosen_ix[k]], **font)
k += 1
plt.tight_layout()
plt.show()
这些技术为我们提供了对文档进行聚类、降低文档向量数据的维数,甚至将单词组合在一起的方法。最近,在使用神经网络的分布式语义方面取得了很大进展。在下一章中,我们将介绍其中一些新技术。
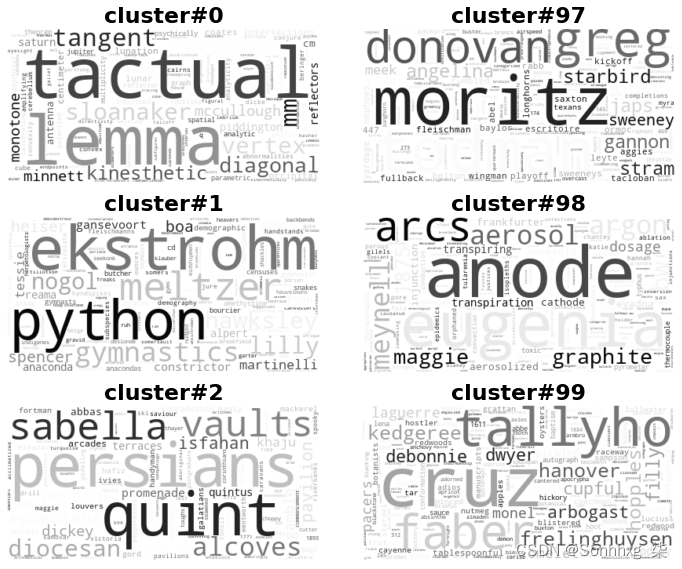
图 10-5。从主题词分布构建的词云
练习
让我们看看这些技术如何解决第 9 章中的分类问题。为此,我们将使用 Spark 的 LDA 实现。
首先,让我们加载数据。
import os
import re
import numpy as np
import pandas as pd
from pyspark.sql.types import *
from pyspark.sql.functions import expr
from pyspark.sql import Row
from pyspark.ml import Pipeline
from pyspark.ml.feature import *
from pyspark.ml.clustering import LDA
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
import sparknlp
from sparknlp import DocumentAssembler, Finisher
from sparknlp.annotator import *
%matplotlib inline
spark = sparknlp.start()HEADER_PTN = re.compile(r'^[a-zA-Z-]+:.*')
def remove_header(path_text_pair):
path, text = path_text_pair
lines = text.split('\n')
line_iterator = iter(lines)
while HEADER_PTN.match(next(line_iterator)) is not None:
pass
return path, '\n'.join(line_iterator)path = os.path.join('data', 'mini_newsgroups', '*')
texts = spark.sparkContext.wholeTextFiles(path).map(remove_header)
schema = StructType([
StructField('path', StringType()),
StructField('text', StringType()),
])
texts = spark.createDataFrame(texts, schema=schema) \
.withColumn('newsgroup', expr('split(path, "/")[7]')) \
.persist()
train, test = texts.randomSplit([0.8, 0.2], seed=123)现在,让我们构建我们的 NLP 管道。
assembler = DocumentAssembler()\
.setInputCol('text')\
.setOutputCol('document')
sentence = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentences")
tokenizer = Tokenizer()\
.setInputCols(['sentences'])\
.setOutputCol('token')
lemmatizer = LemmatizerModel.pretrained()\
.setInputCols(['token'])\
.setOutputCol('lemma')
normalizer = Normalizer()\
.setCleanupPatterns([
'[^a-zA-Z.-]+',
'^[^a-zA-Z]+',
'[^a-zA-Z]+$',
])\
.setInputCols(['lemma'])\
.setOutputCol('normalized')\
.setLowercase(True)
finisher = Finisher()\
.setInputCols(['normalized'])\
.setOutputCols(['normalized'])\
.setOutputAsArray(True)让我们删除停用词并使用 TF.IDF 向量。
stopwords = set(StopWordsRemover.loadDefaultStopWords("english"))
sw_remover = StopWordsRemover() \
.setInputCol("normalized") \
.setOutputCol("filtered") \
.setStopWords(list(stopwords))
count_vectorizer = CountVectorizer(
inputCol='filtered', outputCol='tf', minDF=10)
idf = IDF(inputCol='tf', outputCol='tfidf')Spark 有一个 LDA 的实现。让我们将它与逻辑回归结合使用作为我们的分类器。我们将使用VectorAssembler.
lda = LDA(
featuresCol='tfidf',
seed=123,
maxIter=20,
k=100,
topicDistributionCol='topicDistribution',
)
vec_assembler = VectorAssembler(
inputCols=['tfidf', 'topicDistribution'])logreg = LogisticRegression(
featuresCol='topicDistribution',
maxIter=100,
regParam=0.0,
elasticNetParam=0.0,
)最后,我们组装我们的管道。
label_indexer = StringIndexer(
inputCol='newsgroup', outputCol='label')
pipeline = Pipeline().setStages([
assembler, sentence, tokenizer,
lemmatizer, normalizer, finisher,
sw_remover, count_vectorizer, idf,
lda, vec_assembler,
label_indexer, logreg
])
evaluator = MulticlassClassificationEvaluator(metricName='f1')
model = pipeline.fit(train)
train_predicted = model.transform(train)
test_predicted = model.transform(test)
print('f1', evaluator.evaluate(train_predicted))f1 0.9956621119176594
print('f1', evaluator.evaluate(test_predicted))f1 0.5957199376998746

















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











