






为了将训练的yolo v8部署到rk3588运行。按照官方文档与流程进行了转换尝试。
由于之前做过torch模型转onnx再转rknn,因此继续使用这个套路推进。
翻阅了一些前人的智慧
https://blog.csdn.net/m0_48979117/article/details/135628375
直接使用模型精度惨不忍睹,还是要在理解的基础上演化运用,这里记录一些踩到的关键坑。
1、 选择网络输出的node
使用yolo官网写的导出onnx格式代码导出onnx模型
torch_model = YOLO("best.pt")
onnx_file = torch_model.export(format="onnx", imgsz=640, opset=19, dynamic=False)
模型的末段部分如图所示:
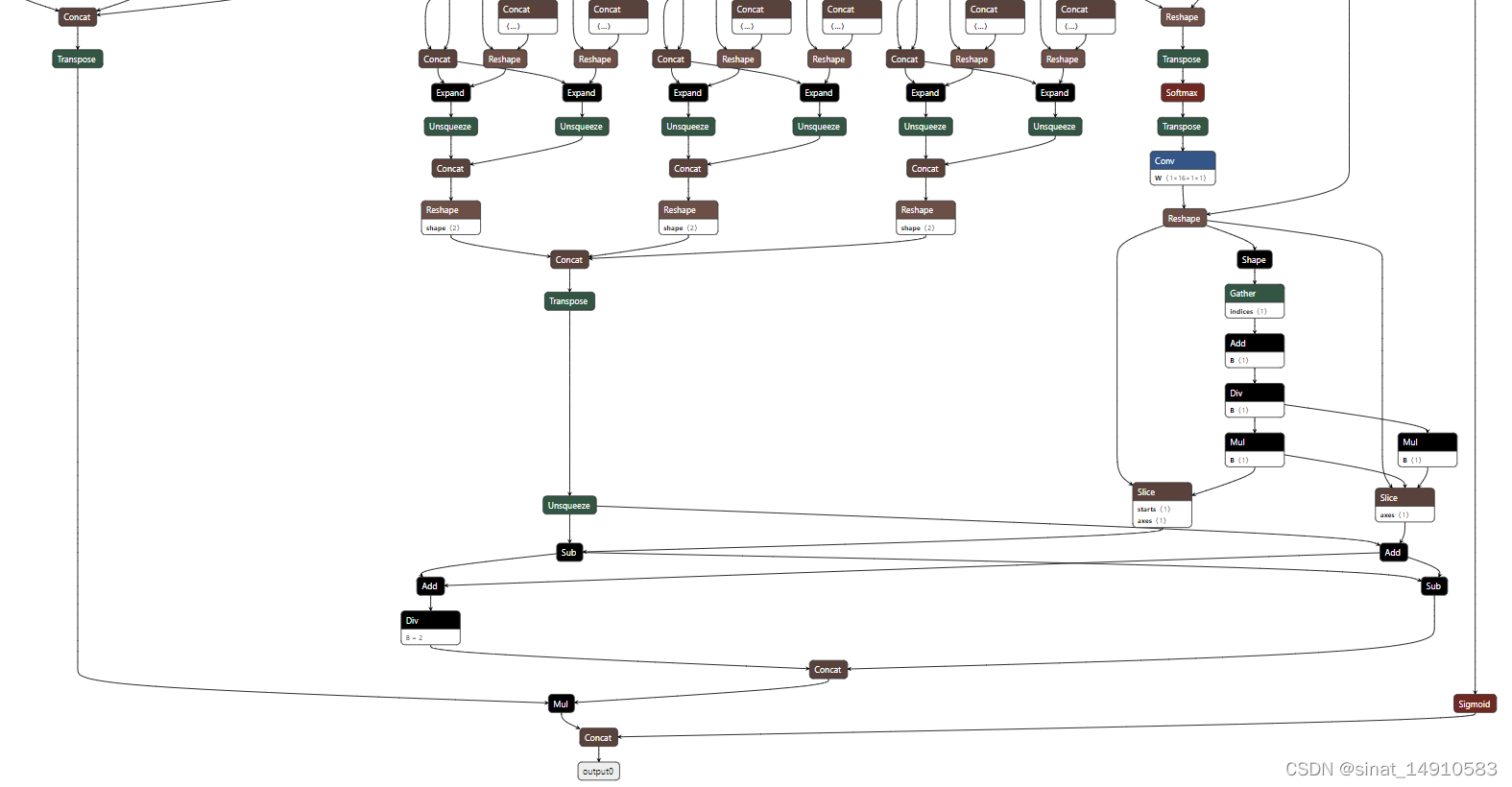
yolov8官方代码输出的onnx模型的最终输出是一个[bsz, 4+n_cls, n_boxes] 维度的向量。如果用onnx推理,这个output0输出配合后处理得到的结果与pt模型推理的误差在2e-5的级别,误差可忽略不计。然而转换成rknn模型后不需要统计也知道差异巨大。
查询资料,大佬说rknn转换中的量化环节经过sigmoid以后精度完全丢失了,因此需要提取输出[‘/model.22/Mul_5_output_0’, ‘/model.22/Split_1_output_1’](分别是下图中黄色标记的node的输入)作为输出,在后处理代码中进行sigmoid计算。
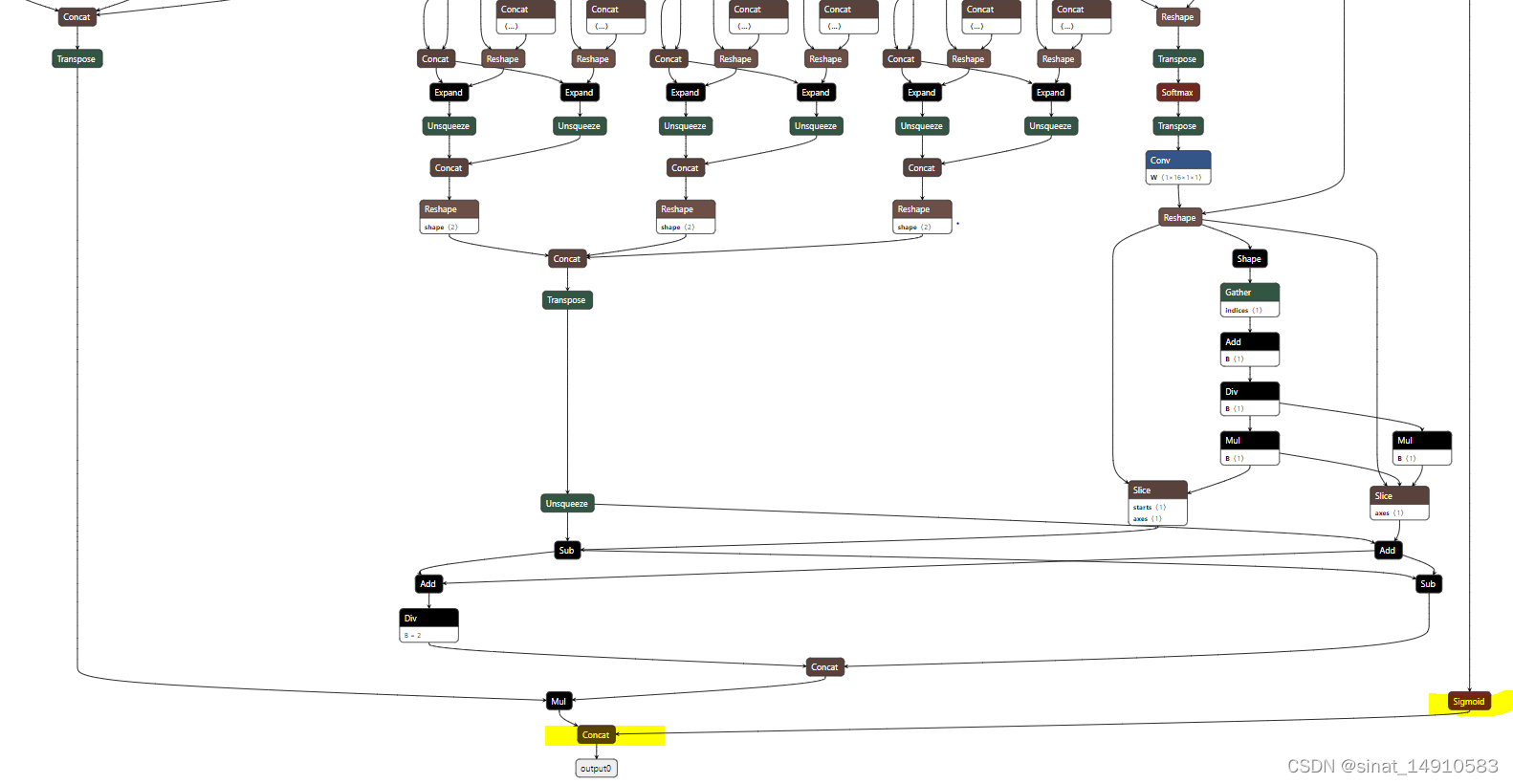
对应的rknn配置如下
rknn.load_onnx(
model=ONNX_MODEL,
inputs=['images'],
input_size_list=[[1,3,640,640]],
outputs=[
'/model.22/Mul_5_output_0', '/model.22/Split_1_output_1',
]
)
rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET, rknn_batch_size=1)
rknn.export_rknn(RKNN_MODEL)
2、输出模型结构相关的静态参数
npu使用了特殊的NC1HWC2数据排列,因此rknn在转换过程中会改变模型的维度。因此原yolov8中从模型中提取的常数项会在rknn转换中被改变,进而影响后处理

我的处理相对简单,就是在模型export成onnx时同时将相关静态参数一并导出为配置文件,在后续处理中加载使用。
具体方法是在编辑ultralytics项目的原始文件:ultralytics\nn\modules\head.py
修改前:
if self.export and self.format in ("tflite", "edgetpu"):
# Precompute normalization factor to increase numerical stability
# See https://github.com/ultralytics/ultralytics/issues/7371
img_h = shape[2]
img_w = shape[3]
img_size = torch.tensor([img_w, img_h, img_w, img_h], device=box.device).reshape(1, 4, 1)
norm = self.strides / (self.stride[0] * img_size)
dbox = dist2bbox_rknn(self.dfl(box) * norm, self.anchors.unsqueeze(0) * norm[:, :2], xywh=True, dim=1)
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, x)
修改后:
if self.export and self.format in ("tflite", "edgetpu"):
# Precompute normalization factor to increase numerical stability
# See https://github.com/ultralytics/ultralytics/issues/7371
img_h = shape[2]
img_w = shape[3]
img_size = torch.tensor([img_w, img_h, img_w, img_h], device=box.device).reshape(1, 4, 1)
norm = self.strides / (self.stride[0] * img_size)
dbox = dist2bbox_rknn(self.dfl(box) * norm, self.anchors.unsqueeze(0) * norm[:, :2], xywh=True, dim=1)
y = torch.cat((dbox, cls.sigmoid()), 1)
if self.export and self.format == 'onnx':
torch.save(self.anchors.unsqueeze(0),'./anchors.pt')
torch.save(self.strides,'./strides.pt')
return self.dfl(box), cls
return y if self.export else (y, x)
这段代码的作用有2点:
1、导出onnx时将静态参数向量保存到本地,推理时将两个文件与模型一起下载到板端
2、相比上一节从onnx模型中选择输出点,将推理结果直接作为输出点,截断了后续模型。
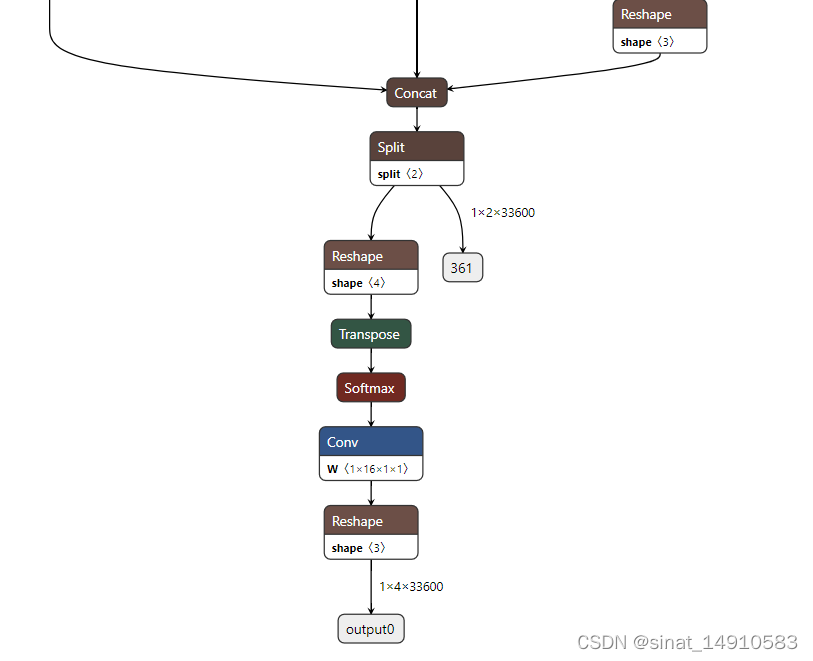
3、修改官方前处理与后处理代码
官方前处理代码中对图像进行了归一化、通道变换,rknn推理时又会做一次。
因此板端推理的前处理中要剔除相关操作
rknn.config(
# see:ultralytics/yolo/data/utils.py
mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
quantized_algorithm='normal',
quantized_method='channel',
# optimization_level=2,
compress_weight=False, # 压缩模型的权值,可以减小rknn模型的大小。默认值为False。
single_core_mode=True,
# model_pruning=False, # 修剪模型以减小模型大小,默认值为False。
target_platform='rk3588'
)
4、总结
以上是本菜鸡的一些粗略的踩坑记录,希望对同样困扰的伙伴有所帮助。
若有大神路过请留言指导,拯救一下我这个小白。















 3866
3866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









