






1.局部权重线性回归(自译)
—–Locally weighted linear regression
在介绍该中线性回归方法之前,先引入一些概念:
- 欠拟合(underfitting):对训练特征的复杂度或者说特征空间的维度估计过低,导致拟合效果不足的现象
- 过拟合(overfitting):训练特征的复杂度或者说特征空间的维度估计过高,导致过分拟合的结果
因为两种拟合都不能得到满意的拟合结果,在线性回归中加入权重函数,得到locally weighted linear regression
该方法通过最小化下式来得到需要预测的点的参数
θ
:
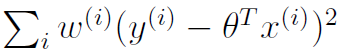
其中 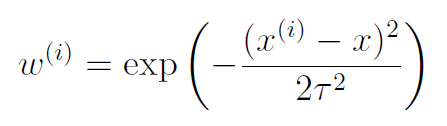
个人认为,该算法通过对局部取样本点,达到通过局部的线性来拟合非线性的效果,其中权重函数相当于一个截断函数,宽度由带宽参数
τ2
控制,这里权重函数可以取其他合适的函数。该方法计算量大,对于每一个预测点需要单独计算参数。
该方法是一个non-parametric算法:对于每一个新的预测点,我们需要保留原始训练集,重新训练。
parametric算法:一次训练后,可以得到固定的参数,训练集即可以丢弃。
对于线性回归的概率解释
—–Probabilistic interpretation
在频率学家的认知中,
θ
是事物固有的参数,是一个常量,而我们需要预测的目标值,是一个随机变量,该变量的概率密度函数由参数
θ
表示,由于中心极限定理,我们通常认为该变量概率密度函数为呈高斯状,如下式:
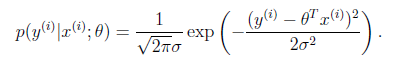
即 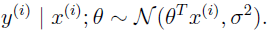
定义可能性函数likelihood function:
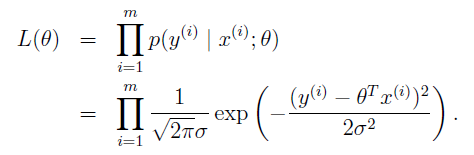
根据最大可能性mamum likelihood原则,我们所选择的
θ
应该在定义域中使可能性函数值最大.
为了方便推导计算,对可能性函数取对数log,结果如下:
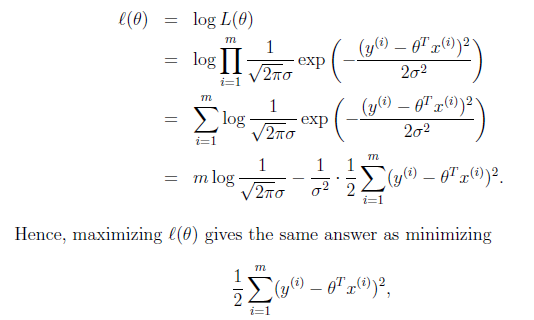
可见该种思路得到的结果与最小二乘方算法得到的最终形式相同,对上式进行分析,高斯函数的方差
τ2
对结果没有影响,这点会在后续的课程中进行讨论。
分类与逻辑回归
—–classification and logistic regression
对于二分类问题,之前的线性回归方法不太适用,因为目标函数值是离散的。因此我们引入逻辑函数logistic or sigmoid function:
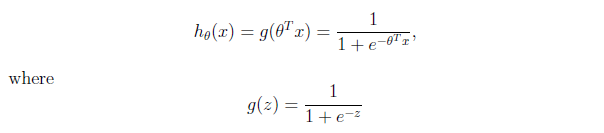
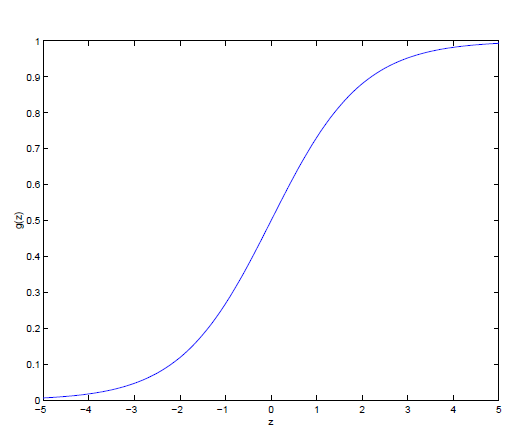
概率密度函数可写为
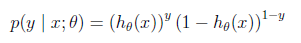
可能性函数推导如下:
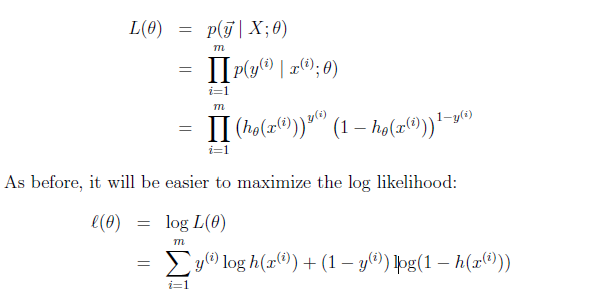
θ
使用梯度上升法:
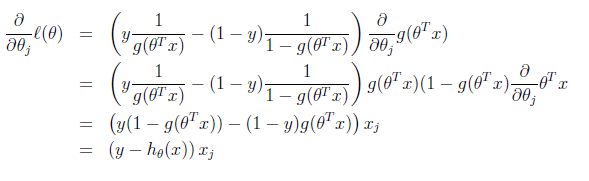
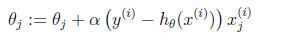
注意,该算法与LMS算法并不相同,这里h函数是一个非线性函数,不过奇妙的是最后我们使用了相同的更新算法,即梯度下降与梯度上升。这背后的原因将会在GML模型中得到深入的分析。
补充:感知器算法
对逻辑函数进行修正:
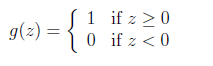
然后使用梯度上升计算参数
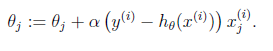
这便是感知器算法。
请注意,感知器算法不同于逻辑回归算法和最小均方差算法,它不能找到合理地概率论的解释,或者像最大可能性函数一样推导感知器。















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









