






从玻尔兹曼机到深度置信网络
本文仍处于草稿阶段,请慎重观看
引言
受限玻尔兹曼机(Restricted Boltzmann Machines, RBM)最初是在1986年由Paul Smolensky发明,在Geoffrey Hinton和合作者在2005年左右为其发明了快速学习的算法之后,RBM得以进一步发展。RBM可用于可用于降维、分类、回归、协同过滤、特征学习和主题建模。根据任务,RBM可用于监督学习或无监督学习。
RBM也可用于深度学习网络。具体而言,深度置信网络(Deep Belief Networks)可以通过“堆叠”RBM并可选地通过梯度下降和反向传播来微调网络的参数。
- 本文将从玻尔兹曼机的结构开始介绍,其后引申至受限玻尔兹曼机,最后介绍由受限玻尔兹曼机堆叠而成的深度置信网络。
1. 玻尔兹曼机
玻尔兹曼机(Boltzmann Machine,BM)是一个为整个网络定义“能量”的单元网络。BM的节点产生二元结果(0或1),一个玻尔兹曼机可以表示为带权重的无向图:

由上图可以看出BM的结构为层间、层内全连接。由于每个节点是二值的,所以一共有
2n
2
n
个状态,对于一个节点
xi
x
i
,其值为1 的时候表示这个节点是’on’,其值为0的时候表示这个节点是’off’。
与Hopfield网络不同,玻尔兹曼机节点是随机的。而BM的能量形式与Hopfield网络的形式相同:
其中, wij w i j 为节点 i i 和 j j 之间的连接权重; si s i 为节点 i i 的状态,其值为0或1;为节点 i i 的偏置。
1. 1 玻尔兹曼机节点状态概率
BM的全局能量差值由每个节点的状态差值产生,由下式给出:
2. 受限玻尔兹曼机
无连接约束(层间层内全连接)的波尔兹曼机被证明在机器学习实际问题中效果不佳,但是如果节点的连接受到适当限制,则可以使学习效果足够有效以用于解决实际问题。
受限玻尔兹曼机是玻尔兹曼机的一种变体,区别于玻尔兹曼机,受限玻尔兹曼机可见节点和隐含节点之间存在连接,而隐含节点两两之间以及可见节点两两之间不存在连接,也就是层间全连接,层内无连接。
RBM可以表示成一个二分图模型,所有可见层节点和隐藏层节点都有两种状态:处于激活状态时值为1,未被激活状态值为0。这里的0和1状态的意义是代表了模型会选取哪些节点来使用,处于激活状态的节点被使用,未处于激活状态的节点未被使用。节点的激活概率由可见层和隐藏层节点的分布函数计算。
下面给出RBM模型的数学化定义:
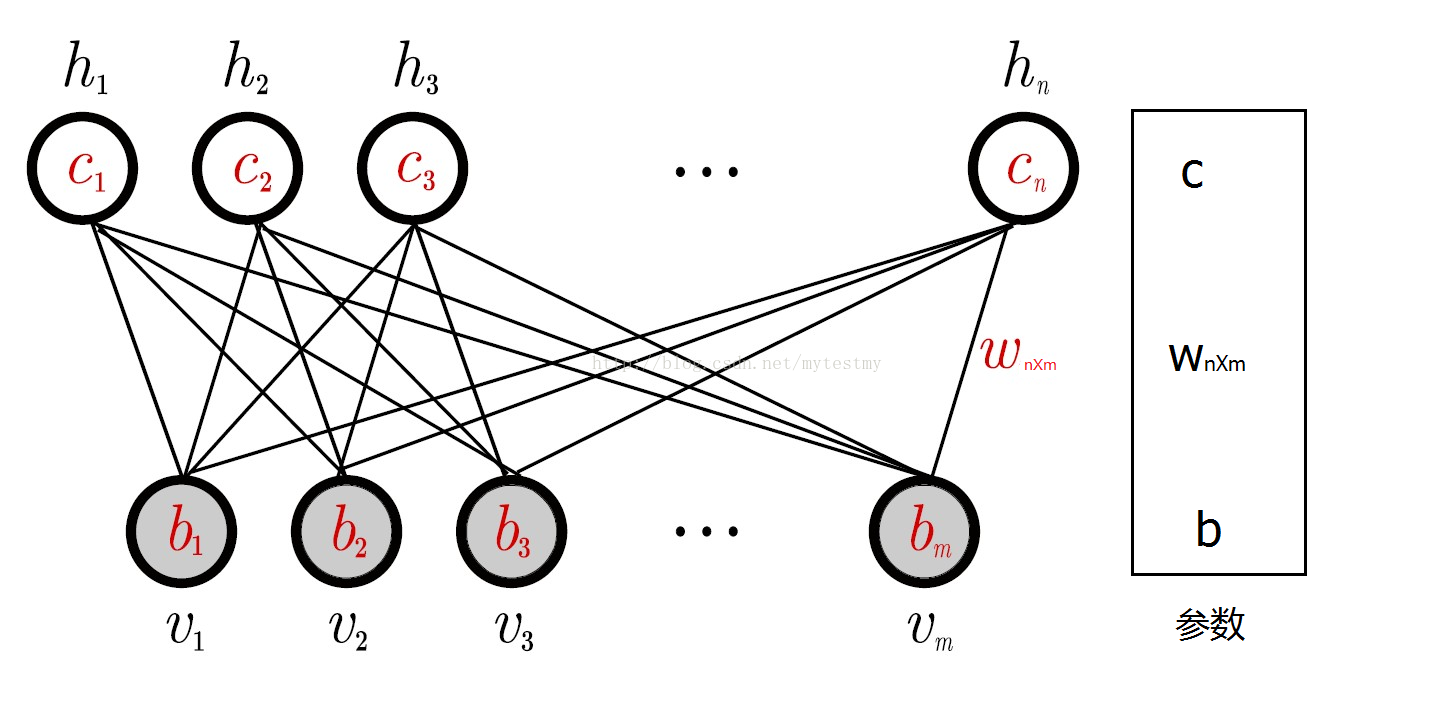
RBM有如下性质:
当给定可见层神经元的状态时,各隐藏层神经元的之间是否激活是条件独立的;反之也同样成立。
2.1 受限玻尔兹曼机参数学习
RBM中,
v
v
表示所有可见单元,表示所有隐单元。要想确定该模型,只要能够得到模型三个参数
θ={W,A,B}
θ
=
{
W
,
A
,
B
}
即可。分别是权重矩阵
W
W
,可见层单元偏置,隐藏层单元偏置
B
B
。
假设一个RBM有个可见单元和
m
m
个隐单元,用表示第
i
i
个可见单元,表示第
j
j
个隐单元,它的参数形式为:
,其中
Wi,j
W
i
,
j
表示第
i
i
个可见单元和第个隐单元之间的权值
A={ai∈Rm}
A
=
{
a
i
∈
R
m
}
,其中
ai
a
i
表示第
i
i
个可见单元的偏置阈值
,其中
bj
b
j
表示第
j
j
个可见单元的偏置阈值
对于一组给定状态下的值,假设可见层单元和隐藏层单元均服从伯努利分布,RBM的能量公式是:
对该能量函数指数化和正则化后可以得到可见层节点集合和隐藏层节点集合分别处于某一种状态下 (v,h) ( v , h ) 联合概率分布公式:
对于参数的求解往往采用似然函数求导的方法。已知联合概率分布 P(v,h|θ) P ( v , h | θ ) ,通过对隐藏层节点集合的所有状态求和,可以得到可见层节点集合的边缘分布 P(v|θ) P ( v | θ ) :
由于RBM模型的特殊的层间连接、层内无连接的结构,它具有以下重要性质:
1)在给定可见单元的状态时,各隐藏层单元的激活状态之间是条件独立的。此时,第
j
j
个隐单元的激活概率为:

采用该函数用作每一层节点的激活概率公式的原因是:sigmoid函数的定义域是
(−∞,+∞)
(
−
∞
,
+
∞
)
,值域处于
(0,1)
(
0
,
1
)
之间。也就是说,无论模型的可见层输入节点数据处于一个多大的范围内,都可以通过sigmoid函数求得它相应的函数值,并且该函数值被压缩于0到1之间,即节点的激活概率值。
2.2 受限玻尔兹曼机模型参数求解
确定RBM模型需要求解模型的三个参数 θ={Wij,ai,bj} θ = { W i j , a i , b j } ,下面围绕参数的求解进行分析。
参数求解使用对数似然函数对参数求导。
从
P(v|θ)=1Z(θ)∑he−E(v,h|θ)
P
(
v
|
θ
)
=
1
Z
(
θ
)
∑
h
e
−
E
(
v
,
h
|
θ
)
可知,能量
E
E
和概率成反比,通过最大化
P
P
来最小化。最大化似然函数常用方法是梯度上升法,梯度上升法是指按照以下公式对参数进行修改:
对数似然函数的格式: lnP(vs) l n P ( v s ) , vs v s 表示模型的输入数据,此处先对单个样本进行分析,即 vs v s 为数据集中第 s s 个样本。
然后对里的参数分别进行求导,详细的推导过程就不写了:
2.3 模型训练算法
通过常规的MCMC采样法来估计上面的式子的未知项十分缓慢,最大原因在于需要经过很多步的状态转换才能保证采集到的样本符号目标分布。既然我们的目标是让RBM拟合训练样本的分布,那么是否可以考虑让MCMC的状态以训练样本作为起点呢?这样一来也许这些状态只需要很少次数的状态转换就可以抵达RBM的分布了。 基于这个想法,Hinton教授于2002年发明了对比散度算法(Contrastive Divergence,CD),该方法目前已成为训练RBM的标准算法。
k步CD算法(CD-k)具体可描述为:对
∀v∈S
∀
v
∈
S
,取初始值
v(0):=v
v
(
0
)
:=
v
,然后执行k次采样:
for t = 1,2,3,……,k:
利用
P(h|v(t−1))
P
(
h
|
v
(
t
−
1
)
)
采样出
h(t−1)
h
(
t
−
1
)
利用
P(v|h(t−1))
P
(
v
|
h
(
t
−
1
)
)
采样出
v(t)
v
(
t
)
接着,利用k次采样后得到的
v(k)
v
(
k
)
来估计2.2中的三个公式
∂lnP(vt)∂wi,j
∂
l
n
P
(
v
t
)
∂
w
i
,
j
、
∂lnP(vt)∂ai
∂
l
n
P
(
v
t
)
∂
a
i
、
∂lnP(vt)∂bj
∂
l
n
P
(
v
t
)
∂
b
j
,具体为:
至此,梯度计算公式都变得具体可算了。
2.3.模型的评估
对于已经学习或者正在学习的RBM,评价其优劣的指标常用重构误差(reconstruction error),即以训练样本作为初始状态,经过RBM的分布进行一次Gibbs转移后与原数据的差异量,具体为:

重构误差能在一定程度上反映RBM对训练样本的似然度,不过并不完全可靠。但其计算较简单,在实践中非常有用。
另外还有一种叫退火式重要性抽样也可计算RBM对训练数据的似然度。
3 深度置信网络
深度置信网络(Deep Belief Nets,DBN)神经网络的一种。既可以用于非监督学习,类似于一个自编码机;也可以用于监督学习,作为分类器来使用。
从非监督学习来讲,其目的是尽可能地保留原始特征的特点,同时降低特征的维度。从监督学习来讲,其目的在于使得分类错误率尽可能地小。而不论是监督学习还是非监督学习,DBN的本质都是Feature Learning的过程,即如何得到更好的特征表达。
一个DBN模型由若干个RBM堆叠而成,训练过程由低到高逐层进行训练,其结构如下图所示:
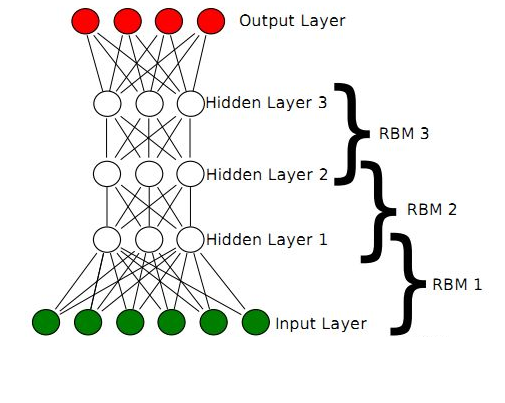
回想一下RBM,由可见层、隐层组成,可见单元用于接受输入,隐含单元用于提取特征,因此隐含单元也有个别名,叫特征检测器。也就是说,通过RBM训练之后,可以得到输入数据的特征。
另外,RBM还通过学习将数据表示成概率模型,一旦模型通过无监督学习被训练或收敛到一个稳定的状态,它还可以被用于生成新数据。
正是由于RBM的以上特点,使得DBN逐层进行训练变得有效,通过隐层提取特征使后面层次的训练数据更加有代表性,通过可生成新数据能解决样本量不足的问题。逐层的训练过程如下:
(1)最底部RBM以原始输入数据进行训练
(2)将底部RBM抽取的特征作为顶部RBM的输入继续训练
(3)重复这个过程训练以尽可能多的RBM层
Hinton提出,这种预训练过程是一种无监督的逐层预训练的通用技术,也就是说,不是只有RBM可以堆叠成一个深度网络,其它类型的网络也可以使用相同的方法来生成网络。
参考文献
[1]https://www.cnblogs.com/jhding/p/5687696.html [2]https://blog.csdn.net/u010223750/article/details/60882390
[3]https://blog.csdn.net/itplus/article/details/19408143
[4]Hinton G. A practical guide to training restricted Boltzmann machines[J]. Momentum, 2010, 9(1): 926.
[5]Bengio Y, Lamblin P, Popovici D, et al. Greedy layer-wise training of deep networks[J]. Advances in neural information processing systems, 2007, 19: 153.
[6]Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural computation, 2006, 18(7): 1527-1554.
[7]https://en.wikipedia.org/wiki/Restricted_Boltzmann_machine
[8]https://blog.csdn.net/Rainbow0210/article/details/53010694?locationNum=1&fps=1
[9]https://my.oschina.net/u/876354/blog/1626639















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









