








写在前面:
本教程将介绍从原始标注数据到训练EfficientDet的全部过程,适合入门级选手,你将得到:
(1)详细的步骤介绍
(2)数据集处理代码
(3)EfficientDet训练示例代码
(4)EfficientDet官方预训练模型(百度网盘,链接在文末)
大家有任何问题可留言交流,必要时进行远程协助~
【EfficientDet系列文章】
Part-1 EfficientDet简介
Part-2 项目实战(训练Pascal VOC 2012)
Part-3 项目实战(训练口罩检测)
目录
1 说明
本教程采用的是EfficientDet官方原版开源代码,链接:
https://github.com/google/automl/tree/master/efficientdet
文末有本教程对应的工程源码、EfficientDet官方预训练模型(百度网网盘下载地址)
推荐环境配置:
- TensorFlow >= 2.0 (建议采用最新版的TensorFlow)
- CUDA >= 10.0
EfficientDet对各种Python包依赖不强,环境较为容易配置,主要是TensorFlow
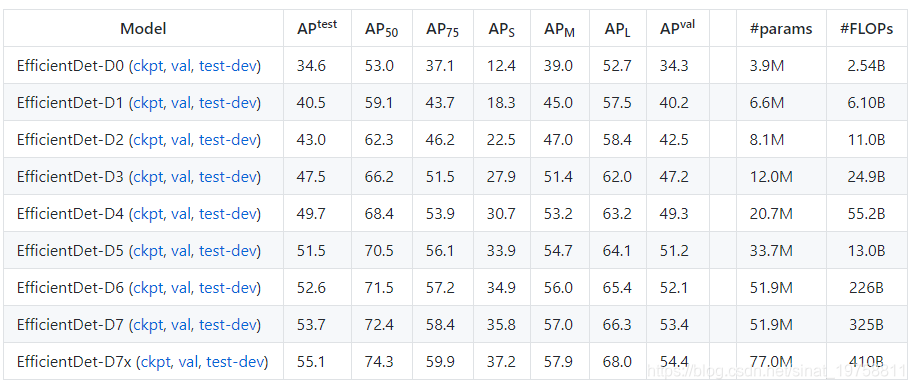
本教程主要介绍如何训练自己的数据,EfficientDet原理不再过多介绍,其实力毋庸置疑,有图为证
COCO test-dev2017 指标(截至2020.08.14)
2 数据准备
数据集处理工具为 data_process_eff
GitHub地址:https://github.com/polar99/Data_Process_of_EfficientDet
2.1 原始标注数据整理
注意:数据集标注采用VOC格式,其他标注格式后续会做兼容
一般来讲,数据集标注后会得到图像和xml两种文件,其中图像是jpg格式。
按照VOC格式要求,图像文件夹命名为JPEGImages,标注文件夹命名为Annotations,目录结构如下:

2.2 数据集预处理
自己标注的数据集中,box的坐标可能存在错误,比如 box的 xmax > img_witdh,因此在正式训练之前,首先使用工程下的 check_xmls.py检查并自动修正错误的标注。
在工程data_process_eff目录下运行:
python check_xmls.py --xml_path=your_data_path/Annotations2.3 数据集划分
数据集一般划分为
- 训练集 train
- 验证集 val
- 测试集 test
考虑到实际项目中,可能接触不到带有标注的测试集或不具备测试集,本教程介绍将原始数据集划分为 训练集和验证集
Pascal VOC数据集中,使用 ImageSets/Main 文件夹下的 txt文件控制train val数据集的划分。假设原始数据共1000张图像,数据集目录结构如下所示:

在工程data_process_eff目录下运行:
python split_dataset.py --src_path=your_source_data_path --train_ratio=0.9命令行参数解释:
- src_path:对应上面的src_path,其中有JPEGImages 和 Annotations 两个文件夹
- train_ratio:训练集所占的比例,则验证集的比例为(1-train_ratio)
成功运行后会在src_path下生成ImageSets/Main文件夹:

2.4 tfrecord生成
EfficientDet使用tfrecord文件进行训练,tfrecord是一种高效的文件存储结构,有利于加速TensorFlow的训练(相较于本地直接读取图像文件)。
EfficientDet源码文件夹dataset下复制一份create_pascal_tfrecord.py,命名为
my_create_pascal_tfrecord.py
注意:data_process_eff工程下也提供了修改好的my_create_pascal_tfrecord.py,如果不想自己改代码可直接使用该文件,省略前3步,直接进行第四步(4)。
修改my_create_pascal_tfrecord.py
(1)修改YEARS
YEARS = ['VOC2007', 'VOC2012', 'merged']
将YEARS中加入2.3中src_path文件夹名称,本人实验中的是my_set,则
YEARS = ['VOC2007', 'VOC2012', 'merged', 'my_set']
(2)修改pascal_label_map_dict
pascal_label_map_dict = {
'background': 0,
自定义类-1: 1,
自定义类-2: 2,
...
}
本人实验中,类别有2两类,车辆(vehicle)和行人(person),则
pascal_label_map_dict = {
'background': 0,
'vehicle': 1,
'person': 2,
}
(3)修改main()中的代码
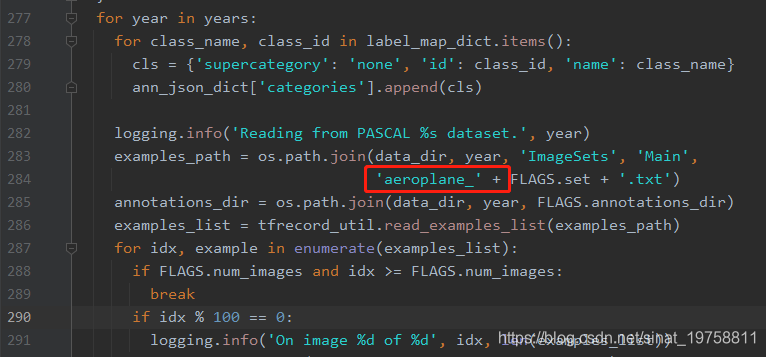
去掉‘aeroplane_'+
(4)运行my_create_pascal_tfrecord.py
本人实验时的数据集目录结构

运行需要指定4个参数:
- data_dir: 数据集根目录
- set:数据集类型train、val、 test
- year:数据集名称
- output_path:tfrecord保存路径
建议使用绝对路径,本人实验时运行的命令:
python my_create_pascal_tfrecord.py \
--data_dir=D:/dataset \
--set=train \
--year=my_set \
--output_path=D:/dataset/my_set可能出现的错误:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 109: invalid continuation byte

这个错误是由dict_to_tf_example()函数引起的,原因是my_create_pascal_tfrecord.py中的代码
img_path = os.path.join(data['folder'], image_subdirectory, data['filename'])data['folder']路径或data['filename']可能不正确。
问题主要是,自己标注的数据集中的xml内 folder字段,可能与现在数据集文件目录结构不一致导致的。可以通过脚本rectify_xml_folder.py来修改xml内的folder字段:
python rectify_xml_folder.py --src_path=D:/dataset/my_set接下来重新运行my_create_pascal_tfrecord.py 可以生成关于train的 tfrecord及json文件。再将set改为val:
python my_create_pascal_tfrecord.py \
--data_dir=D:/dataset \
--set=val \
--year=my_set \
--output_path=D:/dataset/my_set以生成关于val的 tfrecord及json文件。
注意:my_create_pascal_tfrecord.py命令行参数中有一个num_shards,用于指定tfrecord的个数,数据量较小时可以设置为1,即所有的数据集将会被打包到1个tfrecord文件
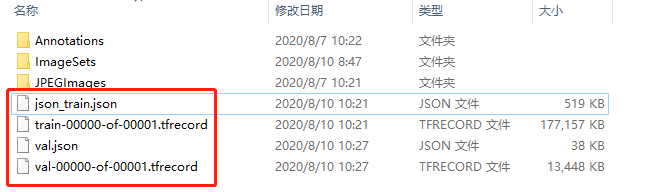
本人实验时的运行结果:
3 训练
在EfficientDet目录下新建 my_config.yaml文件
输入(本人的数据集分两类person和vehicle)
代码如下:
num_classes: 3
var_freeze_expr: '(efficientnet|fpn_cells|resample_p6)'
label_map: {1: person, 2: vehicle}运行命令
python main.py --mode=train_and_eval \
--training_file_pattern=D:/dataset/my_set/train*.tfrecord \
--validation_file_pattern=D:/dataset/my_set/val*.tfrecord \
--model_name=efficientdet-d0 \
--model_dir=/tmp/efficientdet-d0-finetune \
--ckpt=efficientdet-d0 \
--train_batch_size=12\
--eval_batch_size=12 --eval_samples=100\
--num_examples_per_epoch=900--num_epochs=50 \
--hparams=my_config.yaml其中:
- training_file_pattern和validation_file_pattern为2.4中生产的tfrecord文件,*为通配符。
- model_dir:训练时得到的ckpt文件存储路径
- ckpt:预训练模型所在目录(预训练模型可在百度网盘中下载)
- num_examples_per_epoch:训练集大小(本人的训练集900张图像)
- eval_samples:验证集大小(本人的验证集100张图像)
- hparams:自定义的配置文件
注意:以上涉及到路径配置的建议使用绝对路径。如果出现错误,不妨将路径设置为绝对路径再试试
预训练模型下载(百度网盘)
欢迎大家关注微信公众号“CV实战”,回复“effdet预训练模型”,即可获取下载地址

问题交流
大家有任何问题可留言或关注公众号交流,必要时可进行远程协助~
欢迎各位同道提出宝贵意见!


















 4057
4057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









