







一、源码下载
可以通过下方链接下载Efficientdet源码
 https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch/tree/master
https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch/tree/master二、环境配置
1、使用anaconda创建环境
conda create -n efficient python==3.8 -y2、进入环境
conda activate efficient3、安装依赖包
pip install pycocotools-windows numpy opencv-python tqdm tensorboard tensorboardX pyyaml webcolors4、安装torch和torchvision
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html5、测试配置
5.1预训练权重下载
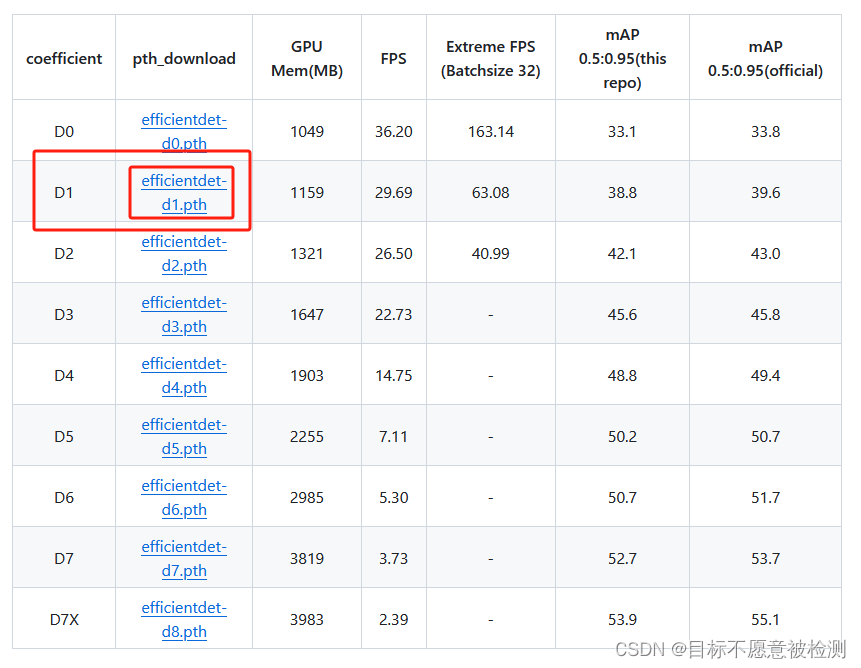
在源码下载的地方将预训练权重下载下来,这里选择的是Efficientdet-D1版本的预训练权重
在根目录下创建weights文件夹,将预训练权重放在文件夹内
5.2修改参数
在efficientdet_test.py中修改测试图片路径和efficientdet的版本,这里我下的版本是D1,所以就要将compound_coef改为1,如果你下的是其他版本,就将compound_coef改成对应的版本数字。

测试图片官方已经放在test\img.png,修改完之后运行efficientdet_test.py,检测结果保存在test文件夹内。

至此,efficientdet的所有环境配置结束。
三、自己的数据集制作
由于efficientdet使用的是coco格式的数据集,需要将标签转为coco格式,如果使用labelme进行标注,可以直接在labelme中切换成json格式的标签,最后用脚本进行合并,本文介绍的是使用VOC格式(xml)如何转为coco格式数据集。
1、划分验证集和训练集
使用下面的脚本将训练集进行划分:
# 将标签格式为xml的数据集按照8:2的比例划分为训练集和验证集
import os
import shutil
import random
from tqdm import tqdm
def split_img(img_path, label_path, split_list):
try: # 创建数据集文件夹
Data = 'yourdatasetsname'
os.mkdir(Data)
train_img_dir = Data + '/images/train'
val_img_dir = Data + '/images/val'
# test_img_dir = Data + '/images/test'
train_label_dir = Data + '/labels/train'
val_label_dir = Data + '/labels/val'
# test_label_dir = Data + '/labels/test'
# 创建文件夹
os.makedirs(train_img_dir)
os.makedirs(train_label_dir)
os.makedirs(val_img_dir)
os.makedirs(val_label_dir)
# os.makedirs(test_img_dir)
# os.makedirs(test_label_dir)
except:
print('文件目录已存在')
train, val = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









