






代码链接:EfficientDet-study(建议看我的,关键部分代码注释详细,参考Yet-Another-EfficientDet-Pytorch)
论文链接: EfficientDet、EfficientNet、EfficientNetV2
官方链接:EfficientDet
EfficientNet
在说EfficientDet之前得先了解EfficientNet架构。
在EfficientNet没出来之前,基本就是ResNet的天下。看一下官方给的对比。左边是第一代的和当时其它主流模型的对比,右边是第二代的跟自己做对比。
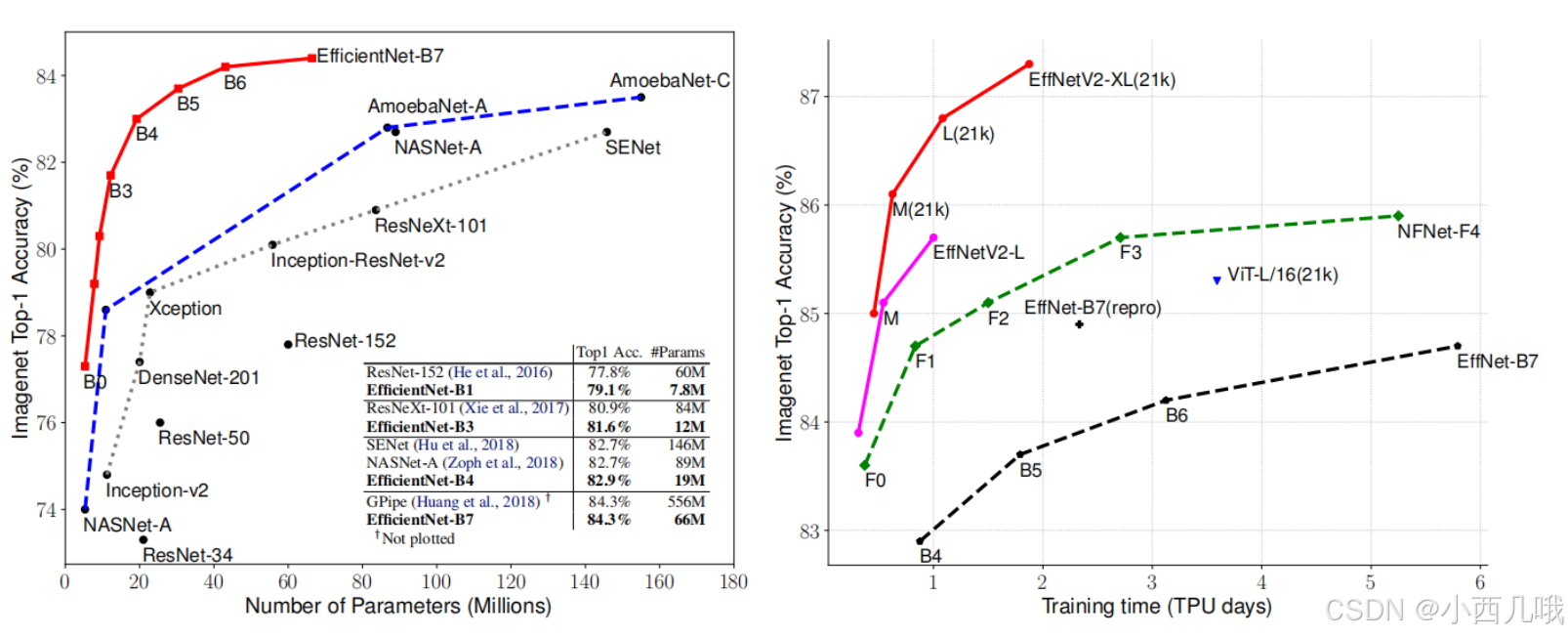
当时模型的架构可谓百花齐放,各有各的诡异之处。EfficientNet反其道而行之,辗转反侧的想怎么才能减少模型的计算量,不想搞那些花里胡哨的东西,主打一个质朴。
模型计算量主要取决于模型的深度、宽度和输入图片的分辨率。
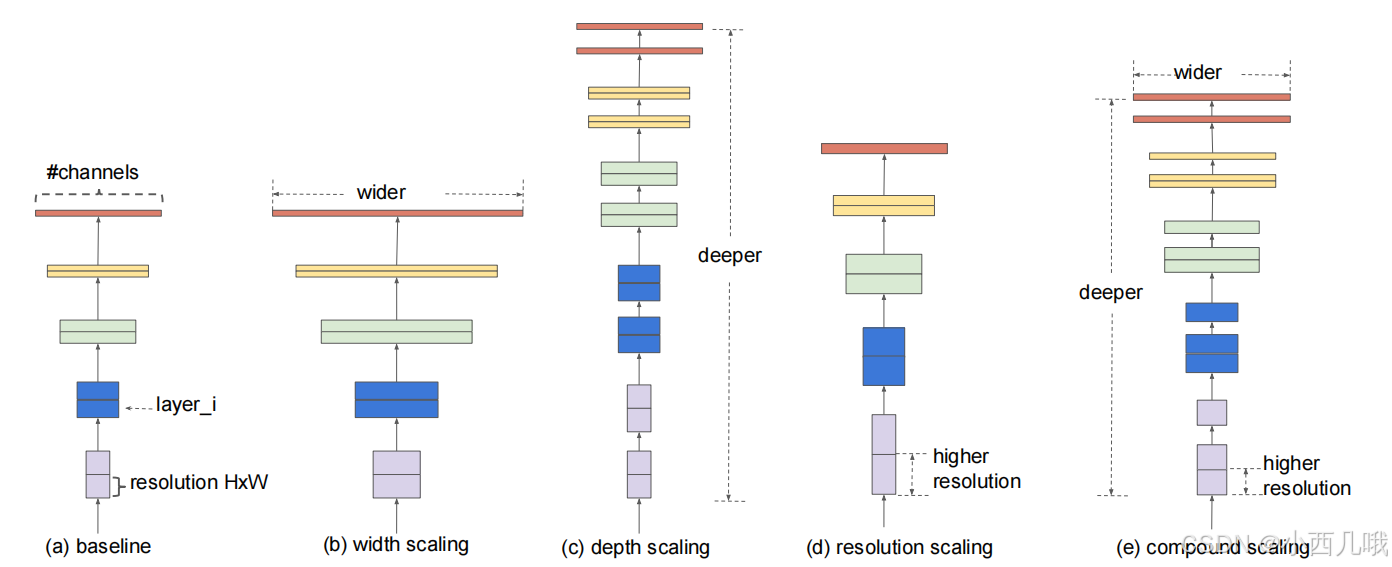
Depthwise深度可分离卷积
那应该怎么做呢?听说 MobileNetV2小弟有一个Depthwise深度可分离卷积,估摸着不错,读书人拿过来瞧瞧。
在标准的卷积中,一张输入图像通常是三通道(RGB),每个卷积核(filter)会对输入的每个通道进行卷积,然后将每个通道的卷积结果合并成一个输出特征图。这就意味着…大家都在老老实实干活。
这时候有个牛马不干了,直接起义,我一个人凭什么打三份工。说得好啊,大家纷纷举起手中的镰刀起义。上层实在顶不住压力,被迫执行了存在已久的劳动法,果然存在即合理。现在牛马是舒服了,毕竟工作量(计算量)减少了大半,但是上层开始急了啊,前端不懂后端的怎么协作啊(仅处理单通道的空间特征,没有捕捉到不同通道之间的相关性)。
看着老员工态度强硬,手握技术,不肯让步,领导一拍大腿,有了!招点实习生(1×1卷积)。果然还是实习生好啊,便宜又好用(1×1 卷积的参数量与计算量仅与输入通道数和输出通道数有关,成本相对较低。不仅可以整合特征,还可以通过改变输出通道数来调整网络的容量)。
-
标准卷积
参数量 = k2×Cin×Cout
计算量 = H×W×k2×Cin×Cout -
深度可分离卷积
参数量 = k2×Cin+Cin×Cout
计算量 = H×W×(k2×Cin+Cin×Cout)
说了这么多,怎么实现啊。很简单,就是在标准的Conv里加了个group。group=in_channels,表示每个输入通道使用一个独立的卷积核,不进行跨通道的运算。
self._depthwise_conv = Conv2d(
in_channels=oup, out_channels=oup, groups=oup, # groups makes it depthwise
kernel_size=k, stride=s, bias=False)
MBConv
MBConv是EfficientNet核心内容了。我怎么知道的呢,你看下图(EfficientNet-B0 baseline network),9个里面有7个都是MBConv,这还不核心?
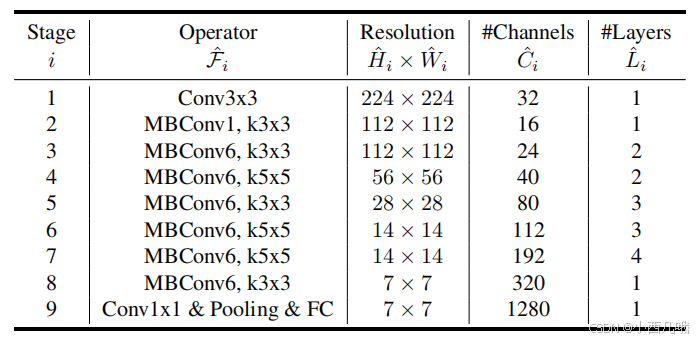
其中MBConv1不扩展通道数,MBConv6将输入通道数扩展为 6 倍。你问我为什么这么设计,还是那句老话:“经验所得”。通俗的讲就是在网络浅层时特征较少,直接卷积已经足够。后面特征复杂了,需要更高的表达能力。是不是听君一席话如听一席话。后面的Layers的意思就是这一层循环几次。
这个图可以看到,第一个MBConv的输入输出都是32,第二个MBConv的输出就是输入的6倍。
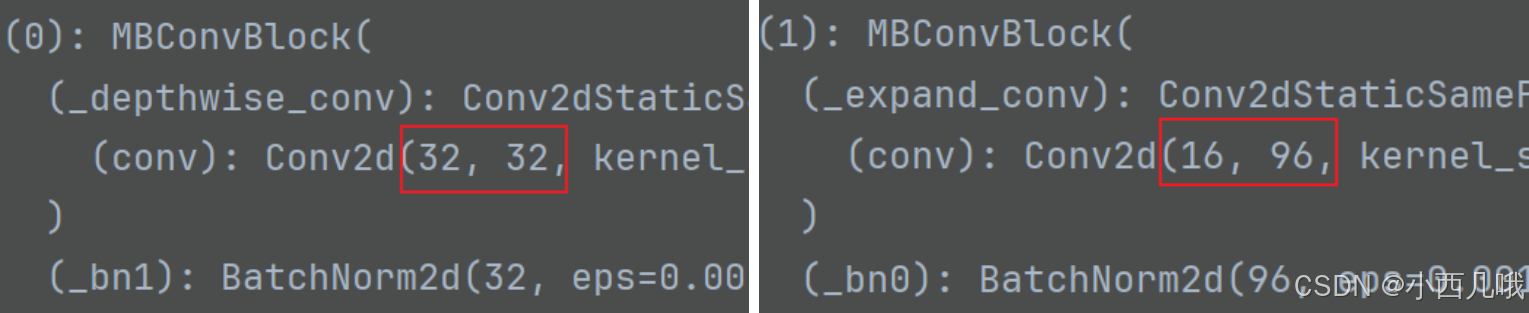
我在说下图的时候,括号EfficientNet-B0,在此处早已埋下伏笔,因为EfficientNet还有好几个版本,分别从EfficientNet-B0 到 EfficientNet-B7。它们对应的参数也都不相同,在代码里给你们看一下。compound_coef代表的就是哪个版本,例如使用EfficientNet-B2,compound_coef=2,取参数的时候就是self.backbone_compound_coef[compound_coef]
class EfficientDetBackbone(nn.Module):
def __init__(self, num_classes=80, compound_coef=0, load_weights=False, **kwargs):
super(EfficientDetBackbone, self).__init__()
self.compound_coef = compound_coef
# 根据d0-d8分了8个参数
self.backbone_compound_coef = [0, 1, 2, 3, 4, 5, 6, 6, 7]
self.fpn_num_filters = [64, 88, 112, 160, 224, 288, 384, 384, 384]
self.fpn_cell_repeats = [3, 4, 5, 6, 7, 7, 8, 8, 8]
self.input_sizes = [512, 640, 768, 896, 1024, 1280, 1280, 1536, 1536]
self.box_class_repeats = [3, 3, 3, 4, 4, 4, 5, 5, 5]
self.pyramid_levels = [5, 5, 5, 5, 5, 5, 5, 5, 6]
self.anchor_scale = [4., 4., 4., 4., 4., 4., 4., 5., 4.]
conv_channel_coef = {
# the channels of P3/P4/P5.
0: [40, 112, 320],
1: [40, 112, 320],
2: [48, 120, 352],
3: [48, 136, 384],
4: [56, 160, 448],
5: [64, 176, 512],
6: [72, 200, 576],
7: [72, 200, 576],
8: [80, 224, 640],
}
SE
在EfficientNet 的架构中,还有一个SE 模块,一个轻量级的注意力机制,用于提高特征图中重要通道的权重。
就是用两卷积计算每个特征图的权重,然后再加权求和。计算前先进行全局平均池化。正常一批数据是不是(B,C,H,W),这里不需要这个高宽的数据,所以置为1。这里的self._se_reduc和self._se_exp就是两卷积,一个先缩特征图数量,一个再还原,中间夹个self._swi激活函数。
x_squeezed = F.adaptive_avg_pool2d(x, 1) # 因为这里需要的是每个特征图的重要性,所以wh为1
x_squeezed = self._se_reduce(x_squeezed)
x_squeezed = self._swish(x_squeezed)
x_squeezed = self._se_expand(x_squeezed)
x = torch.sigmoid(x_squeezed) * x # 特征图乘上权重
EfficientDet
我的天,EfficientNet部分终于写完了,累死我了,现在进入正题。
因为EfficientDet和YOLO4属于同一时空的产物,所以无法跟YOLO4做对比,不过跟YOLO3做了对比,效果看上去还不错的样子。话说YOLO现在都出到11了,我每天跟考古的一样…
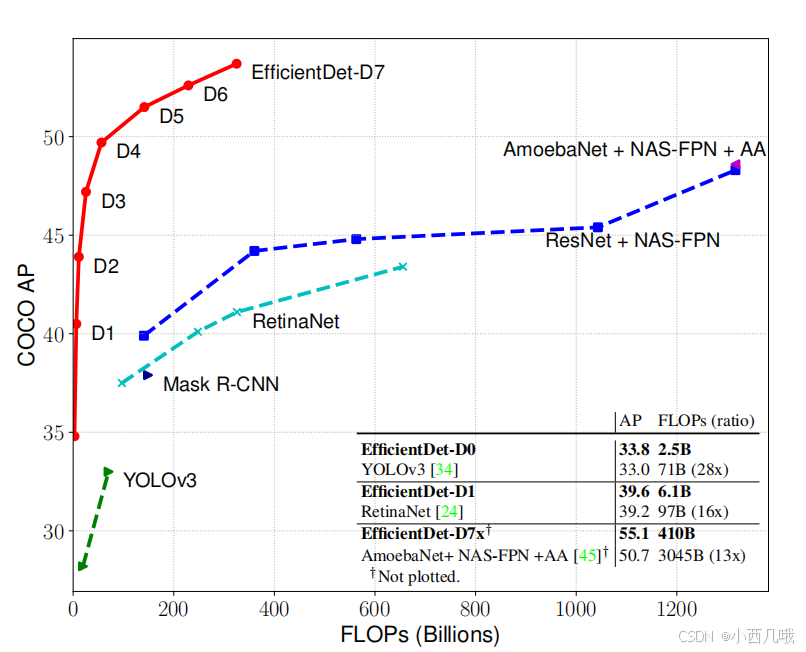
我前面花了大篇章讲EfficientNet,就是因为EfficientDet是先用EfficientNet作为主干网络提取图像特征(话说从名字也能看出来这两家伙脱不了干系,不过我一开始看名字还以为它还跟DETR有关系,结果没有)。
特征金字塔网络
特征金字塔大家应该都知道吧,就是多长尺度特征融合。为什么要这么做呢,说来话长…
做图像处理的都是先有个主干网络,然后从浅层到深层逐步提取图片特征。就是下面图中第一列没颜色的圈,它们的HW是不一样的。
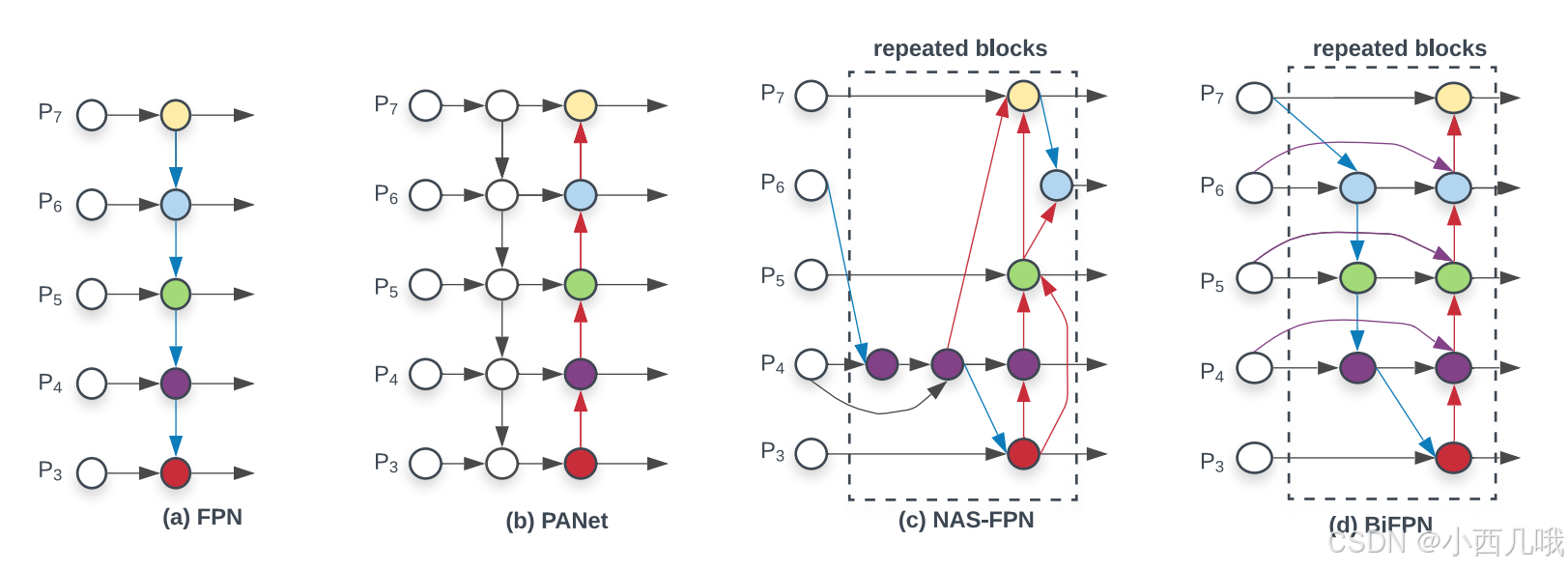
图像处理一直有个问题,就是小目标比大目标难检测。这也很好理解,你卷积的越深,你的感受野越大,每个点看到的东西越多。就像你512×512的输入,到最后一层就8×8了。我8×8就给你512×512的看完了,那我还会在意那小目标吗。那怎么办,用浅层网络啊,那会视野还没那么宽阔,还能容下一些小目标的特征。但还是有问题,浅层还没怎么训练呢,你有小目标的特征,但是根本识别不到。
深层是能力强,但看不到小目标,浅层看的到但是能力不行,没法处理,怎么办呢?当然是找大佬帮忙啊。通过上采样,将深层特征图放大到与浅层特征图相同的尺寸,然后再融合,帮助浅层小弟找到目标。
这样就能理解FPN的结构了吧,理解了FPN就理解了PANet了吧,理解了PANet,就理解了N…害,这没啥好讲的,NAS-FPN还是那句老话:“经验所得”。而本EfficientDet模型,用的就是最后一个BiFPN。
EfficientDet体系结构
上面说那么多就是为了让大家明白这图中间那个是干啥的。
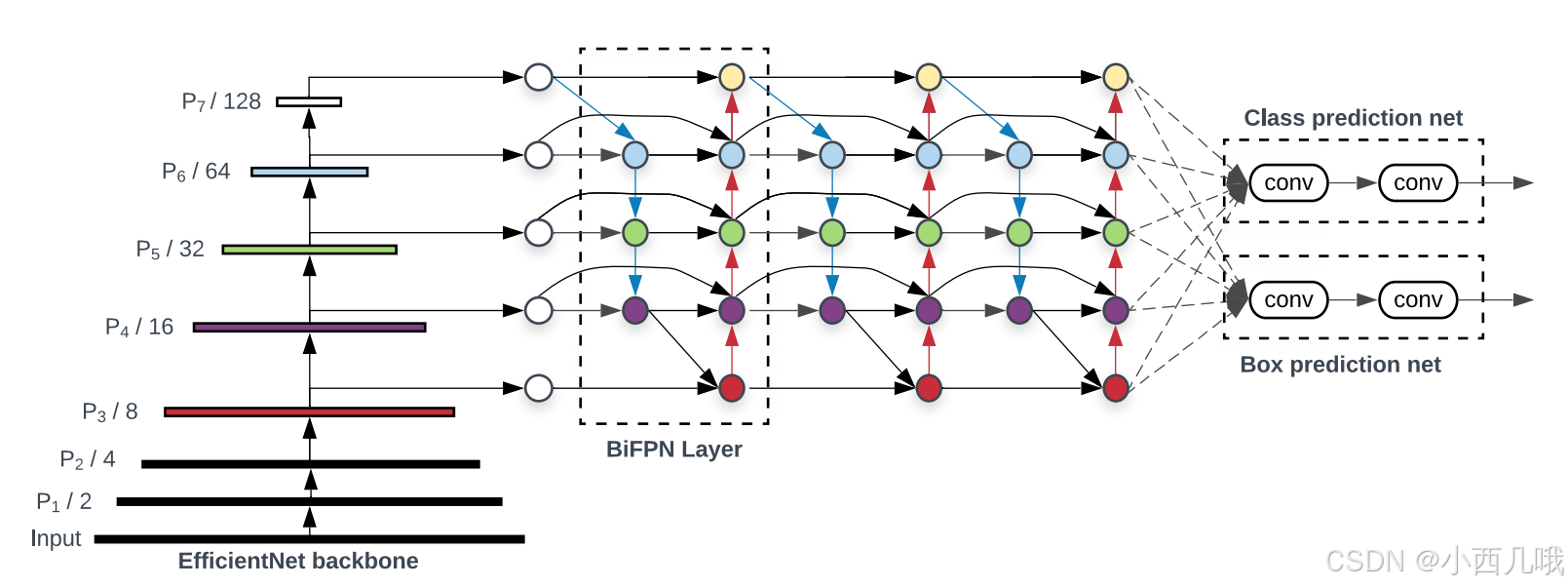
把大象装进冰箱三步走:打开冰箱门–>把大象塞进去–>关上冰箱门
EfficientDet也分三步走:EfficientNet提取特征–>BiFPN多尺度特征融合 -->两个检查头(分类网络,锚框回归网络)
BiFPN
上面讲的特征金字塔大家应该知道这是个什么玩意,我这里从代码的角度讲一下。
def _forward_fast_attention(self, inputs):
if self.first_time: # 如果初始输入图像resize为512 那么现在的hw为16
p3, p4, p5 = inputs # p5 (bs, 320, 16, 16) EiffcientNet最后一层输出的特征图数量是320
# 16 -> 8 -> 4 每下采样一次hw减半 如果你的num_channels是64的话 输出64个特征图
p6_in = self.p5_to_p6(p5) # (16, 64, 8, 8)
p7_in = self.p6_to_p7(p6_in) # (16, 64, 4, 4)
# 为了后面的融合 特征图的数量需要统一 都进行一次1*1的卷积
p3_in = self.p3_down_channel(p3) # 40 -> 64
p4_in = self.p4_down_channel(p4) # 112 -> 64
p5_in = self.p5_down_channel(p5) # 320 -> 64
else: # 如果不是第一次 直接拿过来用 因为这时候的特征图数量和大小已规范好了
# P3_0, P4_0, P5_0, P6_0 and P7_0
p3_in, p4_in, p5_in, p6_in, p7_in = inputs
# P7_0 to P7_2
# Weights for P6_0 and P7_0 to P6_1
p6_w1 = self.p6_w1_relu(self.p6_w1) # 计算每块特征图的权重 这里是p6和p7的
weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)
# Connections for P6_0 and P7_0 to P6_1 respectively p7需要进行一个上采样才能跟p6的wh一致 然后再进行加权求和
p6_up = self.conv6_up(self.swish(weight[0] * p6_in + weight[1] * self.p6_upsample(p7_in)))
# Weights for P5_0 and P6_1 to P5_1
p5_w1 = self.p5_w1_relu(self.p5_w1)
weight = p5_w1 / (torch.sum(p5_w1, dim=0) + self.epsilon)
# Connections for P5_0 and P6_1 to P5_1 respectively
p5_up = self.conv5_up(self.swish(weight[0] * p5_in + weight[1] * self.p5_upsample(p6_up)))
# Weights for P4_0 and P5_1 to P4_1
p4_w1 = self.p4_w1_relu(self.p4_w1)
weight = p4_w1 / (torch.sum(p4_w1, dim=0) + self.epsilon)
# Connections for P4_0 and P5_1 to P4_1 respectively
p4_up = self.conv4_up(self.swish(weight[0] * p4_in + weight[1] * self.p4_upsample(p5_up)))
# Weights for P3_0 and P4_1 to P3_2
p3_w1 = self.p3_w1_relu(self.p3_w1)
weight = p3_w1 / (torch.sum(p3_w1, dim=0) + self.epsilon)
# Connections for P3_0 and P4_1 to P3_2 respectively
p3_out = self.conv3_up(self.swish(weight[0] * p3_in + weight[1] * self.p3_upsample(p4_up)))
if self.first_time:
p4_in = self.p4_down_channel_2(p4)
p5_in = self.p5_down_channel_2(p5)
# Weights for P4_0, P4_1 and P3_2 to P4_2
p4_w2 = self.p4_w2_relu(self.p4_w2)
weight = p4_w2 / (torch.sum(p4_w2, dim=0) + self.epsilon)
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
p4_out = self.conv4_down( # 这里需要对p3_out进行下采样操作才能跟p4的wh一致
self.swish(weight[0] * p4_in + weight[1] * p4_up + weight[2] * self.p4_downsample(p3_out)))
# Weights for P5_0, P5_1 and P4_2 to P5_2
p5_w2 = self.p5_w2_relu(self.p5_w2)
weight = p5_w2 / (torch.sum(p5_w2, dim=0) + self.epsilon)
# Connections for P5_0, P5_1 and P4_2 to P5_2 respectively
p5_out = self.conv5_down(
self.swish(weight[0] * p5_in + weight[1] * p5_up + weight[2] * self.p5_downsample(p4_out)))
# Weights for P6_0, P6_1 and P5_2 to P6_2
p6_w2 = self.p6_w2_relu(self.p6_w2)
weight = p6_w2 / (torch.sum(p6_w2, dim=0) + self.epsilon)
# Connections for P6_0, P6_1 and P5_2 to P6_2 respectively
p6_out = self.conv6_down(
self.swish(weight[0] * p6_in + weight[1] * p6_up + weight[2] * self.p6_downsample(p5_out)))
# Weights for P7_0 and P6_2 to P7_2
p7_w2 = self.p7_w2_relu(self.p7_w2)
weight = p7_w2 / (torch.sum(p7_w2, dim=0) + self.epsilon)
# Connections for P7_0 and P6_2 to P7_2
p7_out = self.conv7_down(self.swish(weight[0] * p7_in + weight[1] * self.p7_downsample(p6_out)))
return p3_out, p4_out, p5_out, p6_out, p7_out
代码不知道怎么将,我画图给大家讲一下。
经过EfficientNet输出后有了p3,p4和p5。这时候p6和p7还没生出来,所以在第一次运行的时候,需要P5通过一个卷积和Maxpool得到p6,接着是p7。
从图中可以看到p6_up是通过p7_in和p6_in得到的,但是它两尺度又不一样大怎么办。先对p7_in进行一个上采样不就跟p6_in对齐了嘛,然后再融合,再来个激活、卷积得到p6_up。下面的以此类推都是这样。
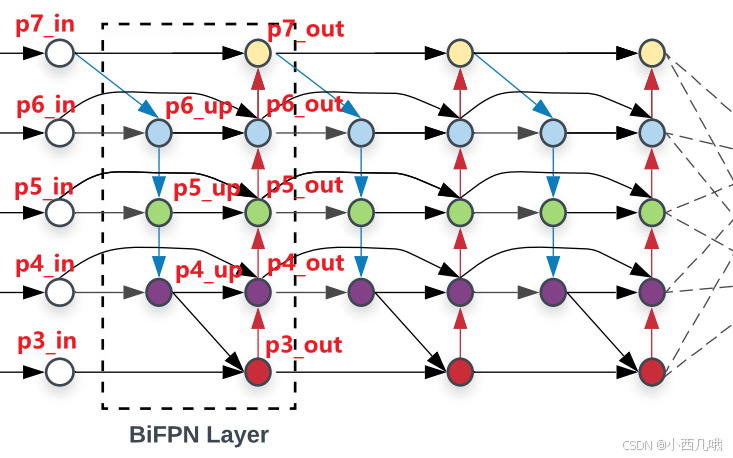
不过这里还有一个点,它们不是简单的直接融合,还有一个加权操作。比如p4_out,是从p4_in,p4_up和p3_out融合而来,但是我不知道它们哪个更重要一点啊,所以还有一个权重计算,加权到每个特征上再进行融合。p4_out = w1×p4_in+w2×p4_up+w3×p3_out。
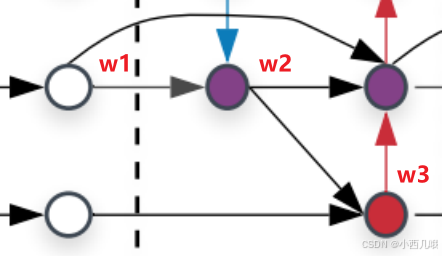
所有步骤完成之后,下一轮运行会将原来的out变为in,再进行几次计算。
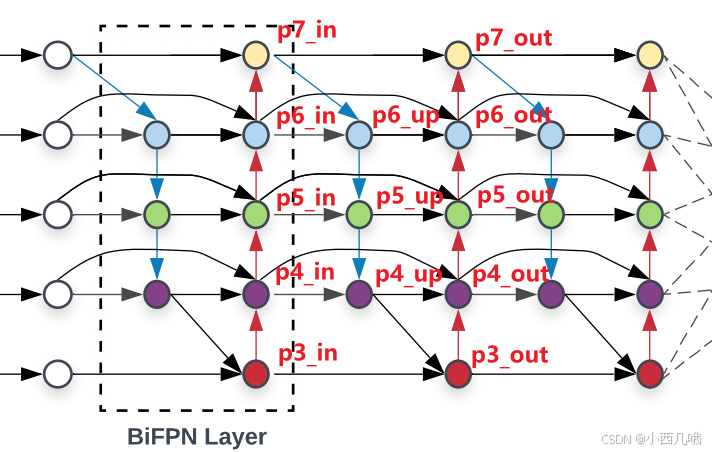
BIFPN的改进
-
之前的融合只引入了两条线,这里引入了三条线
-
之前特征融合没有加入权重机制,这里加入了权重机制
-
之前没有重复多次,这里重复了多次
检查头
两个检查头,分类和锚框
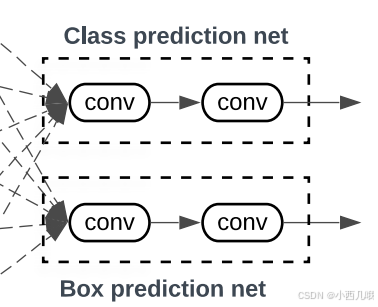
检查头就没啥好讲的了,就是对最后的输出连几个卷积得到结果。
def forward(self, inputs):
feats = []
for feat, bn_list in zip(inputs, self.bn_list): # inputs包含BiFPN后的五层特征数据
for i, bn, conv in zip(range(self.num_layers), bn_list, self.conv_list):
feat = conv(feat) # 就是进行深度可分离卷积后再进行一些1*1的卷积
feat = bn(feat)
feat = self.swish(feat)
feat = self.header(feat)
feat = feat.permute(0, 2, 3, 1)
feat = feat.contiguous().view(feat.shape[0], -1, 4)
feats.append(feat)
feats = torch.cat(feats, dim=1)
return feats
这个代码是分类检查头,它跟锚框检查头不同的就是它输出数是锚框数量×分类数,锚框的检查头输出的是锚框数量×4(dy, dx, dh, dw),这四个就是预测的锚框位置的偏移量。
模型讲完,损失计算就不说了,比较简单,用了Focal Loss计算分类损失和交叉熵计算锚框的回归损失。
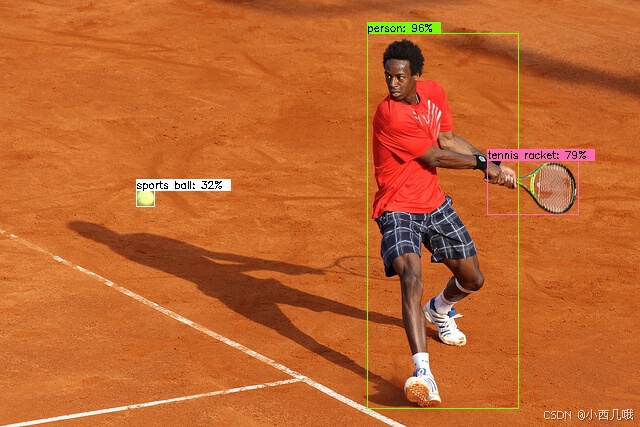
最后让我们看一下效果
我用的别人训练好的模型跑的,我自己条件有限跑不动(跑了几个小时效果跟没有的一样,给我整破防了)用的d0版本,效果不错。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









