







 本文介绍了科研及信息检索领域中常见的评价指标,包括准确率、召回率、F-值、平均精度(mAP)等,并解释了这些指标的意义及应用场景。
本文介绍了科研及信息检索领域中常见的评价指标,包括准确率、召回率、F-值、平均精度(mAP)等,并解释了这些指标的意义及应用场景。
初入科研坑,基本概念都不懂,为了对一些必要的简单知识增加一下记忆,就整理这篇文章,就当是本字典,以备之后忘记了随时查阅。
参考一些大神们的解释,今天要总结的知识点是对检索结果评判的一些标准,主要包括:准确率(Precision rate)、召回率(Recall rate)、F值、平均精度(mAP)、最近邻(NN)
准确率(Precision rate)、召回率(Recall rate)、F值
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
F值 = 准确率 * 召回率 * 2 / (准确率 + 召回率) (F 值即为准确率和召回率的调和平均值)
图表表示为:
准确率是评估检索结果中相关量所占得比例;召回率,顾名思义,就是从关注领域中,召回相关类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。

当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。
平均精度(mAP)
mAP是为解决P,R,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线
可以看出,虽然两个系统的性能曲线有所交叠,但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。
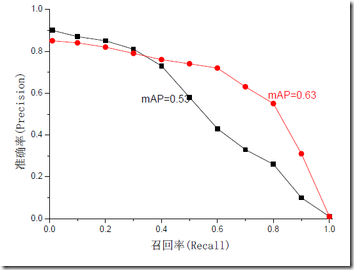
从中我们可以发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。
更加具体的,曲线与坐标轴之间的面积应当越大。
最理想的系统,其包含的面积应当是1,而所有系统的包含的面积都应当大于0。
这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP,它是指P-R曲线与坐标轴构成的面积。
最近邻(NN)
用于测量前一个检索的精度

















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









