







算法入门(python总结)
前言
这次的总结,主要是为了工作中的程序优化进行总结。所有的程序都是按照c语言,改成了python的语言结构(虽然有些麻烦,但是c真的忘完了)。之后的面试算法部分,就复习自己总结的即可。以下开始进行总结~
目录
文章目录
ACM基础算法
1.枚举
思想
-
枚举也称作穷举,指的是从问题所有可能的解的集合中一一枚举各元素。
-
用题目中给定的检验条件判定哪些是无用的,哪些是有用的。能使命题成立。即为其解。
特点
-
优点:算法简单,在局部地方使用枚举法,效果会十分的好
-
缺点:运算量过大,当问题的规模变大的时候,循环的阶数越大,执行速度越慢。计算量容易过大
代码
#比如现在给你一个鸡兔同笼问题,
#你其实可以将所有的情况展示出来
#这里代码有点简单,就不展示了。
2.二分
思想
算法:当数据量很大适宜采用该方法。采用二分法查找时,数据需是排好序的。
基本思想:假设数据是按升序排序的,对于给定值key,从序列的中间位置k开始比较,
当前位置的值如果等于k,就找到了,如果没找到k,
直到找到为止,时间复杂度:O(log(n))
代码
#list是传入的列表(必须是排完序的,排序顺序无所谓),item是你要的结果
def binary_search(list, item):
low = 0
high = len(list)-1
n = 0
while low <= high:
mid = int((low + high)/2)
if list[mid]==item: #相等就找到了
return mid
if list[mid]<item: #否则根据排序结果,拆分找前后的关系
low = mid + 1
else:
high = (mid-1)
3.查并集
思想
查并集是一种树型的数据结构,用于处理不相交集合的合并及查询问题。用于高效的查找某两个元素是否属于同一个集合。
查并集主要分为两种操作:查找和合并。
代码
class DSU:
def __init__(self, nums):
self.root_relation_list = [-1] * (nums+1) # 如果从一开始 初始化父节点列表 需要(nums+1),从0开始则不用
def find_root_node(self, node): # 找父节点
while self.root_relation_list[node] != -1: # 即如果node的父节点不是-1,则继续网上找
node = self.root_relation_list[node] # 更新node
return node
def node_connect(self, node1, node2): # 将两个节点相连
node1_root = self.find_root_node(node1)
node2_root = self.find_root_node(node2)
if node1_root != node2_root:
self.root_relation_list[node1_root] = node2_root
else:
print("connected")
return
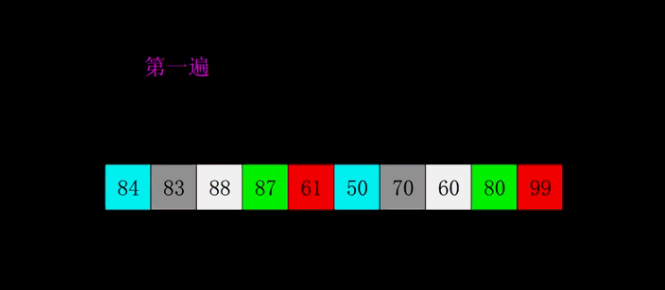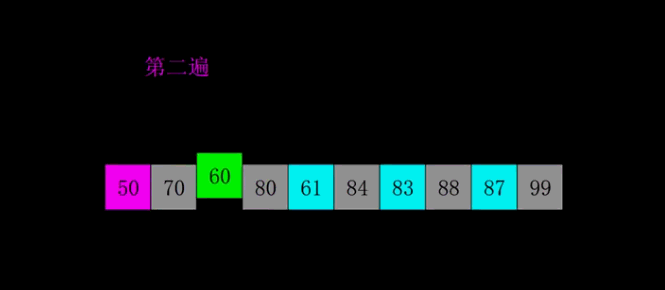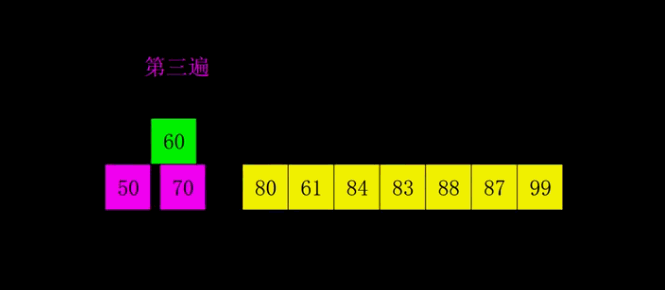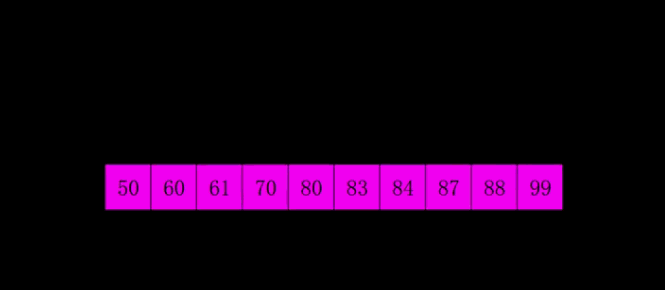
4.DFS深度优先
思想
网络上找的图
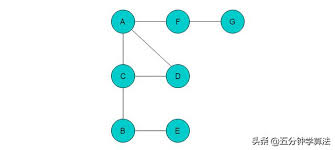
从A点出发,假设第一个点是C点,那么我们就将A和C点标记
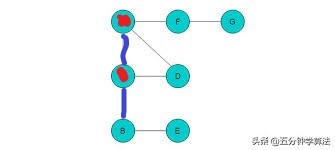
然后开始往B点走,走到B点之后,再标记B点,往E点走
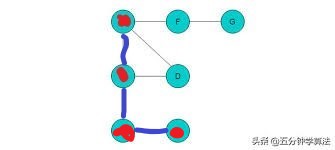
走到E点发现,没有路可以走了,回退到B点,也称之为回溯,看看B点有没有其他未标记的路可以走,如果没有,再回退到C点,此时D点没有被标记,往D点走。
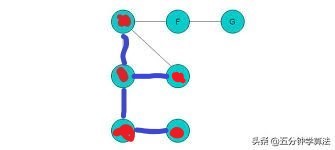
D点走完,发现可以往A点走,但是A点又被标记过了,所以又回退到D点,而D点又没有其他路可以走了,回退到C点,C点又没有路可以走了,回退到A点,往F点走。
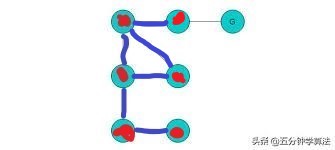
F点走完往G点走,将G点标记后,G点没有其他的路可以走了,回退到F点,F点也没有其他的路可以走了,回退到A点,A点没有其他的路可以走了,整个深度优先搜索也就完成了。
5.BFS
思想
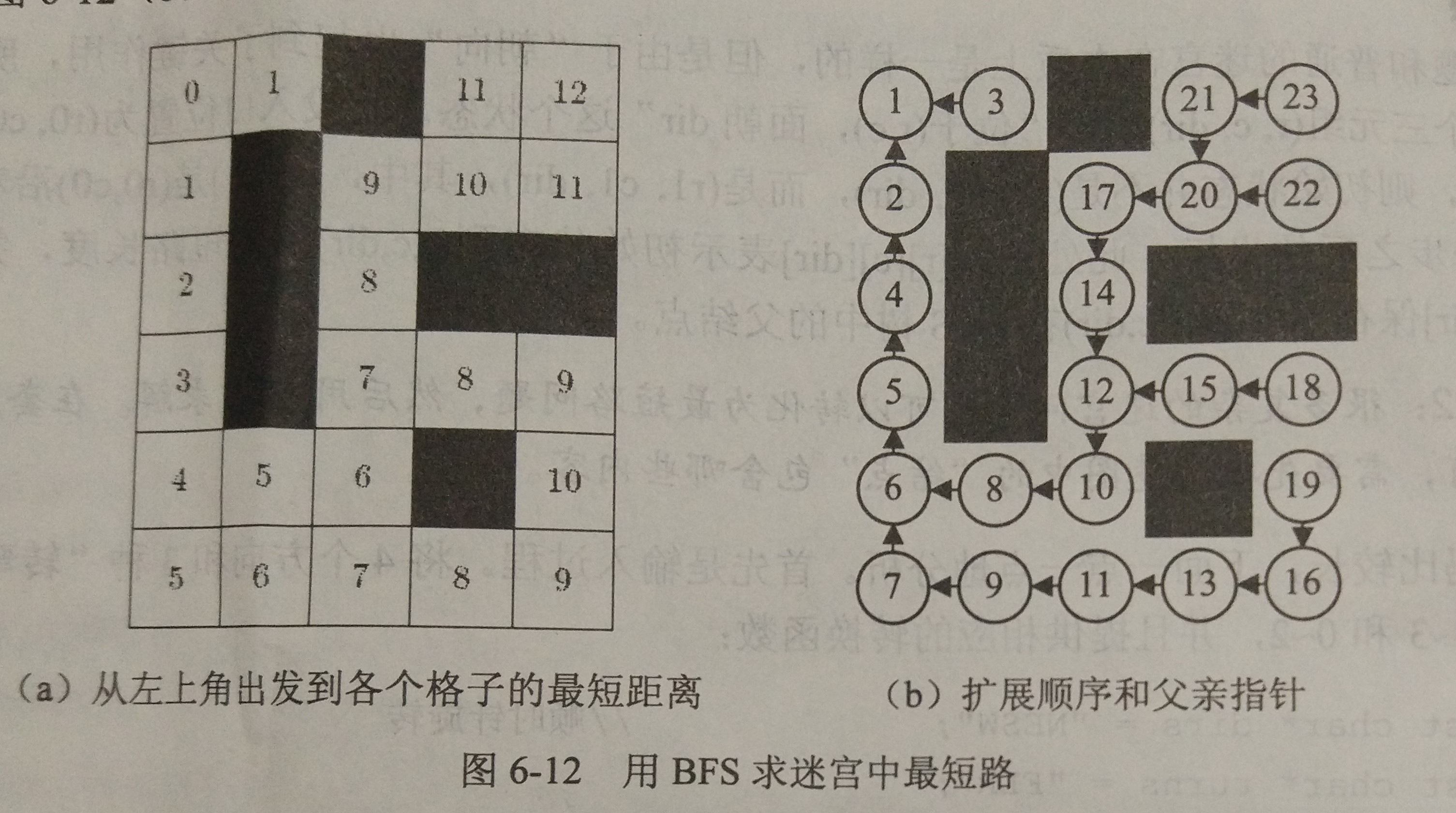
图a就是我们最常见的bfs最短路讲解图(每个小方格里面记录的是左上角起点距当前格子的最短距离);图b则是我们按照bfs的遍历顺序,将每个点标号。此时我们就会发现,这路径是一棵树。倘若还是看不出来,请看下图:

理解了这个之后,就会很好的帮助我们输出bfs的遍历顺序。
6.DP动态规划
思想
朴素递归算法之所以效率很低,是因为它反复求解相同的子问题。因此,动态规划方法仔细安排求解顺序,对每个子问题只求解一次,并将结果保存下来。如果随后再次需要此子问题的解,只需查找保存的结果,而不必重新计算。因此,动态规划方法是付出额外的内存空间来节省计算时间,是典型的时空权衡的例子。而时间上的节省可能是非常巨大的:可能将一个指数时间的解转化为一个多项式时间的解。如果子问题的数量是输入规模的多项式函数,而我们可以在多项式时间内求解出每个子问题,那么动态规划方法的总运行时间就是多项式阶的。
过程

动态规划的核心是定义状态和状态转移方程(注意,关键在于定义方程而非关注递推式的求解方法)
动态规划就是 使用递归的思路 找到正确的算法步骤使得得到正确的解,然后使用迭代的方式写出来。(如此便验证了那句自顶向下的考虑问题,自底向上的解决问题)
例子
爬楼梯问题
一个人爬楼梯,每次只能爬1个或两个台阶,假设有n个台阶,那么这个人有多少种不同的爬楼梯方法
动态规划的状态转移:第 i 个状态的方案数和第 i-1, i-2时候的状态有关,即:dp[i]=dp[i-1]+dp[i-2],dp表示状态矩阵。
def climb_stairs(n):
dp=[0]*n
dp[0]=1
dp[1]=2
for i in range(2,n):
dp[i]=dp[i-1]+dp[i-2]
return dp[n-1]
7.贪心
思想
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择,选择的贪心策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关。
过程
建立数学模型来描述问题; 把求解的问题分成若干个子问题; 对每一子问题求解,得到子问题的局部最优解; 把子问题的解局部最优解合成原来解问题的一个解。
例子
分糖果(leetcode455)
题目:已知一些孩子和一些糖果,每个孩子有需求因子g,每个糖果有大小s,当某个糖果的大小s>=某个孩子的需求因子g时,代表该糖果可以满足该孩子,求使用这些糖果,最多能满足多少孩子(注意,某个孩子最多只能用1个糖果满足)
思考:
当某个孩子可以被多个糖果满足时,是否需要优先用某个糖果满足这个孩子?
当某个糖果可以满足多个孩子时,是否需要优先满足某个孩子?
贪心规律是什么?
贪心规律:
某个糖果如果不能满足某个孩子,则该糖果也一定不能满足需求因子更大的孩子
某个孩子可以用更小的糖果满足,则没必要用更大糖果满足,因为可以保留更大的糖果满足需求因子更大的孩子
孩子的需求因子更小则其更容易被满足,故优先从需求因子小的孩子尝试,可以得到正确的结果(因为我们追求更多的孩子被满足,所以用一个糖果满足需求因子较小或较大的孩子都是一样的)。
算法设计:
(1)对需求因子数组g和糖果大小数组s进行从小到大的排序
(2)按照从小到大的顺序使用各糖果尝试是否可满足某个孩子,每个糖果只尝试1次,只有尝试成功时,换下一个孩子尝试,直到发现没更多的孩子或者没有更多的糖果,循环结束。
class Solution:
def findContentChild(self,g,s):
g = sorted(g)
s = sorted(s)
child = 0
cookie = 0
while child < len(g) and cookie < len(s):
if g[child] <= s[cookie]:
child +=1
cookie+=1
return child
if __name__ =="__main__":
g = [5,10,2,9,15,9]
s = [6,1,20,3,8]
S = Solution()
result = S.findContentChild(g,s)
8.分治
思想
将一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题----“分”
将最后子问题可以简单的直接求解----“治”
将所有子问题的解合并起来就是原问题打得解----“合”
- 该问题的规模缩小到一定的程度就可以容易地解决
绝大多数问题都可以满足的,因为问题的计算复杂性一般是随着问题规模的增加而增加
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
是应用分治法的前提它也是大多数问题可以满足的,此特征反映了递归思想的应用
- 利用该问题分解出的子问题的解可以合并为该问题的解;
如果具备了第一条和第二条特征,而不具备第三条特征,则可以考虑用贪心法或动态规划法。
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
涉及到分治法的效率,如果各子问题是不独立的则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然可用分治法,但一般用动态规划法较好。
面试用的
10大排序算法
1.冒泡排序
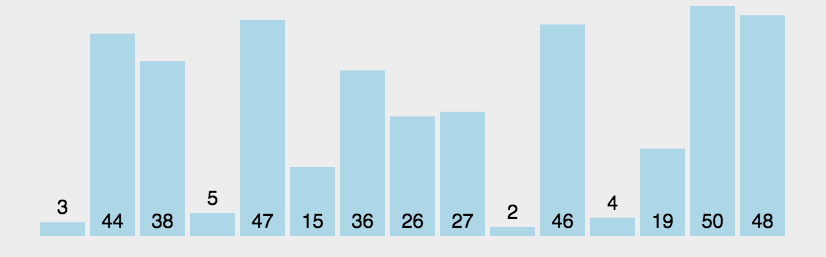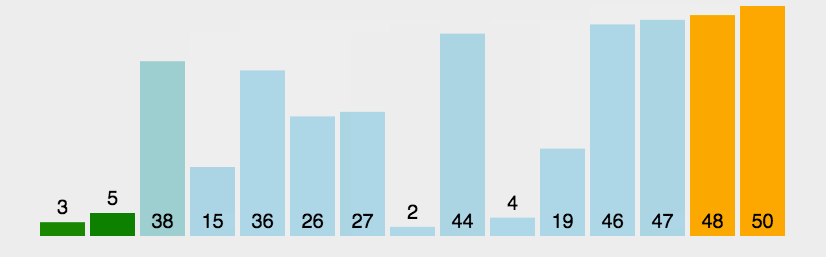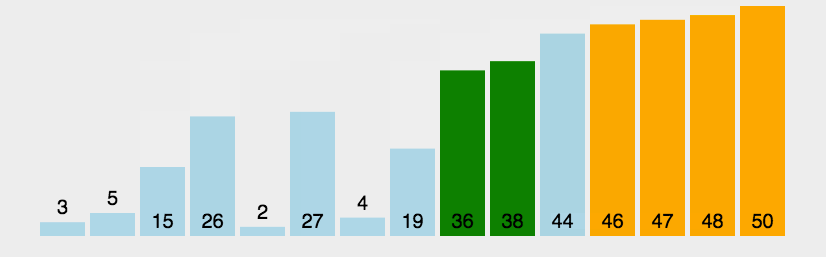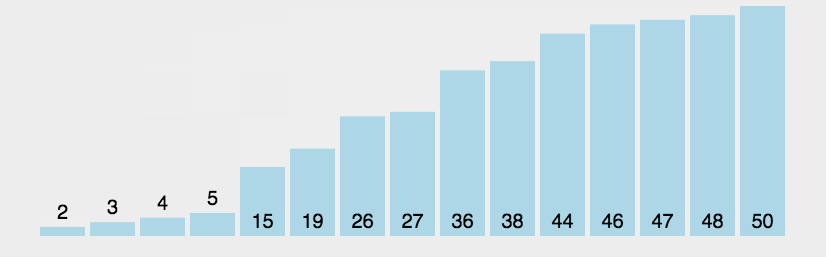
d0 = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44]
d0_out = [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64] # 正确排序
while 1:
state = 0 # 假设本次循环没有改变
for i in range(len(d0) - 1):
if d0[i] > d0[i + 1]:
d0[i], d0[i + 1] = d0[i + 1], d0[i]
state = 1 # 有数值交换,那么状态值置1
if not state: # 如果没有数值交换,那么就跳出
break
print(d0)
print(d0_out)
2.选择排序
def select_sort(data):
d1 = []
while len(data):
min = [0, data[0]]
for i in range(len(data)):
if min[1] > data[i]:
min = [i, data[i]]
del data[min[0]] # 找到剩余部分的最小值,并且从原数组中删除
d1.append(min[1]) # 在新数组中添加
return d1
if __name__ == "__main__":
d0 = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44] # 原始乱序
d0_out = [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64] # 正确排序
d1 = select_sort(d0)
print(d1)
print(d0_out)
3.插入排序
def direct_insertion_sort(d): # 直接插入排序,因为要用到后面的希尔排序,所以转成function
d1 = [d[0]]
for i in d[1:]:
state = 1
for j in range(len(d1) - 1, -1, -1):
if i >= d1[j]:
d1.insert(j + 1, i) # 将元素插入数组
state = 0
break
if state:
d1.insert(0, i)
return d1
if __name__ == "__main__":
d0 = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44] # 原始乱序
d0_out = [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64] # 正确排序
d1 = direct_insertion_sort(d0)
print(d1)
print(d0_out)
4.堆排序

import numpy as np
d0 = [99, 5, 36, 7, 22, 17, 46, 12, 2, 19, 25, 28, 1, 92]
def sort_max(data): # 直接冒泡一下吧,小到大
for i in range(len(data) - 1):
for j in range(len(data) - 1):
if data[j] > data[j + 1]:
data[j], data[j + 1] = data[j + 1], data[j]
return data
def heap_min(data, type):
index = 0
if not type:
for i in range(len(data[1:])):
if data[index] > data[i + 1]:
index = i + 1
data[0], data[index] = data[index], data[0]
return data
else:
for i in range(len(data[1:])):
if data[index] < data[i + 1]:
index = i + 1
data[0], data[index] = data[index], data[0]
return data
def heap_adj(data, type): # data 原始堆,type=1最大堆,type=0最小堆
length = len(data)
floor = int(np.log2(length))
for i in range(floor, 0, -1): # 3(7 6 5 4)-2(3 2)-1(1)
for j in range(2 ** floor - 1, 2 ** (floor - i) - 1, -1):
# print(i,j) # j-1 为当前父节点
d_mid = [data[j - 1]] # j = 7,j-1 =6 index
if j * 2 <= length: # 14
d_mid.append(data[j * 2 - 1])
if j * 2 + 1 <= length:
d_mid.append(data[j * 2])
d_mid = heap_min(d_mid, type)
if len(d_mid) == 2:
data[j - 1], data[j * 2 - 1] = d_mid[0], d_mid[1]
elif len(d_mid) == 3:
data[j - 1], data[j * 2 - 1], data[j * 2] = d_mid[0], d_mid[1], d_mid[2]
return data
if __name__ == '__main__':
d1 = []
for i in range(len(d0)):
data = heap_adj(d0, 0)
d1.append(d0[0])
del d0[0]
print(d1)
5.快速排序
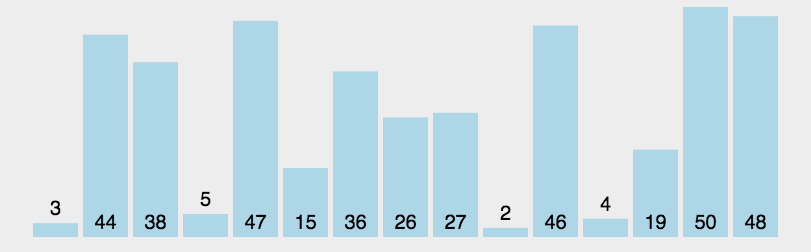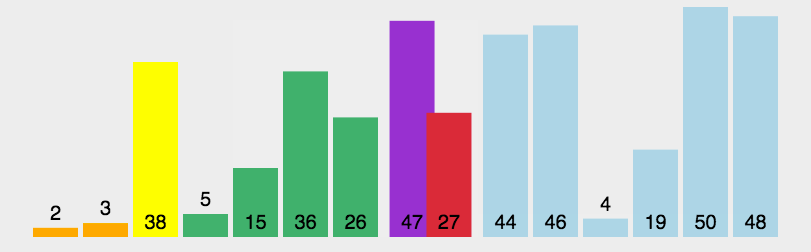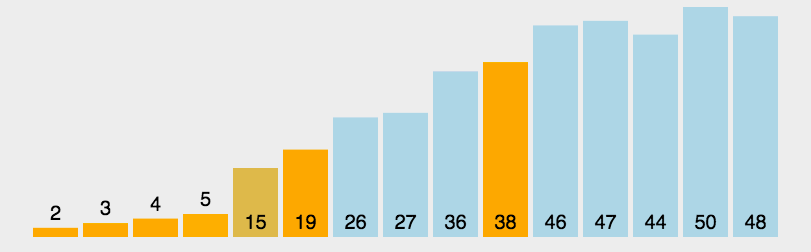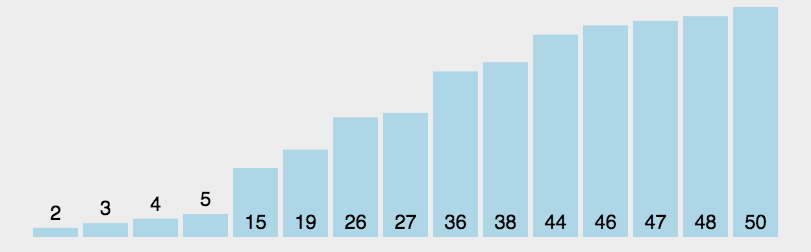
def quick_sort(data):
d = [[], [], []]
d_pivot = data[-1] # 因为是乱序数组,所以第几个都是可以的,理论上是一样的
for i in data:
if i < d_pivot: # 小于基准值的放在前
d[0].append(i)
elif i > d_pivot: # 大于基准值的放在后
d[2].append(i)
else: # 等于基准值的放在中间
d[1].append(i)
# print(d[0], d[1], d[2])
if len(d[0]) > 1: # 大于基准值的子数组,递归
d[0] = quick_sort(d[0])
if len(d[2]) > 1: # 小于基准值的子数组,递归
d[2] = quick_sort(d[2])
d[0].extend(d[1])
d[0].extend(d[2])
return d[0]
if __name__ == "__main__":
d0 = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44] # 原始乱序
d0_out = [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64] # 正确排序
d1 = quick_sort(d0)
print(d1)
print(d0_out)
6.希尔排序
def direct_insertion_sort(d): # 直接插入排序,因为要用到后面的希尔排序,所以转成function
d1 = [d[0]]
for i in d[1:]:
state = 1
for j in range(len(d1) - 1, -1, -1):
if i >= d1[j]:
d1.insert(j + 1, i) # 将元素插入数组
state = 0
break
if state:
d1.insert(0, i)
return d1
def shell_sort(d): # d 为乱序数组,l为初始增量,其中l<len(d),取为len(d)/2比较好操作。最后还是直接省略length输入
length = int(len(d) / 2) # 10
num = int(len(d) / length) # 2
while 1:
for i in range(length):
d_mid = []
for j in range(num):
d_mid.append(d[i + j * length])
d_mid = direct_insertion_sort(d_mid)
for j in range(num):
d[i + j * length] = d_mid[j]
# print(d)
length = int(length / 2)
if length == 0:
return d
break
# print('length:',length)
num = int(len(d) / length)
if __name__ == "__main__":
d0 = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44] # 原始乱序
d0_out = [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64] # 正确排序
d1 = shell_sort(d0)
print(d1)
print(d0_out)
7.归并排序
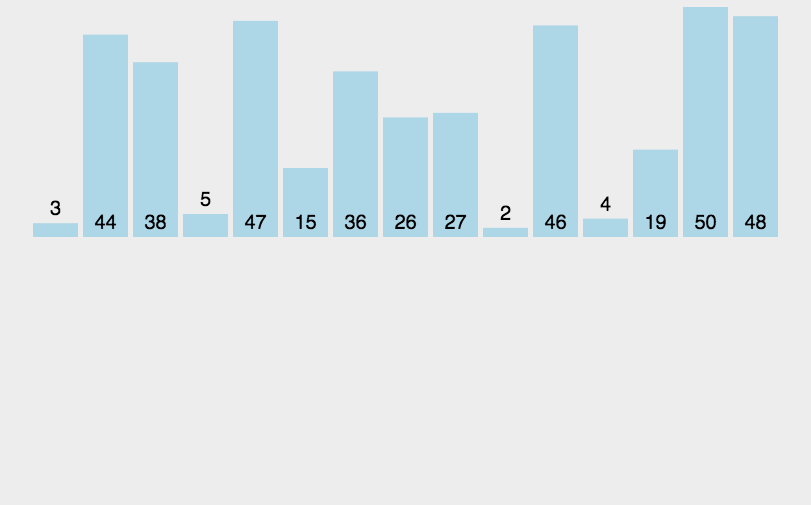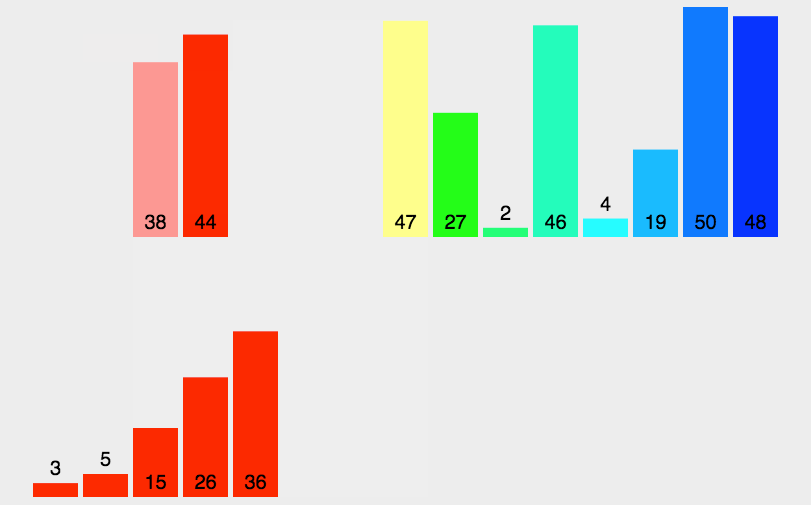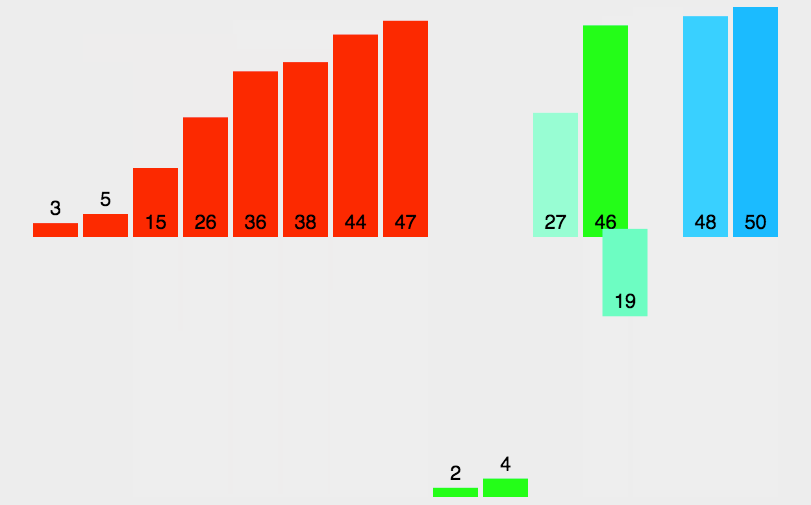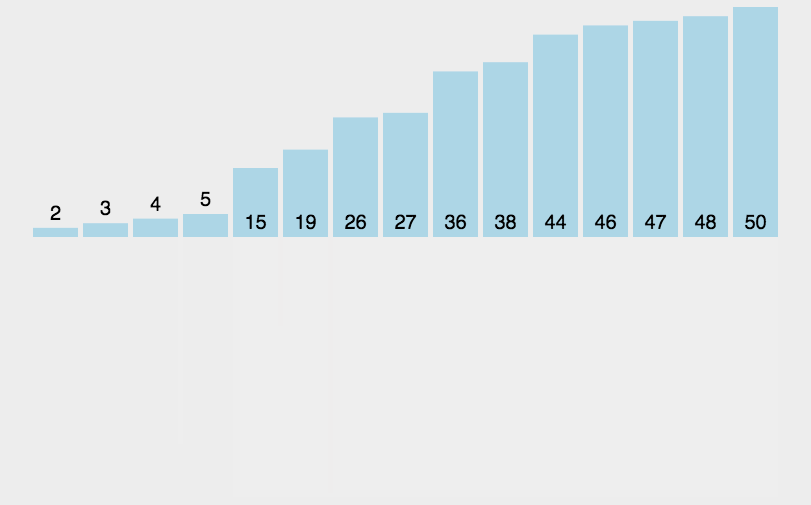
# 归并排序,还有些问题。其中有些细节需要重新理解
# 也是递归问题
def merge_sort(data): # 分治发的典型应用,大问题拆分成小问题,逐个击破,之后将结果合并
half_index = int(len(data) / 2) # 将数组拆分
d0 = data[:half_index]
d1 = data[half_index:]
if len(d0) > 1:
d0 = merge_sort(d0)
if len(d1) > 1:
d1 = merge_sort(d1)
index = 0
for i in range(len(d1)):
state = 1
for j in range(index, len(d0)):
if d1[i] < d0[j]:
state = 0
index = j + 1
d0.insert(j, d1[i])
break
if state == 1: # 如果大于d0这个队列的所有值,那么直接extend所有数据
d0.extend(d1[i:])
break
return d0
if __name__ == "__main__":
d0 = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44] # 原始乱序
d0_out = [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64] # 正确排序
d1 = merge_sort(d0)
print(d1)
print(d0_out)
8.计数排序
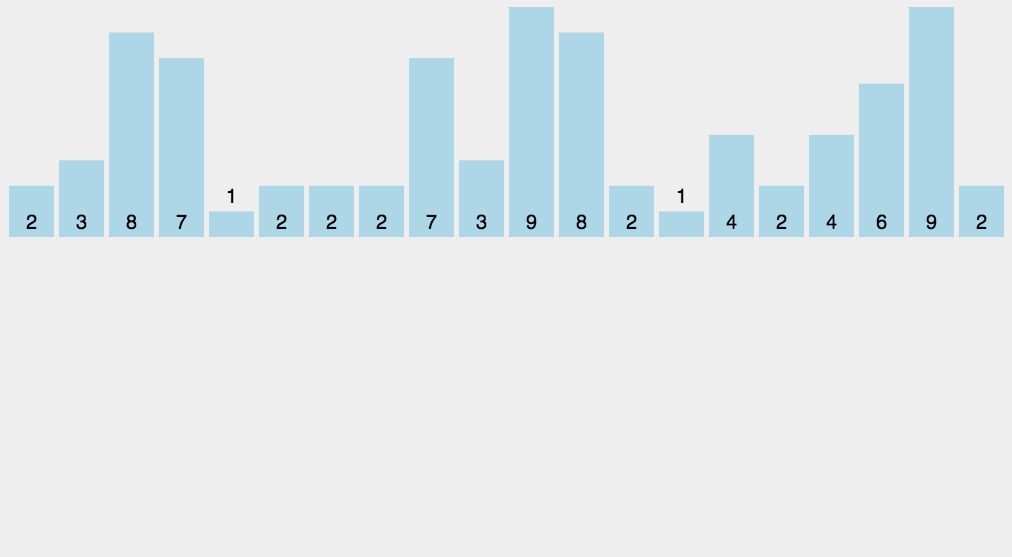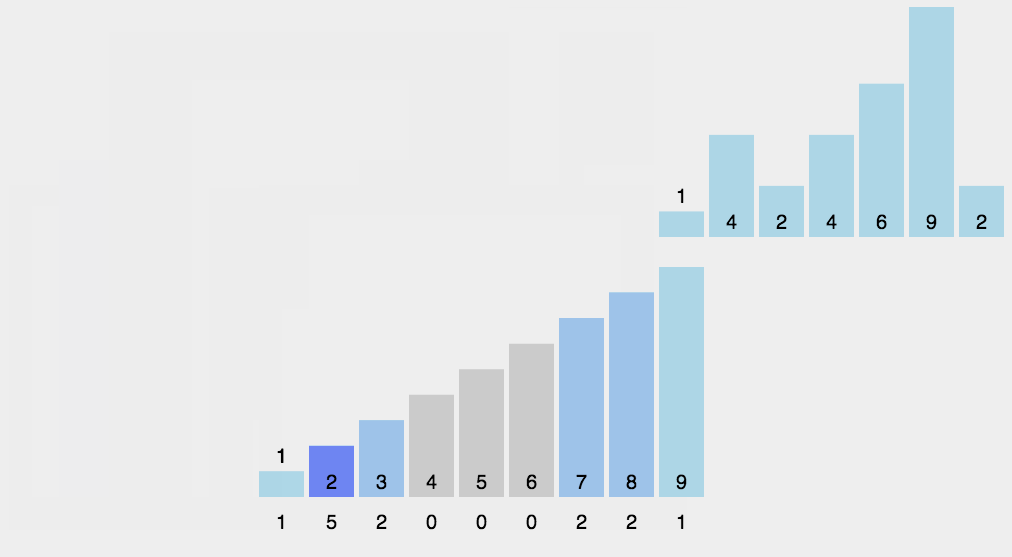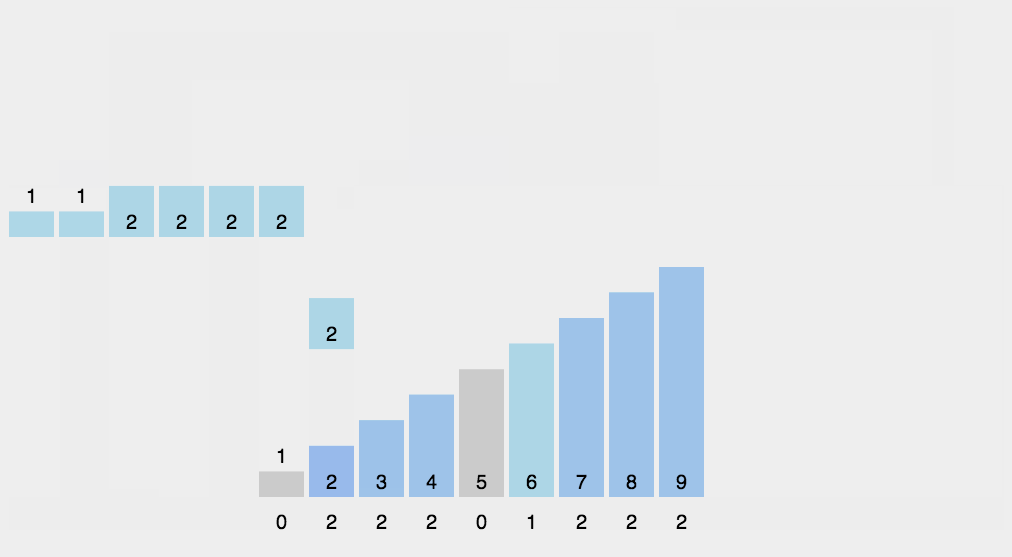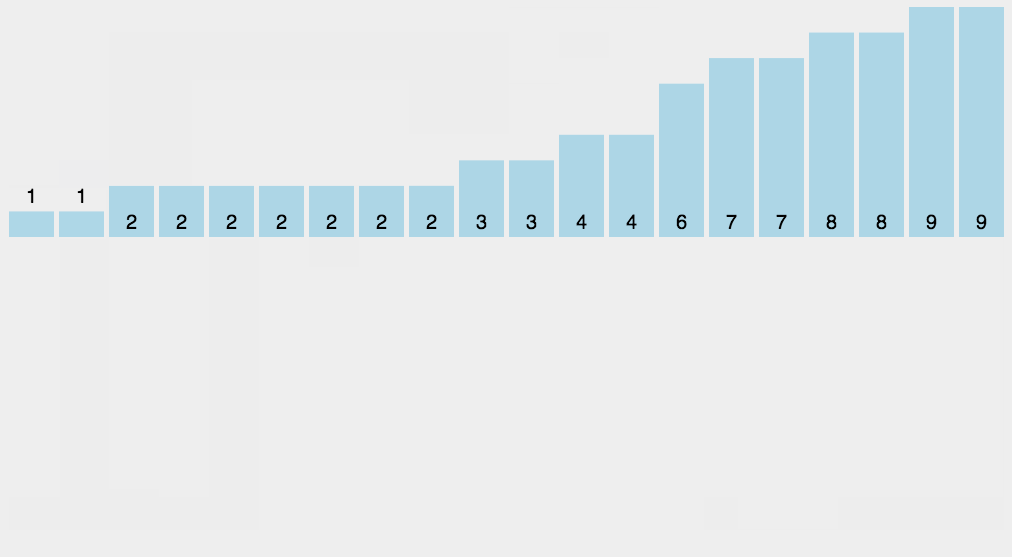
d0 = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44]
d0_out = [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64]
d_max = 0
d_min = 0
for i in d0:
if d_max < i:
d_max = i
if d_min > i:
d_min = i
d1 = {}
for i in d0:
if i in d1.keys():
d1[i] += 1
else:
d1[i] = 1
d2 = []
for i in range(d_min, d_max + 1):
if i in d1.keys():
for j in range(d1[i]):
d2.append(i)
print(d2)
9.桶排序
d0 = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44]
d1 = [[] for x in range(10)]
for i in d0:
d1[int(i / 10)].append(i)
for i in range(len(d1)):
if d1[i] != []:
d2 = [[] for x in range(10)]
for j in d1[i]:
d2[j % 10].append(j)
d1[i] = d2
d3 = []
for i in d1:
if i:
for j in i:
if j:
for k in j:
if k:
d3.append(k)
print(d3)
10.基数排序

1 d0 = [2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 64, 5, 6, 4, 2, 3, 54, 45, 4, 44]
d1 = [[] for x in range(10)]
# 第一次 最小位次排序
for i in d0:
d1[i % 10].append(i)
print(d1)
d0_1 = []
for i in d1:
if i:
for j in i:
d0_1.append(j)
print(d0_1)
# 第二次 次低位排序
d2 = [[] for x in range(10)]
for i in d0_1:
d2[int(i/10)].append(i)
print(d2)
d0_2 = []
for i in d2:
if i:
for j in i:
d0_2.append(j)
print(d0_2)
常见算法
如何翻转一个单链表?
class Solution(object):
def reverseList(self, head):
"""
:type head: ListNode
:rtype: ListNode
"""
# 申请两个节点,pre和 cur,pre指向None
pre = None
cur = head
# 遍历链表,while循环里面的内容其实可以写成一行
# 这里只做演示,就不搞那么骚气的写法了
while cur:
# 记录当前节点的下一个节点
tmp = cur.next
# 然后将当前节点指向pre
cur.next = pre
# pre和cur节点都前进一位
pre = cur
cur = tmp
return pre
斐波那契数列
def fib();
a, b = 0, 1
while true:
yield a
a, b = b, a+b
from itertools import islice
print list(islice(fib(), 5))















 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









