









自用
文章目录
设计高效的数据加载器
数据加载是机器学习系统的一个重要部分。 当数据集较小,我们可以将整个数据集加载到显存中。 但对于较大的数据集,我们智能将示例存在内存中。而当数据集过大而无法装入内存时,数据加载将成为系统性能的关键。 在设计数据加载器时,我们的目标是实现更高效的数据加载,减少数据准备工作,并提供简洁灵活的界面。
设计说明如下:
- IO Design Insight: 设计数据加载的指导原则。
- Data Format: 使用dmlc-core二进制 recordIO。
- Data Loading: 使用dmlc-core提供的线程迭代器来降低IO成本。
- **Interface Design:**编写MXNet数据迭代器只需几行Python代码。
- Future Extension: 数据加载更加灵活,具有可拓展性
以下几个需求应该是一个好的IO系统应满足的。
主要需求:
- 文件体积小。
- 并行的(分布式的)数据打包。
- 快速的数据加载和在线增强。
- 能够快速读取分布式数据集中的任何部分。
Design Insight
数据加载和数据准备是设计IO系统必须要解决的两大任务。数据准备是离线的,且会影响在线的性能。 本节将介绍这两个任务的IO设计。
数据准备
数据准备描述了将数据打包成所需格式以便以后处理的过程。像处理ImageNet这样的大型数据集时,这个过程可能会非常耗时。在这些情况下,我们使用了几种启发式方法:
- 将数据集打包成少量的文件。数据集可能包含数百万个数据实例。而打包好的数据很容易在机器之间分配。
- 仅打包一次。我们不希望在诸如机器数量发生变化等情况下每次运行都需要重新打包。
- 打包过程时并行的。
- 可以轻松访问数据的任意部分,这对于分布式的机器学习系统,尤其是数据并行的情况下是很重要的。当数据被打包到数个物理数据文件中时,事情可能会变得很棘手。所要达到的效果是:无论有多少物理数据文件,打包的数据都可以在逻辑上划分为任意数量的分区。例如,我们将1000张图片打包到4个物理文件,每个文件包含250张图片。假设我们使用10台机器训练,那么每台机器应该能够加载大约100张图片。 一些机器可能需要从不同的物理文件中读取图片。
数据加载
下一步是考虑如何将打包数据加载到内存中。目标是越快越好。以下是我们使用的几种启发式方法:
- 连续读取: 从磁盘的连续位置读取可以读取得更快。
- 减少要加载的字节数: 我们可以通过紧凑的方式(比如使用JPG存储图像)来实现这一点。
- 加载和训练在不同的进程: 这避免了加载数据时的计算瓶颈。
- **内存保存:**智能的决定是否将整个文件加载到内存里。
数据格式
由于深度神经网络训练涉及到大量的数据,因此我们选择的格式应该既高效又方便。因此我们将二进制数据打包成可拆分的格式。在MXNet中,我们依赖于在dmlc-core中实现的二进制recordIO格式。
二进制记录
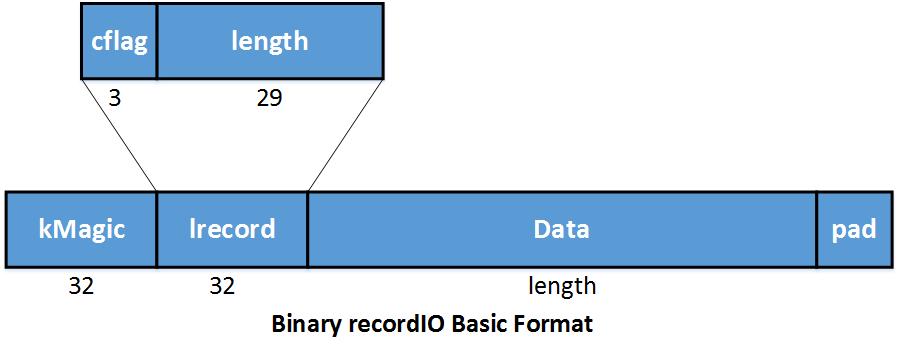 在MXNet二进制RecordIO中,我们将每个数据实例存储为一个记录。kMagic表示记录的开始。 Lrecord 编码长度和连续标志。 In lrecord,
在MXNet二进制RecordIO中,我们将每个数据实例存储为一个记录。kMagic表示记录的开始。 Lrecord 编码长度和连续标志。 In lrecord,
- cflag == 0: 完整的记录。
- cflag == 1: 多段记录的开始
- cflag == 2: 多端记录的中间
- cflag == 3: 多端记录的末尾
Data 保存数据内容的空间。 Pad 使记录对齐4个字节,仅仅使个填充空间。
打包数据之后,每个文件包含多个记录。这样,加载可以是连续的。这样可以避免因读取磁盘上的随机位置而导致的低性能。
One advantage of storing data via records is that each record can vary in length. This allows us to save data compactly when good compression algorithms are available for our data. For example, we can use JPEG format to save image data. The packed data will be much smaller compared with storing uncompressed RGB values for each pixel.
Take ImageNet_1K dataset as an example. If we store the data as 3 * 256 * 256 array of raw RGB values, the dataset would occupy more than 200G. But after compressing the images using JPEG, they only occupy about 35G of disk space. This significantly reduces the cost owing to reading from disk.
Here’s an example of binary recordIO:  We first resize the image into 256 * 256, then compress into JPEG format. After that, we save a header that indicates the index and label for that image to be used when constructing the Data field for that record. We then pack several images together into a file. You may want to also review the example using im2rec.py to create a RecordIO dataset.
We first resize the image into 256 * 256, then compress into JPEG format. After that, we save a header that indicates the index and label for that image to be used when constructing the Data field for that record. We then pack several images together into a file. You may want to also review the example using im2rec.py to create a RecordIO dataset.
Access Arbitrary Parts Of Data
One desirable property for a data loader might be: The packed data can be logically sliced into an arbitrary number of partitions, no matter how many physical packed data files there are. Since binary recordIO can easily locate the start and end of a record using the Magic Number, we can achieve the above goal using the InputSplit functionality provided by dmlc-core.
InputSplit takes the following parameters:
- FileSystem filesys: dmlc-core wrapper around the IO operations for different file systems, like hdfs, s3, local. User shouldn’t need to worry about the difference between file systems anymore.
- Char uri: The URI of files. Note that it could be a list of files because we may pack the data into several physical parts. File URIs are separated by ‘;’.
- Unsigned nsplit: The number of logical splits. nsplit could be different from the number of physical files.
- Unsigned rank: Which split to load in this process.
The splitting process is demonstrated below:
- Determine the size of each partition.

- Approximately partition the records according to file size. Note that the boundary of each part may be located in the middle of a record.

- Set the beginning of partitions in such a way as to avoid splitting records across partitions.

By conducting the above operations, we now identify the records belong to each part, and the physical datafiles needed by each logical part. InputSplit greatly simplifies data parallelism, where each process only reads part of the data.
Since our partitioning scheme does not depend on the number of physical data files, we can process a huge dataset like ImageNet_22K in parallel fashion as illustrated below. We don’t need to consider distributed loading issue at the preparation time, just select the most efficient physical file number according to the dataset size and computing resources available. 
Data Loading and Preprocessing
When the speed of loading and preprocessing can’t keep up with the speed of training or evaluation, IO can bottleneck the speed of the whole system. In this section, we will introduce a few tricks to achieve greater efficiency when loading and preprocessing data packed in binary recordIO format. When applied to the ImageNet dataset, our approach achieves the IO speed of 3000 images/sec with a normal HDD.
Loading and preprocessing on the fly
When training deep neural networks, we sometimes must load and preprocess the data while simultaneously training for the following reasons:
- When the whole size of the dataset exceeds available RAM size, we can’t load it in advance;
- Sometimes, to make models robust to things like translations, rotations, and small amounts of color shift of noise, we introduce randomness into the training process. In these cases we must re-preprocess the data each time we revisit an example.
In service of efficiency, we also address multi-threading techniques. Taking Imagenet training as an example, after loading a bunch of image records, we can start multiple threads to simultaneously perform image decoding and image augmentation. We depict this process in the following illustration: 
Hide IO Cost Using Threadediter
One way to lower IO cost is to pre-fetch the data for next batch on one thread, while the main thread performs the forward and backward passes for training. To support more complicated training schemes, MXNet provides a more general IO processing pipeline using threadediter provided by dmlc-core. The key of threadediter is to start a stand-alone thread that acts as a data provider, while the main thread acts as a data consumer as illustrated below.
The threadediter maintains a buffer of a certain size and automatically fills the buffer when it’s not full. And after the consumer finishes consuming part of the data in the buffer, threadediter will reuse the space to save the next part of data. 
MXNet IO Python Interface
We make the IO object as an iterator in numpy. By achieving that, the user can easily access the data using a for-loop or calling next() function. Defining a data iterator is very similar to defining a symbolic operator in MXNet.
The following example code demonstrates a Cifar data iterator.
dataiter = mx.io.ImageRecordIter(
# Dataset Parameter, indicating the data file, please check the data is already there
path_imgrec="data/cifar/train.rec",
# Dataset Parameter, indicating the image size after preprocessing
data_shape=(3,28,28),
# Batch Parameter, tells how many images in a batch
batch_size=100,
# Augmentation Parameter, when offers mean_img, each image will subtract the mean value at each pixel
mean_img="data/cifar/cifar10_mean.bin",
# Augmentation Parameter, randomly crop a patch of the data_shape from the original image
rand_crop=True,
# Augmentation Parameter, randomly mirror the image horizontally
rand_mirror=True,
# Augmentation Parameter, randomly shuffle the data
shuffle=False,
# Backend Parameter, preprocessing thread number
preprocess_threads=4,
# Backend Parameter, prefetch buffer size
prefetch_buffer=1)
Generally, to create a data iterator, you need to provide five kinds of parameters:
- Dataset Param: Information needed to access the dataset, e.g. file path, input shape.
- Batch Param: Specifies how to form a batch, e.g. batch size.
- Augmentation Param: Which augmentation operations (e.g. crop, mirror) should be taken on an input image.
- Backend Param: Controls the behavior of the backend threads to hide data loading cost.
- Auxiliary Param: Provides options to help with debugging.
Usually, Dataset Param and Batch Param MUST be given, otherwise the data batch can’t be created. Other parameters can be given as needed. Ideally, we should separate the MX Data IO into modules, some of which might be useful to expose to users, for example:
- Efficient prefetcher: allows the user to write a data loader that reads their customized binary format that automatically gets multi-threaded prefetcher support.
- Data transformer: image random cropping, mirroring, etc. Allows the users to use those tools, or plug in their own customized transformers (maybe they want to add some specific kind of coherent random noise to data, etc.)
Future Extensions
In the future, there are some extensions to our data IO that we might consider adding. Specifically, we might add specialized support for applications including image segmentation, object localization, and speech recognition. More detail will be provided when such applications have been running on MXNet.















 1611
1611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









