







处理方式就是做数字转化
1 概念解读
在 mmm 模型中,一些因子(如数字广告、tv 广告)对销量不是线性增长关系,这意味着,广告的增加只能在一定程度上增加销量,一旦达到饱和点,每增加一单位广告投入对销量的影响就会减少,因此,对这些非线性因子需要进行一些转换,从而将它们包含在线性模型中,数据转换主要用于数字广告、tv 广告、线下广告等主动广告营销因子,包含如下 2 个方面:
广告的滞后效应
指广告效果不会立即体现在销量上,而是分阶段影响消费者行为。例如:
- 数字广告:用户可能在点击后几天才完成购买。
- 电视广告:用户可能在观看后数周仍记得品牌。
Adstock 公式,Adstock 转换通过递归方式计算广告的累积影响:

广告的饱和效应(Sigmoid/S-Curve Transformation)
广告的饱和效应指随着投入增加,边际效果递减,最终趋于平稳。可用 逻辑函数(Logistic Function) 或 双曲正切函数(Tanh) 模拟:
Sigmoid 函数公式

2 滞后效应:Adstock模型
广告的滞后效应指广告对消费者行为的影响不会在投放后立即消失,而是会以逐渐衰减的方式持续多期。
几种滞后或衰减策略:
- 几何衰减:用指数函数表示广告效果的逐步减弱(如θ=0.75时,首期广告的75%效果延续到下一期),避免将广告效果视为即时爆发。
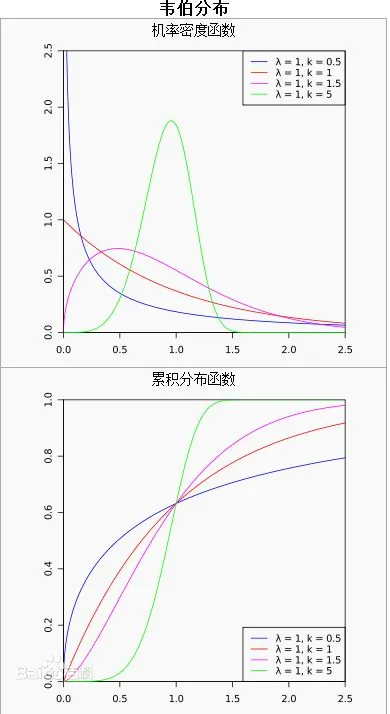
- Weibull衰减:基于生存函数动态调整衰减速率,通过参数(形状、尺度)控制衰减曲线的灵活性,更精准反映不同广告媒介的长期影响差异。
import numpy as np
def adstock_transformation(ad_data, decay_rate=0.6, max_lag=3):
"""
计算广告的滞后效应累积值
:param ad_data: 原始广告投入序列(数组)
:param decay_rate: 保留率(0~1)
:param max_lag: 最大滞后期数(默认3期)
:return: 带滞后效应的广告值序列
"""
adstock = np.zeros_like(ad_data, dtype=float)
for t in range(len(ad_data)):
current_effect = ad_data[t]
# 累加前max_lag期的衰减影响
for lag in range(1, max_lag + 1):
if t - lag >= 0:
current_effect += ad_data[t - lag] * (decay_rate ** lag)
adstock[t] = current_effect
return adstock
# 示例数据:12个月的广告投入(单位:万元)
ad_spend = np.array([50, 60, 80, 100, 70, 90, 120, 110, 85, 75, 60, 50])
# 计算Adstock值(保留率0.6,滞后期3)
adstock_values = adstock_transformation(ad_spend, decay_rate=0.6, max_lag=3)
# 输出结果
print("原始广告投入:", ad_spend)
print("Adstock转换后:", np.round(adstock_values, 1))
可以看一个大概:
原始广告投入: [ 50 60 80 100 70 90 120 110 85 75 60 50]
Adstock转换后: [ 50. 90. 158. 256. 186. 245.8 298. 313. 252.5 223.5 179. 150.6]
其中几个需关注的调节参数:
- 保留率(Retention Rate):通常通过历史数据拟合确定,不同行业差异显著(如快消品可能0.3-0.5,耐用品0.6-0.8)。
- 滞后周期选择:汽车行业可能需3-6个月,互联网广告可能仅1-2周。可通过统计检验(如格兰杰因果)确定最佳滞后期数。
也就是说,如何你有一列原始广告投入的数据,需要经过一轮所谓的adstock_transformation转化,变成新的一列数据在入后续的MMM模型中
3 饱和效应
引入S型曲线函数,将广告投入映射到效果变量时实现阈值响应和渐近饱和:
- 在低投入阶段,效果增长平缓(对应启动期);
- 达到拐点后进入快速响应区(边际收益递增);
- 接近饱和阈值时增速放缓(边际收益递减),最终趋向极值。
常用Hill函数(S曲线)描述:

所以,一个比较完整的数据转化是:
- 先处理投入滞后效应,进行转化
- 再处理饱和效应,进行二次处理
import numpy as np
import pandas as pd
from sklearn.linear_model import RidgeCV
from scipy.stats import weibull_min
# 1. Adstock转换(几何衰减)
def adstock_geometric(x, theta):
x_decayed = np.zeros_like(x)
x_decayed[0] = x[0]
for t in range(1, len(x)):
x_decayed[t] = x[t] + theta * x_decayed[t-1]
return x_decayed
# 2. Saturation转换(Hill函数)
def hill_transform(x, alpha, gamma):
return x**alpha / (x**alpha + gamma**alpha)
# 3. 完整广告效应转换
def adstock_saturation(x, theta, alpha, gamma):
x_adstock = adstock_geometric(x, theta)
x_saturated = hill_transform(x_adstock, alpha, gamma)
return x_saturated
# 4. 模拟数据生成
np.random.seed(42)
time_periods = 52
ad_spend = np.random.uniform(0, 100, time_periods)
true_effect = adstock_saturation(ad_spend, theta=0.7, alpha=2, gamma=50)
sales = 100 + 30 * true_effect + np.random.normal(0, 5, time_periods)
# 5. 构建MMM模型
X = pd.DataFrame({
'ad_effect': true_effect,
# 可添加其他变量(价格、促销等)
})
y = sales
model = RidgeCV(alphas=[0.1, 1, 10], cv=5)
model.fit(X, y)
print(f"广告效应系数: {model.coef_[0]:.2f}")
9 其他
Adstock转换,除了几何衰减、Weibull衰减之外,还有什么衰减方式?给出以上所有衰减方式的分布图
几种分布:
- 1几何衰减:陡峭的指数下降曲线。
- 2.Weibull衰减:根据 值呈现多样化曲线(早期快、后期慢或相反)。
- 3.双曲线衰减:初期快速下降,后期平缓趋近于零。
- 4.阻尼指数衰减:带有振荡波纹的指数衰减曲线。
- 5.阶梯衰减:分段水平线,每段结束后突降。
广告投放支出数据除了需要进行衰减效应、饱和效应的,是否可以跟log混合使用?有什么经济学意义吗?该如何解读?
弹性分析:对数模型(如log-log模型)直接体现广告支出与销售额的弹性关系,即广告支出每增加1%对销售额的影响百分比。

















 2671
2671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









