




 本文详细介绍gensim库的应用,包括模型训练、使用、导出与导入等流程,并通过具体案例演示了word2vec、TF-IDF及LSI等模型的实际操作。此外,还介绍了如何处理大规模文本数据以及词向量的高级应用。
本文详细介绍gensim库的应用,包括模型训练、使用、导出与导入等流程,并通过具体案例演示了word2vec、TF-IDF及LSI等模型的实际操作。此外,还介绍了如何处理大规模文本数据以及词向量的高级应用。
一、gensim介绍
gensim是一款强大的自然语言处理工具,里面包括N多常见模型:
- 基本的语料处理工具
- LSI
- LDA
- HDP
- DTM
- DIM
- TF-IDF
- word2vec、paragraph2vec
.
二、训练模型
1、训练
最简单的训练方式:
# 最简单的开始
import gensim
sentences = [['first', 'sentence'], ['second', 'sentence','is']]
# 模型训练
model = gensim.models.Word2Vec(sentences, min_count=1)
# min_count,频数阈值,大于等于1的保留
# size,神经网络 NN 层单元数,它也对应了训练算法的自由程度
# workers=4,default = 1 worker = no parallelization 只有在机器已安装 Cython 情况下才会起到作用。如没有 Cython,则只能单核运行。
第二种训练方式:
# 第二种训练方式
new_model = gensim.models.Word2Vec(min_count=1) # 先启动一个空模型 an empty model
new_model.build_vocab(sentences) # can be a non-repeatable, 1-pass generator
new_model.train(sentences, total_examples=new_model.corpus_count, epochs=new_model.iter)
# can be a non-repeatable, 1-pass generator
案例:
#encoding=utf-8
from gensim.models import word2vec
sentences=word2vec.Text8Corpus(u'分词后的爽肤水评论.txt')
model=word2vec.Word2Vec(sentences, size=50)
y2=model.similarity(u"好", u"还行")
print(y2)
for i in model.most_similar(u"滋润"):
print i[0],i[1]
txt文件是已经分好词的5W条评论,训练模型只需一句话:
model=word2vec.Word2Vec(sentences,min_count=5,size=50)
第一个参数是训练语料,第二个参数是小于该数的单词会被剔除,默认值为5,
第三个参数是神经网络的隐藏层单元数,默认为100
2、模型使用
# 根据词向量求相似
model.similarity('first','is') # 两个词的相似性距离
model.most_similar(positive=['first', 'second'], negative=['sentence'], topn=1) # 类比的防护四
model.doesnt_match("input is lunch he sentence cat".split()) # 找出不匹配的词语
如何查看模型内部词向量内容:
# 词向量查询
model['first']
.
3、模型导出与导入
最简单的导入与导出
# 模型保存与载入
model.save('/tmp/mymodel')
new_model = gensim.models.Word2Vec.load('/tmp/mymodel')
odel = Word2Vec.load_word2vec_format('/tmp/vectors.txt', binary=False) # 载入 .txt文件
# using gzipped/bz2 input works too, no need to unzip:
model = Word2Vec.load_word2vec_format('/tmp/vectors.bin.gz', binary=True) # 载入 .bin文件
word2vec = gensim.models.word2vec.Word2Vec(sentences(), size=256, window=10, min_count=64, sg=1, hs=1, iter=10, workers=25)
word2vec.save('word2vec_wx')
word2vec.save即可导出文件,这边没有导出为.bin
.
model = gensim.models.Word2Vec.load('xxx/word2vec_wx')
pd.Series(model.most_similar(u'微信',topn = 360000))
gensim.models.Word2Vec.load的办法导入
其中的Numpy,可以用numpy.load:
import numpy
word_2x = numpy.load('xxx/word2vec_wx.wv.syn0.npy')
还有其他的导入方式:
import gensim
word_vectors = gensim.models.KeyedVectors.load_word2vec_format('/tmp/vectors.txt', binary=False) # C text format
word_vectors = gensim.models.KeyedVectors.load_word2vec_format('/tmp/vectors.bin', binary=True) # C binary format
导入txt格式+bin格式。
其他导出方式:
from gensim.models import KeyedVectors
# save
model.save(fname) # 只有这样存才能继续训练!
model.wv.save_word2vec_format(outfile + '.model.bin', binary=True) # C binary format 磁盘空间比上一方法减半
model.wv.save_word2vec_format(outfile + '.model.txt', binary=False) # C text format 磁盘空间大,与方法一样
# load
model = gensim.models.Word2Vec.load(fname)
word_vectors = KeyedVectors.load_word2vec_format('/tmp/vectors.txt', binary=False)
word_vectors = KeyedVectors.load_word2vec_format('/tmp/vectors.bin', binary=True)
# 最省内存的加载方法
model = gensim.models.Word2Vec.load('model path')
word_vectors = model.wv
del model
word_vectors.init_sims(replace=True)
來源:简书,其中:如果你不打算进一步训练模型,调用init_sims将使得模型的存储更加高效
.
4、增量训练
model = gensim.models.Word2Vec.load('/tmp/mymodel')
model.train(more_sentences)
不能对C生成的模型进行再训练.
.
# 增量训练
model = gensim.models.Word2Vec.load(temp_path)
more_sentences = [['Advanced', 'users', 'can', 'load', 'a', 'model', 'and', 'continue', 'training', 'it', 'with', 'more', 'sentences']]
model.build_vocab(more_sentences, update=True)
model.train(more_sentences, total_examples=model.corpus_count, epochs=model.iter)
.
5、bow2vec + TFIDF模型
5.1 Bow2vec
主要内容为:
拆分句子为单词颗粒,记号化;
生成词典;
生成稀疏文档矩阵
documents = ["Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey"]
# 分词并根据词频剔除
# remove common words and tokenize
stoplist = set('for a of the and to in'.split())
texts = [[word for word in document.lower().split() if word not in stoplist]
for document in documents]
生成词语列表:
[['human', 'machine', 'interface', 'lab', 'abc', 'computer', 'applications'],
['survey', 'user', 'opinion', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'management', 'system'],
['system', 'human', 'system', 'engineering', 'testing', 'eps'],
['relation', 'user', 'perceived', 'response', 'time', 'error', 'measurement'],
['generation', 'random', 'binary', 'unordered', 'trees'],
['intersection', 'graph', 'paths', 'trees'],
['graph', 'minors', 'iv', 'widths', 'trees', 'well', 'quasi', 'ordering'],
['graph', 'minors', 'survey']]
生成词典:
# 词典生成
dictionary = corpora.Dictionary(texts)
dictionary.save(os.path.join(TEMP_FOLDER, 'deerwester.dict')) # store the dictionary, for future reference
print(dictionary)
print(dictionary.token2id) # 查看词典中所有词
稀疏文档矩阵的生成:
# 单句bow 生成
new_doc = "Human computer interaction Human"
new_vec = dictionary.doc2bow(new_doc.lower().split())
print(new_vec)
# the word "interaction" does not appear in the dictionary and is ignored
# [(0, 1), (1, 1)] ,词典(dictionary)中第0个词,出现的频数为1(当前句子),
# 第1个词,出现的频数为1
# 多句bow 生成
[dictionary.doc2bow(text) for text in texts] # 当前句子的词ID + 词频
5.2 tfidf
from gensim import corpora, models, similarities
corpus = [[(0, 1.0), (1, 1.0), (2, 1.0)],
[(2, 1.0), (3, 1.0), (4, 1.0), (5, 1.0), (6, 1.0), (8, 1.0)],
[(1, 1.0), (3, 1.0), (4, 1.0), (7, 1.0)],
[(0, 1.0), (4, 2.0), (7, 1.0)],
[(3, 1.0), (5, 1.0), (6, 1.0)],
[(9, 1.0)],
[(9, 1.0), (10, 1.0)],
[(9, 1.0), (10, 1.0), (11, 1.0)],
[(8, 1.0), (10, 1.0), (11, 1.0)]]
tfidf = models.TfidfModel(corpus)
# 词袋模型,实践
vec = [(0, 1), (4, 1),(9, 1)]
print(tfidf[vec])
>>> [(0, 0.695546419520037), (4, 0.5080429008916749), (9, 0.5080429008916749)]
查找vec中,0,4,9号三个词的TFIDF值。同时进行转化,把之前的文档矩阵中的词频变成了TFIDF值。
利用tfidf求相似:
# 求相似
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=12)
vec = [(0, 1), (4, 1),(9, 1)]
sims = index[tfidf[vec]]
print(list(enumerate(sims)))
>>>[(0, 0.40157393), (1, 0.16485332), (2, 0.21189235), (3, 0.70710677), (4, 0.0), (5, 0.5080429), (6, 0.35924056), (7, 0.25810757), (8, 0.0)]
对corpus的9个文档建立文档级别的索引,vec是一个新文档的词语的词袋内容,sim就是该vec向量对corpus中的九个文档的相似性。
索引的导出与载入:
index.save('/tmp/deerwester.index')
index = similarities.MatrixSimilarity.load('/tmp/deerwester.index')
5.3 继续转换
潜在语义索引(LSI) 将Tf-Idf语料转化为一个潜在2-D空间
lsi = models.LsiModel(tfidf[corpus], id2word=dictionary, num_topics=2) # 初始化一个LSI转换
corpus_lsi = lsi[tfidf[corpus]] # 在原始语料库上加上双重包装: bow->tfidf->fold-in-lsi
设置了num_topics=2,
利用models.LsiModel.print_topics()来检查一下这个过程到底产生了什么变化吧:
lsi.print_topics(2)
根据LSI来看,“tree”、“graph”、“minors”都是相关的词语(而且在第一主题的方向上贡献最多),而第二主题实际上与所有的词语都有关系。如我们所料,前五个文档与第二个主题的关联更强,而其他四个文档与第一个主题关联最强:
>>> for doc in corpus_lsi: # both bow->tfidf and tfidf->lsi transformations are actually executed here, on the fly
... print(doc)
[(0, -0.066), (1, 0.520)] # "Human machine interface for lab abc computer applications"
[(0, -0.197), (1, 0.761)] # "A survey of user opinion of computer system response time"
[(0, -0.090), (1, 0.724)] # "The EPS user interface management system"
[(0, -0.076), (1, 0.632)] # "System and human system engineering testing of EPS"
[(0, -0.102), (1, 0.574)] # "Relation of user perceived response time to error measurement"
[(0, -0.703), (1, -0.161)] # "The generation of random binary unordered trees"
[(0, -0.877), (1, -0.168)] # "The intersection graph of paths in trees"
[(0, -0.910), (1, -0.141)] # "Graph minors IV Widths of trees and well quasi ordering"
[(0, -0.617), (1, 0.054)] # "Graph minors A survey"
相关转换
参考:《 Gensim官方教程翻译(三)——主题与转换(Topics and Transformations)》
词频-逆文档频(Term Frequency * Inverse Document Frequency, Tf-Idf)
一个词袋形式(整数值)的训练语料库来实现初始化。
model = tfidfmodel.TfidfModel(bow_corpus, normalize=True)
潜在语义索引(Latent Semantic Indexing,LSI,or sometimes LSA)
将文档从词袋或TfIdf权重空间(更好)转化为一个低维的潜在空间。在真正的语料库上,推荐200-500的目标维度为“金标准”。
>>> model = lsimodel.LsiModel(tfidf_corpus, id2word=dictionary, num_topics=300)
LSI训练的独特之处是我们能在任何继续“训练”,仅需提供更多的训练文本。这是通过对底层模型进行增量更新,这个过程被称为“在线训练”。正因为它的这个特性,输入文档流可以是无限大——我们能在以只读的方式使用计算好的模型的同时,还能在新文档到达时一直“喂食”给LSI“消化”!
>>> model.add_documents(another_tfidf_corpus) # 现在LSI已经使用tfidf_corpus + another_tfidf_corpus进行过训练了
>>> lsi_vec = model[tfidf_vec] # 将新文档转化到LSI空间不会影响该模型
>>> ...
>>> model.add_documents(more_documents) # tfidf_corpus + another_tfidf_corpus + more_documents
>>> lsi_vec = model[tfidf_vec]
随机映射(Random Projections,RP)
目的在于减小空维度。这是一个非常高效(对CPU和内存都很友好)方法,通过抛出一点点随机性,来近似得到两个文档之间的Tfidf距离。推荐目标维度也是成百上千,具体数值要视你的数据集大小而定。
>>> model = rpmodel.RpModel(tfidf_corpus, num_topics=500)
隐含狄利克雷分配(Latent Dirichlet Allocation, LDA)
也是将词袋计数转化为一个低维主题空间的转换。LDA是LSA(也叫多项式PCA)的概率扩展,因此LDA的主题可以被解释为词语的概率分布。这些分布式从训练语料库中自动推断的,就像LSA一样。相应地,文档可以被解释为这些主题的一个(软)混合(又是就像LSA一样)。
>>> model = ldamodel.LdaModel(bow_corpus, id2word=dictionary, num_topics=100)
gensim使用一个基于[2]的快速的在线LDA参数估计实现,修改并使其可以在计算机集群上以分布式模式运行。
分层狄利克雷过程(Hierarchical Dirichlet Process,HDP)
是一个无参数贝叶斯方法(注意:这里没有num_topics参数):
>>> model = hdpmodel.HdpModel(bow_corpus, id2word=dictionary)
gensim使用一种基于[3]的快速在线来实现。该算法是新加入gensim的,并且还是一种粗糙的学术边缘产品——小心使用。
增加新的VSM转化(例如新的权重方案)相当平常;参见API参考或者直接参考我们的源代码以获取信息与帮助。
三、gensim训练好的word2vec使用
1、相似性
持数种单词相似度任务:
相似词+相似系数(model.most_similar)、model.doesnt_match、model.similarity(两两相似)
model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1)
[('queen', 0.50882536)]
model.most_similar(positive=‘woman’, topn=topn, restrict_vocab=restrict_vocab) # 直接给入词
model.most_similar(positive=[vector], topn=topn, restrict_vocab=restrict_vocab) # 直接给入向量
model.doesnt_match("breakfast cereal dinner lunch".split())
'cereal'
model.similarity('woman', 'man')
.73723527
model.n_similarity(['word1','word2'],['word3'])
0.999
其中,n_similarity,就是两个list之间的求相似
.
2、词向量
通过以下方式来得到单词的向量:
model['computer'] # raw NumPy vector of a word
array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
3、 词向量表
model.wv.vocab.keys()
model.wv.index2word
.
案例一:800万微信语料训练
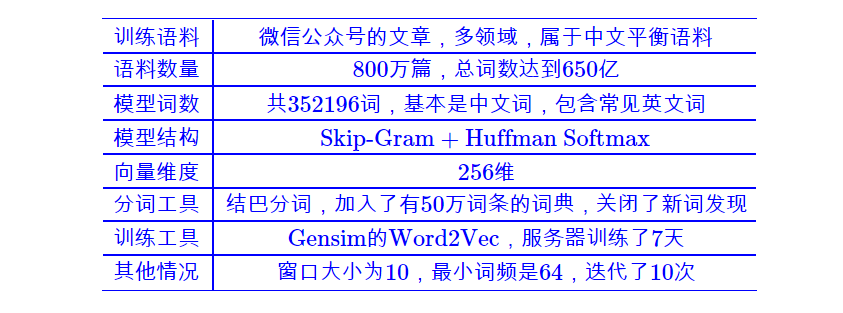
训练过程:
import gensim, logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
import pymongo
import hashlib
db = pymongo.MongoClient('172.16.0.101').weixin.text_articles_words
md5 = lambda s: hashlib.md5(s).hexdigest()
class sentences:
def __iter__(self):
texts_set = set()
for a in db.find(no_cursor_timeout=True):
if md5(a['text'].encode('utf-8')) in texts_set:
continue
else:
texts_set.add(md5(a['text'].encode('utf-8')))
yield a['words']
print u'最终计算了%s篇文章'%len(texts_set)
word2vec = gensim.models.word2vec.Word2Vec(sentences(), size=256, window=10, min_count=64, sg=1, hs=1, iter=10, workers=25)
word2vec.save('word2vec_wx')
这里引入hashlib.md5是为了对文章进行去重(本来1000万篇文章,去重后得到800万),而这个步骤不是必要的。
.
案例二:字向量与词向量的训练
来源github:https://github.com/nlpjoe/daguan-classify-2018/blob/master/src/preprocess/EDA.ipynb
# 训练词向量
def train_w2v_model(type='article', min_freq=5, size=100):
sentences = []
if type == 'char':
corpus = pd.concat((train_df['article'], test_df['article']))
elif type == 'word':
corpus = pd.concat((train_df['word_seg'], test_df['word_seg']))
for e in tqdm(corpus):
sentences.append([i for i in e.strip().split() if i])
print('训练集语料:', len(corpus))
print('总长度: ', len(sentences))
model = Word2Vec(sentences, size=size, window=5, min_count=min_freq)
model.itos = {}
model.stoi = {}
model.embedding = {}
print('保存模型...')
for k in tqdm(model.wv.vocab.keys()):
model.itos[model.wv.vocab[k].index] = k
model.stoi[k] = model.wv.vocab[k].index
model.embedding[model.wv.vocab[k].index] = model.wv[k]
model.save('../../data/word2vec-models/word2vec.{}.{}d.mfreq{}.model'.format(type, size, min_freq))
return model
model = train_w2v_model(type='char', size=100)
model = train_w2v_model(type='word', size=100)
# model.wv.save_word2vec_format('../../data/laozhu-word-300d', binary=False)
# train_df[:3]
print('OK')
参考于:
基于python的gensim word2vec训练词向量
Gensim Word2vec 使用教程
官方教程:http://radimrehurek.com/gensim/models/word2vec.html
报错:
ImportError: DLL load failed: The specified module could not be found.
问题描述:
C extension did not be loaded
gensim需要gcc、g++进行加速,
之前大多给的解决方案是
conda install libpython mingw
但是提示缺乏镜像源,最终找到了合适的镜像源进行添加之后就可以了
解决办法:
https://blog.csdn.net/weixin_39056447/article/details/100770804
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
# 添加镜像源
conda install mingw libpython
# libpython 和 mingw 有先后,但是conda会自动依赖顺序安装


























 到【灌水乐园】发言
到【灌水乐园】发言









