







前言
人脸识别系统基本流程如下:

比如Openface,SeetaFace的系统都是可以学习一下的。强调一下这篇文章主要是讲的是特征提取和分类器分类。
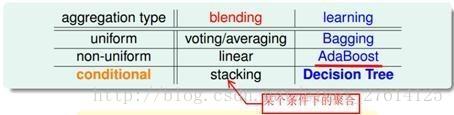
1 模型提升的方法
Nature IDea:boost(提升树的思想)。从这个角度来说明阐述人脸识别的方法。(是不是感觉很神奇)
1.1 DeepID2
Idea:Averaging/voting。思路很简单就是多个模型,然后做个平均就可以。Deepid2很夸张,训练了200个cnn模型。处理方法就是第一次选择最有效的25个模型,然后用PCA的方法降低纬度。然后就是剩下的最有效额25个模型来,然后PCA 的方法来降低纬度。按着这个方法来重复七次。虽然模型是SVM的做最后的特征融合的。所以,在模型完全训练完之后,可以采用muti-scale muti-view的方法来提升模型的准确率。这个方法百试不爽。
1.2 VggFace
Idea:stacking。Dtree(决策树),如果我们决策树的深度增加,那么模型的拟合能力也会提高,当时很容易过拟合现象。这个跟神经网络有些性质类似了,神经网络深度越深,模型的拟合能力就越大,比如vggnet,残差网络等等,如果样本量少,模型的过拟合情况就比较严重。vggface网络上面并没有很多技巧,用了vgg16 cnn 的模型,比Deepid多了11 layers,然后就拿来用在人脸识别的用途上面,效果上也很不错。所以现在用残差网络来训练人脸识别的特征提取部分,性能也不会挺好的(前提是你会调参,样本足够好)。
1.3 小结
从上面两个讨论来说,其实也说明神经网络的发展方向,go deeper。
2 人脸识别(特征提取的网络框架)
好的特征是成功的大半。如果特征选择选择的好,其实分类器差不多的。cnn网络框架的设计,我个人理解是从两个方向来做的。首先是度量上面的设计(也就是说loss),其次是hidden layer的设计。loss设计也会影响到你的前面hidden的设计,有些论文里面这两个方面都是有的。
2.1 度量
softmax(也算吧),siamese loss ,triplet loss,center loss,L-softmax(目前我所了解到的loss 设计)
2.2.1 center loss
Link:https://github.com/ydwen/caffe-face
Paper:《A Discriminative Feature Learning Approach for Deep Face Recognition》
loss:其实本质上前面是个softmax,后面就是一个关于center 的loss。他的最终目的是属于同一类的样本聚拢在某个中心点。

backward computation:
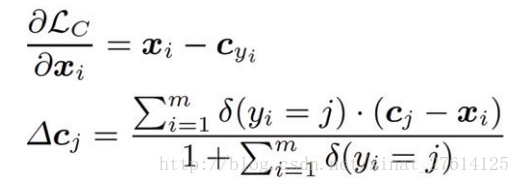
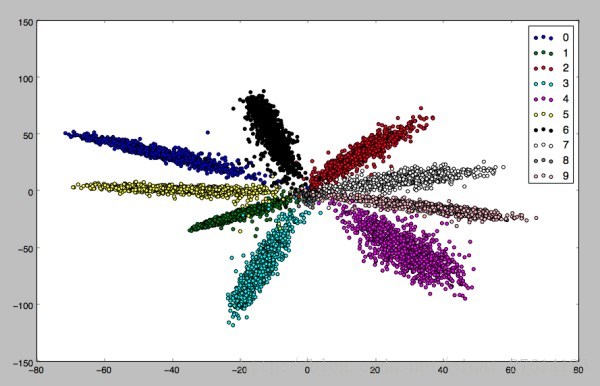
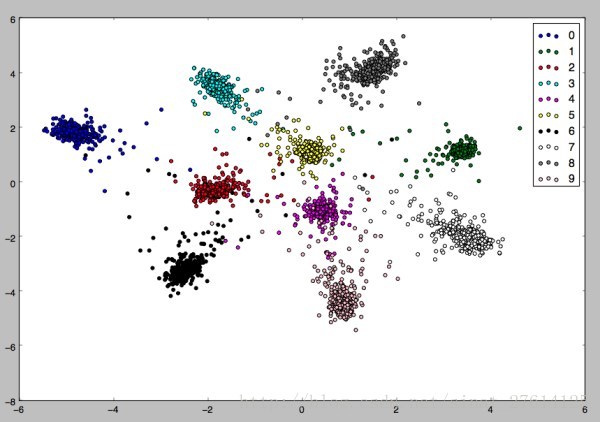
效果图:特征取个二维特征,投影到平面,模型最终效果图如下。
2.2.2 triplet loss:
Link:https://cmusatyalab.github.io/openface/
Paper:《FaceNet: A Unified Embedding for Face Recognition and Clustering》
loss:
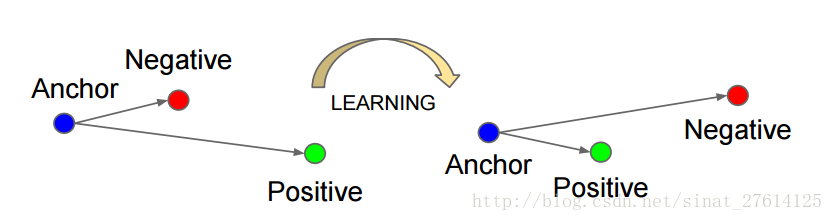
triplet是一个三元组,这个三元组是这样构成的:从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor (记为x_a)属于同一类的样本和不同类的样本,这两个样本对应的称为Positive (记为x_p)和Negative (记为x_n),由此构成一个(Anchor,Positive,Negative)三元组。
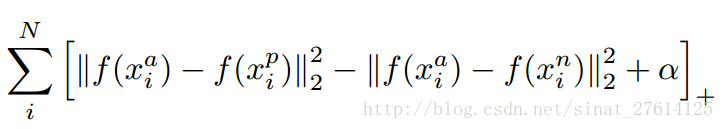
2.2.3 siamese loss
Paper:我个人觉得来源Deepid。
loss:以前模型都是softmax,也就说在反向传播的时候增加一个验证信号。
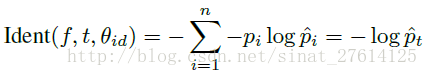
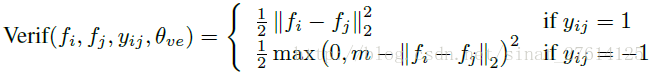
实际上应用的时候,跟Deepid方法不太一样。
小节:前面所有方法的思想就是:同类的样本尽可能接近,不同的样本尽可能距离远。
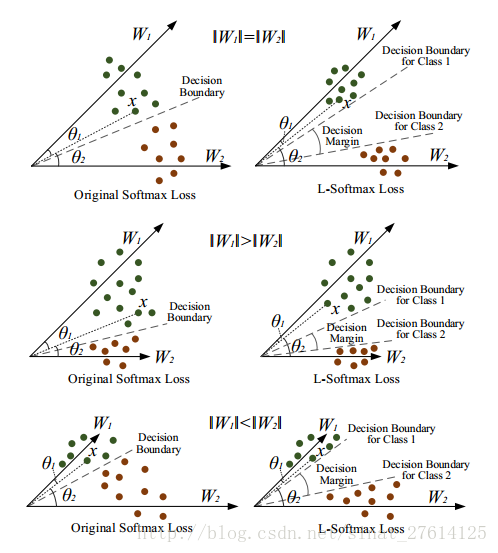
2.2.4 L-softmax loss
Paper:《Large-Margin Softmax Loss for Convolutional Neural Networks》
Loss:(还没看,捂脸)
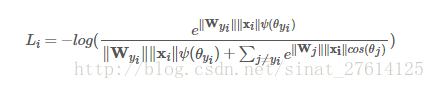
效果图:
3 内部网络结构的设计
3.1 NORMFACE:L2 hypersphere embedding for face Verification
可以看我上面一篇博客。
3.2 LightCNN
感觉没什么东西可以看,作者使用maxout作为激活函数,实现了对噪声的过滤和对有用信号的保留,从而产生更好的特征图MFM(Max-Feature-Map)。同时,这个maxout也就是所谓的slice+eltwise。
BN
http://blog.csdn.net/tangwei2014/article/details/46788025
http://blog.csdn.net/stdcoutzyx/article/details/42091205
http://blog.csdn.net/shaoxiaohu1/article/details/53325945















 5827
5827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









