






之前的方法都是借助参数模型来恢复人体体型的,这样做缺少了很多表面细节,而且对于体型的恢复不如对于姿势的恢复那么准确。这篇文章提出了一个叫做层次变形网格(Hierarchical Mesh Deformation,一下简称HDR)的结构,它将参数模型的鲁棒性与真实三维人体变形的灵活性相结合,利用该结构重新定义一种新的人体体型的恢复方式,它能够恢复除了皮肤模型之外的人体体型,也就是能能很好的恢复人体表面的衣服特征,不再是一个单纯的3D模型。
HDR主要思想是通过一层一层的由粗到细的不断细化参数化模型的结果,如下图所示该框架总共分为四步:第一步首先根据2D图像生成一个初始化的3D SMPL网格模型,在这之后的三步通过预测网格的变形对第一步生成的网格不断进行精细化,以达到对人体体型细化的目的。第一步的初始化SMPL网格通过HMR(论文《End-to-end Recovery of Human Shape and Pose》中所提出的方法)获得,但是这在我上周的周报中也提到过,由于该方法中引入对姿势和体型的鉴别器,对于一些特殊姿势和身材特别的人体恢复效果并不是很好。所以为了减少网格的误差,在第一阶段后又添加三个阶段来对网格进行层层细化。
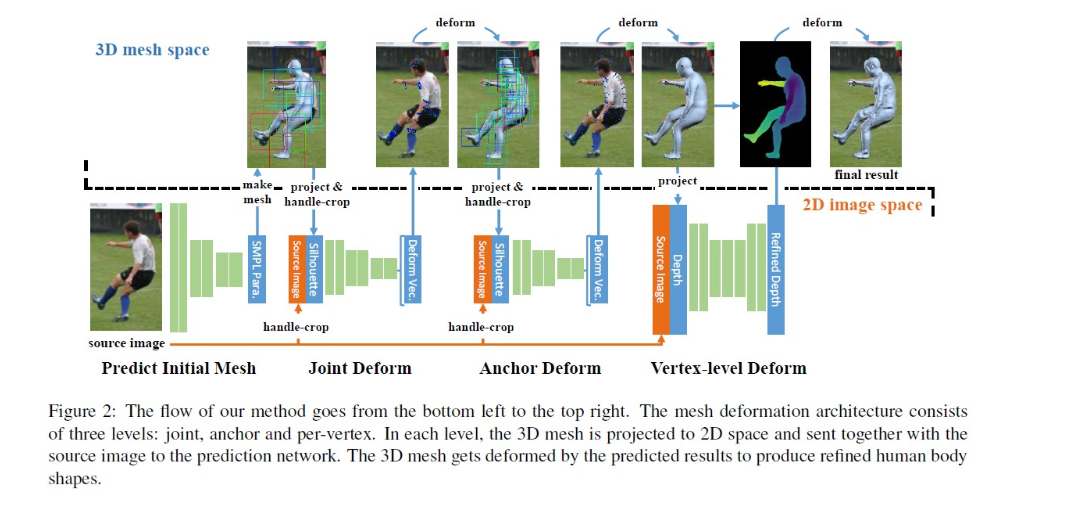
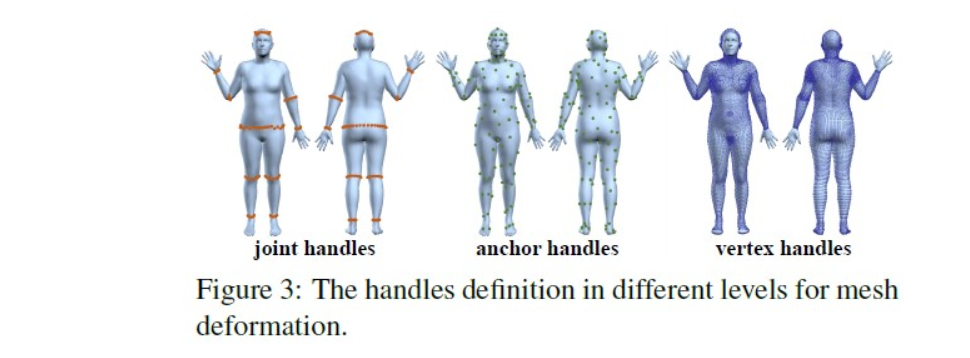
在网格上定义3个关键的点(在本文中称作句柄,handles)以及在每个handle上定义motion vector,分别是:
-
joint handle:选择10个关节点(头部,腰部,左/右肩,左/右肘,左/右膝盖和左/右脚踝)作为控制点 。SMPL网格下的关节周围的顶点被选为joint handle。将每组joint handle的几何中心作为其相应的身体关节的位置。每个关节句柄的运动矢量的方向为从投影网格的关节位置指向到2D图像中真实关节点位置。
-
Anchor handles:从人体网格中选择200个顶点作为anchor handle。为了能够均匀的选择锚点,采用如下方法:
- 首先构建一个向量集C = { v 1 , v 2 , . . . , v n v_1, v_2, ... , v_n v1,v2,...,vn}, 其中 v i v_i vi为顶点 i 在3D网格曲面上对应的法向量,n为SMPL模型对应的顶点总数。
- 使用K-means方法将C分为200个分组。
- 将距离每个分组中心最近的顶点定义为anchor handles。
此外为了避免一些不必要的干扰,移除了在脸部、手指、脚趾部位的顶点。每个锚点只允许其沿着其定义的法向量的方向移动,所以其运动矢量只需要一个值,表示其沿着法线移动。
-
Vertex-level handles:SMPL模型中的顶点太稀疏了,无法用到像素级别的形变中,所以将网格的每个面又细分为4个面,得到27554个顶点,这些顶点就是Vertex-level handles。
在每一层的细化中,借助这些句柄,通过神经网络来优化网格。定义如下三个网络:
-
joint prediction network:首先将原2D图像裁剪为64*64的大小,并要求joint handle居中于图像。将预处理后的图像与前一步得到的3D网格在2D平面上的投影得到的轮廓图作为网络的输入,输出得到joint handler的motion vector。损失函数如下:
L j o i n t = ∣ ∣ p − p ^ ∣ ∣ 2 L_{joint} = ||p - \widehat{p}||_2 Ljoint=∣∣p−p ∣∣2
其中网络预测得到的motion vector, p ^ \widehat{p} p 是3D网格投影到2D的关键点与关键点的ground truth之间的偏移量。 -
anchor prediction network:该网络的目的是使得3D网格的投影轮廓与2D ground truth的轮廓间不匹配的区域面积最小化。在实际操作时,将不匹配区域的面积转换为落入不匹配区域的沿着顶点法线方向的投影线段的长度,以该线段的长度作为ground truth,使用L2范式进行损失计算。
joint 和 anchor的预测网络都使用VGG结构。对于两个网络的输入,除了可以用原本的2D图像之外,还可以用2D图像中人体的轮廓图作为输入,该轮廓为网络提供了更精准的信息,从而避免了背景信息的干扰。
-
vertex-level deformation:这一步的目的是给已经构建好的人体3D网格添加更多的细节:
- 训练一个UNet,以通过将3D网格投影到2D平面获取到的深度图和与其对应的原图作为输入,输出一个有更多细节的深度图,以其深度图的ground truth作为监督。接下来将这个网络输出得到的深度图与其对应的原图输入到Shading-Net(以原始2D图像和上一步得到的深度图作为输入,预测得到一个具有表面细节的深度图)中进行训练。在进行损失计算的时候,不仅用到了UNet中的loss,还有根据最终输出的深度图色彩重建后得到的图像与原图间的误差 ,根据每个像素点的误差进行如下计算:
L p h o t o = ∥ ρ ∑ k = 1 9 l k H k ( n ) − I ∥ 2 L_{p h o t o}=\left\|\rho \sum_{k=1}^{9} l_{k} H_{k}(\boldsymbol{n})-I\right\|_{2} Lphoto=∥∥∥∥∥ρk=1∑9lkHk(n)−I∥∥∥∥∥2
- 其中, ρ \rho ρ是通过传统的内在分解方法计算得到的反射率。同时在Lambertian表面假设的基础下,利用second spherical harmonics(SH)进行光照表示。 H k H_k Hk表示的是SH函数的基础部分, l i l_i li表示的是SH函数的系数,可以通过最小二乘法得到:
l ∗ = arg min l ∥ ρ ∑ k = 1 9 l k H k ( n coarse ) − I ∥ 2 2 l^{*}=\underset{l}{\arg \min }\left\|\rho \sum_{k=1}^{9} l_{k} H_{k}\left(\boldsymbol{n}_{\text {coarse}}\right)-I\right\|_{2}^{2} l∗=largmin∥∥∥∥∥ρk=1∑9lkHk(ncoarse)−I∥∥∥∥∥22
分别训练这三个神经网络,每一个神经网络都以前一阶段的结果作为输入,最后得到预测的带有形变特征的网格。
使用拉普拉斯网格形变(Laplacian mesh deformation)方法来2D空间的句柄使得3D空间的网格朝着具体的方向发生形变。具体的说,训练网络通过2D图像中的关键点和轮廓图来预测每个句柄的运动矢量(motion vector)。根据此运动矢量,人体网格将通过拉普拉斯形变方法进行形变。这是本文的亮点之一:创造性的用神经网络从单张图像预测形变。
结果对比:
现利用提供的已训练好的模型对HMR与HMD进行可视化的对比:


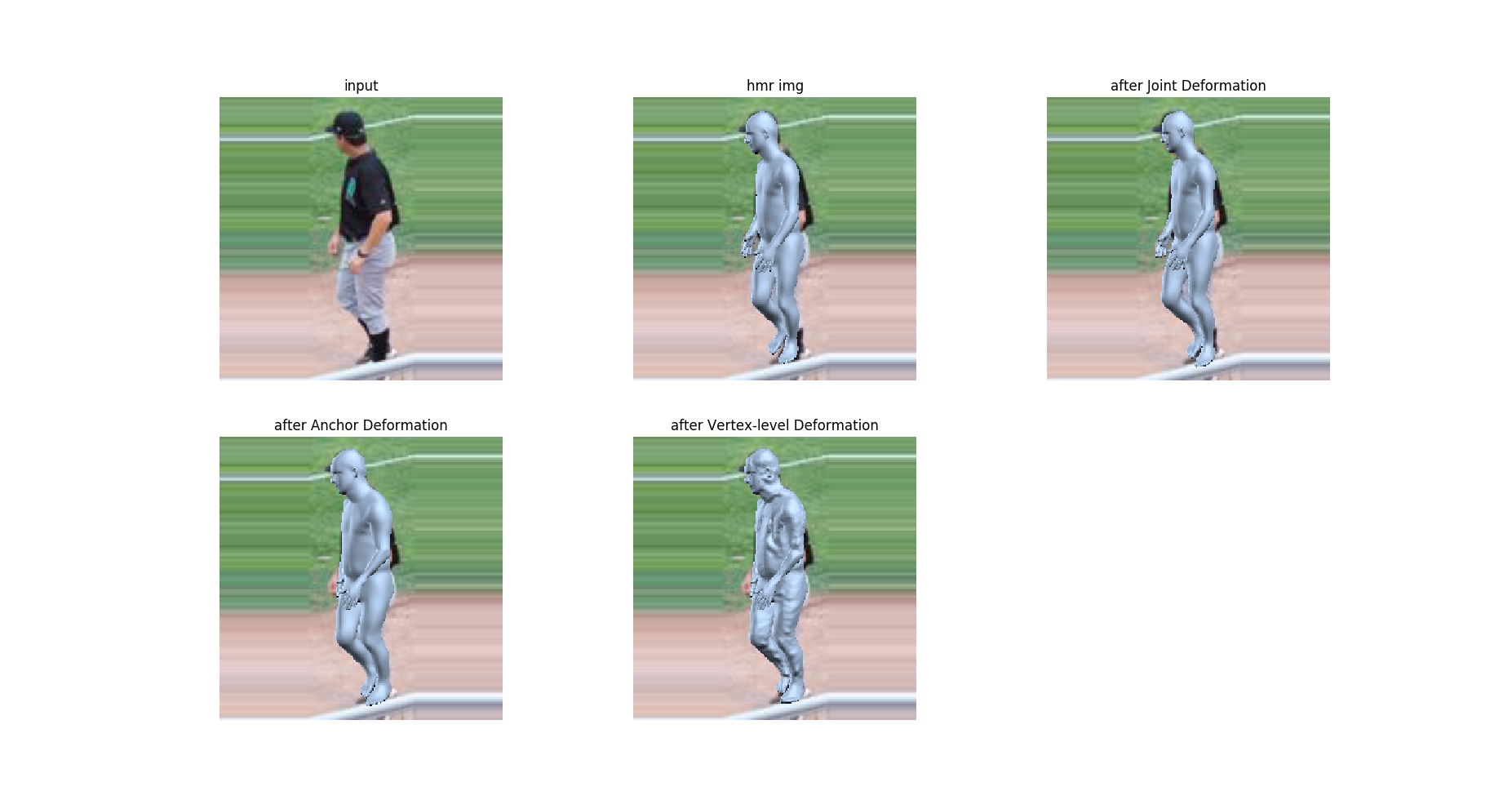
可以看到在HMR的基础上,一层一层的对3D网格进行形变,最后得到的网格相比于HMR网格在体型方面较原图有更好的拟合度,而且生成的衣物细节也使得3D网格更加真实。















 992
992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









