








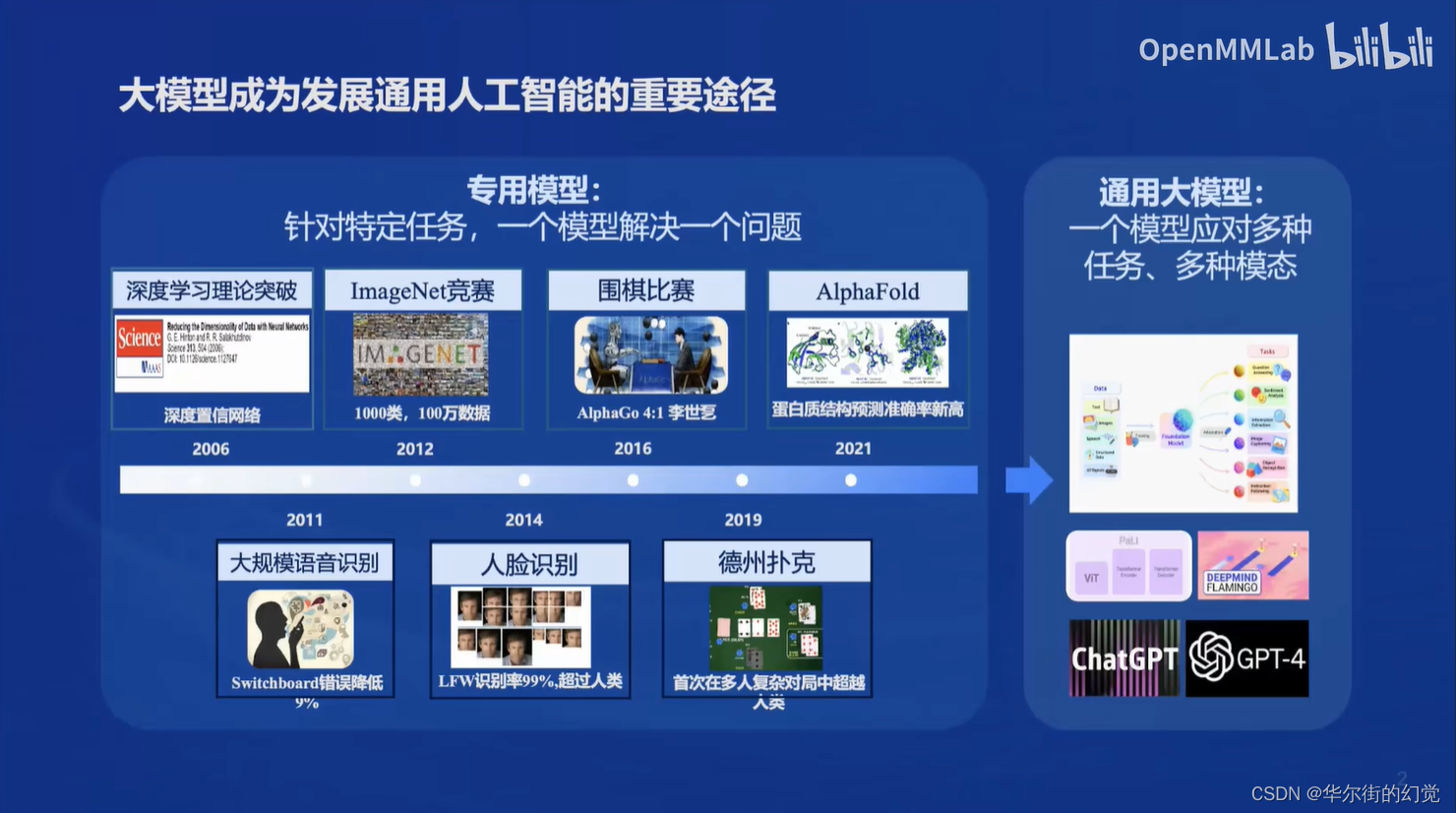
专用模型 到 通用大模型
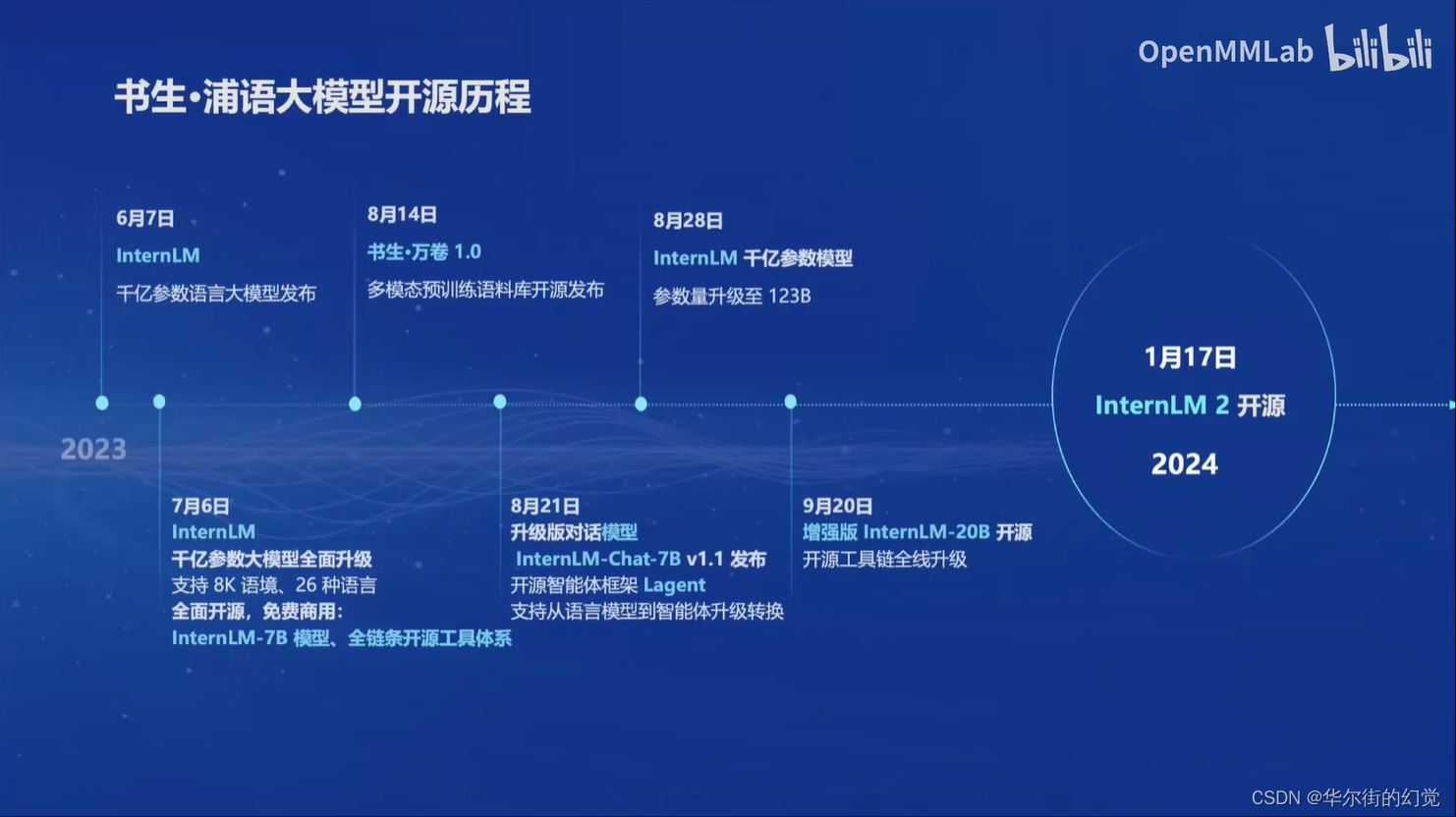
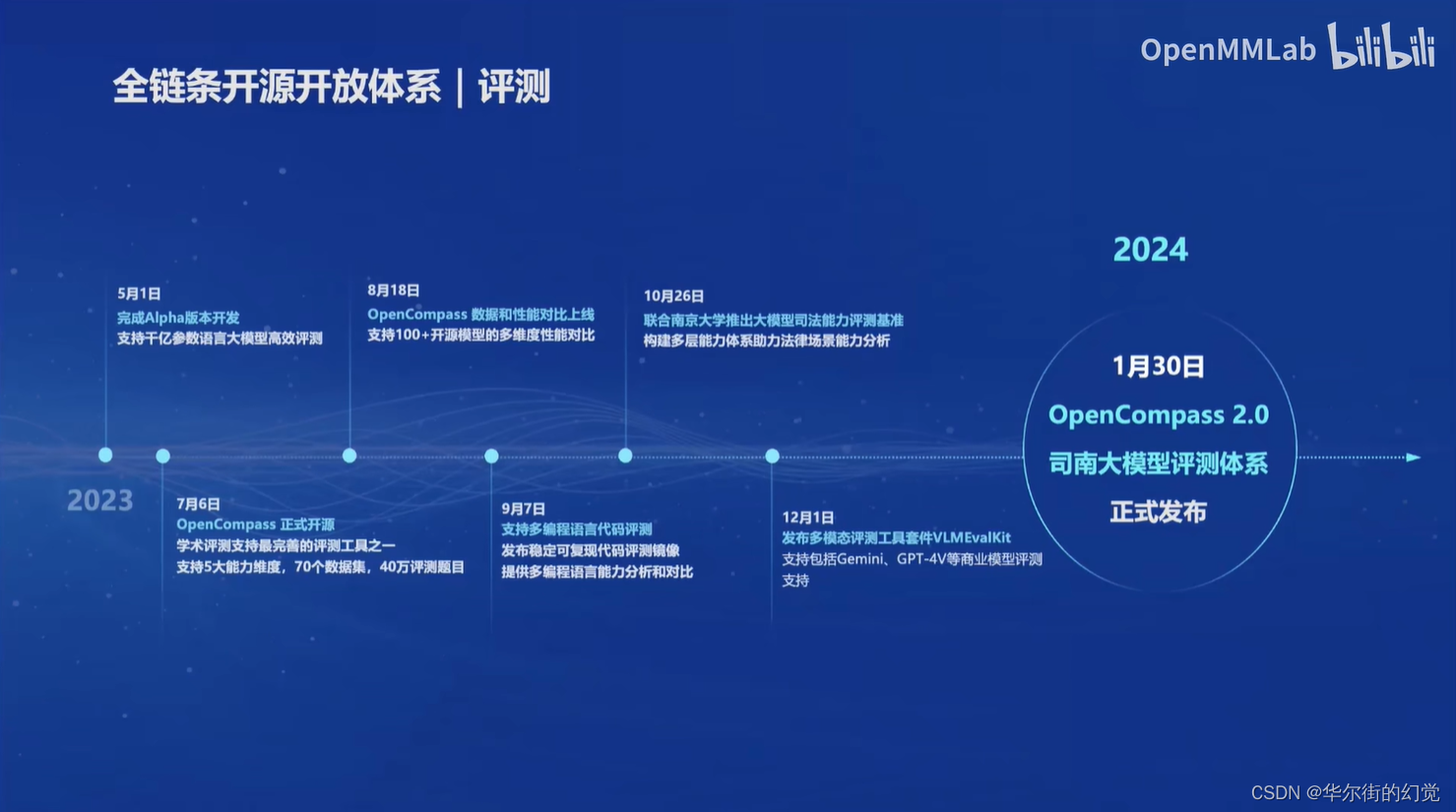
开源历程
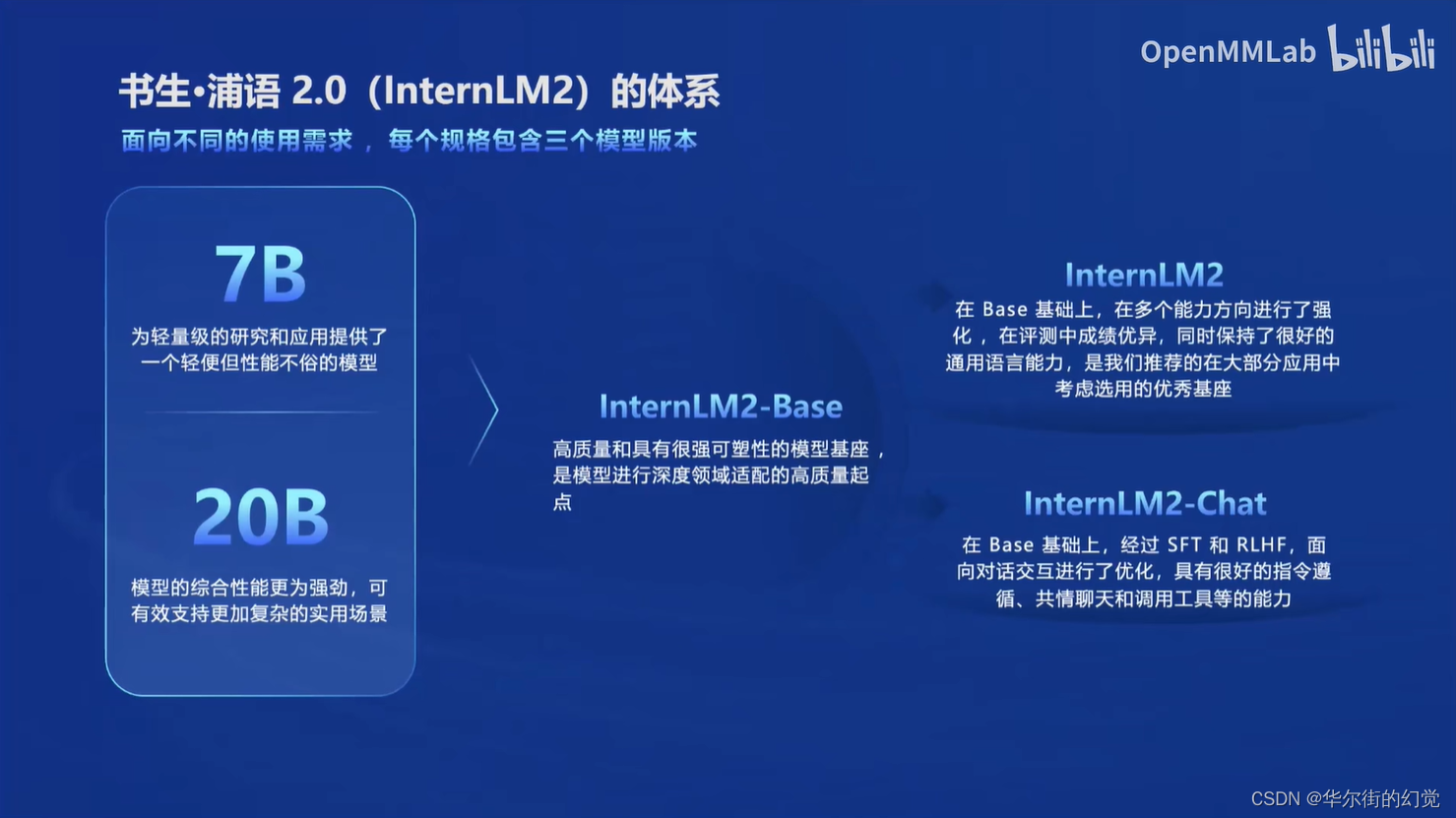
书生浦语2.0体系
InternLM2的主要亮点
- 超长上下文:模型在20万token上下文中,几乎完美实现“大海捞针”
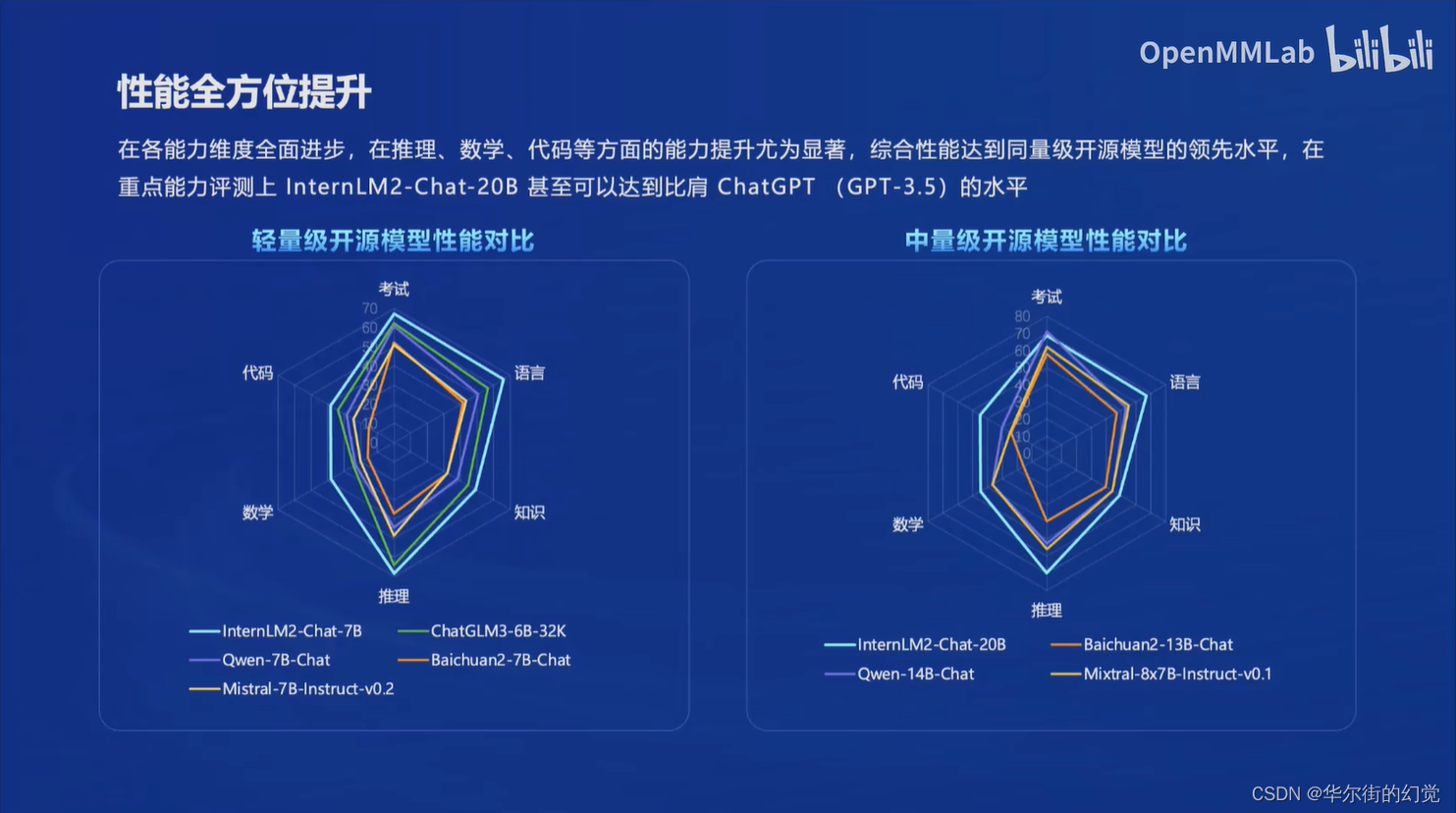
- 综合性能全面提升:推理,数学,代码提升显著InternLM2-Chat-20B在重点评测上比肩ChatGPT
- 优秀的对话和创作体验:精准指令跟随,丰富的结构化创作,在AlpacaEval2超越GPT-3.5和Gemini Pro
- 工具调用能力整体升级:可靠支持工具多轮调用,复杂智能体搭建
- 突出的数理能力和实用的数据分析功能:强大的内生计算能力,加入代码解释后,在GSM8K和MATH达到和GPT-4相仿水平





模型到应用

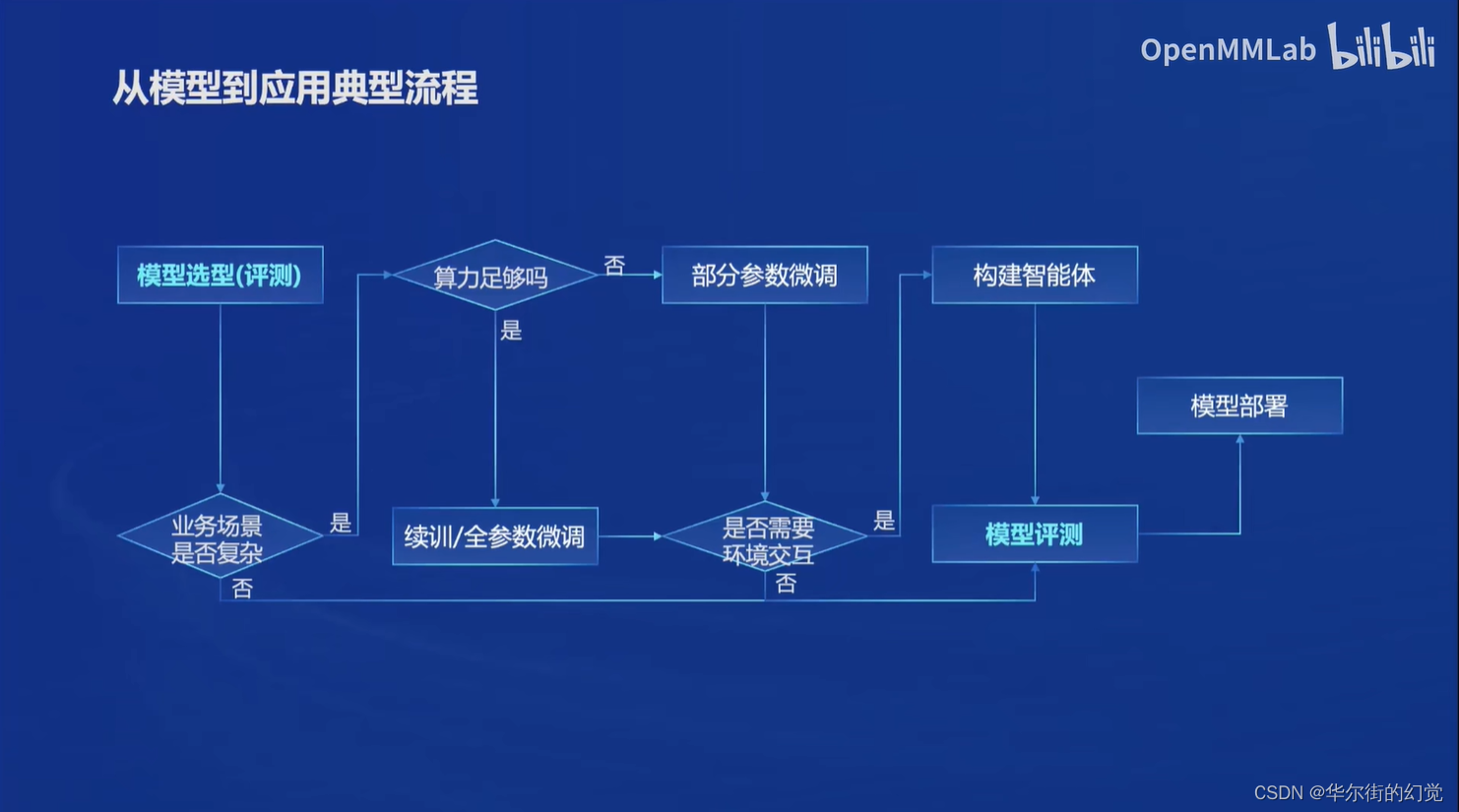
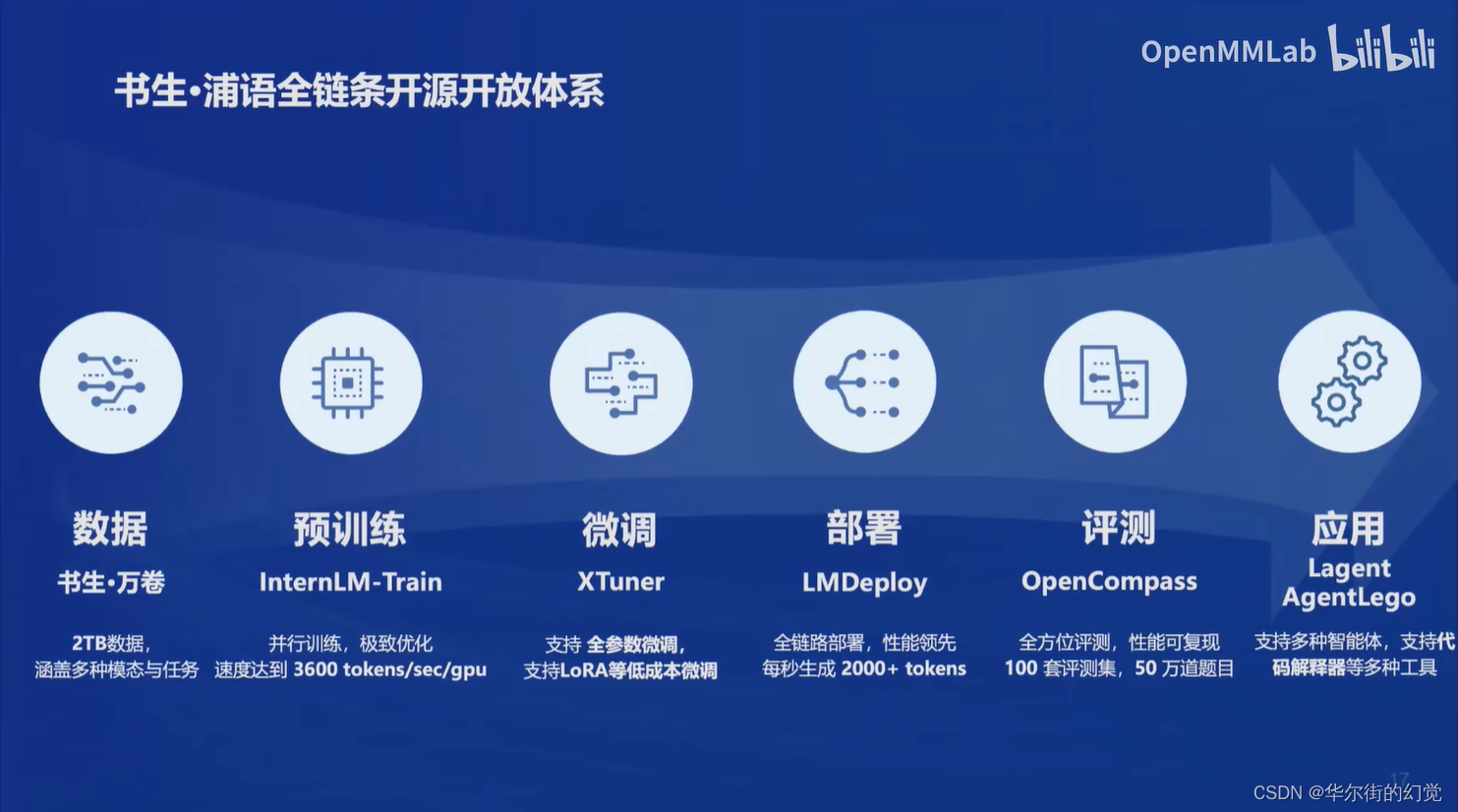
全链条开源开放体系
书生葡语的全链条工具体系开源,包括:数据、预训练、微调、部署、评测、应用等环节
数据

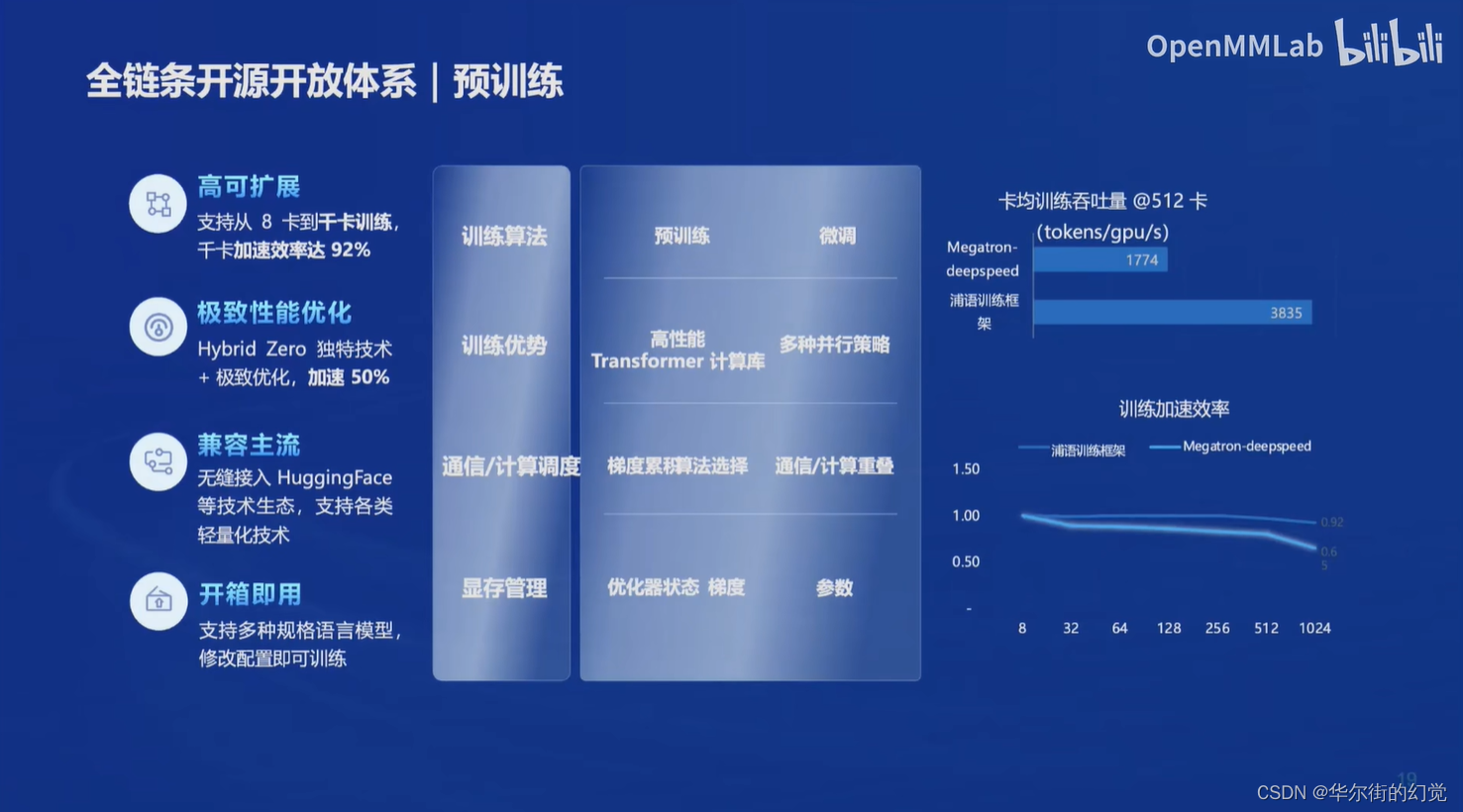
预训练

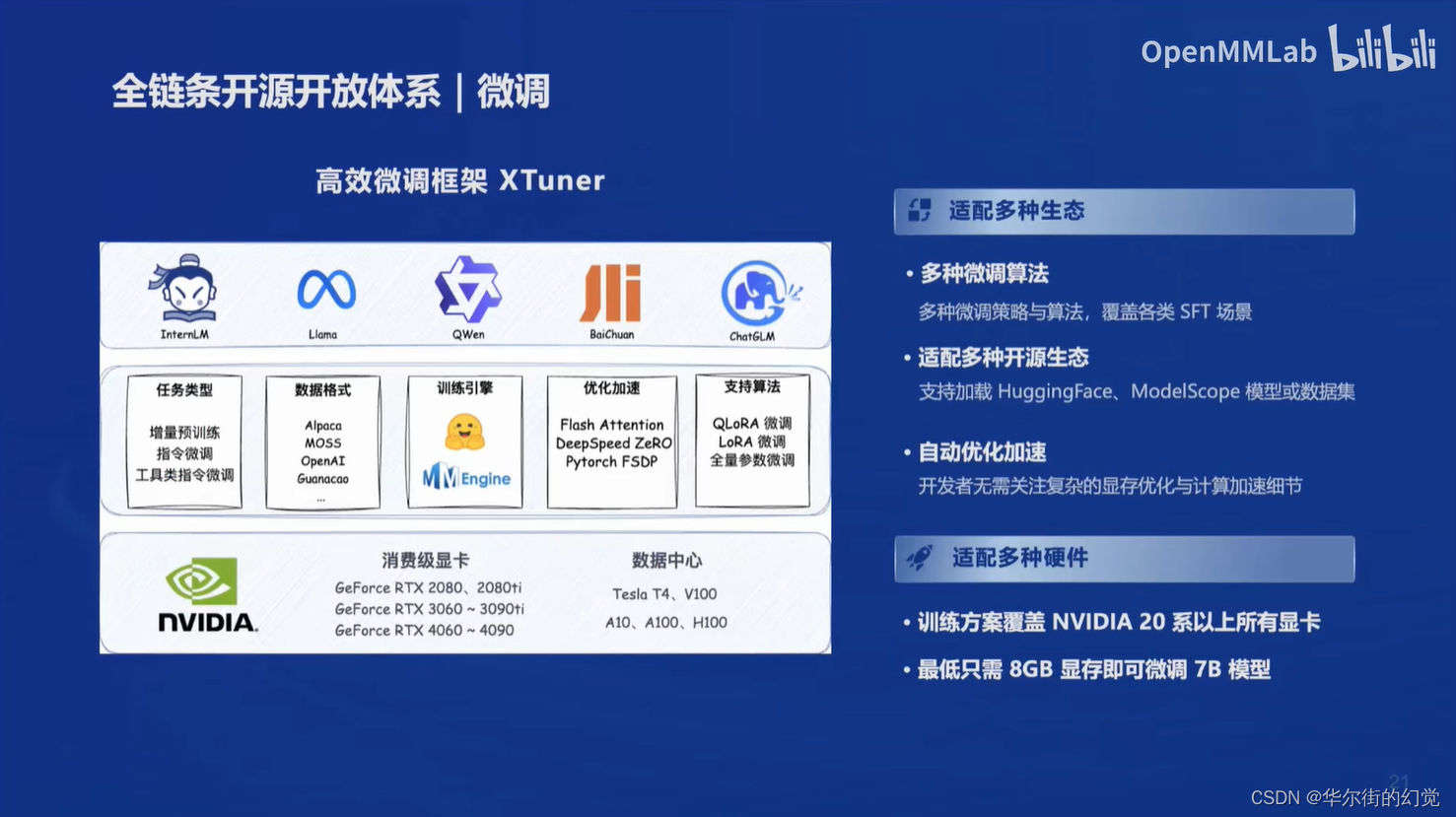
评测-OpenCompass
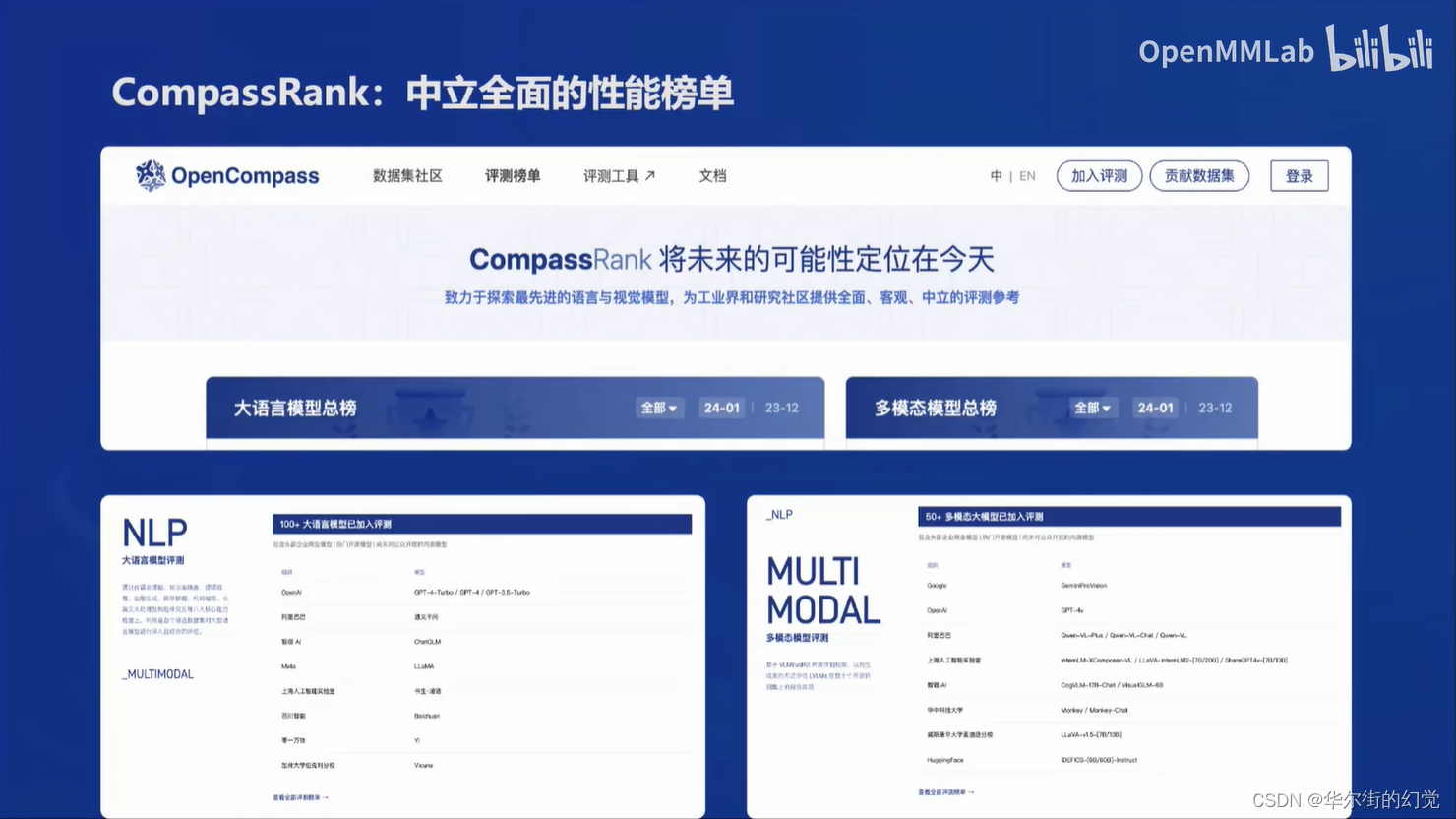
OpenCompass是国产大模型评测体系,已经适配超过100个评测集。采用循环评测策略提高性能。国内模型在中文场景下具有优势,开源社区模型表现优异,指导未来开源模型选型。


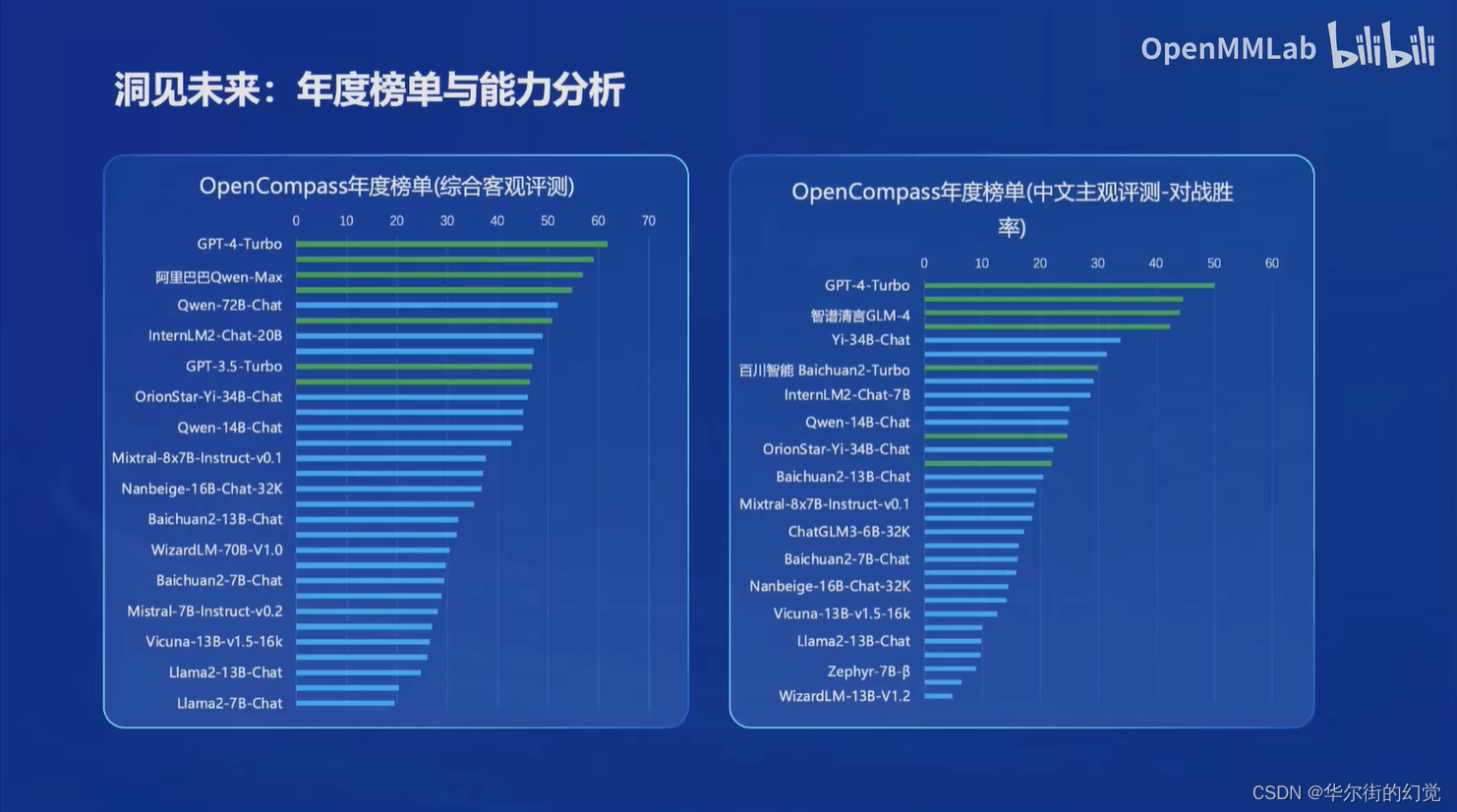
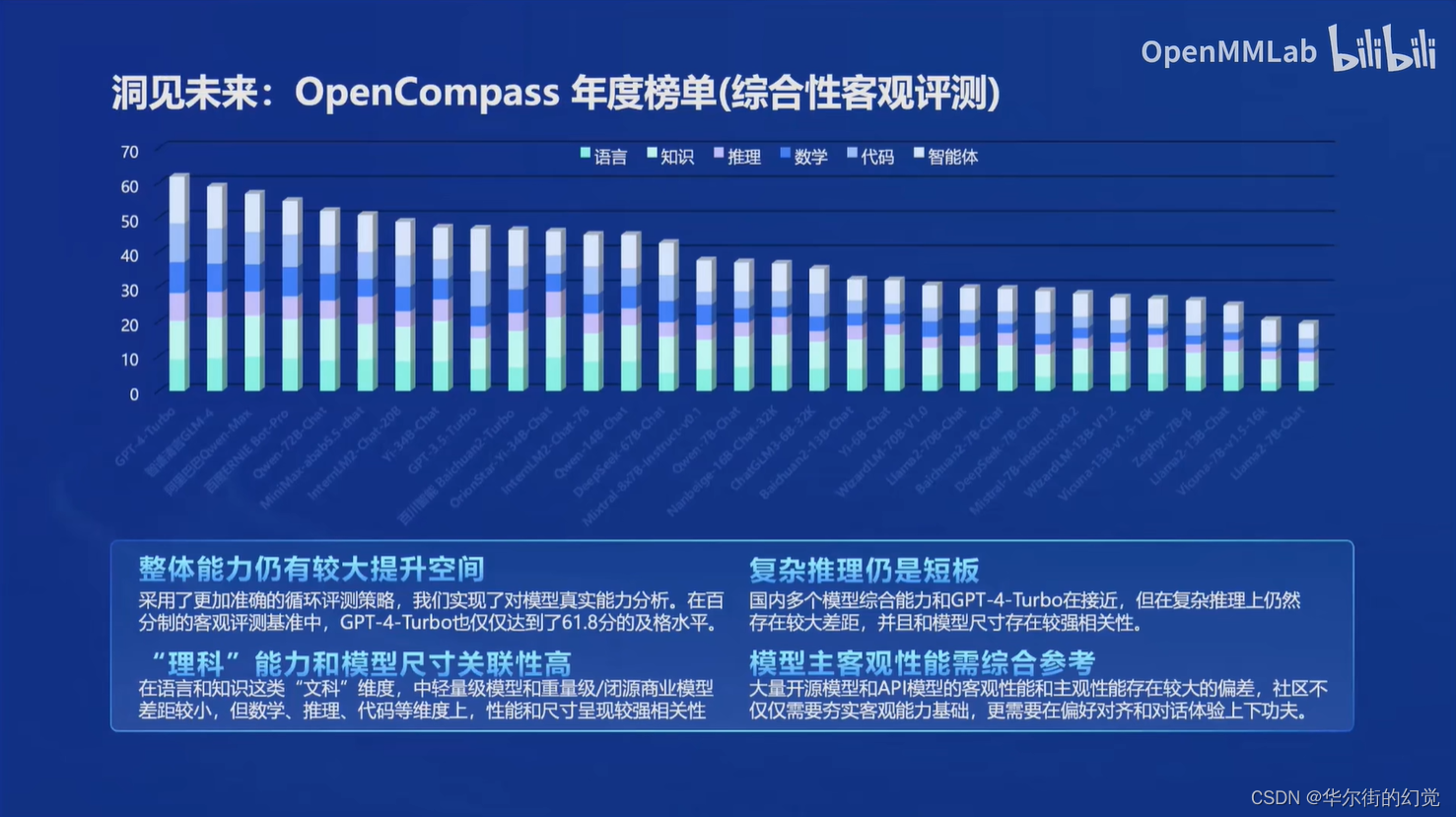
在OpenCompass年度榜单中反映了四个问题
- 整体能力仍有较大提升空间:在百分制的客观评测基准中,GPT-4-Turbo也仅仅达到了61.8分的及格水平
- “理科”能力和模型尺寸关联度高:在语言和知识这类“文科”维度,中轻量级模型和重量级/闭源商业模型差距较小,但在数学,推理,代码等维度上,性能和尺寸呈现较强相关性
- 复杂推理仍是短板:国内多个模型综合能力和GPT-4-Turbo在接近,但在复杂推理上仍然存在较大差距,并且和模型尺寸存在较强相关性
- 模型主客观性能需综合参考:大量开源模型和API模型的客观性能和主观性能存在较大的偏差,社区不仅仅需要夯实客观能力基础,更需要在偏好对齐和对话体验上下功夫
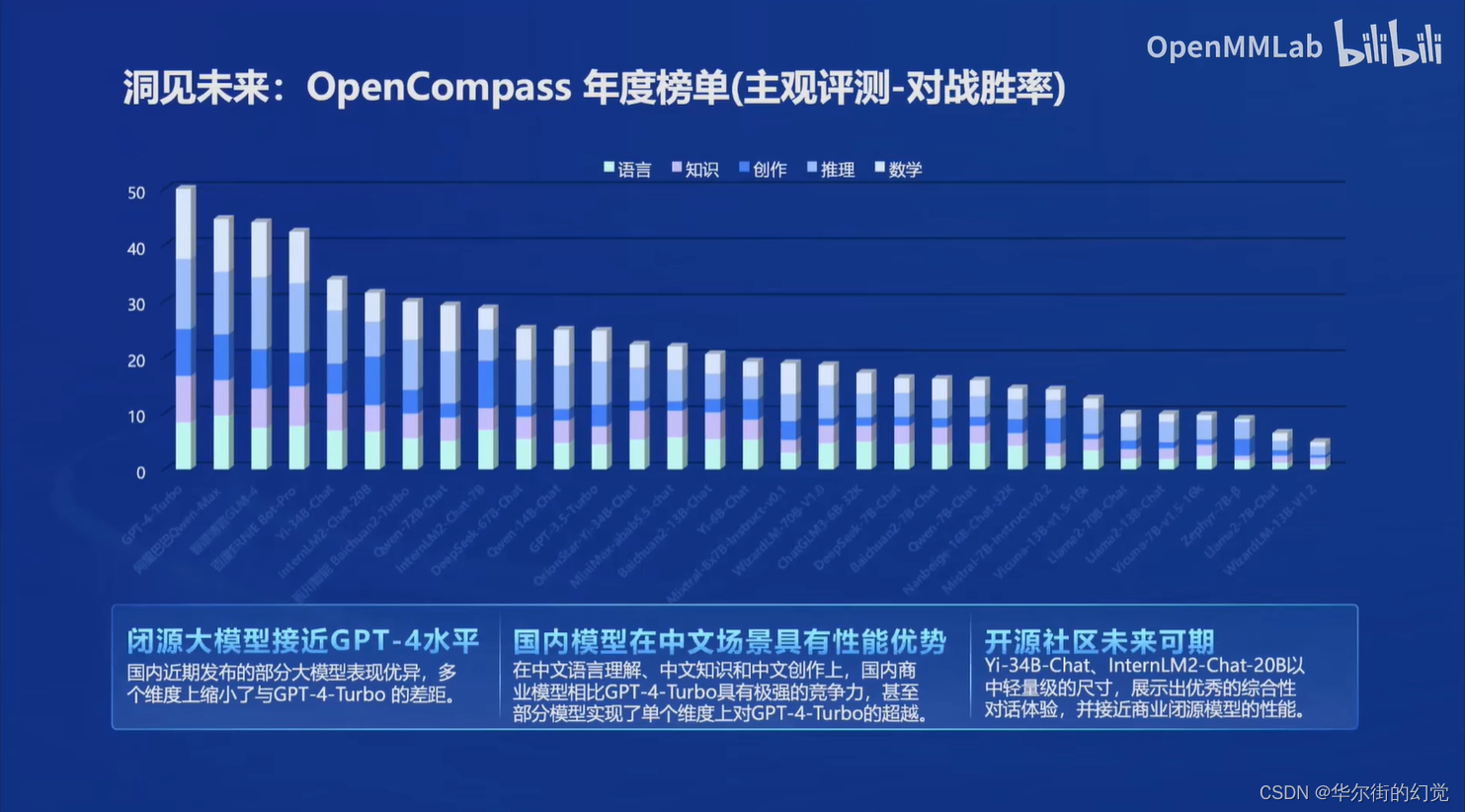
在OpenCompass年度榜单中反映了三个信息
- 闭源大模型接近GPT-4水平:国内经期发布的部分大模型表现优异,多个维度上缩小了与GPT-4-Turbo的差距
- 国内模型在中文场景具有性能优势:在中文语言理解,中文知识和中文创作上,国内商业模型相比GPT-4-Turbo具有极强的竞争力,甚至部分模型实现了单个维度上GPT-4-Turbo的超越
- 开源社区未来可期:Yi-34B-Chat,InternLM2-Chat-20B以中轻量级的尺寸,展示出优秀的综合性对话体验,并接近商业闭源模型的性能
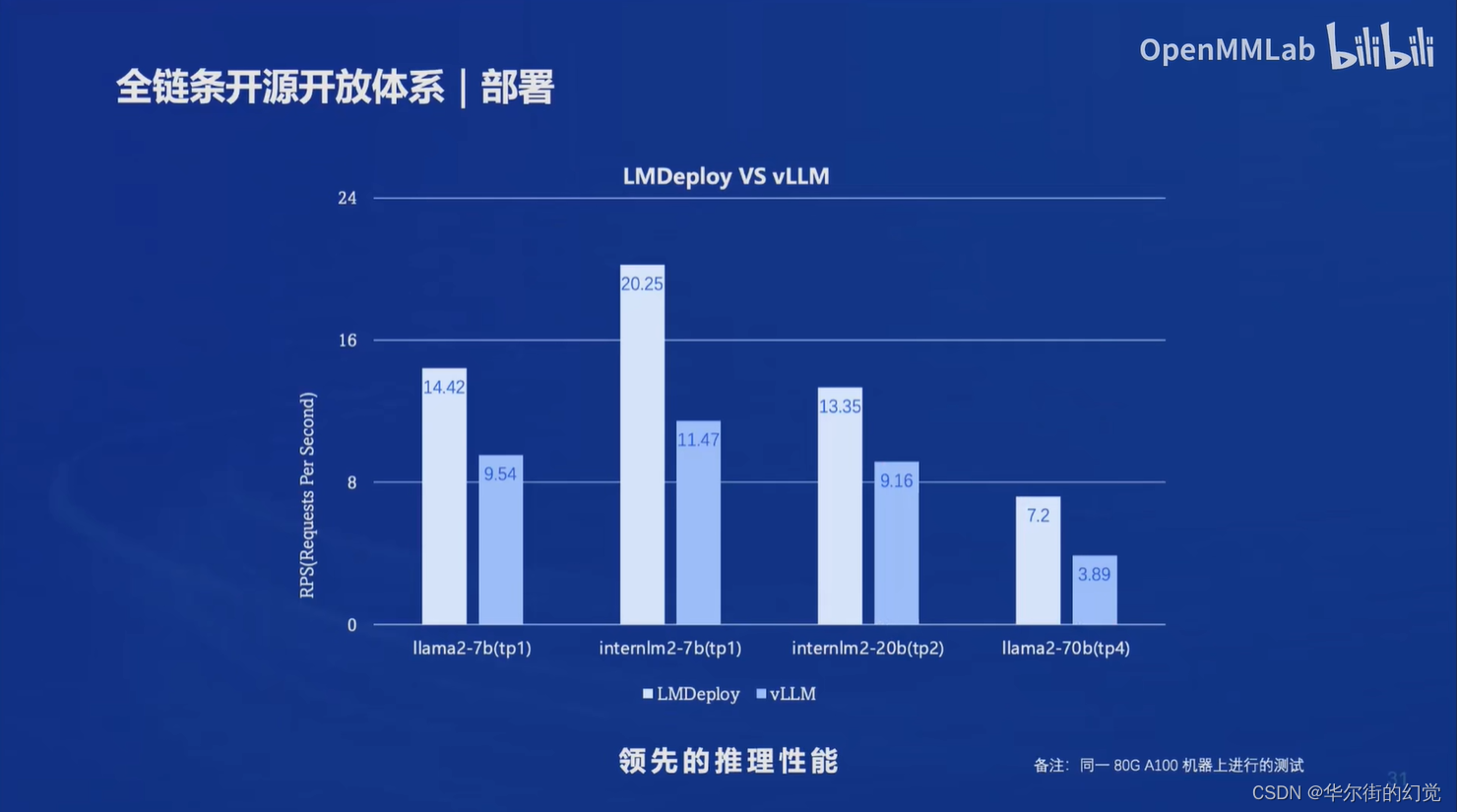
部署

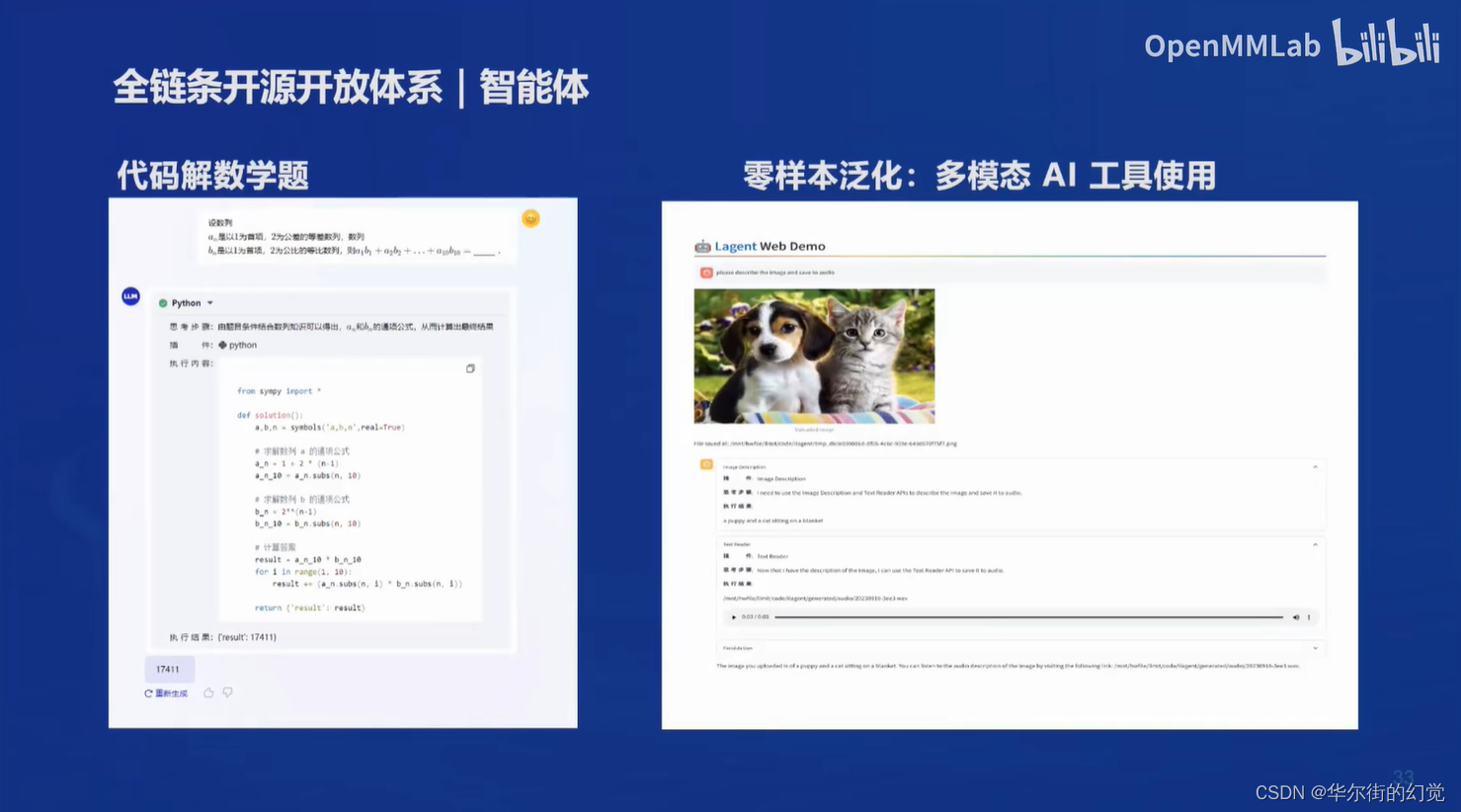
智能体

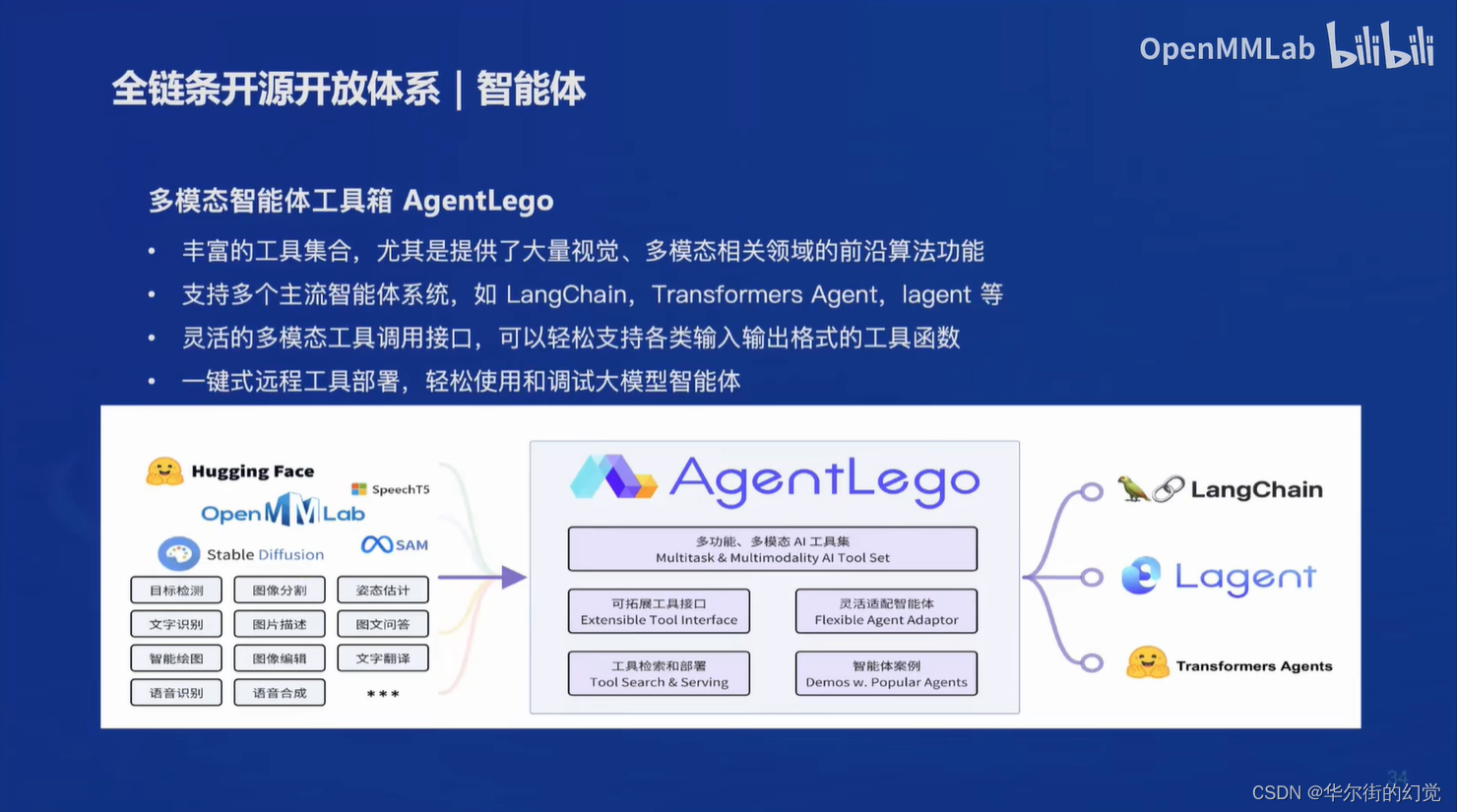
回顾

课程介绍

轻松玩转书生·浦语大模型趣味 Demo


实战第一部分
实战第二部分
实战第三部分
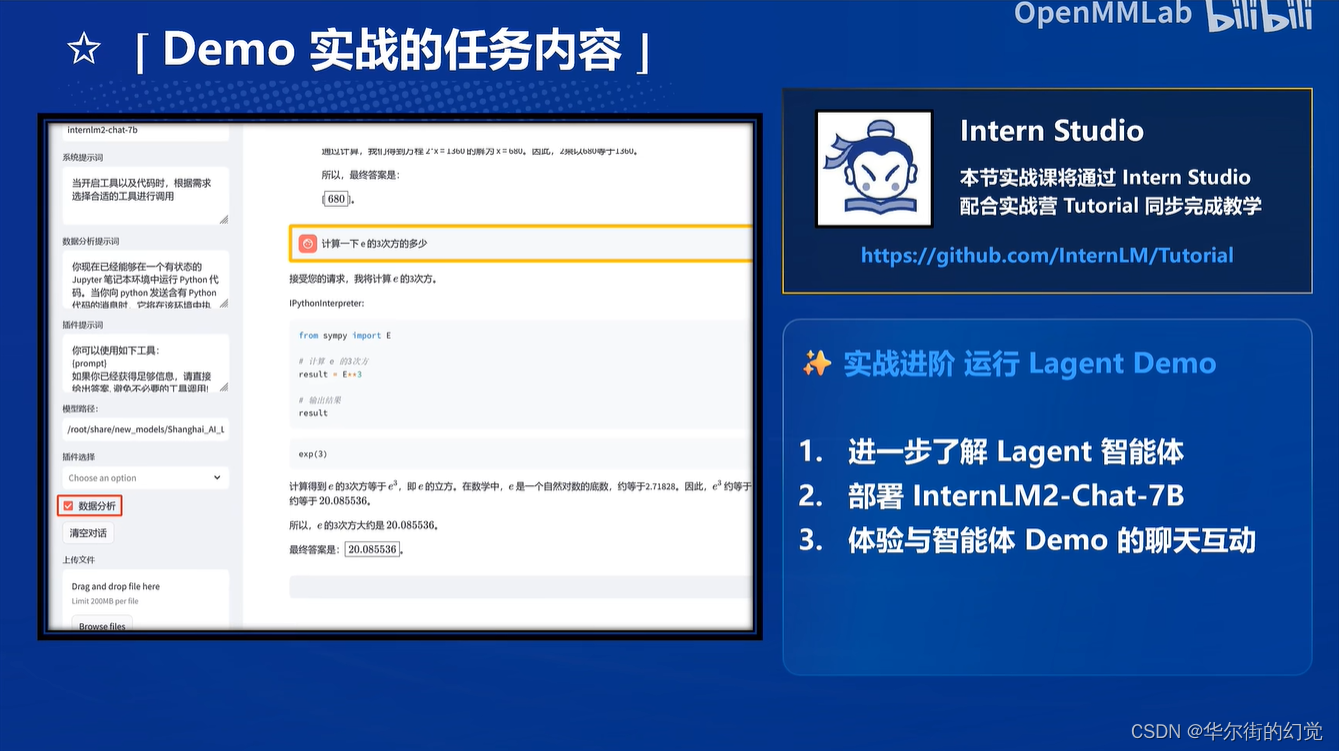
实战第四部分

优秀作品

参考链接
- bilibili官方视频: 书生·浦语大模型全链路开源体系
- bilibili官方视频:轻松玩转书生·浦语大模型趣味 Demo
- GitHub文档:书生·浦语大模型的 HelloWorld















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









