






近年来,随着参数量极大的AI模型涌现,GPU-HBM模块被广泛用于AI模型的训练和推理。其具备高存储容量和TB/s级的处理器与存储器间带宽。然而,传统GPU-HBM模块中,数据通过片外互连移动时会产生高功耗和延迟,成为系统整体性能的瓶颈。
为减少片外数据移动,需通过片上网络扩展片上缓存容量。为提升片上缓存容量,已有多种新架构被提出,包括使用静态随机存取存储器(SRAM)作为主存的加速器及配备堆叠L3缓存的中央处理器(CPU)。近期发布的NVIDIAGPU也增加了L2缓存容量。然而,尽管存在这些进展,片上缓存容量仍显不足。
一种ESC堆叠GPU-HBM模块架构是通过将基于SRAM的L2缓存堆叠于GPU之上(如图1所示),利用更短的片上互连减少数据移动。因此,该架构是实现高性能与高能效AI计算的理想方案。
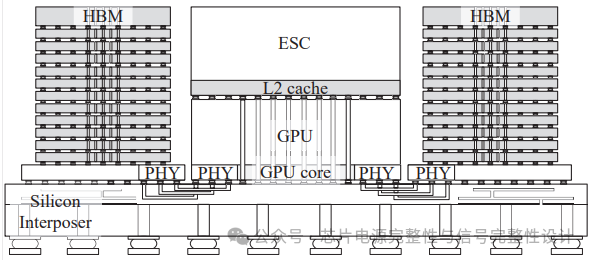
图1:扩展规模缓存(ESC)堆叠-GPU-HBM模块架构的概念视图
然而,该架构中,由于ESC通过分层PDN向GPU核心传递额外开关噪声,SSN增加。SSN会引发电压波动,可能导致GPU核心逻辑操作故障。因此,为确保架构的稳定PI性能,我们在VDD电源域的时域内分析其SSN。
ESC堆叠GPU-HBM模块架构设计
如图1所示,所提出的ESC堆叠GPU-HBM模块架构的核心是将L2缓存组成的ESC堆叠于GPU之上。通过此设计,延迟的降低提升了吞吐量,而功耗的减少提高了能效。为实现该架构,需对GPU进行背面研磨,使ESC堆叠GPU的高度与HBM一致(符合JEDEC规范规定的720um)。该ESC堆叠GPU集成了六颗新一代HBM,配备高密度I/O,可提供数十TB/s的高带宽。
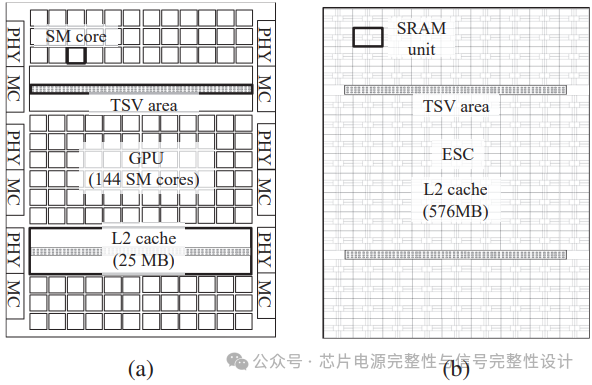
图2: 设计Floorplan和配置(a) GPU (b) ESC
图2展示了GPU与ESC的布局设计。GPU和ESC的总面积相同。GPU包含144个流式多处理器(SM)核心及总计50MB的L2缓存(含用于与ESC连接的硅通孔(TSV)区域)。ESC配置为576MB的L2缓存,由9×16个4MB的SRAM单元组成,同样包含TSV区域以维持与GPUL2缓存的连接。
架构的PI分析
A.架构的SSC建模与分析
分别对GPU和ESC的SSC频谱进行建模。使用芯片功耗模型(CPM)建模GPU的SSC。CPM是一种通过分段线性(PWL)电流源反映芯片动态功耗的PI分析方法。基于GPU的700W峰值功耗及焊点数量,其PWL电流源的峰值电流(Iₚₑₐₖ)为7.1mA,周期(T)为0.55ns,上升/下降时间为0.05T。ESC的SRAM电路通过SPICE仿真生成读操作重复时的电流频谱,其Iₚₑₐₖ为0.4mA。GPU和ESC的电源电压(VDD)均为1.1V,时钟频率(f₆ₗₒcₖ)为1.8GHz。
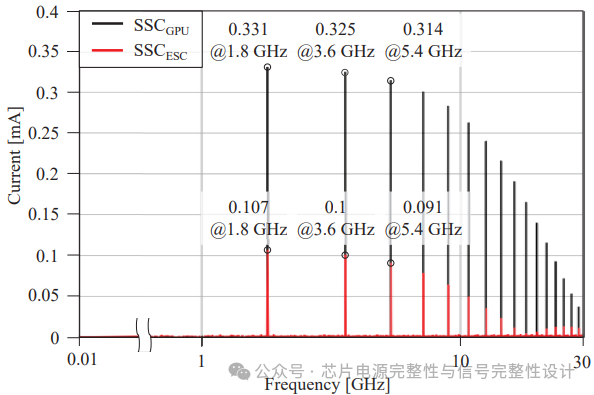
图3:GPU和ESC的电流频谱
如图3所示,通过快速傅里叶变换(FFT)得到GPU和ESC的频域SSC频谱。两者的SSC峰值电流主要集中于时钟频率的高次谐波区域。GPU的峰值电流高于ESC,这归因于其SM核心的高功耗。
B.分层PDN建模与分析
分层PDN模型包含封装PDN、中介层PDN、GPUPDN和ESCPDN。封装PDN尺寸为50.6mm×35.6mm;中介层PDN为网格型,尺寸6.8mm×6.2mm;GPU和ESC的PDN为网格型,尺寸分别为3.4mm×3.4mm和2.8mm×1.9mm。各单元通过平衡传输线法(TLM)建模为等效电路。中介层PDN的单元金属密度为75%,长度20um;芯片PDN的单元金属密度为80%,长度5um。所有组件通过分段法级联。
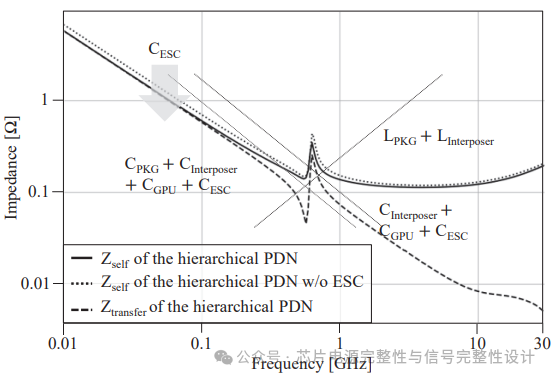
图4:GPU中心端口探测的自阻抗和传输PDN阻抗
图4展示了0.01至30GHz频段内分层PDN的阻抗特性。在GPU中心端口测得的自阻抗(Zₛₑₗₐ)表明,ESC的加入使PDN总电容增加,原因是高金属密度导致电源与地平面重叠面积增大。转移阻抗(Zₜᵣₐₙₛfₑᵣ)在低频段与Zₛₑₗₐ一致,但在高频段因端口间距差异而变化。Zₜᵣₐₙₛfₑᵣ的总和较高,需详细分析SSN。
C.SSN建模与分析
通过将SSC与PDN阻抗相乘并进行逆快速傅里叶变换(IFFT),我们建模并分析了SSN。传统GPU-HBM模块的SSN包含自开关噪声和转移开关噪声总和。所提出架构还需考虑ESC传递的额外噪声(如公式所示)。

在GPU中心端口探测SSN时,发现其值远超VDD的5%阈值,需通过去耦电容(decaps)抑制SSN。金属-绝缘体-金属(MIM)电容因其低电阻和低寄生电容适用于高频场景,且可布设于电源/地平面重叠区域,无需额外占用芯片面积。
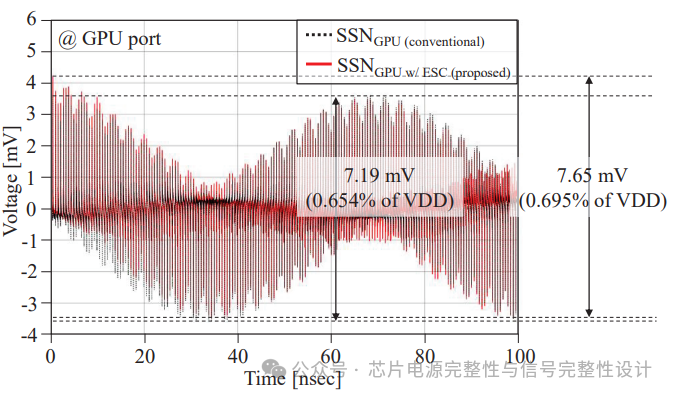
图5:SSN噪声比较
图5对比了传统GPU-HBM模块(SSNGₚᵤ)与加入1,152nFdecaps的所提出架构(SSNGₚᵤw/ESC)的SSN。SSNGₚᵤ降至7.19mV(VDD的0.654%),SSNGₚᵤw/ESC为7.65mV(VDD的0.695%),显著低于5%阈值,表明此设计具备可靠的PI性能。
结论
ESC堆叠GPU-HBM模块架构通过堆叠L2缓存降低片外数据移动。通过设计GPU与ESC的布局,并建模分析其分层PDN、SSC及SSN,验证了其PI性能。


















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











