




 该博客介绍了通过对抗性损失和多尺度生成器与判别器实现高分辨率语义分割的方法,旨在保留图像细节和真实纹理。创新点包括交互式控制输出内容,允许用户编辑生成的图像风格,并结合实例分割信息。网络结构包含粗到细的生成器,以及作用于不同尺度的多尺度判别器。此外,还利用实例级特征编码进行风格选择。目标函数包括特征匹配损失,且提供了一种从边界图和语义标签中提取实例信息的方式。
该博客介绍了通过对抗性损失和多尺度生成器与判别器实现高分辨率语义分割的方法,旨在保留图像细节和真实纹理。创新点包括交互式控制输出内容,允许用户编辑生成的图像风格,并结合实例分割信息。网络结构包含粗到细的生成器,以及作用于不同尺度的多尺度判别器。此外,还利用实例级特征编码进行风格选择。目标函数包括特征匹配损失,且提供了一种从边界图和语义标签中提取实例信息的方式。
1、目的
语义分割mask -> 高分辨率图像,具备细节和真实纹理
2、创新点
1)高分辨率输出
-> adversarial loss
-> multi-scale generator
-> multi-scale discriminator
2)交互式控制输出内容
-> instance segmentation信息
-> 可编辑生成的图像风格
3、网络
1)Coarse-to-fine generator
首先训练G1,然后训练G2,然后一起fine-tune
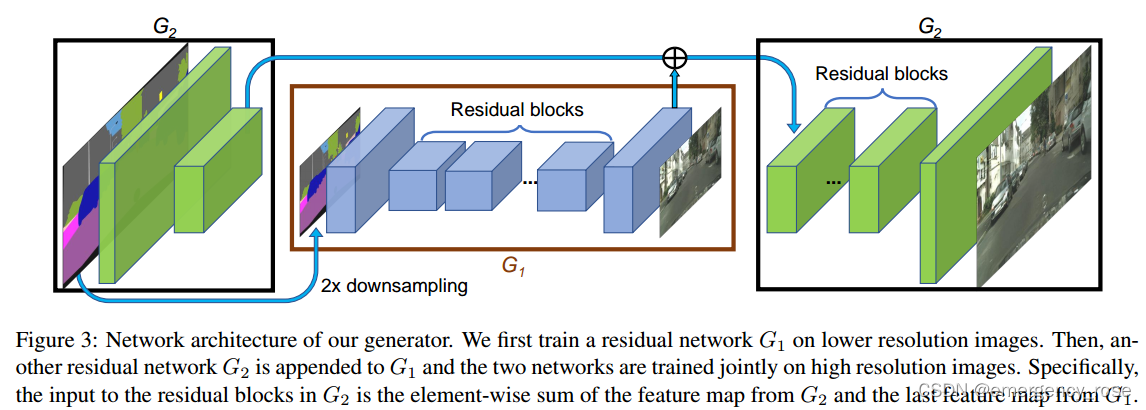
a)G1:全局生成
H/2 x W/2 -> 卷积 ![]() -> 若干残差模块
-> 若干残差模块![]() -> 反卷积
-> 反卷积![]() -> output1
-> output1
b)G2:局部增强
H x W -> 卷积![]() -> + output1 -> 若干残差模块
-> + output1 -> 若干残差模块![]() -> 反卷积
-> 反卷积![]()
注:可根据需要扩展更多的generator,以适应更高分辨率的生成
2)multi-scale discriminator
结构相同,作用于不同scale(1,1/2,1/4)的![]() ,
,![]() ,
,![]()
4、目标函数
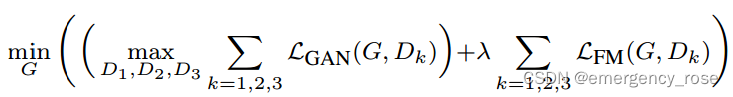
feature matching loss(D不参与梯度更新,只作为特征提取器):
![]()
其中,![]() 指的是判别器
指的是判别器![]() 第i层的输出
第i层的输出
5、Instance map
1)提取boundary map(与相邻4个pixel中的某个pixel类别不同的点)
2)和one-hot semantic label map并联,输入生成器/判别器
6、Instance-level特征编码
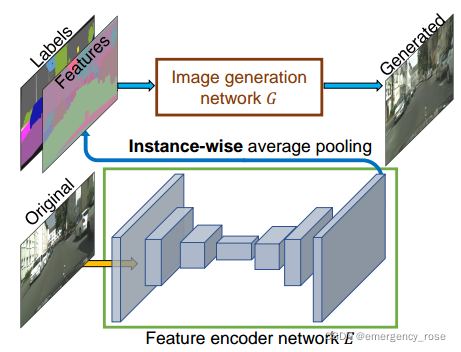
1)encoder-decoder结构的特征编码网络 -> instance-wise average pooling -> broadcast
2)和生成器/判别器联合训练
3)对于每种语义类别,K-means聚类出候选风格,供用户挑选

















 2888
2888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









