




Abstract
方法:
一种新的对抗性损失函数以及新颖的多尺度生成器和判别器架构,生成了2048×1024分辨率的图像。
加入了两个用于交互式视觉操作的新功能。
- 整合了对象实例分割信息,使得能够进行对象的操作,例如移除/添加对象以及更改对象类别。
- 提出了一种方法,在相同输入下生成多样化的结果,允许用户交互式地编辑对象外观。
1. Introduction
讨论了一种新的方法,产生高分辨率图像的语义标签映射。
首先仅通过对抗性训练获得结果,而不依赖任何手工制作的损失或预先训练的网络进行感知损失。
然后,如果预训练网络可用,则添加来自预训练网络的感知损失可以在某些情况下略微改善结果。
利用实例级对象分割信息,将同一类别内的不同对象实例进行分割。
提出了一种方法来生成不同的结果,给定相同的输入标签映射,允许用户交互编辑相同对象的外观。
2. Related Work
Generative adversarial networks(生成对抗网络):
旨在通过强制生成的样本与自然图像不可区分来模拟自然图像分布。
Image-to-image translation(图像到图像的转换):
在给定输入输出图像对作为训练数据的情况下,将输入图像从一个域翻译到另一个域。
基于感知损失的直接回归目标,并生成了第一个能够合成2048×1024图像的模型。(高分辨率)
Deep visual manipulation(深度视觉操作):
基于GANs学习的先验知识的对象外观编辑优化方法。
专注于对象级语义编辑,允许用户与整个场景交互并操纵图像中的单个对象。
系统允许更灵活的操作,并产生实时高分辨率的结果。
3. Instance-Level Image Synthesis
提出了一个条件对抗框架,用于从语义标签地图生成高分辨率照片真实感图像。
3.1 The pix2pix Baseline——像素到像素基准模型
生成器G的目标是将语义标签图转换为逼真的图像,而判别器D的目标是区分真实图像与生成的图像。
训练数据集是由对应图像对{(si, xi)}组成的,其中si是语义标签图,xi是对应的自然照片。
输入语义标签图的真实图像的条件分布:
minGmaxDLGAN(G,D)\min_G \max_D L_{\text{GAN}}(G, D)GminDmaxLGAN(G,D)
目标函数:
LGAN(G,D)=E(s,x)[logD(s,x)]+Es[log(1−D(s,G(s)))]L_{\text{GAN}}(G, D) = \mathbb{E}_{(s, x)}[\log D(s, x)] + \mathbb{E}_s[\log(1 - D(s, G(s)))]LGAN(G,D)=E(s,x)[logD(s,x)]+Es[log(1−D(s,G(s)))]
采用U-Net作为生成器,采用基于Patch的全卷积网络作为判别器。
输入判别器的是语义标签图和对应图像的逐通道拼接。
3.2 Improving Photorealism and Resolution——提高图片真实感和分辨率
Coarse-to-fine generator(粗糙到精细的生成器):
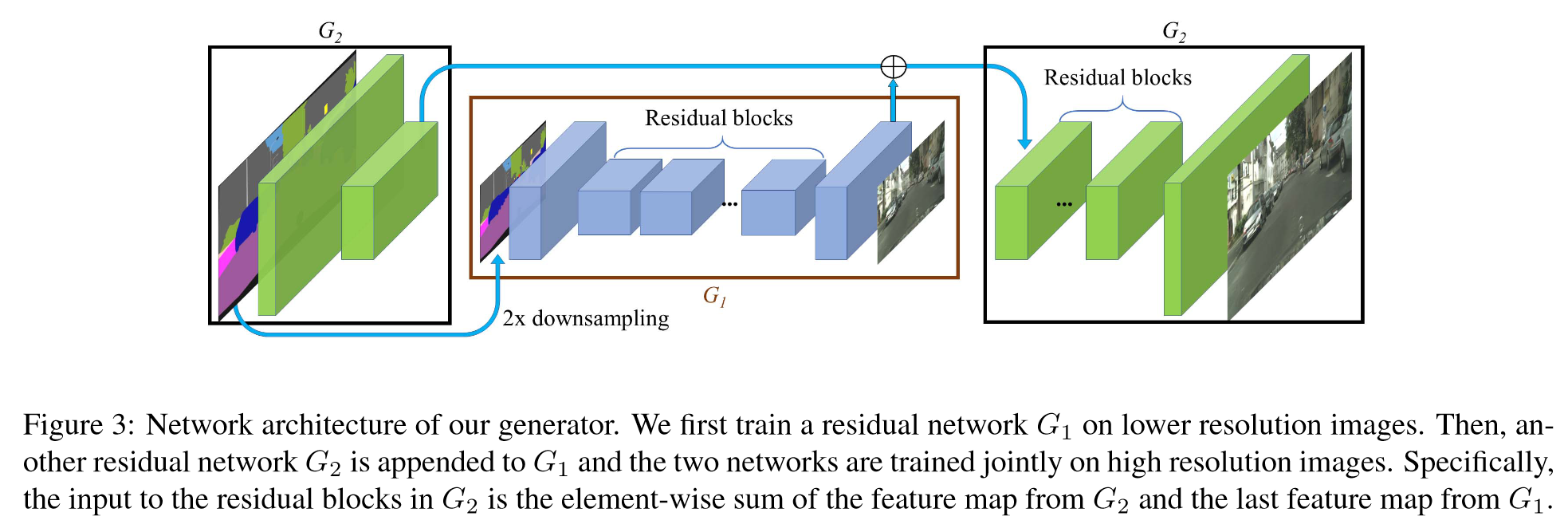
将生成器分解为两个子网络:G1 和 G2,生成器表示为一个元组 G = {G1, G2}。将 G1 称为全局生成器网络,将 G2 称为局部增强器网络。
全局生成器网络在 1024 × 512 的分辨率下运行,局部增强器网络输出的图像分辨率是前一网络输出的 4 倍(每个图像维度上增加 2 倍)。
为了生成更高分辨率的图像,可以使用额外的局部增强器网络。
全局生成器网络包含 3 个组件:卷积前端 G(F)1、一组残差块 G®1和反卷积后端 G(B)1。
局部增强器网络同样由 3 个组件组成:卷积前端 G(F)2、一组残差块 G®2 和反卷积后端 G(B)2。
G1 输入分辨率为 1024 × 512 的语义标签图,输出分辨率为 1024 × 512 的图像。
G2 输入分辨率为 2048 × 1024 的语义标签图,输入到残差块 G®2 的特征图是两个特征图的逐元素和:G(F)2 的输出特征图和全局生成网络 G(B)1 后端的最后一个特征图。这有助于将来自 G1 的全局信息整合到 G2 中,有效地整合全局和局部信息。
Multi-scale discriminators(多尺度判别器):
使用 3 个判别器,它们的网络结构相同,但在不同的图像尺度上运行,称为 D1、D2 和 D3。
将真实和合成的高分辨率图像分别按 2 倍和 4 倍的比例进行下采样,创建一个包含 3 个尺度的图像金字塔。
判别器 D1、D2 和 D3 分别在这 3 个不同的尺度上训练,以区分真实图像和合成图像。
运行在最粗尺度的判别器具有最大的感受野,对图像有更全局的视角,能够引导生成器生成全局一致的图像。
运行在最细尺度的判别器则专注于引导生成器生成更精细的细节。
这使得训练粗到细生成器变得更容易,因为将低分辨率模型扩展到更高分辨率只需在最细级别添加一个额外的判别器,而不必从头开始训练。
加入判别器后的公式:
minGmaxD1,D2,D3∑k=13LGAN(G,Dk)\min_G \max_{D_1, D_2, D_3} \sum_{k=1}^{3} \mathcal{L}_{GAN}(G, D_k)Gmin
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2915
2915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









