








 这篇博客介绍了如何在公司网络无法直接访问driver.google.com的情况下,通过获取文件夹内文件的ID并使用在线工具转换成直链进行分段下载。首先,分享文件夹并获取所有文件的ID,然后利用浏览器控制台提取文件的data-id。接着,使用https://api.moeclub.org/GoogleDrive/将ID转换为直链,最后通过Python脚本来逐个下载文件,实时显示下载进度。
这篇博客介绍了如何在公司网络无法直接访问driver.google.com的情况下,通过获取文件夹内文件的ID并使用在线工具转换成直链进行分段下载。首先,分享文件夹并获取所有文件的ID,然后利用浏览器控制台提取文件的data-id。接着,使用https://api.moeclub.org/GoogleDrive/将ID转换为直链,最后通过Python脚本来逐个下载文件,实时显示下载进度。
背景:公司的网络上不了driver.google.com,却能够上得了googleusercontent.com (这是谷歌文件下载的直链),然后文件一大,下载到一半老是断,所以要避免文件夹直接压缩下载,只能一个一个下载,
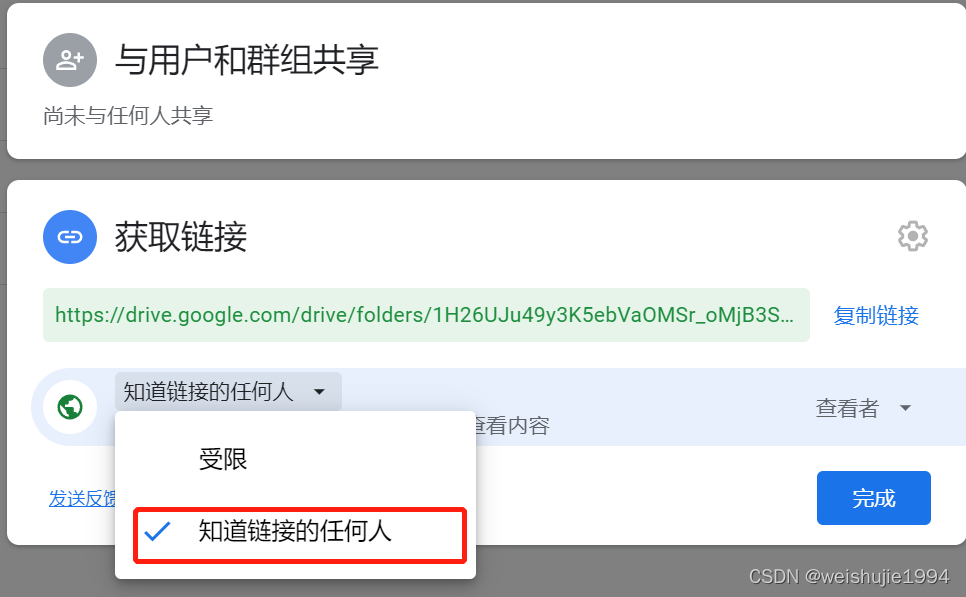
一:首先第一步,要把要下载的文件夹分享出去,直接在文件夹那里右键-》共享-》记得选择知道链接的任何人,然后你的文件上就有一对情侣
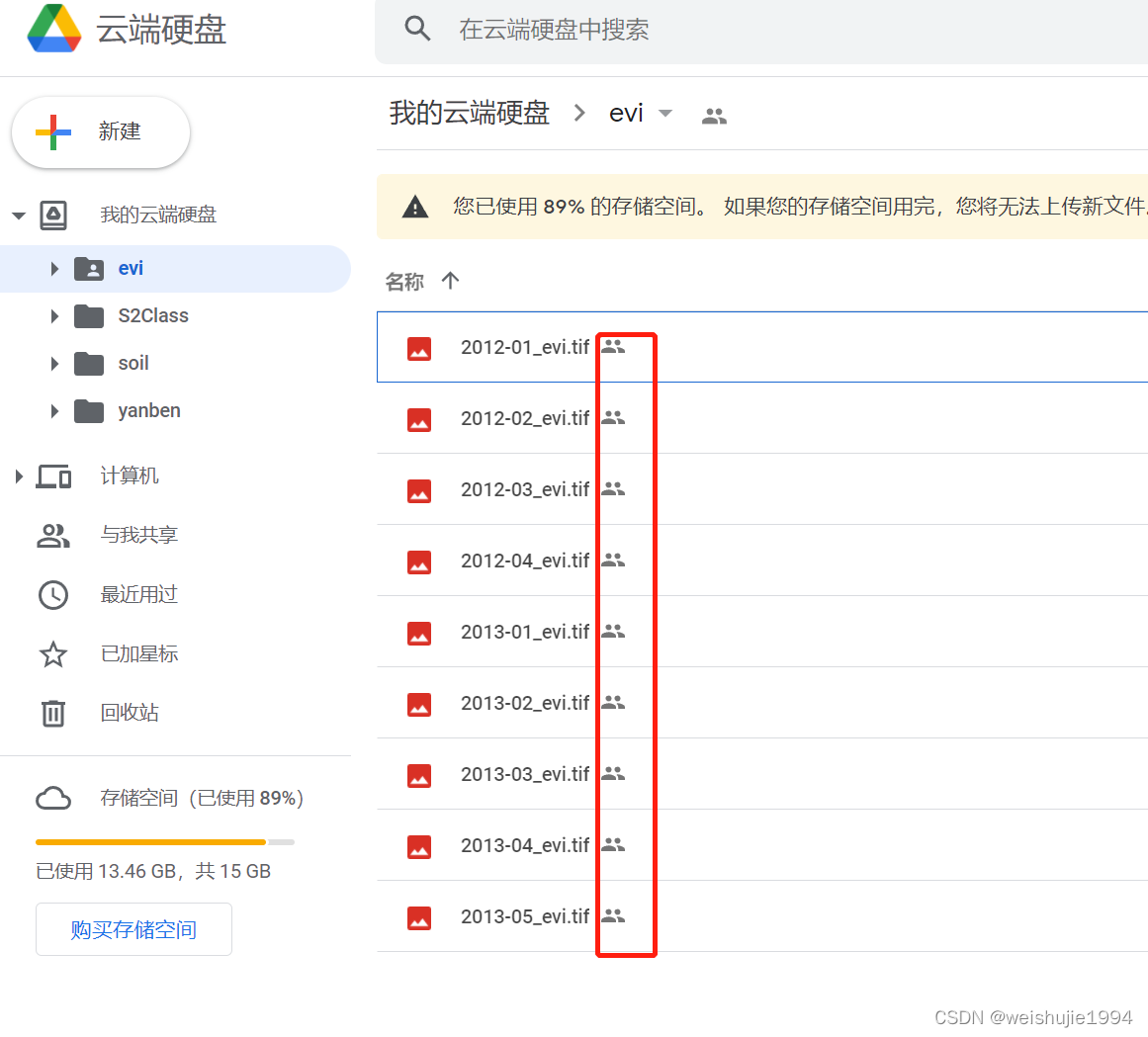
注意:如果文件夹里的文件特别多,要滚动鼠标,然后所有文件都在列表了
二:按F12打开浏览器控制台
输入:
for(i=0;i<document.getElementsByClassName("WYuW0e").length;i++){console.log(document.getElementsByClassName("WYuW0e")[i].getAttribute("data-id"))}得到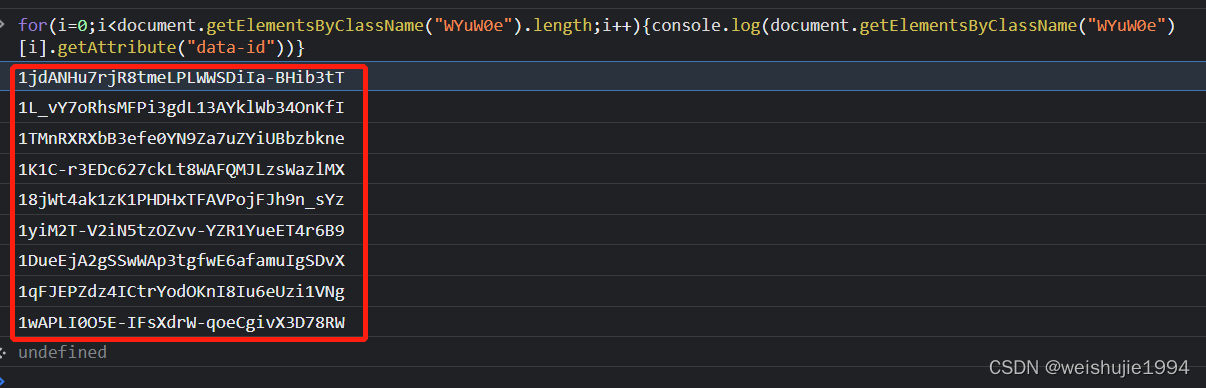
这些就是文件的ID,之后拿着这个ID,去网上找大佬无私奉献的直链转换工具,就能够得到直链下载地址,我这里用的是:
https://api.moeclub.org/GoogleDrive/
这个链接后面拼上id就能够获取到直链了
然后上代码:
# ids获取方式
# 在谷歌云盘浏览器控制台输入
# for(i=0;i<document.getElementsByClassName("WYuW0e").length;i++){console.log(document.getElementsByClassName("WYuW0e")[i].getAttribute("data-id"))}
from contextlib import closing
ids = [
"18jWt4ak1zK1PHTFAVPojFJh9n_sYz",
"balabalablalalalfdsaldfas",
]
uri = "https://api.moeclub.org/GoogleDrive/"
outpath = "E:\\"
allok = []
allerr = []
import requests
# proxies = {
# 'http': 'http://127.0.0.1:1080',
# 'https': 'http://127.0.0.1:1080' # https -> http
# }
okfile = r'ok.txt'
errfile = r'err.txt'
for id_ in ids:
try:
print(f"开始请求下载{id_}")
with closing(requests.get(uri + id_, allow_redirects=True, stream=True)) as myfile:
# myfile = requests.get(uri + id_, allow_redirects=True, stream=True)
print(f"获取下载链接成功,开始获取文件名")
print(f"链接为:{myfile.url}")
filename = myfile.headers.get("content-disposition").split("filename=")[1].replace("\"", "").split(";")[0]
print(f"文件名为{filename}")
filepath = outpath + filename
print(f"开始保存到路径{filepath}")
fh = open(filepath, 'wb')
print(f"开始下载{filename}")
filesize = int(myfile.headers.get('content-length'))
print(f"文件大小为:{filesize/1024/1024} MB")
downloaded = 0
perper = 0
for chunk in myfile.iter_content(chunk_size=2048): # 每次下载5120,因为我的大点,我选择每次稍大一点,这个自己根据需要选择。
downloaded += 2048
per = downloaded/filesize*100
if per - perper >= 1:
print(f"下载进度为:{per} %")
perper = per
if chunk:
fh.write(chunk)
# print(f"获取下载链接成功,开始获取文件名")
# print(f"链接为:{myfile.url}")
# filename = myfile.headers.get("content-disposition").split("filename=")[1].replace("\"", "").split(";")[0]
# print(f"文件名为{filename}")
# filepath = outpath + filename
# print(f"开始保存到路径{filepath}")
# fh = open(filepath, 'wb')
# fh.write(myfile.content)
print(f"文件 {filename} 下载成功,并保存到了 {filepath}")
allok.append(id_ + "," + filename)
with open(okfile, 'a+') as ok:
ok.write(id_ + "," + filename + "\n") # 加\n换行显示
except BaseException as e:
allerr.append(id_)
with open(errfile, 'a+') as err:
err.write(id_ + "\n") # 加\n换行显示
print(f"发生异常: {e}")
continue
else:
fh.close()
print(allok)
print(allerr)
exit()
















 6008
6008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









