







第九章主要是对支持向量机(SVM)的应用,应用领域是水质评价,即利用支持向量机对图像数据进行训练,从而对水质类别进行分类。
关于支持向量机的理论内容,支持向量机通俗导论(理解SVM的三层境界)这篇文章讲得非常详细,博主主要对书中的实战部分进行整理。
首先,对数据进行导入,并构造特征和标签。
代码如下:
#-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
inputfile='D:/ProgramData/PythonDataAnalysiscode/chapter9/demo/data/moment.csv'
data=pd.read_csv(inputfile,encoding='gbk')
data=data.take(np.random.permutation(len(data)))
data=data.as_matrix()
data_train=data[:int(0.8*len(data)),:]
data_test=data[int(0.8*len(data)):,:]
#构造特征和标签
x_train=data_train[:,2:]*30
y_train=data_train[:,0].astype(int)
x_test=data_test[:,2:]*30
y_test=data_test[:,0].astype(int)值得一提的是,原书中,打乱数据用的是random.shuffle,经过实践,此函数打乱后的数据并不是我们想要的结果。此处应该用以下三种方法来打乱数据:
【data.sample(frac=1)】
【from sklearn.utils import shuffle
shuffle(data)】
【data.take(np.random.permutation(len(data)))】然后,导入算法,训练模型。
代码如下:
#导入模型相关的函数,建立并训练模型
from sklearn import svm
model=svm.SVC()
model.fit(x_train,y_train)
import pickle
#保存模型
pickle.dump(model,open('D:/ProgramData/PythonDataAnalysiscode/chapter9/demo/data/svm.model','wb'))最后,对测试集数据进行预测,并画出训练数据和测试数据预测的混淆矩阵图。
书中并没有对预测结果的混淆矩阵进行可视化,博主参照其他资料,将混淆矩阵绘图函数代码记录如下:
import matplotlib.pyplot as plt
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')具体混淆矩阵运行代码如下:
from sklearn import metrics
cm_train=metrics.confusion_matrix(y_train,model.predict(x_train))
cm_test=metrics.confusion_matrix(y_test,model.predict(x_test))
fig=plt.figure(figsize=(10,5))
ax=fig.add_subplot(121)
plot_confusion_matrix(cm_train,classes=range(5),title='Confusion matrix on train-set')
ax=fig.add_subplot(122)
plot_confusion_matrix(cm_test,classes=range(5),title='Confusion matrix on test-set')
plt.show()输出结果如下图:
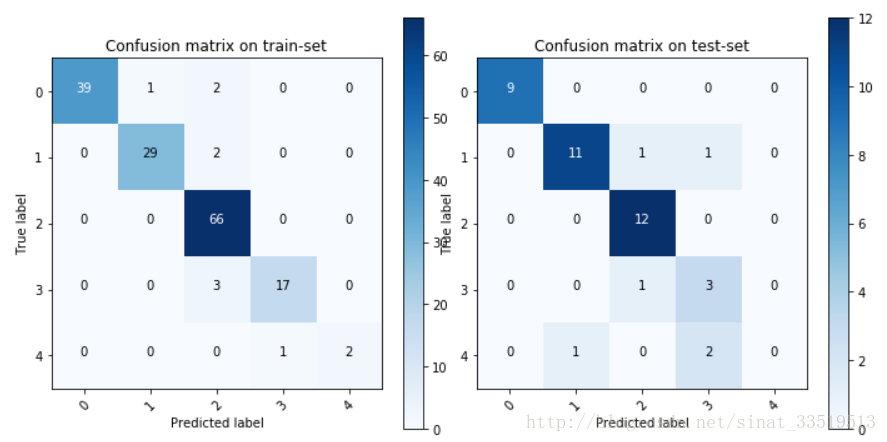
支持向量机在训练集上的准确率有93.3%,但其在测试集上的准确率却只有79.5%。说明模型方差较大,可能存在过拟合。
但是由于我们前面将数据进行了打乱,因此每一次运行的结果都有所不同,经几次运行,在测试集上的准确率最高的达到92.68%,这应该与数据量的限制有关系。
这说明支持向量机模型对于水质评价分类效果较好,但是数据量太少,需要更多的数据,这样才能得到更为稳定的结果。
最后,这一章的实践较为简单,但支持向量机的理论部分还是需要好好理解,其应用还是非常广泛的。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









