







 本文回顾了2015年至2018年间关于句子分布式嵌入向量的典型文献,涵盖无监督方法(如词向量均值组合和神经网络编码器)以及有监督方法(依赖下游NLP任务)。通过对比不同方法的步骤和效果,为句向量学习提供参考。
本文回顾了2015年至2018年间关于句子分布式嵌入向量的典型文献,涵盖无监督方法(如词向量均值组合和神经网络编码器)以及有监督方法(依赖下游NLP任务)。通过对比不同方法的步骤和效果,为句向量学习提供参考。
作者:王小草
背景介绍
最近对句子的分布式嵌入向量做了些许调研,前程往事自不必多提,未来之事也无需多虑,本文只聚焦于2015年-2018年最近4年最为典型的文献予以介绍和推荐,若读者在工作中有接触和应用更好的方法,跪求您给我留言建议哦,不胜感激。
词嵌入或词表征,是用具有语义相似性的向量来表征自然语言中的词语。以此类推,句子嵌入或句子表征,就是用向量来表征自然语言中的句子,使得向量中携带着句子的语义信息,从而可以被计算机计算和使用。词句披上表征自己含义的向量,游刃于计算机,如同灵魂裹在相由心生的皮囊来往于人世间。
可以将句字嵌入向量的方法分成3大类:
1.无监督-对预训练好词向量进行均值组合得到句向量(本文介绍4篇文献)
2.无监督-对预训练好的词向量通过神经网络编码器得到句向量(本文介绍2篇文献)
3.有监督-对预训练好的词向量通过神经网络编码器+下游有监督的NLP任务进行联合训练得到能产出句向量的编码器(本文介绍2篇文献)
类别一:无监督–对词向量进行均值组合得到句向量
该类别的套路是,先预训练好词向量(一般使用CBOW,Skip-gram,Glove3类经典的方法);然后通过对句子中词的词向量求对应维度上的均值得到相同维度的句向量。直接求算数平均是最基本最简单最粗暴的方法,效果也是不差的,但也总有可以进步的地方,于是下面要介绍的3篇文献都是对如何求均值做了些许改进,从而提高了句向量的质量。
文献一
题目: Siamese CBOW: Optimizing Word Embeddings for Sentence Representations
作者: Tom Kenter1 Alexey Borisov1, 2 Maarten de Rijke1
机构: University of Amsterdam, Yandex, Moscow
时间: 2016
源码: https://bitbucket.org/TomKenter/siamese-cbow.
该文提出Siamese Continuous Bag of Words (Siamese CBOW)模型,一种求sentence embedding的高效神经网络。它对已经训练好的word embedding进行fine tunning,使得利用优化后的词向量通过求均值生成的句向量能有更好的效果。
步骤:
1.预训练好词向量
2.构建神经网络(如下图)
输入:一个source sentence
输出:两个上下文 sentence, 两个nagtive sentence
(1)输入source sentence中的每个词
(2)在预训练的词嵌入矩阵中得到每个词的词向量
(3)将每个词的词向量求均值,表征句子向量
(4)句子向量输入cosine simirayty层,分别计算source sentence和输出层中的4个sentence的余弦相似度
(5)然后进入softmax层,计算概率分布
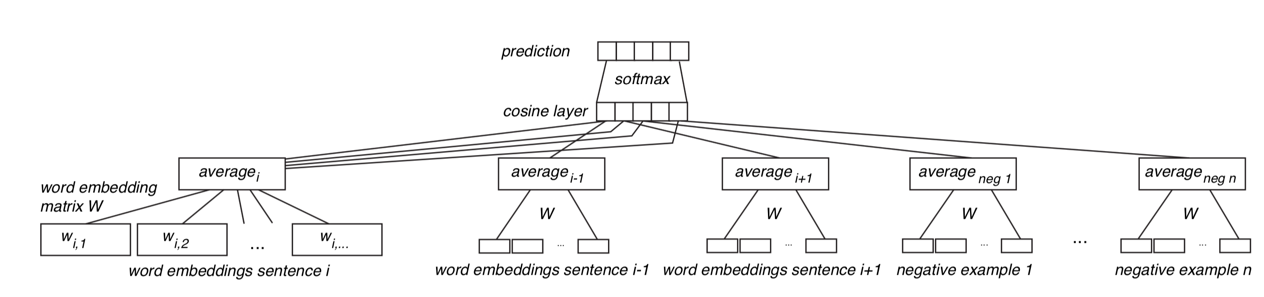
3.通过以上训练得到了新的词向量,用该词向量去求均值计算句向量。
效果:
作者拿word2vec skipgram, word2vec CBOW, skip-thought3者作为basline来和本文提出的模型在20个数据集上作比较,大部分情况下本文的Siamese CBOW模型取得了最好的效果。
文献二
题目:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6045
6045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









