







adaboost算法
adaboost是boosting方法中的一种,主要思想是提高分类错误的样本的权值,降低分类正确样本的权值。这样做的方法存在两个问题
第一,如何更新样本权值
第二,如何组合成一个强分类器
带着这些问题来看算法的具体步骤:
输入:训练集数据;以及弱学习算法
输出:强分类器
1.初始化训练数据的权值
在这里设为1/N
2.遍历1-m
a.使用具有权值分布的训练数据训练分类器
b.计算该分类器的分类误差
Em
c.计算该分类器的系数(权重)
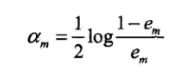
在这个系数的构建就可以看出其分类器的系数与分类正确率正相关。分类越正确那么该分类器的权重越高。
d.更新数据集的权重
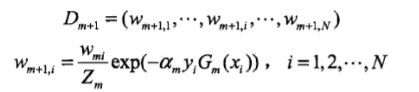
更新w的过程就是,构造一个函数使得分类错误的样本权重更大并且使得权重标准化
3.弱分类器线性组合成强分类器
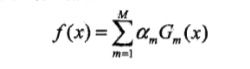
前向分步算法
考虑一个加法模型有:
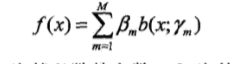
那么给定一个损失函数L()
最小化损失函数
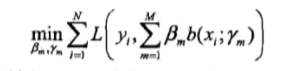
由于学习的是加法模型
可以每次只学习一个基函数以及其系数,慢慢减少误差。那么每步只需要对一个基函数进行优化,从而减少大量的计算:
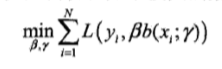
说完总体思路来看看其具体算法:
输入:训练集,损失函数,基函数集
输出:加法模型
1.初始化加法模型等于0
2.遍历1-M
a.极小化损失函数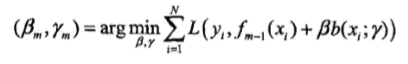
得到参数beta和yita
b.更新加法模型
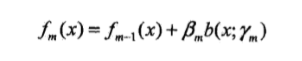
3.加总得到最终分类器</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









