







 超级会员免费看
超级会员免费看
 本文介绍了语音处理中的分帧技术,详述了分帧过程中帧长、重叠长度和帧移的概念,并探讨了如何在处理后重组语音,避免重复并减少丢弃的数据对结果的影响。通过stft处理的示例,展示了重组语音的过程。
本文介绍了语音处理中的分帧技术,详述了分帧过程中帧长、重叠长度和帧移的概念,并探讨了如何在处理后重组语音,避免重复并减少丢弃的数据对结果的影响。通过stft处理的示例,展示了重组语音的过程。
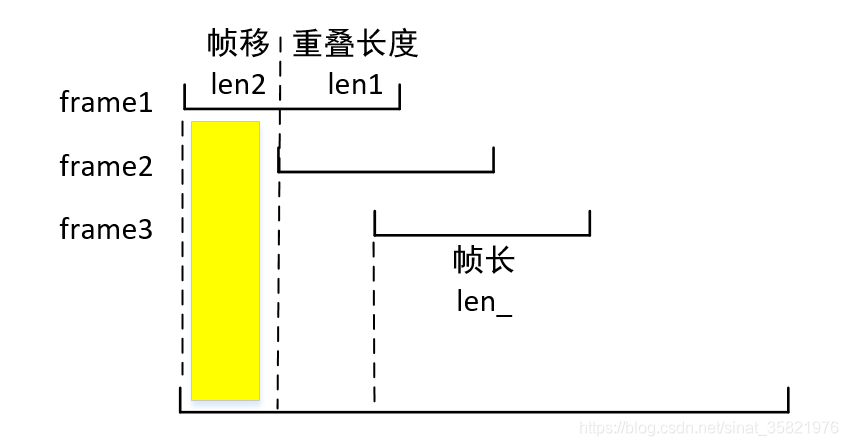
我们在对语音信号进行处理的时候经常需要对语音进行分帧,而在分帧的过程中帧与帧之间会有一些重叠部分。在对每一帧处理之后我们需要将语音还原成原来的形式。下面详细说明语音分帧过程及如何还原重组语音。
如下图所示,在分帧过程中,帧长为len_,重叠长度为len1, 帧移为len2。在对语音信号处理后,我们会得到一个帧长为len_的处理后的语音帧,如果我们将这个整个帧重组原始语音的话,在处理后的第二帧里面有部分与第一帧重叠。为了避免这种重复带来的问题,如果语音长度恰好可以将帧长整除,我们在重组语音过程中每次只写入长度为len2的语音,即填充黄色区域对应的数据即可,其实可以发现语音帧有部分被丢弃了,这部分占很少的一部分对语音处理影响不大。
下面以stft处理为例给出代码:
import librosa
from basic_functions import *
x, fs = librosa.load("D:\\Samples\\1.wav", sr=8000)
k = 0
nfft = 512
len_ = 240 # 帧长
len1 &
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









