







 超级会员免费看
超级会员免费看
CUDA介绍及入门
- CUDA介绍
- CUDA应用
- CUDA开发环境
- 在Windows、Linux和macOS上安装CUDA工具包
- 使用CUDA开发简单的C程序
1. CUDA介绍
- 计算机统一设备架构(Computer Unified Device Architecture,CUDA)是由英伟达(NVIDIA)开发的一套非常流行的并行计算平台和编程模型,它只支持英伟达显卡
- OpenCL则用来为其他类型的GPU编写并行代码,比如AMD和英特尔,但它比CUDA更加复杂,CUDA可以使用简单的编程API在图像处理单元(GPU)上创建大规模并行应用程序
- 用CUDA编写的程序类似与简单的C或C++编写的程序,就是需要添加利用GPU并行处理的关键字,并且CUDA允许程序员指定CUDA代码的哪个部分在CPU上运行,哪个部分在GPU上运行
1.1. 并行处理
-
假设你被告知要在很短的时间内挖一个很大的洞,你会有以下三种方法以及时完成这项工作:
- 你可以挖得更快
- 你可以买一把更好的铲子
- 你可以雇佣更多的挖掘机,它们可以帮助你完成工作
-
第三种选择类似与拥有许多可以并行执行复杂任务的更强大的处理器,CUDA遵循这种计算方式,它不是一个可以执行复杂任务的更强大的处理器,而是有许多小而简单的且可以并行工作的处理器。
1.2. GPU架构和CUDA介绍
- CPU具有复杂的控制硬件和较少的数据计算硬件,复杂的控制硬件在性能上提供了CPU的灵活性和一个简单的编程接口,但是就功耗而言,这是昂贵的。而另一方面,GPU具有简单的控制硬件和更多的数据计算硬件,使其具有并行计算的能力,这种结构使它更节能,缺点时它有一个更严格的编程模型。
- 一般来说,任何硬件架构的性能都是根据延迟和吞吐量来衡量的,延迟指的是完成给定任务所花费的时间,而吞吐量时给定时间内所完成的任务量。
- 正常的串行CPU被设计为优化延迟,而GPU被设计为优化吞吐量。CPU被设计为在最短时间内完成所有指令,而GPU被设计为在给定的时间内执行更多指令,它的这种设计理念使其在图像处理和计算机视觉中十分有用
- 如果我们想在相同的时钟速度和功率要求下提高计算性能,那么并行计算即使我们所需要的。GPU通过让更多简单的计算单元并行工作来提高这种能力。而为了与GPU交互,利用这种并行计算能力,则需要一个有CUDA提供的简单的并行编程架构
1.3. CUDA架构
-
CUDA包含一个unified shedder管道,它允许GPU芯片上的所有算数逻辑单元(ALU)被一个CUDA程序编组。ALU还被设计成符合IEEE浮点单精度和双精度标准,因此它可以用于通用应用程序。指令集也适合与一般用途的计算,而不是特定于像素计算,他还允许对内存的任意读写访问,这些特性使CUDA架构在通用应用程序中非常有用
-
所有的GPU都有许多被称为核心(Core)的并行处理单元。在硬件方面,这些核心被分为流处理器和流多处理器,GPU有这些流多处理器的网格。在软件方面,CUDA程序作为一系列并行运行的多线程(Thread)来执行的。每个线程都在不同的核心上执行,可以将GPU看作多个块(Block)的组合,每个块可以执行多个线程,每个块绑定到GPU上的不同流多处理器。来自同一个块的线程可以相互通信,GPU有一个分层的内存结构,处理一个块和多个块内线程之间的通信
-
CUDA C程序的开发步骤如下:
- 1)为主机(Host)和设备(Device)显存中的数据分配内存
- 2)将数据从主机内存复制到设备显存
- 3)通过指定并行度来启动内核
- 4)所有线程完成后,将数据从设备显存复制回主机内存
- 5)释放主机和设备上使用的所有内存
2. CUDA应用
CUDA被广泛应用于如下领域:
- 计算机视觉应用
- 医学成像
- 金融计算
- 生命科学、生物信息学和计算化学
- 天气研究和预报
- 电子设计自动化(EDA)
- 政府和国防
3. CUDA开发环境
支持CUDA的GPU
英伟达显卡程序
标准C编译器
CUDA开发工具包
4. 一个基本的CUDA程序
- 打卡Visual Statio 2019
- 新建项目 opencv_cuda
- 新建.cu文件并编写代码
- 配置项目属性并编译:右键项目->生成自定义->生成依赖项->选择cuda版本
- 右键.cu文件属性:常规->项类型->CUDA C/C++
- 右键项目->生成解决方案,执行程序即可
- 下边放一个小例子:
#include <iostream>
#include <stdio.h>
__global__ void myfirstkernel(void)
{
}
int main(void) {
myfirstkernel << <1, 1 >> > ();
printf("Hello, CUDA!\n");
return 0;
}
---- 输出:
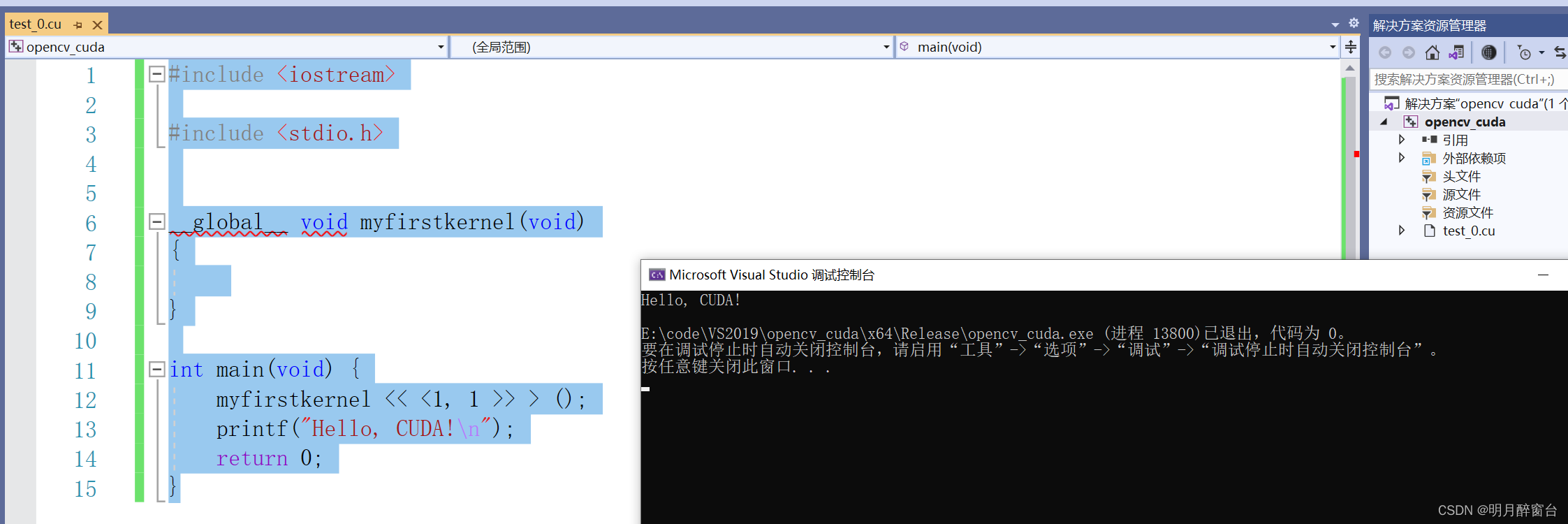
-
上述简单的CUDA例程,与用简单C编写的代码相比,有两个重要的区别:
- 一个名为 myfirstkernel 的空函数,前缀为 global
- 使用 <<1,1>> 调用 myfirstkernel 函数
- __global__是CUDA C在标准C中添加的一个限定符,它告诉编译器在这个限定符后边的函数定义应该在设备上而不是在主机上运行。
- <<1,1>> 内的之表示我们希望在运行时从主机传递给设备的参数,基本上,它表示块的数量和将在设备上并行运行的线程数。因此在上述代码中,它表示myfirstkernel将运行在设备上的一个块和一个线程上。
















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











