







 FLCert是一种新的联邦学习框架,它可以证明对恶意客户端的中毒攻击具有安全性。通过将客户端分组并使用多数投票策略,FLCert能够在有限数量的恶意客户端存在的情况下,保证测试输入预测标签的正确性。该框架包括概率版本FLCert-P和确定性版本FLCert-D,分别提供概率和确定性的安全保证。实验表明,FLCert在多个数据集和基础FL算法上有效抵御了中毒攻击,提供了认证的准确性保证。
FLCert是一种新的联邦学习框架,它可以证明对恶意客户端的中毒攻击具有安全性。通过将客户端分组并使用多数投票策略,FLCert能够在有限数量的恶意客户端存在的情况下,保证测试输入预测标签的正确性。该框架包括概率版本FLCert-P和确定性版本FLCert-D,分别提供概率和确定性的安全保证。实验表明,FLCert在多个数据集和基础FL算法上有效抵御了中毒攻击,提供了认证的准确性保证。
摘要
由于其分布式性质,联邦学习容易受到中毒攻击,其中恶意客户端通过操纵其本地训练数据和/或发送到云服务器的本地模型更新来毒害训练过程,从而使中毒的全局模型错误地分类许多不分青红皂白的测试输入或攻击者选择的输入。现有的防御主要利用拜占庭式的联合学习方法或检测恶意客户端。但是,这些防御措施没有针对中毒攻击的可证明的安全保证,并且可能容易受到更高级的攻击。在这项工作中,我们的目标是通过提出FLCert来弥合差距,FLCert是一个集成的联合学习框架,可以证明可以安全地抵御有限数量的恶意客户端的中毒攻击。我们的主要思想是将客户划分为组,使用任何现有的联邦学习方法为每组客户端学习全局模型,并在全局模型中获得多数票以对测试输入进行分类。具体来说,我们考虑了两种对客户端进行分组的方法,并相应地提出了两种 FLCert 变体,即 FLCert-P 在每个组中随机采样客户端,以及 FLCert-D 确定性地将客户端划分为不相交组。我们在多个数据集上的大量实验表明,我们的 FLCert 为测试输入预测的标签可证明不受有限数量的恶意客户端的影响,无论它们使用何种中毒攻击。
一、引言
联邦学习(FL)[18],[23]是一种新兴的机器学习范式,它使客户(例如,智能手机,物联网设备和组织)能够协作学习模型,而无需与云服务器共享其本地训练数据。由于其承诺保护客户本地培训数据的隐私以及新兴的隐私法规,如通用数据保护条例(GDPR),FL已被行业部署。例如,谷歌已经在Android Gboard上部署了FL用于下一个单词预测。现有的FL方法主要遵循单一全局模型范式。具体来说,云服务器维护一个全局模型,每个客户端维护一个本地模型。全局模型通过客户端和服务器之间的多次通信迭代进行训练。在每次迭代中,执行三个步骤:1)服务器将当前全局模型发送给客户端;2)客户端根据全局模型和本地训练数据更新本地模型,并将模型更新发送到服务器;3) 服务器聚合模型更新并使用它们来更新全局模型。然后使用学习的全局模型来预测测试输入的标签。
然而,这种单一全局模型范式容易受到中毒攻击。特别是,攻击者可以将假客户端注入 FL 或破坏正版客户端,我们称假客户端为恶意客户端。例如,攻击者可以使用功能强大的计算机来模拟许多假冒智能手机。此类恶意客户端可以通过仔细篡改发送到服务器的本地训练数据或模型更新来破坏全局模型。因此,损坏的全局模型对于正常测试输入 [6]、[10](称为非靶向中毒攻击)或某些攻击者选择的测试输入 [2]、[3](称为靶向中毒攻击)的准确性较低。例如,在非目标中毒攻击中,恶意客户端可以通过操纵其本地模型更新来偏离全局模型,使其与在没有攻击的情况下更新的方向相反[10]。在有针对性的中毒攻击中,当学习图像分类器时,恶意客户端可以在其本地训练数据中将带有某些条带的汽车重新标记为鸟类,并扩展发送到服务器的模型更新,以便全局模型错误地将带有条带的汽车预测为鸟 [2]。
已经提出了各种拜占庭稳健的FL方法来防御来自恶意客户端的中毒攻击。[4], [5], [32]。这些方法的主要思想是减轻客户模型更新中统计异常值的影响。它们可以绑定在没有恶意客户端的情况下学习的全局模型参数与在某些客户端变得恶意时学习的全局模型参数之间的差异。但是,这些方法无法证明测试输入的全局模型预测的标签不受恶意客户端的影响。事实上,研究表明,恶意客户端仍然可以通过仔细篡改发送到服务器的模型更新来大幅降低拜占庭鲁棒方法学习的全局模型的测试准确性[3],[6],[10]。
A. 我们的工作
在这项工作中,我们提出了FLCert,这是第一个可以证明对中毒攻击安全的FL框架。具体来说,给定n 客户,我们定义N 组,每个组都包含客户端的一个子集。特别是,我们设计了两种对客户端进行分组的方法,对应于FLCert的两个变体,即FLCert-P和FLCert-D,其中P和D分别代表概率和确定性。在 FLCert-P 中,每个N 组包括k 从n 客户端统一随机。请注意,总共有(nk) 可能的组,因此N 可以和(nk) 在 FLCert-P.在 FLCert-D 中,我们将n 客户进入N 确定性地不相交组。
对于每个组,我们使用任意 FL 算法(称为基本 FL 算法)与组中的客户端学习全局模型。总的来说,我们训练N 全球模型。给定测试输入x ,我们使用每个N 预测其标签的全局模型。我们表示n我 作为预测标签的全局模型的数量我 为x 并定义p我=n我n 哪里i=1,2,⋯,L .
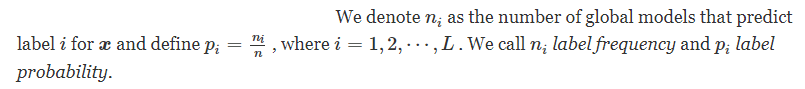 我们的集成全局模型预测标签频率/概率最大的标签x .换句话说,我们的集成全局模型在N 用于预测标签的全局模型x .由于每个全局模型都是使用客户端子集学习的,因此当大多数客户端是良性的时,大多数全局模型都是使用良性客户端学习的。因此,多数票标签中的N 测试输入的全局模型不受有限数量的恶意客户端的影响,无论它们使用何种中毒攻击。
我们的集成全局模型预测标签频率/概率最大的标签x .换句话说,我们的集成全局模型在N 用于预测标签的全局模型x .由于每个全局模型都是使用客户端子集学习的,因此当大多数客户端是良性的时,大多数全局模型都是使用良性客户端学习的。因此,多数票标签中的N 测试输入的全局模型不受有限数量的恶意客户端的影响,无论它们使用何种中毒攻击。
B. 理论
我们的第一个主要理论结果是,FLCert 可证明地预测了测试输入的相同标签x 当恶意客户端的数量不大于阈值时,我们称之为认证安全级别。我们的第二个主要理论结果是,我们证明了我们派生的认证安全级别是严格的,即,当没有对基础FL算法做出假设时,不可能推导出比我们更大的认证安全级别。请注意,对于不同的测试输入,认证安全级别可能不同。
C. 算法
计算我们认证的安全级别x 需要其最大和第二大标签频率/概率。对于 FLCert-P,当(nk) 很小(例如,n 客户是数十个组织[17]和k 很小),我们可以通过训练精确地计算最大和第二大标签概率N=(nk) 全球模型。但是,在以下情况下准确计算它们具有挑战性(nk) 很大。为了应对计算挑战,我们开发了一种随机算法,通过训练以概率保证来估计它们N≪(nk) 全球模型。由于这种随机性,FLCert-P实现了概率安全保证,即FLCert-P为测试输入输出不正确的认证安全级别,其概率可以设置为任意小。对于FLCert-D,我们训练N 全局模型并确定性地获取标签频率,使FLCert-D的安全保证具有确定性。
D. 评价
我们在来自不同领域的五个数据集上实证评估了我们的方法,包括三个图像分类数据集(MNIST-0.1 [20],MNIST-0.5 [20]和CIFAR-10 [19]),人类活动识别数据集(HAR)[1]和下一个单词预测数据集(Reddit)[2]。我们将MNIST和CIFAR中的训练示例分发给客户端以模拟FL场景,而HAR和Reddit数据集代表真实世界的FL场景,其中每个用户都是一个客户端。我们还评估了五种不同的基本FL算法,即FedAvg [23],Krum [4],Trimmed-mean[32],Median [32]和FLTrust [5]。此外,我们使用认证的准确性作为我们的评估指标,这是无论恶意客户端使用何种中毒攻击,方法都可以证明达到的测试准确性的下限。例如,我们的FLCert-D与FedAvg和N=500 当训练示例均匀分布在 81,1 个客户端且其中 000 个是恶意客户端时,可以在 MNIST 上达到 100% 的认证准确率。
总之,我们的主要贡献如下:
-
我们提出了FLCert,一个具有可证明的安全保证的FLCert框架,可以防止中毒攻击。具体来说,FLCert-P 提供概率安全保证,而 FLCert-D 提供确定性保证。此外,我们证明我们派生的认证安全级别是严格的。
-
我们提出了一种随机算法来计算FLCert-P的认证安全级别。
-
我们在来自不同领域的多个数据集和多个基本 FL 算法上评估 FLCert。我们的结果表明,FLCert在理论上和经验上都对中毒攻击是安全的。
二、相关工作
A. 联邦学习
客户端和服务器协作以迭代方式解决优化问题。具体来说,在训练过程的每次迭代中,执行以下三个步骤:1)服务器将当前全局模型广播给(子集)客户端;2)客户端将其本地模型初始化为接收的全局模型,使用随机梯度下降训练局部模型,并将本地模型更新发送回服务器;3)服务器聚合本地模型更新并更新全局模型。
B. 对FL的中毒攻击
最近的研究[2],[3],[6],[10],[24],[27]表明FL容易受到中毒攻击。 根据攻击者的目标,对FL的中毒攻击可以分为两类:非靶向中毒攻击[6],[10],[24],[27]和有针对性的中毒攻击[2],[3]。
1)非针对性中毒攻击:
非靶向中毒攻击的目标是降低学习到的全局模型的测试准确性。这些攻击旨在尽可能提高全局模型的不分青红皂白的测试错误率,这可以被视为拒绝服务(DoS)攻击。根据攻击的执行方式,非靶向中毒攻击有两种变体,即数据中毒攻击 [27] 和本地模型中毒攻击 [6]、[10]。数据中毒攻击会篡改恶意客户端上的本地训练数据,同时假设计算过程保持完整性。他们注入虚假的训练数据点,删除现有的训练数据点,和/或修改现有的训练数据点。本地模型中毒攻击篡改恶意客户端的计算过程,即直接篡改恶意客户端的本地模型或发送到服务器的模型更新。请注意,在 FL 中,任何数据中毒攻击都可以通过本地模型中毒攻击来实现。这是因为在每个恶意客户端上,我们始终可以将使用篡改的本地训练数据集训练的本地模型视为被篡改的本地模型。
C. 防御对FL中毒攻击
已经提出了许多防御措施[8],[14],[15],[16],[21],[22],[26],[28],[29],[30],以应对集中学习场景中的数据中毒攻击。 但是,它们不足以防御对FL的中毒攻击。特别是,经验防御[8],[22],[30]需要有关训练数据集的知识,出于隐私考虑,FL服务器通常无法使用这些知识。此外,可证明安全的防御 [14]、[15]、[16]、[21]、[26]、[28]、[29] 可以保证为测试输入预测的标签不受有限数量的中毒训练示例的影响。 但是,在 FL 中,单个恶意客户端可以毒害任意数量的本地训练示例,从而打破其假设。
拜占庭稳健的FL方法[4],[5],[32]利用拜占庭稳健的聚合规则来抵抗中毒攻击。他们分享了在聚合本地模型更新时减轻中毒攻击引起的统计异常值的影响的想法。例如,Krum [4] 选择具有最小平方欧几里得距离分数的单个模型更新作为新的全局模型更新;修剪平均值 [32] 计算修剪后模型更新参数的坐标平均值,并使用相应的平均值更新全局模型;中位数 [32] 通过计算局部模型更新的坐标中位数来更新全局模型;FLTrust [5] 利用一个小型干净数据集来计算服务器更新,并将其用作基线来引导对本地模型更新的信任。这些方法都有一个关键限制:它们无法提供可证明的安全保证,即,当存在中毒攻击时,它们无法确保用于测试输入的全局模型的预测标签保持不变。
另一种类型的防御侧重于检测恶意客户端并在聚合之前删除其本地模型 [10], [25], [33]。Shen等人[25]建议在本地模型上执行聚类以检测恶意客户端。Fang et al. [10] 提出了两种防御措施,即使用验证数据集根据它们对验证数据集上评估的错误率或损失值的影响来拒绝潜在的恶意本地模型。Zhang等人[33]提出通过检查模型更新的一致性来检测恶意客户端。这些防御在检测恶意客户端方面显示出一些经验有效性。但是,它们也无法提供可证明的安全保证。
Wang等人[28]提出了一种经过认证的后门攻击防御措施。最近的一项工作[31]将这种方法扩展到FL,并称之为CRFL。CRFL旨在证明针对特定后门攻击的鲁棒性[2],其中所有恶意客户端都使用后门本地训练数据集训练其本地模型,并在一次FL迭代中同时将其模型更新发送到服务器之前扩展其模型更新。他们表明,如果恶意客户端本地训练数据的变化幅度有限,则可以证明在这种特定攻击下学习的全局模型的准确性。但是,恶意客户端可以任意更改其本地训练数据。因此,单个恶意客户端可以通过使用中毒攻击而不是被视为特定的后门攻击来破坏其防御。相反,无论恶意客户端执行何种攻击,我们的 FLCert 都是可证明安全的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









