







前言
本次比赛前期花费的时间精力很多,但是到后期陷入了瓶颈,无法再提高精度。单纯修改优化模型的收益比不上挖掘特征的收益,并且训练时间很长。而且到后期很难再挖出新的有效的特征来,有些有效的特征组合再一起,效果反而变差了。由于后期事务繁多,也没有时间继续研究了,成绩不是很好,但是这个过程还是收益颇多,所以写博客记录下来。
比赛背景
任务
开发一个模型,该模型能够使用来自订单簿和股票收盘竞价的数据来预测数百只纳斯达克上市股票的收盘价走势。
评估
预测值和目标值的平均绝对误差 (MAE):
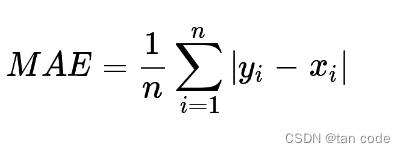
数据说明
-
stock_id - 股票的唯一标识符。
-
date_id - 日期的唯一标识符。日期ID在所有股票中都是连续的和一致的。
-
imbalance_size - 以当前参考价格(美元计)不匹配的金额。
-
imbalance_buy_sell_flag- 反映竞价失衡方向的指标。
买方失衡;1
卖方失衡;-1
无不平衡;0 -
reference_price - 成对份额最大化、不平衡最小化以及与买卖中点的距离最小化的价格,按此顺序排列。也可以认为等于最佳买入价和卖出价之间的近价。
-
matched_size - 可以按当前参考价格(美元)匹配的金额。
-
far_price - 仅根据拍卖利息最大化匹配的股票数量的交叉价格。此计算不包括连续市价单。
-
near_price- 交叉价格,将最大化基于竞价和连续市价订单匹配的股票数量。
-
[bid/ask]_price- 非拍卖账簿中最具竞争力的买入/卖出水平的价格。
-
[bid/ask]_size- 非拍卖账簿中最具竞争力的买入/卖出水平的美元名义金额。
-
wap- 非拍卖账簿中的加权平均价格。
-
seconds_in_bucket- 自当天收盘竞价开始以来经过的秒数,始终从 0 开始。
-
target- 股票波动的 60 秒未来走势减去合成指数的 60 秒未来走势。 仅供训练组使用。
- 综合指数是Optiver为本次比赛构建的纳斯达克上市股票的定制加权指数。
- 目标的单位是基点,这是金融市场中常见的计量单位。1个基点的价格变动相当于0.01%的价格变动。
- 其中 t 是当前观测值的时间,我们可以定义目标:
前面是从网站上copy来的,可能需要一点电子订单簿,电子交易过程的前置知识。由于不是重点,就不赘述。
下面进入代码,结合代码说明一些做法
1.初始化的相关工作
1.1 导入库,设置flag
import gc
import os
import time
import warnings
from itertools import combinations
from warnings import simplefilter
import joblib
import lightgbm as lgb
import numpy as np
import pandas as pd
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import KFold, TimeSeriesSplit
import polars as pl
warnings.filterwarnings("ignore")
simplefilter(action="ignore", category=pd.errors.PerformanceWarning)
is_offline = False
LGB = True
NN = False
is_train = True
is_infer = True
max_lookback = np.nan
split_day = 435
由于训练和提交,是不同的代码,我们提前训练好后模型后,直接把这个模型进行提交,用来预测,不需要在提交后重新训练,所以用 is_train, is_infer, is_offline这几个标志来进行相关的控制。
1.2 加载数据和预处理
df = pd.read_csv("/kaggle/input/optiver-trading-at-the-close/train.csv")
df = df.dropna(subset=["target"])
df.reset_index(drop=True, inplace=True)
df_shape = df.shape
这里缺失数据有多种处理方法,比如用均值填充,填充为了0等等,我尝试过构建模型,将不缺少的部分作为训练集,缺失部分作为目标,用训练的模型得到的结果来填充,但是效果不佳。
1.3 内存优化
本次数据集相当大,如果没有使用内存优化,会导致训练过程中内存用完的情况出现。
主要的思想是,将一些像double等所占内存大的类型,在保证精度的前提下,转换成所占内存小的类型,例如:
double a = 1 ----> int a = 1
def reduce_mem_usage(df, verbose=0):
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float32)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float32)
if verbose:
logger.info(f"Memory usage of dataframe is {
start_mem:.2f} MB")
end_mem = df.memory_usage().sum() / 1024**2
logger.info(f"Memory usage after optimization is: {
end_mem:.2f} MB")
decrease = 100 * (start_mem - end_mem) / start_mem
logger.info(f"Decreased by {
decrease:.2f}%")
return df
从上面也能总结出一些内存相关函数的使用方法
start_mem = df.memory_usage().sum() / 1024**2
1.4 并行计算
为了提高计算速度,减少模型运行时间,采用并行计算,这里只对 imbalance采用了,原因是在python中并行计算的一些限制。
from numba import njit, prange
@njit(parallel=True)
def c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











