









 本文详细介绍了如何在不同电脑间迁移已配置好的TensorFlow和PyTorch环境,包括查看现有环境、查询包位置、替换lib文件及激活环境的步骤。通过此教程,用户可以在新设备上快速恢复深度学习开发环境。
本文详细介绍了如何在不同电脑间迁移已配置好的TensorFlow和PyTorch环境,包括查看现有环境、查询包位置、替换lib文件及激活环境的步骤。通过此教程,用户可以在新设备上快速恢复深度学习开发环境。
相关文章:
【一】tensorflow安装、常用python镜像源、tensorflow 深度学习强化学习教学
【二】tensorflow调试报错、tensorflow 深度学习强化学习教学
trick1---实现tensorflow和pytorch迁移环境教学
tensorflow和pytorch迁移环境教学,实现奖已创建好的pytorch和tensorflow编译环境包到别的电脑上去,并进行激活使用。
- 第一步:查看现有虚拟环境,看编译环境下有没有tensorflow和torch,如果有将已配置好的包lib所有内容拷贝备份即可。
激活环境
conda activate tf2
python or ipythonimport tensorflow
import torch- 第二步 查询tensorflow和pytorch包的位置
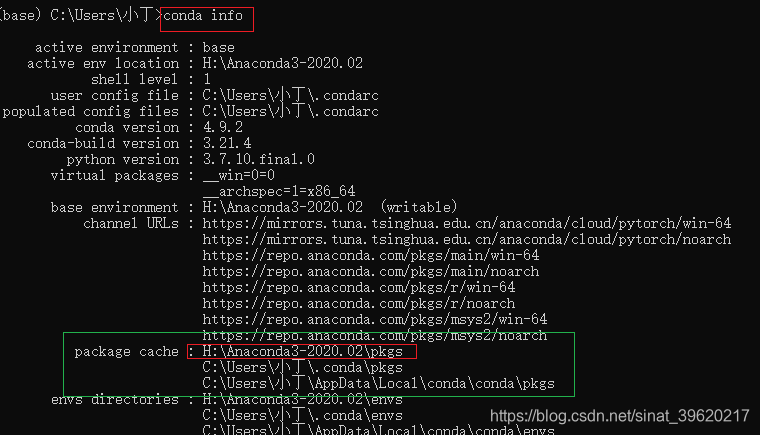
看到对应的编译环境
- 第三步 查询版本和路径
(base) C:\Users\xxx>conda activate tf2
(tf2) C:\Users\xxx>python
Python 3.7.10 (default, Feb 26 2021, 13:06:18) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow
2021-04-06 21:00:46.661044: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2021-04-06 21:00:46.664907: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
>>> import torch
>>> import tensorflow as tf
>>> print(tf.__version__)
2.4.1
>>> print(torch.__version__)
1.5.1
>>> print(torch.__path__)
['H:\\Anaconda3-2020.02\\envs\\tf2\\lib\\site-packages\\torch']
>>> print(tf.__path__)
['H:\\Anaconda3-2020.02\\envs\\tf2\\lib\\site-packages\\tensorflow', 'H:\\Anaconda3-2020.02\\envs\\tf2\\lib\\site-packages\\tensorflow_estimator\\python\\estimator\\api\\_v2', 'H:\\Anaconda3-2020.02\\envs\\tf2\\lib\\site-packages\\tensorboard\\summary\\_tf', 'H:\\Anaconda3-2020.02\\envs\\tf2\\lib\\site-packages\\tensorflow', 'H:\\Anaconda3-2020.02\\envs\\tf2\\lib\\site-packages\\tensorflow\\_api\\v2']-
第四步:替换lib文件下的所有内容 (注意:如果你怕报错就把原来的更换一下名字,以免以后找不回)
在第二台电脑中找到anaconda的编译环境或者创建的虚拟环境文件目录,替换lib即可
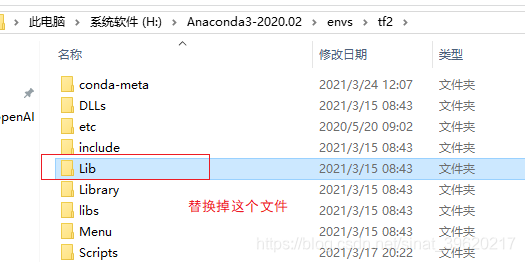
注意:保险做法可以先重命名为Lib_old 先放着
- 第五步 重新打开终端激活环境
将复制到第二台电脑的包lib文件放置在tensorflow编译环境中,并进行激活:显然,成功激活。
重复第一步和第三步看看激活成功了不。
具体快速安装可见下面链接有详细安装教程。
https://blog.csdn.net/sinat_39620217/article/details/115462155?spm=1001.2014.3001.5501


















 3853
3853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











