







1. LiteLLM快速使用
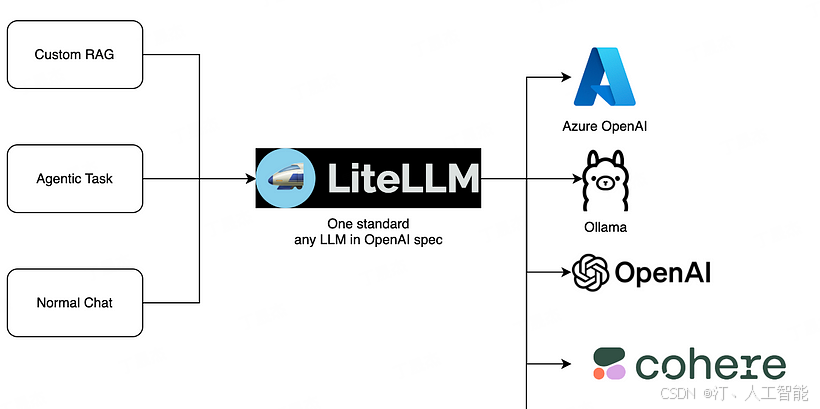
LiteLLM 是一个 Python 库,旨在简化多种大型语言模型(LLM)API 的集成。通过支持来自众多提供商的超过 100 种 LLM 服务,它使用户能够使用标准化的 OpenAI API 格式与这些模型进行交互。提供商包括 Azure、AWS Bedrock、Anthropic、HuggingFace、Cohere、OpenAI、Ollama 和 Sagemaker 等主要品牌。
LiteLLM 代理 是 LiteLLM 模型 I/O 库的关键组件,旨在标准化对 Azure、Anthropic 和 OpenAI 等多种语言模型服务的 API 调用。作为中间件,LiteLLM 代理通过提供统一的接口简化了与多个 LLM API 的交互。它管理 API 密钥,处理错误回退,记录请求和响应,跟踪令牌使用和消费,并提供缓存和速率限制等功能。
LiteLLM 为主流的模型服务提供统一的调用方式。功能包括:
- 标准化接口:调用超过 100 种 LLM 模型,提供统一的输入 / 输出格式。
- 接口转换:支持将输入翻译成提供商的文本生成、嵌入和图像生成端点。
- 多部署重试 / 后备机制:可以在多个部署(如 Azure/OpenAI)之间重试或切换。
- 预算和速率限制:可为项目、API 密钥或模型设置预算和速率限制。
- 跟踪开销:可监控项目花费,并设置预算限制。
1.1 安装
通过 pip 安装:
pip install litellm
如果希望将 LiteLLM 服务部署成类似 OneAPI的形式,并带有 UI 管理界面,则用以下方式进行安装:
git clone https://github.com/BerriAI/litellm.git
cd litellm
pip install 'litellm[proxy]'
启动服务:
litellm
可参阅完整的参数文档:CLI Arguments
1.2 配置文件
为 litellm 添加下游模型并设置转发规则,参考文档:
配置文件中有五个主要设置:
项目仓库下的 proxy_server_config.yaml 提供了完整的示例配置文件。以下示例用于配置 Hugging Face 模型:
model_list:
- model_name: bce-embedding-base_v1
litellm_params:
model: huggingface/maidalun1020/bce-embedding-base_v1 # 自动路由到 Hugging Face
api_key: hf_... # Hugging Face API 密钥
- model_name: Meta-Llama-3-8B-Instruct
litellm_params:
model: huggingface/meta-llama/Meta-Llama-3-8B-Instruct
api_key: hf_...
- model_name: llama3:latest
litellm_params:
model: ollama/llama3
api_base: http://localhost:11434
- model_name: gemma2:latest
litellm_params:
model: ollama/gemma2
api_base: http://localhost:11434
general_settings:
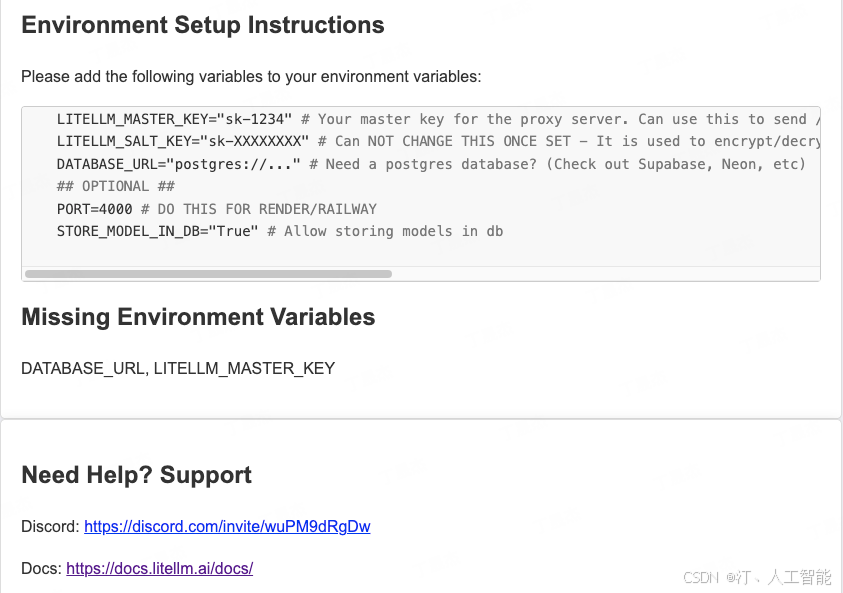
master_key: "sk-1234" # 代理服务器的管理密钥,可用于发送 /chat/completion 请求等
database_url: "postgresql://<user>:<password>@localhost:5432/postgres" # 需要 PostgreSQL 数据库吗?(可以查看 Supabase、Neon 等)
store_model_in_db: true # 允许在数据库中存储模型
参数说明:
master_key作为调用的密钥,也作为管理员的登录密码store_model_in_db保存在线的模型修改database_urlUI 界面的管理需要数据库支持
运行命令:litellm — config litellm-config.yml
此配置为 LiteLLM 代理 定义了要使用的模型列表,并详细指定了每个模型的信息。model_list 包含三个模型:llama3:latest、gemma2:latest 和 mistral:latest。每个条目都有 litellm_params,提供了 LiteLLM 与这些模型交互所需的参数。model 参数标识了托管在 Ollama 上的特定模型版本,而 api_base 参数设置了 API 请求指向的本地端点(http://localhost:11434)。此设置确保 LiteLLM 代理能够正确路由和处理这些模型的请求。
使用 http://0.0.0.0:4000/ui 登录管理仪表盘,您将看到以下内容。
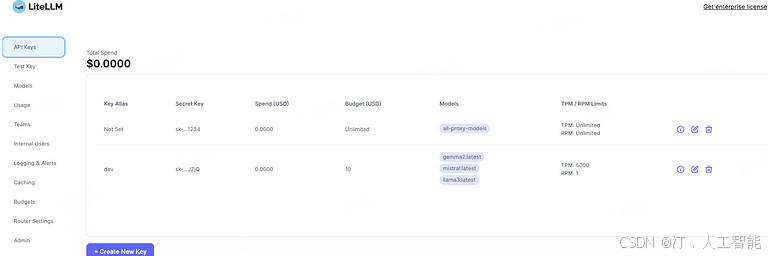
LiteLLM 仪表盘的一些重要功能如下。
1.2.1 API 密钥
LiteLLM 中的 API 密钥 部分允许用户管理其访问密钥,提供对其使用和预算的详细控制。用户可以创建新密钥、设置别名,并指定消费限额。此外,他们可以为每个密钥分配不同的模型,并定义每分钟令牌数(TPM)和每分钟请求数(RPM)的限制。界面还包括设置最大预算和密钥过期时间的选项。这种细粒度控制确保在使用 LiteLLM 通过各种 LLM 时,资源和成本得到高效管理。
1.2.2 模型
LiteLLM 中的 模型 标签提供了对各种语言模型的全面管理功能。用户可以轻松添加、配置和监控模型。用户可以为不同的模型(如 llama3:latest)设置特定的重试策略,通过指定针对 BadRequestError 或 TimeoutError 等错误的重试次数。该标签还提供分析功能,展示每个模型的平均延迟每令牌和异常等指标。此外,它支持详细配置,例如设置 API 基础 URL、每分钟令牌数(TPM)、每分钟请求数(RPM)以及每个模型的其他参数,确保模型管理的稳健性和可定制性。
1.2.3 路由器设置
LiteLLM 中的路由器设置标签提供了广泛的选项,用于配置请求的处理和路由方式。在负载均衡下,用户可以设置路由策略、允许的失败次数、失败后的冷却时间、重试次数和超时值。回退部分允许设置备用模型,以确保主模型失败时服务的连续性。常规标签管理并行请求限制,指定每个 API 密钥的最大并行请求数和代理实例的全局并行请求数。这些设置确保了 LLM 应用中请求的高效和可靠处理。
有许多功能可供选择,但一个重要的安全功能是防护栏,以下是如何在 LiteLLM 配置中设置默认防护栏的方法。(需要企业账户才能使用此功能)
model_list:
- model_name: llama3:latest
litellm_params:
model: ollama/llama3
api_base: http://localhost:11434
- model_name: gemma2:latest
litellm_params:
model: ollama/gemma2
api_base: http://localhost:11434
- model_name: mistral:latest
litellm_params:
model: ollama/mistral
api_base: http://localhost:11434
litellm_settings:
guardrails:
- prompt_injection: # 防护栏的自定义名称
callbacks: [lakera_prompt_injection] # 使用的litellm回调
default_on: true # 当为true时,将对所有llm请求运行
- pii_masking: # 防护栏的自定义名称
callbacks: [presidio] # 使用litellm的presidio回调
default_on: false # 默认情况下,所有请求都关闭
- hide_secrets_guard:
callbacks: [hide_secrets]
default_on: false
- your-custom-guardrail
callbacks: [hide_secrets]
default_on: false
给定的 LiteLLM 配置定义了多个防护栏,以确保与大型语言模型交互的安全和合规性。每个防护栏指定了一个自定义名称和相关的回调函数,以处理特定任务。
-
prompt_injection:使用
lakera_prompt_injection回调,默认启用,以防止提示注入攻击。 -
pii_masking:使用
presidio回调来屏蔽个人身份信息(PII),但默认情况下是禁用的。 -
hide_secrets_guard:使用
hide_secrets回调,同样默认禁用。 -
your-custom-guardrail:一个自定义防护栏的示例,使用
hide_secrets回调,默认禁用。
1.3 Docker 配置
如果希望避免手动配置 Python 环境和数据库,官方提供了 Docker 部署方式。文档:Docker 部署。
以下是个人经过调整并验证有效的 docker-compose.yaml:
version: "3.9"
services:
db:
image: postgres:latest
container_name: litellm_db
volumes:
- ./pgdata:/var/lib/postgresql/data
env_file:
- .env
litellm:
build:
context: .
args:
target: runtime
image: ghcr.io/berriai/litellm:main-latest
depends_on:
- db
ports:
- "4000:4000"
volumes:
- ./litellm-config.yaml:/app/config.yaml
command: [ "--config", "/app/config.yaml", "--port", "4000", "--num_workers", "8", "--detailed_debug" ]
env_file:
- .env
.env 文件的内容:
# Postgres 配置
POSTGRES_USER=
POSTGRES_PASSWORD=
POSTGRES_DB=
# LiteLLM 配置
LITELLM_MASTER_KEY="" # 主密钥,用于代理服务器
UI_USER # UI 界面的用户名
UI_PASSWORD="" # UI 界面的密码
STORE_MODEL_IN_DB='True'
# 默认端口 5432,用户名密码需与上面的 POSTGRES_USER 和 POSTGRES_PASSWORD 一致
DATABASE_URL="postgresql://<user>:<password>@<host>:<port>/<dbname>"
2.基于LiteLLM实现RAG
2.1 集成与实现
这是一个通过 LiteLLM 代理连接到 Azure OpenAI 的简单 RAG 示例。
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.azure_openai import AzureOpenAI
from llama_index.core import SimpleDirectoryReader, ServiceContext, VectorStoreIndex
'''
以下是LiteLLM配置示例。
model_list:
- model_name: azure-gpt-3.5
model: azure/azure-gpt-3.5 ### 发送到`litellm.completion()`的模型名称 ###
api_base: https://my-endpoint-useeast-mantha-868.openai.azure.com/
api_key: "YOUR_AZURE_API_KEY" # 使用os.getenv("YOUR_AZURE_API_KEY")
rpm: 6 # [可选] 此部署的速率限制:每分钟请求数(rpm)
'''
embed_model = OllamaEmbedding(model_name='mxbai-embed-large:latest', base_url='http://localhost:11434')
llm = AzureOpenAI(
engine="azure-gpt-3.5", # LiteLLM代理上的模型名称
temperature=0.0,
azure_endpoint="http://localhost:4000", # LiteLLM代理端点
api_key="sk-DdYGeoO7PoanQYWSP_JZjQ", # LiteLLM代理API密钥
api_version="2023-07-01-preview",
)
documents = SimpleDirectoryReader("product_manual_data", required_exts=['.pdf']).load_data()
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()
response = query_engine.query("将产品规格转换为JSON格式")
print(response)
2.2 使用 Qdrant 混合检索和 LiteLLM 代理 API 的自定义 RAG
qdrant_ops.py
import json
from qdrant_client import QdrantClient, models
from utils.decorator_utils import execution_time_decorator
class HybridQdrantOperations:
def __init__(self):
self.payload_path = "../data.json"
self.collection_name = "hybrid-multi-stage-queries-collection"
self.DENSE_MODEL_NAME = "snowflake/snowflake-arctic-embed-s"
self.SPARSE_MODEL_NAME = "prithivida/Splade_PP_en_v1"
# 连接到我们的Qdrant服务器
self.client = QdrantClient(url="http://localhost:6333", api_key="YOUR_KEY")
self.client.set_model(self.DENSE_MODEL_NAME)
# 注释此行以仅使用密集向量
self.client.set_sparse_model(self.SPARSE_MODEL_NAME)
self.metadata = []
self.documents = []
def load_data(self):
with open(self.payload_path) as fd:
for line in fd:
obj = json.loads(line)
self.documents.append(obj.pop("description"))
self.metadata.append(obj)
def create_collection(self):
if not self.client.collection_exists(collection_{self.collection_name}"):
self.client.create_collection(
collection_{self.collection_name}",
vectors_config=self.client.get_fastembed_vector_params(),
# 注释此行以仅使用密集向量
sparse_vectors_config=self.client.get_fastembed_sparse_vector_params(on_disk=True),
optimizers_config=models.OptimizersConfigDiff(
default_segment_number=5,
indexing_threshold=0,
),
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(always_ram=True),
),
shard_number=4
)
@execution_time_decorator
def insert_documents(self):
self.client.add(
collection_name=self.collection_name,
documents=self.documents,
metadata=self.metadata,
parallel=5, # 如果值为0,则使用所有可用CPU核心进行数据编码
)
# self._optimize_collection_after_insert()
@execution_time_decorator
def hybrid_search(self, text: str, top_k: int = 5):
# self.client.query 如果需要对过滤数据进行查询,也会包含过滤器
search_result = self.client.query(
collection_name=self.collection_name,
query_text=text,
limit=top_k, # 返回最接近的5个结果
)
# `search_result` 包含找到的向量ID及其相似度分数,以及存储的有效负载
# 选择并返回元数据
metadata = [hit.metadata for hit in search_result]
return metadata
def _optimize_collection_after_insert(self):
self.client.update_collection(
collection_name=f'{self.collection_name}',
optimizer_config=models.OptimizersConfigDiff(indexing_threshold=30000)
)
if __name__ == '__main__':
ops = HybridQdrantOperations()
# 仅在首次创建集合并希望导入数据时运行以下代码
ops.load_data()
ops.create_collection()
ops.insert_documents()
# results = ops.hybrid_search(text="What are the gaming companies in bangalore?", top_k=10000)
# print(results)
custom_rag.py
import json
from qdrant_ops import HybridQdrantOperations
from utils.decorator_utils import execution_time_decorator
import requests
class StartupRAG:
def __init__(self, retriever: HybridQdrantOperations = HybridQdrantOperations()):
self.retriever = retriever
def _fetch_context(self, user_query: str = None):
context_retrieved = self.retriever.hybrid_search(text=user_query, top_k=3)
print(f"context_retrieved: {context_retrieved}")
return context_retrieved
@execution_time_decorator
def completion(self, str_or_query: str = None):
context = self._fetch_context(user_query=str_or_query)
rag_prompt_tmpl = (
"以下是上下文信息。\n"
"---------------------\n"
f"{json.dumps(context)}\n"
"---------------------\n"
"根据提供的上下文信息,请一步一步地回答查询,如果不知道答案,请说'我不知道!'。\n"
f"查询: {str_or_query}\n"
"答案: "
)
llm_response = self._call_litellm(content=rag_prompt_tmpl)
return llm_response
def _call_litellm(self, content: str):
url = "http://0.0.0.0:4000/chat/completions"
payload = {
"model": "ollama/gemma2",
"temperature": 0.8,
"max_tokens": 100,
"messages": [
{
"role": "user",
"content": f"{content}"
}
]
}
headers = {"Content-Type": "application/json", "Authorization": "Bearer sk-DdYGeoO7PoanQYWSP_JZjQ",}
resp = requests.request("POST", url, json=payload, headers=headers)
return resp.text
if __name__ == "__main__":
rag = StartupRAG()
# 启动一个循环,持续获取用户输入
while True:
# 获取用户查询
user_query = input("输入你的查询 [输入'bye'或'exit'退出]: ")
# 检查用户是否要终止循环
if user_query.lower() == "bye" or user_query.lower() == "exit":
break
response = rag.completion(str_or_query=user_query)
print(response)
utility.py
import time
from functools import wraps
def execution_time_decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
execution_time = end_time - start_time
print(f"执行时间 for {func.__name__}: {execution_time:.6f} 秒")
return result
return wrapper



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











