






Train分布式训练
仅仅把模型训练任务分散到不同机器上跑,这只是分布式训练的冰山一角。要真正驾驭大规模机器学习,我们需要更强大的工具。今天,我们就来聊聊Ray Train,这个专门用于分布式训练的利器。在座的各位都是专业人士,肯定深有体会:机器学习模型训练,尤其是深度学习,那真是个“甜蜜的负担”。为什么这么说呢?
- 一方面,模型越来越复杂,参数量巨大,训练时间动辄数小时甚至数天。
- 另一方面,数据量呈指数级增长,单台机器内存根本装不下,更别说高效处理了。
- 还有,模型本身也在不断膨胀,比如现在流行的超大模型,单机内存更是捉襟见肘。
这三种情况,哪个都足以让我们的训练任务卡在原地。面对这些挑战,我们有两种主要的分布式策略。
- 第一种是数据并行。你可以想象成,把整个数据集切成几份,每份数据都喂给一个独立的模型副本。每个模型都独立计算,然后通过某种机制,比如梯度同步,把结果汇总起来,更新模型。这种方法特别适合数据量大的情况,能有效缩短训练时间。
- 另一种是模型并行。这种方式更复杂,它把模型本身拆分成很多小块,每个小块在不同的机器上运行,最后再把结果拼起来。这通常用于处理那些极其庞大的模型,比如现在流行的Transformer模型,单个模型可能就超过几十亿参数。当然,模型并行的通信开销会比较大,实现起来也更复杂。
Ray Train,它的定位非常明确,就是专注于数据并行。它不是要解决所有分布式问题,而是要成为数据并行训练的效率之王。Ray Train 的核心价值在于提供了一套高效、易用且可扩展的工具链,让你能够轻松地在 Ray 集群上进行大规模的分布式训练。它不仅支持 PyTorch、TensorFlow 等主流框架,还深度集成 Ray 生态系统,比如 Ray Actors、Ray Tune、Ray Datasets。
核心组件
它的核心组件包括
- Trainers,负责具体的训练逻辑;
- Predictors,用于模型预测;
- Preprocessors,处理数据预处理;
- Checkpoints,实现训练状态的保存和恢复。
咱们再细看一下 Ray Train 的核心组件。
- 首先是 Trainers,这是最核心的部分。它就像一个瑞士军刀,把各种主流的训练框架,比如 PyTorch, TensorFlow, XGBoost, LightGBM,都封装进来了。更重要的是,它把这些框架和 Ray 的核心能力,比如分布式计算、资源调度、超参数调优、数据集管理,无缝地整合在一起。你只需要关注你的训练逻辑,其他的分布式细节,Ray Train 都帮你搞定。
- 训练好模型之后,就需要 Predictors。它负责批量预测,可以用来评估模型在验证集上的表现,甚至可以加速模型部署到生产环境。
- Preprocessors 用于数据预处理,这是提升模型性能的关键一步,而且 Ray Train 提供了内置的预处理器,也支持自定义。
- Checkpoints 则保证了训练的连续性和可恢复性,万一训练中断了,可以从上次保存的 Checkpoint 恢复。
理论讲完了,咱们来看点实际的。我们用一个经典的案例来演示 Ray Train 的威力:预测纽约出租车行程是否会产生高额小费。我们用的是公开的纽约市出租车数据集,目标是判断一个行程的小费是否超过票价的20%。
简单的 PyTorch 神经网络示例
我们会用一个简单的 PyTorch 神经网络来完成这个任务。整个流程会非常贴近实际:先加载数据,做预处理,提取特征;然后定义模型,用 Ray Train 进行分布式训练;最后,把训练好的模型应用到新的数据上。这个例子会用到 Ray Datasets 和 Dask on Ray,但别担心,这些工具都是通用的,Ray Train 的核心能力是跨框架的。
import ray
from ray.util.dask import enable_dask_on_ray
import dask.dataframe as dd
LABEL_COLUMN = "is_big_tip"
FEATURE_COLUMNS = ["passenger_count", "trip_distance", "fare_amount",
"trip_duration", "hour", "day_of_week"]
enable_dask_on_ray()
def load_dataset(path: str, *, include_label=True):
columns = ["tpep_pickup_datetime", "tpep_dropoff_datetime", "tip_amount",
"passenger_count", "trip_distance", "fare_amount"]
df = dd.read_parquet(path, columns=columns)
df = df.dropna()
df = df[(df["passenger_count"] <= 4) &
(df["trip_distance"] < 100) &
(df["fare_amount"] < 1000)]
df["tpep_pickup_datetime"] = dd.to_datetime(df["tpep_pickup_datetime"])
df["tpep_dropoff_datetime"] = dd.to_datetime(df["tpep_dropoff_datetime"])
df["trip_duration"] = (df["tpep_dropoff_datetime"] -
df["tpep_pickup_datetime"]).dt.seconds
df = df[df["trip_duration"] < 4 * 60 * 60] # 4 hours.
df["hour"] = df["tpep_pickup_datetime"].dt.hour
df["day_of_week"] = df["tpep_pickup_datetime"].dt.weekday
if include_label:
df[LABEL_COLUMN] = df["tip_amount"] > 0.2 * df["fare_amount"]
df = df.drop(
columns=["tpep_pickup_datetime", "tpep_dropoff_datetime", "tip_amount"]
)
return ray.data.from_dask(df).repartition(100)
第一步,数据加载和预处理。我们使用 Dask on Ray,它结合了 Dask 的并行计算能力和 Ray 的分布式调度能力,非常适合处理大规模数据。我们用熟悉的 Dask DataFrame API 来操作数据,然后通过 enable_dask_on_ray 将它与 Ray 集群连接起来。预处理过程包括:首先,用 Dask 的 read_parquet 读取 Parquet 文件;然后,进行一些基本的清洗,比如去除缺失值、过滤掉异常值;接着,进行特征工程,比如从时间戳中提取出小时、星期几等特征;计算出我们的标签,也就是是否为高额小费;最后,将处理好的数据转换为 Ray Dataset 的格式,这样就能方便地传入到 Ray Train 的训练流程中了。
import torch
import torch.nn as nn
import torch.nn.functional as F
class FarePredictor(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(6, 256)
self.fc2 = nn.Linear(256, 16)
self.fc3 = nn.Linear(16, 1)
self.bn1 = nn.BatchNorm1d(256)
self.bn2 = nn.BatchNorm1d(16)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.bn1(x)
x = F.relu(self.fc2(x))
x = self.bn2(x)
x = torch.sigmoid(self.fc3(x))
return x
数据准备好了,接下来是模型定义和训练。我们定义了一个简单的三层神经网络,叫 FarePredictor。输入层有6个特征,经过两层隐藏层,最终输出一个0到1之间的概率值,用Sigmoid函数实现。我们还加入了Batch Normalization,这有助于提高模型训练的稳定性,尤其是在分布式环境下。
trainer = TorchTrainer(
train_loop_per_worker=train_loop_per_worker,
train_loop_config={
"lr": 1e-2, "num_epochs": 3, "batch_size": 64
},
scaling_config=ScalingConfig(num_workers=1, resources_per_worker={"CPU": 1, "GPU": 0}),
datasets={
"train": load_dataset("nyc_tlc_data/yellow_tripdata_2020-01.parquet")
},
)
result = trainer.fit()
trained_model = result.checkpoint
训练的核心是 Ray Train 的 TorchTrainer。我们只需要告诉它:训练逻辑是 train_loop_per_worker 函数,数据集是 train,我们希望用多少个 worker,每个 worker 用多少 GPU。TorchTrainer 会自动处理数据并行、模型同步、梯度计算等所有细节。我们只需要在 train_loop_per_worker 中,用 iter_torch_batches 来迭代数据,用 session.report 来报告训练指标,比如 loss,以及用 TorchCheckpoint 来保存模型状态。
from ray.air import session
from ray.air.config import ScalingConfig
import ray.train as train
from ray.train.torch import TorchCheckpoint, TorchTrainer
def train_loop_per_worker(config: dict):
batch_size = config.get("batch_size", 32)
lr = config.get("lr", 1e-2)
num_epochs = config.get("num_epochs", 3)
dataset_shard = session.get_dataset_shard("train")
model = FarePredictor()
dist_model = train.torch.prepare_model(model)
loss_function = nn.SmoothL1Loss()
optimizer = torch.optim.Adam(dist_model.parameters(), lr=lr)
for epoch in range(num_epochs):
loss = 0
num_batches = 0
for batch in dataset_shard.iter_torch_batches(
batch_size=batch_size, dtypes=torch.float
):
labels = torch.unsqueeze(batch[LABEL_COLUMN], dim=1)
inputs = torch.cat(
[torch.unsqueeze(batch[f], dim=1) for f in FEATURE_COLUMNS], dim=1
)
output = dist_model(inputs)
batch_loss = loss_function(output, labels)
optimizer.zero_grad()
batch_loss.backward()
optimizer.step()
num_batches += 1
loss += batch_loss.item()
session.report(
{"epoch": epoch, "loss": loss},
checkpoint=TorchCheckpoint.from_model(dist_model)
)
这就是刚才提到的 train_loop_per_worker 函数的代码。它接收一个 config 参数,里面可以包含 batch size、学习率、epoch 数等。然后,它会从 session 中获取当前 worker 的数据分片 dataset_shard。接着,创建模型 FarePredictor,然后调用 train.torch.prepare_model 将模型适配到分布式训练环境。之后,就是标准的 PyTorch 训练循环:初始化损失函数、优化器,然后在一个 epoch 内,遍历数据分片,计算损失、反向传播、更新参数。注意,这里用的是 dataset_shard.iter_torch_batches,这是 Ray Train 提供的,可以直接在 Dask DataFrame 上迭代出 PyTorch Tensor。每 epoch 结束,用 session.report 报告当前的 epoch 和 loss,同时用 TorchCheckpoint.from_model 保存模型状态。
我们来总结一下 Trainer 的核心概念。所有 Ray Train 的 Trainer 都共享一个通用接口,最常用的就是点fit方法,调用它就启动了训练过程。训练完成后,可以通过点checkpoint属性获取训练结果,比如最终的模型权重。Ray Train 提供了针对不同框架的 Trainer,比如 TorchTrainer、XGBoostTrainer、LightGBMTrainer 等等,你可以根据自己的模型选择合适的 Trainer。
配置一个 Trainer,你需要指定三个关键要素:
- 训练逻辑,也就是train_loop_per_worker函数;
- 数据集,通常是Ray Dataset;
- 规模配置,也就是ScalingConfig,用来告诉 Ray Train 你需要多少个 worker,以及是否需要使用 GPU。
Ray Train 的一个巨大优势就是,它能让你在几乎不改动原有代码的情况下,就能轻松迁移你的训练任务到分布式环境。关键在于 prepare_model 这个函数。
from ray.train.torch import prepare_model
def distributed_training_loop():
model = NeuralNetwork()
model = prepare_model(model)
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(num_epochs):
train_one_epoch(model, loss_fn, optimizer)
你只需要在创建你的 PyTorch 模型后,调用 prepare_model(model),模型就会自动被适配成可以在分布式环境中运行的版本。看看这个 distributed_training_loop 函数,它和我们之前写的 training_loop 函数几乎一模一样,唯一的区别就是多了一行 model = prepare_model(model)。
Ray Train 就是通过这种方式,把底层的分布式通信、进程管理、模型同步等等复杂的事情都封装起来了,让你专注于业务逻辑。Ray Train 的扩展性非常强大。它通过 ScalingConfig 这个类来定义你的训练规模。你可以直接指定需要多少个 worker,num_workers,是否需要使用 GPU,use_gpu。这种配置方式是声明式的,你不需要关心底层的硬件细节,比如有多少台机器、多少个 GPU。你只需要根据你的任务需求,告诉 Ray Train 你需要多少计算资源,它就会自动帮你调度。比如,你可以配置 num_workers=200,use_gpu=True,Ray Train 就会尝试在你的集群上找到 200 个 GPU worker 来运行你的训练任务。这使得你的训练能够随着集群资源的增加而弹性扩展,非常方便。数据预处理是机器学习中至关重要的一环,它直接影响模型的性能。
Ray Train 提供了 Preprocessor 这个核心类来处理数据预处理。它内置了多种常用的预处理器,比如 StandardScaler、MinMaxScaler、OneHotEncoder,可以直接拿来用。当然,你也可以根据自己的需求自定义预处理器。每个 Preprocessor 都有 transform、fit、fit_transform 和 transform_batch 这些标准的 API,方便你进行数据转换。预处理的主要作用是标准化数据,比如缩放、编码,这能显著提升模型的性能。更重要的是,通过预处理,我们可以确保训练和部署服务时使用相同的数据处理逻辑,从而解决训练-服务偏差这个常见的问题。而且,由于预处理器是可序列化的,你可以方便地将它们打包起来,用于模型部署。
如何使用 Preprocessor 呢?非常简单!你只需要创建一个 Preprocessor 实例,然后把它传递给 Trainer 的构造函数。比如,trainer = XGBoostTrainer(preprocessor=StandardScaler(…))。这样,Ray Train 就会自动在训练数据进入模型之前,调用这个 Preprocessor 的 transform 方法进行处理。你不需要手动去调用 transform,Ray Train 已经帮你处理好了。
对于那些需要在训练时计算全局统计量(比如均值、标准差)的预处理器,比如 StandardScaler,Ray Train 会自动在分布式环境下并行计算这些统计量,然后再应用到每个 worker 的数据上。这样,你就可以保证训练和部署时使用一致的预处理逻辑,避免了训练-服务偏差。而且,由于 Preprocessor 是可序列化的,你可以用 pickle.dumps 将它保存下来,方便后续的模型部署和推理。超参数调优,也就是 HPO,是提升模型性能的另一个关键环节。
Ray Train 提供了与 Ray Tune 的深度集成,让你可以轻松地进行超参数调优。Ray Tune 是一个非常强大的自动化超参数调优框架,它可以帮助你自动搜索最佳的超参数组合,从而找到性能最好的模型。Ray Train 和 Ray Tune 的结合,简直是天作之合。你可以用几行代码,就把你的 Trainer 和 Ray Tune 的 Tuner 组合起来,实现自动化的 HPO。
Ray Tune 的优势在于它的鲁棒性,它能处理训练失败的情况,保证 HPO 的可靠性。而且,Ray Tune 还能动态调整训练规模,比如根据当前的超参数配置,自动调整 worker 数量,进一步优化训练效率。我们来看一个简单的 Ray Tune 超参数调优的例子。
import ray
from ray.air.config import ScalingConfig
from ray import tune
from ray.data.preprocessors import StandardScaler, MinMaxScaler
dataset = ray.data.from_items(
[{"X": x, "Y": 1} for x in range(0, 100)] +
[{"X": x, "Y": 0} for x in range(100, 200)]
)
prep_v1 = StandardScaler(columns=["X"])
prep_v2 = MinMaxScaler(columns=["X"])
param_space = {
"scaling_config": ScalingConfig(
num_workers=tune.grid_search([2, 4]),
resources_per_worker={
"CPU": 2,
"GPU": 0,
},
),
"preprocessor": tune.grid_search([prep_v1, prep_v2]),
"params": {
"objective": "binary:logistic",
"tree_method": "hist",
"eval_metric": ["logloss", "error"],
"eta": tune.loguniform(1e-4, 1e-1),
"subsample": tune.uniform(0.5, 1.0),
"max_depth": tune.randint(1, 9),
},
}
首先,我们需要定义一个参数空间,也就是 param_space。在这个例子中,我们定义了几个超参数的范围,比如学习率 eta,我们用 tune.loguniform 采样对数均匀分布的值,范围从 10的负4次方到 10的负1次方;subsample 用 tune.uniform 采样均匀分布,范围是 0.5 到 1.0;max_depth 用 tune.randint 采样随机整数,范围是 1 到 9。我们还使用了 tune.grid_search,让 Ray Tune 在不同的预处理器之间进行网格搜索。
from ray.train.xgboost import XGBoostTrainer
from ray.air.config import RunConfig
from ray.tune import Tuner
trainer = XGBoostTrainer(
params={},
run_config=RunConfig(verbose=2),
preprocessor=None,
scaling_config=None,
label_column="Y",
datasets={"train": dataset}
)
tuner = Tuner(
trainer,
param_space=param_space,
)
results = tuner.fit()
然后,我们创建一个 Tuner 实例,把我们的 Trainer 和参数空间传给它。最后,调用 tuner.fit() 就可以启动超参数调优过程了。Ray Tune 会自动创建多个 Trial,每个 Trial 都会用一个不同的超参数组合来训练一个新模型,然后比较它们的性能,最终找到最优的超参数组合。
训练过程中,我们通常希望实时监控训练的进展,比如 loss、accuracy 等指标。Ray Train 提供了 Callbacks 机制来实现这一点。Callbacks 就像训练过程中的插件,可以在训练的不同阶段被触发,比如在每个 epoch 开始或结束时,或者在训练过程中。你可以用 Callbacks 来记录日志,比如把训练指标写入文件,或者发送到监控平台。
Ray Train 内置了对一些常用框架的集成,比如 TensorBoard、MLflow。你可以直接用 TBXLoggerCallback 或 MLFlowLoggerCallback 将训练日志记录到 TensorBoard 或 MLflow 中,方便你进行可视化分析和实验追踪。当然,你也可以自定义自己的 Callback,实现更复杂的监控逻辑。
在线推理
现在我们把目光转向另一个关键领域——如何高效地部署和运行这些训练好的模型,特别是那些需要实时响应的应用。这就是我们今天要讨论的在线推理。
什么是在线推理?简单来说,就是让机器学习模型像一个随时待命的API一样,直接响应用户的请求。这跟我们之前在离线场景下批量处理数据、预测结果完全不同。在线推理的核心在于实时性,它要求模型能够快速响应,不能有延迟。想想那些需要即时反馈的场景,比如你刷短视频时,平台会根据你的实时观看行为推荐下一个视频,这就是在线推理的典型应用。推荐系统绝对是在线推理的重头戏。无论是电商平台给你推荐商品,还是社交媒体给你推送感兴趣的内容,背后都离不开在线推理。为什么必须实时?因为用户的心意是瞬息万变的!你今天喜欢这个,明天可能就喜欢那个了。
系统必须能捕捉到用户最新的行为和偏好,比如刚浏览了某个商品,或者刚点赞了某个话题,然后立刻做出推荐。这种基于实时数据的个性化推荐,极大地提升了用户体验。再来看聊天机器人。大家现在用的很多在线客服,背后可能就是AI驱动的聊天机器人。它们可以24小时在线,大大降低了人工客服的成本和响应时间。但这可不是简单的文字匹配,一个合格的聊天机器人需要理解复杂的语言,理解用户意图,甚至进行多轮对话。这背后需要整合多种机器学习技术,比如自然语言处理、情感分析、知识图谱等,而且必须实时响应,才能提供流畅的用户体验。还有我们每天都在用的到达时间预测,比如滴滴、导航、外卖App。它们告诉你司机大概多久到,或者你的外卖多久送到。这看似简单,实则非常复杂。它不仅要考虑固定路线,还要实时追踪路况、天气变化、突发事故等等。而且,这个预测不是一成不变的,而是会随着行程不断更新。没有在线推理,靠人工编写规则,根本无法应对这种复杂性。
在线推理的关键特性
这些在线应用,无论推荐、聊天还是预测,都指向一个共同点:对延迟的极致要求。对于普通用户来说,等待时间长了,体验就差了;但对于自动驾驶、机器人控制这些领域,延迟可能直接关系到安全和效率。所以,低延迟是在线推理的生命线。我们的目标就是在保证模型准确性和服务稳定性的前提下,把响应时间压到最低。为什么在线推理这么难搞?一个关键原因就是机器学习模型本身是计算密集型的。想想传统的Web服务器,大部分请求是读写数据库,I/O操作为主。
但机器学习,尤其是深度学习,本质上是大量的线性代数运算,比如矩阵乘法、卷积运算。这跟传统计算模式很不一样。特别是现在模型越来越深,参数越来越多,对计算能力的要求也越来越高。这也是为什么GPU、TPU这些专门为AI加速的硬件变得越来越重要。除了计算量大,另一个大问题就是成本。很多在线服务,比如电商、社交媒体,都需要7x24小时运行。你想想,一个计算密集型的模型,全天候不停地跑,这得消耗多少CPU和GPU资源?如果模型本身复杂,再加上需要持续运行,那成本简直是天文数字。所以,如何在保证低延迟的同时,尽可能地降低成本,就成了在线推理系统必须解决的核心难题。
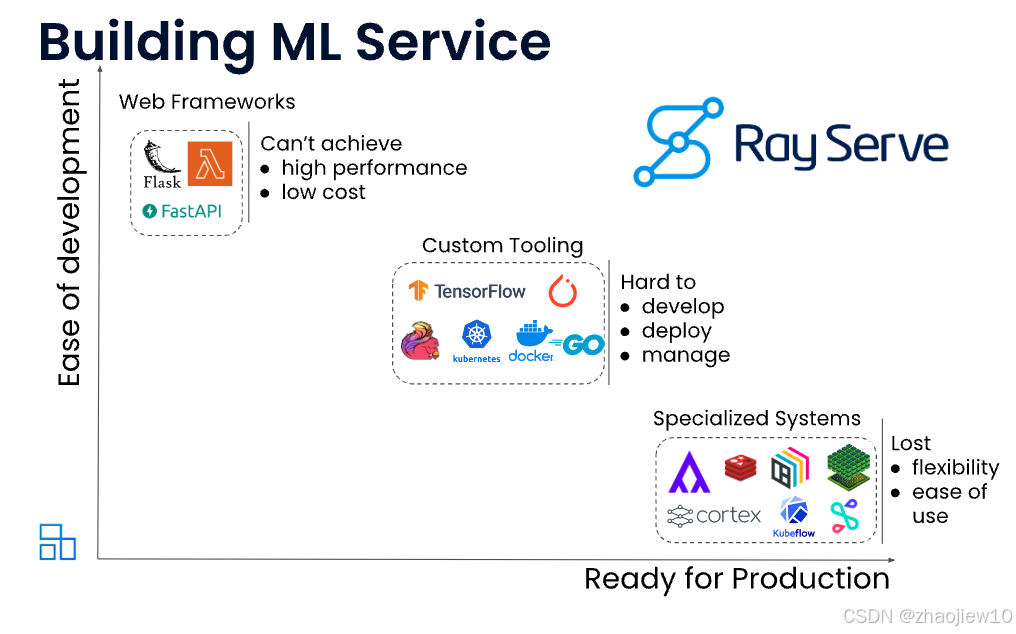
面对这些挑战,Ray Serve应运而生。它是一个构建在Ray之上的、专门为服务机器学习模型设计的可扩展计算层。Ray Serve最大的特点就是灵活,它不挑食,不绑定特定的机器学习框架,无论是TensorFlow、PyTorch还是其他模型,只要是Python代码,它都能处理。更重要的是,它能让你把模型和各种业务逻辑,比如数据验证、规则过滤、结果组合等等,无缝地组合在一起,构建一个完整的在线服务。这正是它解决在线推理挑战的关键所在。
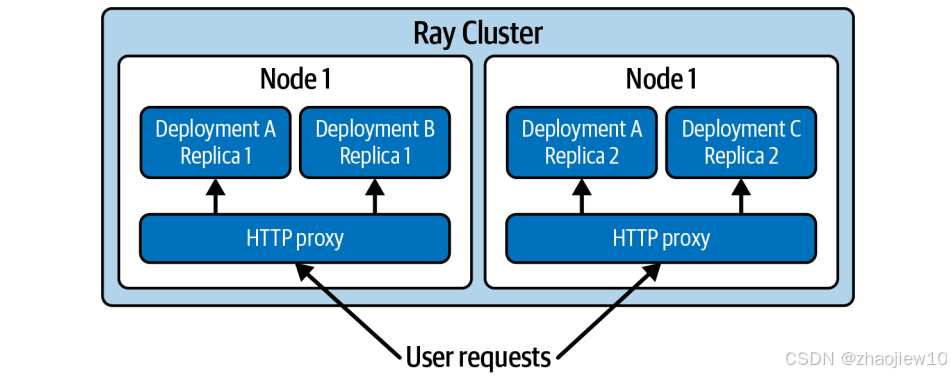
Ray Serve是怎么工作的呢?它最核心的概念是部署。你可以把一个部署想象成一个管理好的Ray Actor集群,它们共同对外提供一个服务接口。每个部署里包含一个或多个Actor,我们叫它们副本。当一个请求进来,HTTP代理会把它分发给这些副本里的一个。背后有个聪明的控制器,负责管理所有这些Actor,确保它们正常运行,如果哪个挂了,控制器将检测到故障,并确保 actor 得到恢复,可以继续提供服务。
我们先来看最简单的例子,把一个模型包装成一个HTTP服务。比如,我们想做一个情感分析模型,判断一句话是积极还是消极。用Ray Serve,只需要定义一个Python类,加上一个@serve.deployment装饰器,告诉Ray Serve这是一个部署。
# app.py
from ray import serve
from transformers import pipeline
@serve.deployment
class SentimentAnalysis:
def __init__(self):
self._classifier = pipeline("sentiment-analysis")
def __call__(self, request) -> str:
input_text = request.query_params["input_text"]
return self._classifier(input_text)[0]["label"]
basic_deployment = SentimentAnalysis.bind()
然后在类里面,__init__方法用来初始化模型,比如加载模型权重,这个过程通常比较耗时,但只会执行一次,非常高效。__call__方法就是处理请求的入口,它接收HTTP请求,调用模型,然后返回结果。最后,用.bind()方法把这个部署定义好。
serve run app:basic_deployment
刚才那个例子处理请求参数有点麻烦,手动写代码解析。Ray Serve还支持和FastAPI集成,FastAPI是现在非常流行的Python Web框架,写起来非常简洁,而且能自动处理输入验证。我们可以把FastAPI的app对象包装成一个部署,然后用@app.deployment和@app.ingress装饰器,这样就能利用FastAPI的路由和参数解析能力,让我们的HTTP API定义更清晰、更健壮。
模型跑起来了,但怎么应对流量高峰?Ray Serve允许我们动态调整资源。比如,可以通过 num_replicas 参数指定一个部署有多少个副本,也就是多少个Actor在同时处理请求。还可以通过 ray_actor_options 参数,比如 num_cpus 或者 num_gpus,来控制每个副本能使用多少资源。
from fastapi import FastAPI
from transformers import pipeline
from ray import serve
app = FastAPI()
@serve.deployment(num_replicas=2, ray_actor_options={"num_cpus": 2})
@serve.ingress(app)
class SentimentAnalysis:
def __init__(self):
self._classifier = pipeline("sentiment-analysis")
@app.get("/")
def classify(self, input_text: str) -> str:
import os
print("from process:", os.getpid())
return self._classifier(input_text)[0]["label"]
scaled_deployment = SentimentAnalysis.bind()
更厉害的是,Ray Serve还支持自动伸缩,可以根据当前的请求数量,自动增加或减少副本的数量,实现真正的弹性伸缩,应对流量波动。
还有一个非常重要的优化技巧:请求批处理。很多模型,特别是GPU模型,非常适合向量化计算,也就是把一批数据放一起处理,效率远高于单个处理。Ray Serve提供了 @serve.batch 装饰器,可以自动把短时间内到达的多个请求合并成一个批量请求,然后一次性调用模型处理。这样做的好处是显而易见的:大大提升了吞吐量,降低了平均延迟,尤其是在GPU上,性能提升非常明显。而且,客户端不需要做任何改动,服务器端自动处理,非常方便。
app = FastAPI()
@serve.deployment
@serve.ingress(app)
class SentimentAnalysis:
def __init__(self):
self._classifier = pipeline("sentiment-analysis")
@serve.batch(max_batch_size=10, batch_wait_timeout_s=0.1)
async def classify_batched(self, batched_inputs):
print("Got batch size:", len(batched_inputs))
results = self._classifier(batched_inputs)
return [result["label"] for result in results]
@app.get("/")
async def classify(self, input_text: str) -> str:
return await self.classify_batched(input_text)
batched_deployment = SentimentAnalysis.bind()
测试部署
import ray
from ray import serve
from app import batched_deployment
handle = serve.run(batched_deployment)
ray.get([handle.classify.remote("sample text") for _ in range(10)])
前面我们讲的都是单个模型的部署,但现实世界中,很多应用需要多个模型协同工作,比如一个推荐系统可能需要用户画像、商品特征、协同过滤等多个模型。Ray Serve的强大之处在于,它能轻松地把这些模型组合起来,构建复杂的推理图。
核心机制是通过 .bind() 方法,把一个部署的引用传递给另一个部署,这样它们就可以互相调用,就像搭积木一样。
@serve.deployment
class DownstreamModel:
def __call__(self, inp: str):
return "Hi from downstream model!"
@serve.deployment
class Driver:
def __init__(self, downstream):
self._d = downstream
async def __call__(self, *args) -> str:
return await self._d.remote()
downstream = DownstreamModel.bind()
driver = Driver.bind(downstream)
部署模式
我们可以用这种方式构建出三种常见的模式:管道、广播和条件分支。
管道模式
想象一下流水线,一个任务做完,下一个任务接着做。比如图像处理,可能先做图像增强,再做目标检测,最后做图像识别。在Ray Serve里,我们可以把每个步骤定义成一个独立的部署,然后在主驱动部署里,依次调用这些步骤,把前一个步骤的输出作为后一个步骤的输入。这样就形成了一个完整的处理流程。
@serve.deployment
class DownstreamModel:
def __init__(self, my_val: str):
self._my_val = my_val
def __call__(self, inp: str):
return inp + "|" + self._my_val
@serve.deployment
class PipelineDriver:
def __init__(self, model1, model2):
self._m1 = model1
self._m2 = model2
async def __call__(self, *args) -> str:
intermediate = self._m1.remote("input")
final = self._m2.remote(intermediate)
return await final
m1 = DownstreamModel.bind("val1")
m2 = DownstreamModel.bind("val2")
pipeline_driver = PipelineDriver.bind(m1, m2)
广播模式
有时候,我们想让同一个输入同时跑多个模型,比如做模型集成,或者从不同角度分析问题。在广播模式下,我们把输入数据分发给多个模型并行处理,然后把结果汇总起来。比如,我们可以用一个情感分析模型和一个文本摘要模型,同时处理一篇文章,然后把两个结果都返回给用户。
@serve.deployment
class DownstreamModel:
def __init__(self, my_val: str):
self._my_val = my_val
def __call__(self):
return self._my_val
@serve.deployment
class BroadcastDriver:
def __init__(self, model1, model2):
self._m1 = model1
self._m2 = model2
async def __call__(self, *args) -> str:
output1, output2 = self._m1.remote(), self._m2.remote()
return [await output1, await output2]
m1 = DownstreamModel.bind("val1")
m2 = DownstreamModel.bind("val2")
broadcast_driver = BroadcastDriver.bind(m1, m2)
条件逻辑
现实世界不是一成不变的,我们需要根据具体情况做出判断。比如,我们可能想根据用户画像,选择不同的推荐模型;或者,如果检测到输入数据有问题,就跳过某些昂贵的计算。Ray Serve允许我们在驱动模型里写入Python逻辑,比如if-else判断,根据条件动态地选择调用哪个下游模型。这使得我们的推理流程更加灵活和智能。
@serve.deployment
class DownstreamModel:
def __init__(self, my_val: str):
self._my_val = my_val
def __call__(self):
return self._my_val
@serve.deployment
class ConditionalDriver:
def __init__(self, model1, model2):
self._m1 = model1
self._m2 = model2
async def __call__(self, *args) -> str:
import random
if random.random() > 0.5:
return await self._m1.remote()
else:
return await self._m2.remote()
m1 = DownstreamModel.bind("val1")
m2 = DownstreamModel.bind("val2")
conditional_driver = ConditionalDriver.bind(m1, m2)
实战案例
理论讲完了,我们来看一个完整的实战案例:构建一个基于Ray Serve的NLP摘要API。这个API的目标是:用户输入一个关键词,比如“物理学”,API会返回该关键词最相关的维基百科文章的简短摘要和关键实体。我们会用到Hugging Face的Transformers库,FastAPI来定义API,还会用到Wikipedia API来抓取文章。
整个流程包括:搜索文章、情感分析、文本摘要、实体识别,最后组合结果。这个案例会综合运用前面讲到的所有Ray Serve功能。
我们需要获取用户搜索的关键词对应的文章内容。我们用Python的wikipedia库来实现这个功能。它会根据关键词搜索维基百科,返回一系列相关文章。我们选择排名第一的文章,并提取它的正文内容。如果没找到文章,就返回None。
from typing import Optional
import wikipedia
def fetch_wikipedia_page(search_term: str) -> Optional[str]:
results = wikipedia.search(search_term)
if len(results) == 0:
return None
return wikipedia.page(results[0]).content
核心的NLP模型,我们用Hugging Face的情感分析模型,还用上了刚才说的批处理,提高效率。
from ray import serve
from transformers import pipeline
from typing import List
@serve.deployment
class SentimentAnalysis:
def __init__(self):
self._classifier = pipeline("sentiment-analysis")
@serve.batch(max_batch_size=10, batch_wait_timeout_s=0.1)
async def is_positive_batched(self, inputs: List[str]) -> List[bool]:
results = self._classifier(inputs, truncation=True)
return [result["label"] == "POSITIVE" for result in results]
async def __call__(self, input_text: str) -> bool:
return await self.is_positive_batched(input_text)
然后是文本摘要,这个模型比较耗资源,所以我们设置了两个副本,num_replicas等于2。
@serve.deployment(num_replicas=2)
class Summarizer:
def __init__(self, max_length: Optional[int] = None):
self._summarizer = pipeline("summarization")
self._max_length = max_length
def __call__(self, input_text: str) -> str:
result = self._summarizer(
input_text, max_length=self._max_length, truncation=True)
return result[0]["summary_text"]
最后是实体识别,我们还会加一些简单的业务逻辑,比如过滤掉置信度低的实体,或者限制返回实体的数量。这三个模型都是独立的部署。
@serve.deployment
class EntityRecognition:
def __init__(self, threshold: float = 0.90, max_entities: int = 10):
self._entity_recognition = pipeline("ner")
self._threshold = threshold
self._max_entities = max_entities
def __call__(self, input_text: str) -> List[str]:
final_results = []
for result in self._entity_recognition(input_text):
if result["score"] > self._threshold:
final_results.append(result["word"])
if len(final_results) == self._max_entities:
break
return final_results
我们还需要一个主控制器来协调它们。我们用FastAPI来定义整个API的接口,包括请求参数和响应格式。在NLPipelineDriver这个部署里,我们编写了完整的控制逻辑:先用fetch_wikipedia_page抓取文章,然后调用情感分析模型,如果文章是负面的就直接返回错误;如果正面,就并行调用摘要和实体识别模型,最后把结果组合起来,返回给用户。
from pydantic import BaseModel
from fastapi import FastAPI
class Response(BaseModel):
success: bool
message: str = ""
summary: str = ""
named_entities: List[str] = []
app = FastAPI()
@serve.deployment
@serve.ingress(app)
class NLPPipelineDriver:
def __init__(self, sentiment_analysis, summarizer, entity_recognition):
self._sentiment_analysis = sentiment_analysis
self._summarizer = summarizer
self._entity_recognition = entity_recognition
@app.get("/", response_model=Response)
async def summarize_article(self, search_term: str) -> Response:
# Fetch the top page content for the search term if found.
page_content = fetch_wikipedia_page(search_term)
if page_content is None:
return Response(success=False, message="No pages found.")
# Conditionally continue based on the sentiment analysis.
is_positive = await self._sentiment_analysis.remote(page_content)
if not is_positive:
return Response(success=False, message="Only positivitiy allowed!")
# Query the summarizer and named entity recognition models in parallel.
summary_result = self._summarizer.remote(page_content)
entities_result = self._entity_recognition.remote(page_content)
return Response(
success=True,
summary=await summary_result,
named_entities=await entities_result
)
把前面定义好的SentimentAnalysis、Summarizer、EntityRecognition这三个部署,以及它们的参数,比如实体识别的阈值,用点bind方法传递给NLPipelineDriver这个驱动部署。这样,整个推理图就连接起来了。
sentiment_analysis = SentimentAnalysis.bind()
summarizer = Summarizer.bind()
entity_recognition = EntityRecognition.bind(threshold=0.95, max_entities=5)
nlp_pipeline_driver = NLPPipelineDriver.bind(
sentiment_analysis, summarizer, entity_recognition)
然后,运行serve run命令,启动服务。
serve run --non-blocking app:nlp_pipeline_driver
现在可以用requests库来测试一下,比如查询physicist,看看能不能得到预期的摘要和实体。
import requests
print(requests.get(
"http://localhost:8000/", params={"search_term": "rayserve"}
).text)
今天我们一起探索了Ray Serve这个强大的工具,它为我们提供了构建高性能、可扩展、低成本的在线推理服务的完整方案。它不仅解决了计算密集、资源消耗、实时性要求高的核心问题,还提供了灵活的模型组合方式,让我们能够轻松构建复杂的、包含多种模型和业务逻辑的智能应用。Ray Serve作为一个开源的、通用的解决方案,是构建下一代AI应用的坚实后盾。

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









