







这是我的第283篇原创文章。
一、引言
当数据集有明显的周期性时,LSTM模型往往效果不如统计学模型比如SARIMA,这篇文章通过组合SARIMA+LSTM,用SARIMA做预测,再将预测的残差输入到LSTM模型去预测残差,将两者的预测结果之和作为最终的预测结果。
一、实现过程
1、准备数据
# 读取数据集
data = pd.read_csv('data.csv')
# 将日期列转换为日期时间类型
data['Month'] = pd.to_datetime(data['Month'])
# 将日期列设置为索引
data.set_index('Month', inplace=True)
data = data['Passengers'].values2、拆分数据集
# 拆分数据集为训练集和测试集
train_size = int(len(data) * 0.8)
train_data = data[:train_size]
test_data = data[train_size:]
print(train_data, len(train_data))训练集115,测试集29。
3、训练过程:
3.1 SARIMA模型训练
输入到SARIMA模型进行训练,得到预测结果(线性预测结果):
# 拟合 SARIMA 模型并提取残差
sarima_model = SARIMAX(train_data, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
sarima_model_fit = sarima_model.fit()
sarima_predictions = sarima_model_fit.predict(start=0, end=train_size-1)
print(sarima_predictions, len(sarima_predictions))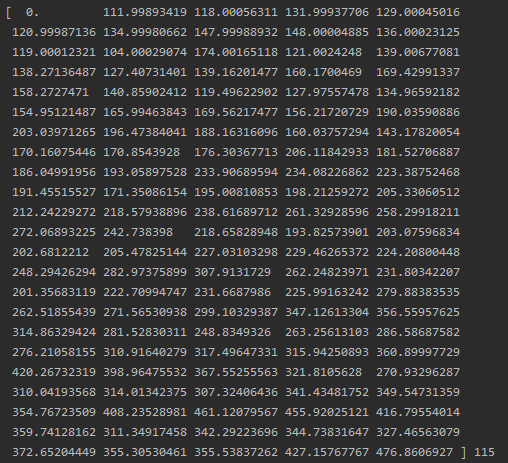
SARIMA模型中差分项(I)会导致第一个差分值无法准确预测,预测的是0。而自回归项(AR)和移动平均项(MA)可以用于预测第一个观测值。因此,如果使用了差分项(I),第一个预测值为0可能是由于差分操作导致的。因此需要做些处理。
3.2 获取残差序列
根据预测结果和实际结果得到残差序列:
# 计算残差序列
residuals = train_data - sarima_predictions
print(residuals)3.3 预测残差(非线性预测值)
将残差序列输入到LSTM模型进行训练,得到残差的预测结果(非线性预测值):
lstm_model = Sequential()
lstm_model.add(LSTM(4, input_shape=(look_back, 1)))
lstm_model.add(Dense(1))
lstm_model.compile(loss='mean_squared_error', optimizer='adam')
lstm_model.fit(train_X, train_Y, epochs=100, batch_size=1, verbose=0)
# LSTM模型预测整个训练集的残差值
lstm_residuals = lstm_model.predict(train_X)
lstm_residuals = scaler.inverse_transform(lstm_residuals)
print(lstm_residuals, len(lstm_residuals))3.4 获取训练集最终的预测结果
SARMIA的预测值和LSTM的预测值的和为训练集最终的预测结果:
train_predictions = sarima_train_predictions[1:] + lstm_train_residuals.flatten()
print("最终训练集的预测值:", train_predictions)
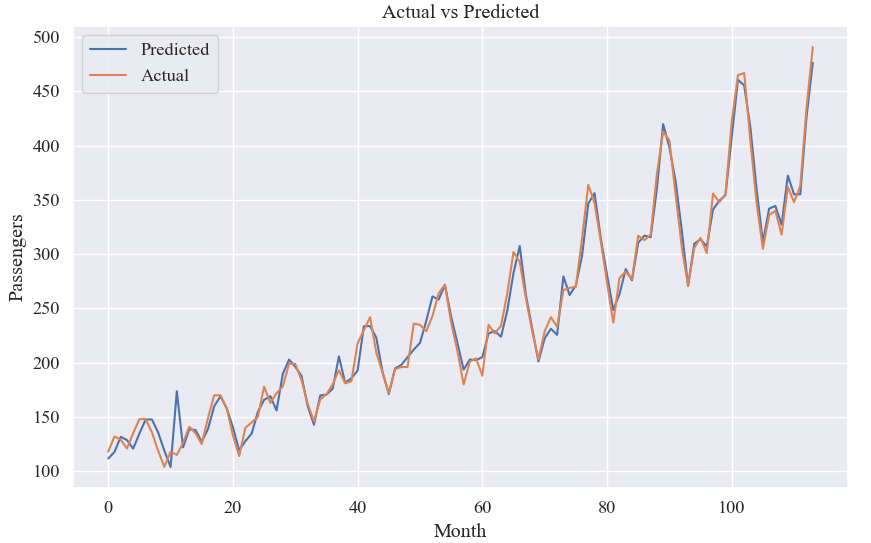
# 绘制训练集预测结果的折线图
plt.figure(figsize=(10, 6))
plt.plot(train_predictions, label='Predicted')
plt.plot(train_data[1:], label='Actual')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.title('Actual vs Predicted')
plt.legend()
plt.show()结果:
4、推理过程:
4.1 SARIMA预测
sarima_test_predictions = sarima_model_fit.predict(start=len(train_data), end=len(train_data) + len(test_data) - 1)
print(sarima_test_predictions, len(sarima_test_predictions))4.2 构造残差数据集
# 计算残差序列
sarima_test_residuals = test_data - sarima_test_predictions
# 归一化残差序列
scaled_test_residuals = scaler.transform(sarima_test_residuals.reshape(-1, 1))
# 构造残差数据集
test_X, test_Y = create_dataset(scaled_test_residuals, look_back)4.3 LSTM模型预测残差
lstm_test_residuals = lstm_model.predict(test_X)
lstm_test_residuals = scaler.inverse_transform(lstm_test_residuals)
print(lstm_test_residuals, len(lstm_test_residuals))4.4 获取测试集最终预测结果
# SARIMA模型预测值与LSTM模型预测残差值相加得到最终测试集的预测值
test_predictions = sarima_test_predictions[1:] + lstm_test_residuals.flatten()
print("最终测试集的预测值:", test_predictions)
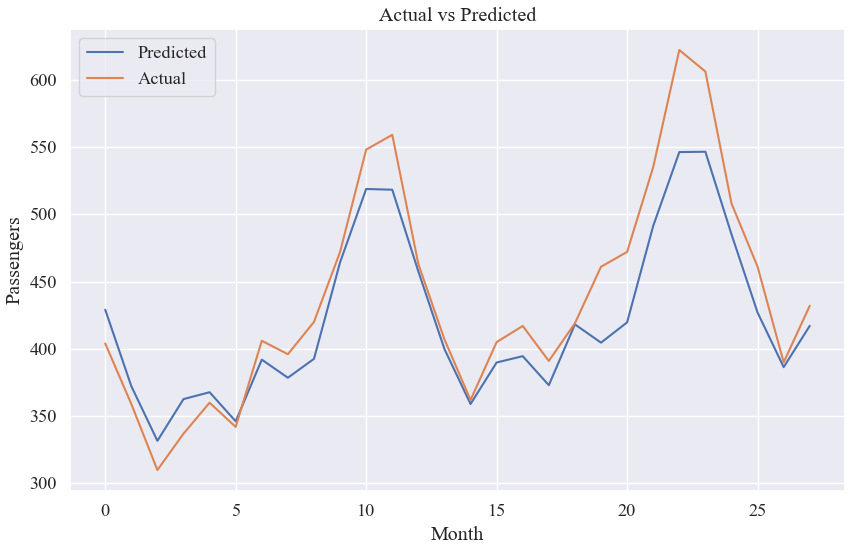
# 绘制测试集预测结果的折线图
plt.figure(figsize=(10, 6))
plt.plot(test_predictions, label='Predicted')
plt.plot(test_data[1:], label='Actual')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.title('Actual vs Predicted')
plt.legend()
plt.show()结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。


















 2147
2147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











