







本文是CVPR2019 的文章,作者给出了一个很强的人体ReID baseline模型,文中包含了许多ReID训练技巧并提出一种BNNeck,在Market1501和DukeMTMC-ReID 两个数据集上达到了目前最好的rank-1 精度和mAP。
论文链接:《Bag of Tricks and A Strong Baseline for Deep Person Re-identification》
代码链接:https://github.com/michuanhaohao/reid-strong-baseline
摘要
本文探讨了一个简单而有效的行人再识别baseline(ReID)。近年来,基于深度神经网络的行人再识别(ReID)技术取得了很大的进展,并取得了良好的性能。然而,许多先进的方法设计复杂的网络结构和连接多分支特征。在文献中,一些有效的训练技巧在几篇论文或源代码中都有简要的介绍。本文将亲自对这些有效的训练技巧进行收集和评价。通过将这些技巧结合起来,该模型在只使用全局特征(global feature)的情况下,在Market1501上实现了94.5%的rank-1和85.9%的mAP。我们的代码和模型在https://github.com/michuanhaohao/reid-strong-baseline。
1 引言
近年来,基于深度神经网络的行人再识别(ReID)技术取得了很大的进展,并取得了良好的性能。然而,许多先进的方法设计复杂的网络结构和连接多分支功能。在文献中,一些有效的训练技巧或改进在几篇论文或源代码中简要出现。本文将亲自收集和评价这些有效的训练技巧。在所有的训练技巧的参与下,ResNet50在Market1501[24]上达到94.5%的rank-1准确率和85.9%的mAP。值得一提的是,它通过模型的全局特性实现了如此惊人的性能。

图1所示。不同baseline在Market1501和dukeMTMC-reid数据集上的性能。我们将我们的强baseline与发表在CVPR2018和ECCV2018上的其他baseline进行比较。
为了进行比较,我们调查了去年在ECCV2018和CVPR2018上发表的文章。如图 1 所示。以前的工作大多是在较差的基线上展开的。在Market1501上,23个baselines中只有两个baselines的准确度超过了90% rakn-1。四个baseline的rank-1精度甚至低于80%。在DukeMTMC-reID上,所有baselines的精度都没有超过80%的rank-1或65%的mAP。我们认为一个强有力的baseling对于促进研究的发展是非常重要的。因此,我们用一些训练技巧修改了标准baseline,以获得一个强baseline。我们强大baseline的代码已经开源。
此外,我们也发现一些作品与其他最好的算法相比是不公平的。具体来说,这些改进主要来自训练技巧,而不是算法本身。但论文中对训练技巧的描述过低,以至于读者忽略了它们。这将使该算法的有效性被夸大。我们建议审稿人在评论学术论文时要考虑这些技巧。
除了上述原因之外,另一个需要考虑的问题是,工业界更喜欢简单而有效的模型,而不是在推理阶段连接许多局部特征(local features)。为了追求更高的精度,学术界的研究人员往往结合多个局部特征,或利用姿态估计或分割模型中的语义信息。这样的方法带来了太多的额外计算。较大的特征也大大降低了检索的速度。因此,我们希望使用一些技巧来提高ReID模型的能力,并且只使用全局特征来实现高性能。本文的研究目的如下:
* 我们调查了许多在顶级会议上发表的作品,发现其中大多数都是在较差的baseline上扩展的。
* 对于学术界,我们希望为研究人员提供一个强大的baseline,以实现更高的准确性的行人ReID。
* 对于社区,我们希望向审阅人员提供一些参考资料,了解哪些技巧会影响ReID模型的性能。我们建议,在比较不同方法的性能时,审阅人员需要考虑这些技巧。
* 对于行业,我们希望提供一些有效的技巧,以获得更好的模型,而不需要太多的额外计算。
幸运的是,在一些论文或开源项目中已经出现了许多有效的训练技巧。我们收集了许多技巧,并在ReID数据集上对每个技巧进行评估。经过大量的实验,我们选择了六个技巧来介绍本文。其中一些是我们设计或修改的。我们将这些技巧添加到一个广泛使用的baseline中,以得到修改后的baseline,该baseline在Market1501上实现了94.5%的rank-1和85.9%的mAP。此外,我们发现不同的作品选择不同的图像size和batch size的数量,作为补充,我们也探讨了它们对模型性能的影响。综上所述,本文的贡献总结如下:
1) 我们为ReID收集了一些有效的训练技巧。其中,我们设计了一种新的neck结构,称为BNNeck。此外,我们还对两个广泛使用的数据集评估了每个技巧的改进。
2) 我们提供了一个强大的ReID baseline,在Market1501上实现了94.5%和85.9%的mAP。值得注意的是,这些结果是用ResNet50 backbone提供的全局特性得到的。据我们所知,这是全局特征亲自获得的最佳性能。
3)作为补充,我们评估了图像size和batch size数量对ReID模型性能的影响。
2 标准Baseline
我们遵循广泛使用的开放源码作为我们的标准baseline。标准baseline的backbone为ResNet50[5]。在训练阶段,pipeline包括以下步骤:
1,我们在ImageNet上初始化带有预训练参数的ResNet50,并将全连接层的维度更改为N, N表示训练数据集中的行人身份数。
2,我们随机抽取每个人的P个身份和K个图像作为训练样本。最后batch-size B = P*K。本文设P = 16, K = 4。
3,我们将每个图像的大小调整为256 *128像素,并将调整后的图像填充10个像素,填充值为0。然后随机裁剪成256 *128的矩形图像。
4,每幅图像水平翻转的概率为0.5。
5,每个图像被解码成32位浮点原始像素值在[0,1]。然后分别减去0.485、0.456、0.406,再除以0.229、0.224、0.225,对RGB通道进行归一化。
6,该模型输出ReID特征为 f 和 ID 预测 logits p。
7,ReID特征 f 用于计算triplet loss[6]。采用ID预测logits p计算交叉熵损失。triplet loss的margin设为0.3。(附:了解triplet loss的话,可以看博客:《triplet loss详解和pytorch实现》)
8,采用Adam方法对模型进行优化。初始学习率设置为0.00035,在第40个epoch和第70个epoch分别降低0.1。总共有120个训练epoches。
3 训练Tricks
本节将亲自介绍一些有效的训练技巧。大多数这样的技巧都可以在不改变模型架构的情况下在标准baseline上扩展。图2 (b)为本节中出现的训练策略和模型架构。

图 2. 标准baseline 和我们修改的baseline pipelines
3.1 warmup 学习率
学习率对ReID模型的性能有很大的影响。标准baseline最初以较大且恒定的学习率进行训练。在[2]中,为了获得更好的性能,使用warmup策略提升网络。在实践中,如图3所示,我们设置10个epoch线性增加学习速率,从3.5*10^-5到 3.5*10^-4。然后,学习速率分别在第40个epoch和第70个epoch,从3.5*10^-5 衰减到3.5*10^-6。在epoch t 处的学习速率lr(t)计算为:
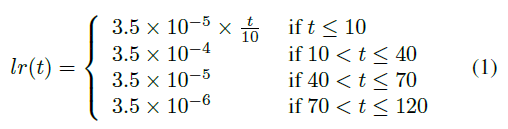

图 3. 学习进度的比较。使用warmup学习策略,学习率在前10个epoch线性增长。
3.2 随机擦除增强
在行人ReID中,人在图像有时被其他物体遮挡。为了解决遮挡问题,提高ReID模型的泛化能力,Zhong等人[27]提出了一种新的数据增强方法——随机擦除增强(REA)。在实践中,在一个mini-batch中的图像 I ,它以![]() 的概率随机擦除、以
的概率随机擦除、以![]() 的概率保持不变。然后,REA在图像 I 中随机选择一个大小为
的概率保持不变。然后,REA在图像 I 中随机选择一个大小为![]() 的矩形区域
的矩形区域![]() ,并用随机值擦除其像素。假设图像 I 和区域
,并用随机值擦除其像素。假设图像 I 和区域 ![]() 的面积分别为
的面积分别为![]() 和
和![]() ,我们将
,我们将![]() 表示为擦除矩形区域的面积比。此外,区域
表示为擦除矩形区域的面积比。此外,区域![]() 的纵横比在 r1 和 r2 之间随机初始化。为了确定一个唯一的区域,REA随机初始化一个点
的纵横比在 r1 和 r2 之间随机初始化。为了确定一个唯一的区域,REA随机初始化一个点![]() 。如果
。如果![]() 并且
并且![]() ,设区域
,设区域![]() 为选定的矩形区域。否则,我们重复上述过程,直到选择合适的
为选定的矩形区域。否则,我们重复上述过程,直到选择合适的 ![]() 。在选定的擦除区域
。在选定的擦除区域 ![]() 中,将
中,将![]() 中的每个像素分别赋给图像 I 的均值。
中的每个像素分别赋给图像 I 的均值。
在本研究中,我们将超参数设为p = 0.5;0.02 < Se < 0.4;r1 = 0.3;r2 = 3.33。一些例子如图4所示。

图4。随机擦除增强的抽样例子。第一行显示了五个原始训练图像。处理后的图像显示在第二行。
3.3 标签平滑
ID embedding (IDE)[25]网络是person ReID的基本baseline。IDE的最后一层是一个全连接层,输出图像的 ID 预测logits。隐藏神经元大小等于行人数N 。给定一个图像,我们定义 y 为ground-truth ID标签, 为类别 i 的ID 行人logits。交叉熵损失计算为:
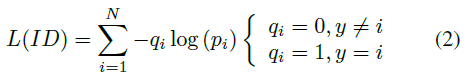
由于分类的类别是由人的ID决定的,本文将这种损失函数称为ID loss。
然而,由于测试集的人id没有出现在训练集中,所以可以将ReID看作是一次性的学习任务,因此防止ReID模型对训练 id 进行过拟合非常重要。在[17]中提出的标签平滑(LS)是一种广泛用于防止分类任务过拟合的方法。它将![]() 结构改为:
结构改为:
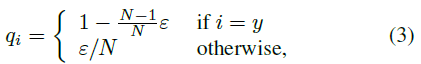
(作者举了个例子,加入原始的label是[0,0,1,0,0,0],平滑参数设置为0.1,则平滑之后的label就会变成[0.02,0.02,0.9,0.02,0.02,0.02],计算损失时由交叉熵换回原始的相对熵。经过标签平滑之后,网络的过拟合程度也会被抑制一点。)
(笔者注:但在其他博客中,标签平滑不是这样定义的:y' = (1 - epsilon)*y + epsilon/N。(即,假设N= 5为五分类,样本真实标签为 y = [0,0,1,0,0],epsilon = 0.1(平滑参数)。 y' 即作者论文中的 qi,为 :y' = (1-0.1)*[0,0,1,0,0] + 0.1/5 = 0.9 * [0,0,1,0,0] + 0.02 = [0,0,0.9,0,0] + 0.02 = [0.02,0.02,0.92,0.02,0.02])。
其中![]() 为一个小常数,鼓励模型不要太相信训练集。在本研究中,
为一个小常数,鼓励模型不要太相信训练集。在本研究中,![]() 设为0.1。当训练集不是很大时,LS可以显著提高模型的性能。
设为0.1。当训练集不是很大时,LS可以显著提高模型的性能。
3.4 最后一步(Last stride)
更高的空间分辨率总是丰富了特征的粒度。在[16]中,Sun等删除了主干网络中的最后一次空间下采样操作,以增加feature map的大小。为了方便起见,我们将骨干网络中的最后一个空间下采样操作表示为最后一步(last stride)。ResNet50的最后一步设置为2。当输入256*128幅图像时,ResNet50的主干输出空间大小为8*4的feature map。如果将最后一步由2步变为1步,我们可以得到一个空间更大的feature map(16*8),这种操作只会增加非常小的计算成本,并且不需要额外的训练参数。然而,更高的空间分辨率带来了显著的改善。
3.5 BNNeck
大多数工作都是将ID loss和triplet loss结合起来训练ReID模型。如图5(a)所示,在标准baseline中,ID loss和triplet loss约束了相同的特征 f,但这两种loss的目标在嵌入空间(embedding space)上不一致。

图 5. 标准neck和我们设计的BNneck之间的比较
如图6(a)所示,ID loss构造多个超平面,将嵌入空间划分为不同的子空间。每个类的特征分布在不同的子空间中。在这种情况下,对于推理阶段的ID loss优化模型,余弦距离比欧氏距离更合适。另一方面,如6(b)所示,triplet loss增强了欧氏空间的类内紧凑性和类间可分性。由于triplet loss不能提供全局最优约束,类间距离有时小于类内距离。一种广泛使用的方法是将ID loss和triplet loss结合起来训练模型。这种方法可以让模型学习到更多有区别的特征。然而,对于嵌入空间中的图像对,ID loss主要是优化余弦距离,而triplet loss主要是欧氏距离。如果我们使用这两个损失同时优化一个特征向量,它们的目标可能是不一致的。在训练过程中,一种可能的现象是一种损失减少了,而另一种损失在振荡甚至增加。

图6。由(a) ID loss、(b)triplet loss、(c) ID +triplet loss、(d) ID +triplet loss+ BNNeck监督的嵌入空间样本分布的二维可视化。不同颜色的点表示不同类的嵌入(embedding)特征。黄色虚线代表假定的分类超平面。
为了克服上述问题,我们设计了如图5(b)所示的BNNeck结构。BNNeck只在特征层之后(和分类器FC层之前)添加了一个batch normalization(BN)层。将BN层之前的特征表示为![]() ,让
,让 ![]() 通过BN层获得归一化特征
通过BN层获得归一化特征![]() 。在训练阶段,分别用
。在训练阶段,分别用 ![]() 和
和![]() 计算triplet loss和 ID loss。normalization平衡了
计算triplet loss和 ID loss。normalization平衡了 ![]() 的各个维度。这些特征在超球面附近呈高斯分布。这种分布使得 ID loss更容易收敛。此外,BNNeck减小了对
的各个维度。这些特征在超球面附近呈高斯分布。这种分布使得 ID loss更容易收敛。此外,BNNeck减小了对![]() 的ID loss约束,ID损失的约束越小,triplet loss越容易同时收敛。第三,normalization保持了属于同一个人的特征的紧凑分布。
的ID loss约束,ID损失的约束越小,triplet loss越容易同时收敛。第三,normalization保持了属于同一个人的特征的紧凑分布。
由于超球面几乎是关于坐标轴原点对称的,BNNeck的另一个技巧是消除分类器FC层的偏差(biases)。它约束分类超平面通过坐标轴原点。我们用[4]中提出的kaiming初始化来初始化FC层。
在推理阶段,我们选择![]() 来完成person ReID任务。余弦距离度量比欧氏距离度量具有更好的性能。实验结果如表1所示,BNNeck可以大幅度提高ReID模型的性能。
来完成person ReID任务。余弦距离度量比欧氏距离度量具有更好的性能。实验结果如表1所示,BNNeck可以大幅度提高ReID模型的性能。

表 1 在Market1501和DukeMTMC-reid数据集上对不同模型的性能进行了评估。Baseline-S代表第2节中介绍的标准baseline。
3.6 Center loss
tripet loss 的组成:
![]()
其中![]() 和
和![]() 为positive pair和negative pair的特征距离。
为positive pair和negative pair的特征距离。![]() 为triplet loss的margin,[z]+ = max(z,0)。在本文中,
为triplet loss的margin,[z]+ = max(z,0)。在本文中,![]() 设为0.3。但是triplet loss只考虑
设为0.3。但是triplet loss只考虑![]() 和
和![]() 的差值,忽略了它们的绝对值。例如,当dp = 0.3;dn = 0.5,triplet为0.1。另一种情况下,dp = 1.3;dn = 1.5,triplet loss也是0.1。triplet loss由随机采样的两个人id确定。在整个训练数据集中,很难保证dp < dn。
的差值,忽略了它们的绝对值。例如,当dp = 0.3;dn = 0.5,triplet为0.1。另一种情况下,dp = 1.3;dn = 1.5,triplet loss也是0.1。triplet loss由随机采样的两个人id确定。在整个训练数据集中,很难保证dp < dn。
center loss[20]同时学习每个类的深度特征中心,并惩罚深度特征与其对应的类中心之间的距离,弥补了triplet loss的缺点。center loss函数表示为:
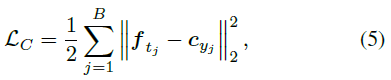
其中 ![]() 是mini-batch中的第 j 个图像的标签。
是mini-batch中的第 j 个图像的标签。![]() 为深度特征的第
为深度特征的第![]() 个类中心。B是batch-size的数量。这个公式有效地描述了类内的变化。将center loss最小化可以增加类内紧凑性。我们的模型总共包括以下三个损失:
个类中心。B是batch-size的数量。这个公式有效地描述了类内的变化。将center loss最小化可以增加类内紧凑性。我们的模型总共包括以下三个损失:
![]()
![]() 是center loss的平衡权重,在我们的实验中
是center loss的平衡权重,在我们的实验中![]() 设置为0.0005。
设置为0.0005。
4 实验结果
在本节中,我们将在Market1501和dukemtc-reid[11]数据集上评估我们的模型。采用Rank-1精度和平均平均精度(mAP)作为评价指标。我们依次在标准基线上添加tricks,并且不更改任何训练设置。消融研究的结果显示,每个trick都能提高性能。为了避免过拟合的误导,我们还展示了跨域(cross-domain)实验的结果。
4.1 每个trick的影响(同域)
第2节中引入的标准baseline在Market1501和DukeMTMC-reID上分别实现了87.7%和79.7%的rank-1精度。标准baseline的性能与其他论文中报道的大多数baseline相似。然后,我们将warmup策略、随机擦除增强、标签平滑、步幅变化、BNNeck和center loss逐一添加到模型训练过程中。我们设计的BNNeck比其他trick更能提高性能,尤其是DukeMTMC-reID。最后,这些技巧使baseline在Market1501上获得了94.5%的Rank-1精度和85.9%的mAP。在DukeMTMC-reID上,其精度达到了86.4%的rank-1和76.4%的mAP。在其他工作中,这些训练tricks将标准baseline的性能提高了10%以上。另外,为了得到这样的改善,我们只需要增加一个BN层,不增加训练时间。
4.2 BNNeck 分析
在本节中,我们使用欧氏距离度量和余弦距离度量来评估两个不同特征(![]() 和
和![]() )的性能。所有模型均经过训练,表2所示无center loss。我们观察到,对于
)的性能。所有模型均经过训练,表2所示无center loss。我们观察到,对于![]() ,余弦距离度量比欧氏距离度量表现得更好。由于ID loss直接限制了BN层之后的特征,
,余弦距离度量比欧氏距离度量表现得更好。由于ID loss直接限制了BN层之后的特征,![]() 可以被多个超平面清晰地分割。余弦距离可以测量两个特征向量之间的夹角,因此余弦距离度量比欧氏距离度量更适用于
可以被多个超平面清晰地分割。余弦距离可以测量两个特征向量之间的夹角,因此余弦距离度量比欧氏距离度量更适用于![]() 。然而,ft接近triplet loss,同时又受到ID loss的约束。两种度量方法在上实现了类似的性能。
。然而,ft接近triplet loss,同时又受到ID loss的约束。两种度量方法在上实现了类似的性能。

表2. BNNeck的消融研究。f (w/o BNNeck)是baseline,没有BNNeck。BNNeck包括两个特征![]() 和
和![]() 。我们分别用欧氏距离和余弦距离来评价它们的性能。
。我们分别用欧氏距离和余弦距离来评价它们的性能。
总体而言,BNNeck显著提高了ReID模型的性能。在推理阶段,我们选择带余弦距离度量的![]() 进行检索。
进行检索。
4.3 每个trick的影响(跨域)
为了进一步探讨其有效性,我们还将跨域实验结果如表3所示。综上所述,warmup策略、标签平滑和BNNeck三种方法显著提高了ReID模型的跨域性能。stride的变化和center loss似乎对表现没有太大的影响。然而,在跨域ReID任务中,REA会对模型造成危害。特别是,当我们的修改baseline在没有REA的情况下进行训练时,它在Market1501和DukeMTMC-reID数据集上的rank-1精度分别达到41.4%和54.3%。它的性能大大超过了标准baseline的性能。通过对训练图像区域的REA mask,可以使模型在训练域中获得更多的知识。它会导致模型在测试领域的性能变差。

表 3. 在跨域数据集上评估不同模型的性能。M->D表示我们在Market1501上训练模型,并在DukeMTMC-reid上进行评估。
4.4 和最好的方法进行比较
我们在表4中比较了强baseline与最先进的方法。所有的方法都被分成不同的类型。Pyramid[22]在两个数据集上实现了惊人的性能。然而,它连接了21个不同规模的局部特征(local feature)。如果只利用全局特征(global feature),则在Market-1501获得92.8%的rank-1精度和82.1%的mAP。我们强大的baseline在Market1501数据集上可以达到94.5%的rank-1精度和85.9%的mAP。BFE[1]的性能与我们的强baseline类似。但是它结合了两个分支的特征。在所有只使用全局特性的方法中,我们的强baseline在Market1501和DukeMTMC - reid上都比AWTL[12]强10%以上。通过k-倒数重排方法提高性能,我们的方法在Market1501和dukemtc - reid上分别达到了94.2%和89.1%的mAP。据我们所知,我们的baseline在仅使用全局特性的情况下实现了最佳性能。

表 4. 和最好的方法的比较。![]() 是在推理阶段的特征数目。PK表示k-倒数重排方法。
是在推理阶段的特征数目。PK表示k-倒数重排方法。
5 补充实验
我们观察到,之前的一些工作是用不同数量的batch-size或图像大小。在本节中,作为补充,我们将探讨它们对模型性能的影
响。
5.1 Batch Size数量的影响
小mini-batch的triplet loss包括B = p*k张图像。P和K分别表示不同的人的数量和每个人不同的图像的数量。一个mini-batch在一个GPU中最多只能包含128张图像,所以我们不能用P = 32,K = 6或P = 32,K = 8来做实验。通过去除center loss,明确了triplet loss与batch size大小的关系。结果如表5所示。然而,目前还没有具体的结论来证明B对性能的影响。我们观察到的一个轻微的趋势是,更大的batch-size有利于模型性能。我们推断,较大的k则有助于挖掘较硬的positive pair,而较大的P有助于挖掘较硬的negative pair。

表 5. 不同batch-size数量的ReID模型的性能
5.2 图像size的影响
我们训练了没有center loss的模型,设P = 16;K = 4。如表6所示,四个模型在两个数据集上实现了类似的性能。在我们看来,图像大小并不是ReID模型性能的一个非常重要的因素。

表 6. 不同图像大小的ReID模型的性能。
6 总结
在本文中,我们收集了一些有效的训练技巧,并为ReID设计了一个强大的baseline。为了证明每种技巧对ReID模型性能的影响,我们在相同域和跨域的ReID任务上做了大量的实验。最后,仅使用全局特征,我们强大的baseline就能在Market1501上达到94.5%的rank-1的精度和85.9%的mAP。我们希望这项工作能够推动ReID在学术界和产业界的研究。
然而,我们工作的目的不是粗略地提高性能。与人脸识别相比,ReID还有很长的路要走。我们认为一些训练技巧可以加速探索,还有很多有效的技巧没有被发现。我们欢迎研究人员与我们分享一些其他有效的技巧。我们将根据这项工作对他们进行评估。在未来,我们将继续设计更多的实验来分析这些trciks的原理。例如,当我们用L2规范化替换BNNeck时,这个网络的性能会变成什么样子?此外,一些先进的方法,如PCB、MGN和AlignedReID等,是否可以在我们强大的基线上扩展?更多的可视化也有助于其他人理解这项工作。















 2882
2882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









