







第三部分:Shell高级(一)
这一章讲解 Shell 脚本编程的进阶内容,主要涉及重定向、文件描述符、管道和过滤器、子 Shell、信号等。
本章会使用到一些底层的编程知识,有C语言和 C++ 编程经验的程序员阅读起来将会更加轻松。
一、Linux Shell重定向(输入输出重定向)精讲
Linux Shell 重定向分为两种,一种输入重定向,一种是输出重定向;从字面上理解,输入输出重定向就是「改变输入与输出的方向」的意思。
那么,什么是输入输出方向呢?标准的输入输出方向又是什么呢?
一般情况下,我们都是从键盘读取用户输入的数据,然后再把数据拿到程序(C语言程序、Shell 脚本程序等)中使用;这就是标准的输入方向,也就是从键盘到程序。
反过来说,程序中也会产生数据,这些数据一般都是直接呈现到显示器上,这就是标准的输出方向,也就是从程序到显示器。
我们可以把观点提炼一下,其实输入输出方向就是数据的流动方向:
- 输入方向就是数据从哪里流向程序。数据默认从键盘流向程序,如果改变了它的方向,数据就从其它地方流入,这就是输入重定向。
- 输出方向就是数据从程序流向哪里。数据默认从程序流向显示器,如果改变了它的方向,数据就流向其它地方,这就是输出重定向。
1、硬件设备和文件描述符
计算机的硬件设备有很多,常见的输入设备有键盘、鼠标、麦克风、手写板等,输出设备有显示器、投影仪、打印机等。不过,在 Linux 中,标准输入设备指的是键盘,标准输出设备指的是显示器。
Linux 中一切皆文件,包括标准输入设备(键盘)和标准输出设备(显示器)在内的所有计算机硬件都是文件。
为了表示和区分已经打开的文件,Linux 会给每个文件分配一个 ID,这个 ID 就是一个整数,被称为文件描述符(File Descriptor)。
| 文件描述符 | 文件名 | 类型 | 硬件 |
|---|---|---|---|
| 0 | stdin | 标准输入文件 | 键盘 |
| 1 | stdout | 标准输出文件 | 显示器 |
| 2 | stderr | 标准错误输出文件 | 显示器 |
Linux 程序在执行任何形式的 I/O 操作时,都是在读取或者写入一个文件描述符。一个文件描述符只是一个和打开的文件相关联的整数,它的背后可能是一个硬盘上的普通文件、FIFO、管道、终端、键盘、显示器,甚至是一个网络连接。
stdin、stdout、stderr 默认都是打开的,在重定向的过程中,0、1、2 这三个文件描述符可以直接使用。
2、Linux Shell 输出重定向
输出重定向是指命令的结果不再输出到显示器上,而是输出到其它地方,一般是文件中。这样做的最大好处就是把命令的结果保存起来,当我们需要的时候可以随时查询。Bash 支持的输出重定向符号如下表所示。
| 类 型 | 符 号 | 作 用 |
|---|---|---|
| 标准输出重定向 | command >file | 以覆盖的方式,把 command 的正确输出结果输出到 file 文件中。 |
| command >>file | 以追加的方式,把 command 的正确输出结果输出到 file 文件中。 | |
| 标准错误输出重定向 | command 2>file | 以覆盖的方式,把 command 的错误信息输出到 file 文件中。 |
| command 2>>file | 以追加的方式,把 command 的错误信息输出到 file 文件中。 | |
| 正确输出和错误信息同时保存 | command >file 2>&1 | 以覆盖的方式,把正确输出和错误信息同时保存到同一个文件(file)中。 |
| command >>file 2>&1 | 以追加的方式,把正确输出和错误信息同时保存到同一个文件(file)中。 | |
| command >file1 2>file2 | 以覆盖的方式,把正确的输出结果输出到 file1 文件中,把错误信息输出到 file2 文件中。 | |
| command >>file1 2>>file2 | 以追加的方式,把正确的输出结果输出到 file1 文件中,把错误信息输出到 file2 文件中。 | |
| command >file 2>file | 【不推荐】这两种写法会导致 file 被打开两次,引起资源竞争,所以 stdout 和 stderr 会互相覆盖,我们将在《三、结合文件描述符谈重定向,彻底理解重定向的本质!》一节只能怪深入剖析。 | |
| command >>file 2>>file |
在输出重定向中,>代表的是覆盖,>>代表的是追加。
(1)注意
输出重定向的完整写法其实是fd>file或者fd>>file,其中 fd 表示文件描述符,如果不写,默认为 1,也就是标准输出文件。
当文件描述符为 1 时,一般都省略不写,如上表所示;当然,如果你愿意,也可以将command >file写作command 1>file,但这样做是多此一举。
当文件描述符为大于 1 的值时,比如 2,就必须写上。
需要重点说明的是,fd和>之间不能有空格,否则 Shell 会解析失败;>和file之间的空格可有可无。为了保持一致,我习惯在>两边都不加空格。
下面的语句是一个反面教材:
echo "c.biancheng.net" 1 >log.txt
注意1和>之间的空格。echo 命令的输出结果是c.biancheng.net,我们的初衷是将输出结果重定向到 log.txt,但是当你打开 log.txt 文件后,发现文件的内容为c.biancheng.net 1,这就是多余的空格导致的解析错误。也就是说,Shell 将该条语句理解成了下面的形式:
echo "c.biancheng.net" 1 1>log.txt
(2)输出重定向举例
【实例1】将 echo 命令的输出结果以追加的方式写入到 demo.txt 文件中。
#!/bin/bash
for str in "C语言中文网" "http://c.biancheng.net/" "成立7年了" "日IP数万"
do
echo $str >>demo.txt #将输入结果以追加的方式重定向到文件
done
运行以上脚本,使用cat demo.txt查看文件内容,显示如下:
C语言中文网
http://c.biancheng.net/
成立7年了
日IP数万
【实例2】将ls -l命令的输出结果重定向到文件中。
[c.biancheng.net]$ ls -l #先预览一下输出结果
总用量 16
drwxr-xr-x. 2 root root 21 7月 1 2016 abc
-rw-r--r--. 1 mozhiyan mozhiyan 399 3月 11 17:12 demo.sh
-rw-rw-r--. 1 mozhiyan mozhiyan 67 3月 22 17:16 demo.txt
-rw-rw-r--. 1 mozhiyan mozhiyan 278 3月 16 17:17 main.c
-rwxr-xr-x. 1 mozhiyan mozhiyan 187 3月 22 17:16 test.sh
[c.biancheng.net]$ ls -l >demo.txt #重定向
[c.biancheng.net]$ cat demo.txt #查看文件内容
总用量 12
drwxr-xr-x. 2 root root 21 7月 1 2016 abc
-rw-r--r--. 1 mozhiyan mozhiyan 399 3月 11 17:12 demo.sh
-rw-rw-r--. 1 mozhiyan mozhiyan 0 3月 22 17:21 demo.txt
-rw-rw-r--. 1 mozhiyan mozhiyan 278 3月 16 17:17 main.c
-rwxr-xr-x. 1 mozhiyan mozhiyan 187 3月 22 17:16 test.sh
(3)错误输出重定向举例
命令正确执行是没有错误信息的,我们必须刻意地让命令执行出错,如下所示:
[c.biancheng.net]$ ls java #先预览一下错误信息
ls: 无法访问java: 没有那个文件或目录
[c.biancheng.net]$ ls java 2>err.log #重定向
[c.biancheng.net]$ cat err.log #查看文件
ls: 无法访问java: 没有那个文件或目录
(4)正确输出和错误信息同时保存
【实例1】把正确结果和错误信息都保存到一个文件中,例如:
[c.biancheng.net]$ ls -l >out.log 2>&1
[c.biancheng.net]$ ls java >>out.log 2>&1
[c.biancheng.net]$ cat out.log
总用量 12
drwxr-xr-x. 2 root root 21 7月 1 2016 abc
-rw-r--r--. 1 mozhiyan mozhiyan 399 3月 11 17:12 demo.sh
-rw-rw-r--. 1 mozhiyan mozhiyan 278 3月 16 17:17 main.c
-rw-rw-r--. 1 mozhiyan mozhiyan 0 3月 22 17:39 out.log
-rwxr-xr-x. 1 mozhiyan mozhiyan 187 3月 22 17:16 test.sh
ls: 无法访问java: 没有那个文件或目录
out.log 的最后一行是错误信息,其它行都是正确的输出结果。
【实例2】上面的实例将正确结果和错误信息都写入同一个文件中,这样会导致视觉上的混乱,不利于以后的检索,所以我建议把正确结果和错误信息分开保存到不同的文件中,也即写成下面的形式:
ls -l >>out.log 2>>err.log
这样一来,正确的输出结果会写入到 out.log,而错误的信息则会写入到 err.log。
(5)/dev/null 文件
如果你既不想把命令的输出结果保存到文件,也不想把命令的输出结果显示到屏幕上,干扰命令的执行,那么可以把命令的所有结果重定向到 /dev/null 文件中。如下所示:
ls -l &>/dev/null
大家可以把 /dev/null 当成 Linux 系统的垃圾箱,任何放入垃圾箱的数据都会被丢弃,不能恢复。
3、Linux Shell 输入重定向
输入重定向就是改变输入的方向,不再使用键盘作为命令输入的来源,而是使用文件作为命令的输入。
| 符号 | 说明 |
|---|---|
| command <file | 将 file 文件中的内容作为 command 的输入。 |
| command <<END | 从标准输入(键盘)中读取数据,直到遇见分界符 END 才停止(分界符可以是任意的字符串,用户自己定义)。 |
| command <file1 >file2 | 将 file1 作为 command 的输入,并将 command 的处理结果输出到 file2。 |
和输出重定向类似,输入重定向的完整写法是fd<file,其中 fd 表示文件描述符,如果不写,默认为 0,也就是标准输入文件。
输入重定向举例
【示例1】统计文档中有多少行文字。
Linux wc 命令可以用来对文本进行统计,包括单词个数、行数、字节数,它的用法如下:
wc [选项] [文件名]
其中,-c选项统计字节数,-w选项统计单词数,-l选项统计行数。
统计 readme.txt 文件中有多少行文本:
[c.biancheng.net]$ cat readme.txt #预览一下文件内容
C语言中文网
http://c.biancheng.net/
成立7年了
日IP数万
[c.biancheng.net]$ wc -l <readme.txt #输入重定向
4
【实例2】逐行读取文件内容。
#!/bin/bash
while read str; do
echo $str
done <readme.txt
运行结果:
C语言中文网
http://c.biancheng.net/
成立7年了
日IP数万
这种写法叫做代码块重定向,也就是把一组命令同时重定向到一个文件,我们将在《五、Shell代码块重定向》一节中详细讲解。
【实例3】统计用户在终端输入的文本的行数。
此处我们使用输入重定向符号<<,这个符号的作用是使用特定的分界符作为命令输入的结束标志,而不使用 Ctrl+D 键。
[c.biancheng.net]$ wc -l <<END
> 123
> 789
> abc
> xyz
> END
4
wc 命令会一直等待用输入,直到遇见分界符 END 才结束读取。<<之后的分界符可以自由定义,只要再碰到相同的分界符,两个分界符之间的内容将作为命令的输入(不包括分界符本身)。
二、Linux中的文件描述符到底是什么?
Linux中一切皆文件,比如 C++ 源文件、视频文件、Shell脚本、可执行文件等,就连键盘、显示器、鼠标等硬件设备也都是文件。
一个 Linux 进程可以打开成百上千个文件,为了表示和区分已经打开的文件,Linux 会给每个文件分配一个编号(一个 ID),这个编号就是一个整数,被称为文件描述符(File Descriptor)。
这只是一个形象的比喻,为了让读者容易理解我才这么说。如果你也仅仅理解到这个层面,那不过是浅尝辄止而已,并没有看到文件描述符的本质。
本篇文章的目的就是拨云见雾,从底层实现的角度来给大家剖析一下文件描述符,看看文件描述如到底是如何表示一个文件的。
不过,阅读本篇文章需要你有C语言编程基础,至少要理解数组、指针和结构体;如果理解内存,那就更好了,看了这篇文章你会醍醐灌顶。
好了,废话不多说,让我们马上进入正题吧。
Linux 文件描述符到底是什么?
一个 Linux 进程启动后,会在内核空间中创建一个 PCB 控制块,PCB 内部有一个文件描述符表(File descriptor table),记录着当前进程所有可用的文件描述符,也即当前进程所有打开的文件。
内核空间是虚拟地址空间的一部分,不想纠缠细节的读者可以这样理解:进程启动后要占用内存,其中 一部分内存分配给了文件描述符表。
除了文件描述符表,系统还需要维护另外两张表:
- 打开文件表(Open file table)
- i-node 表(i-node table)
文件描述符表每个进程都有一个,打开文件表和 i-node 表整个系统只有一个,它们三者之间的关系如下图所示。
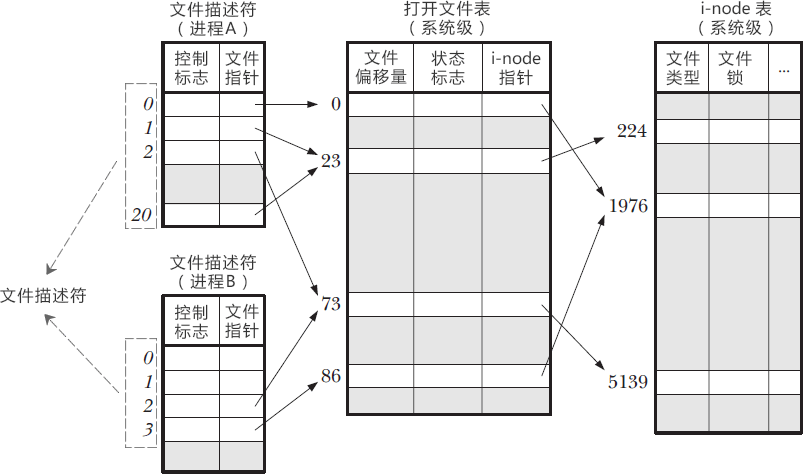
从本质上讲,这三种表都是结构体数组,0、1、2、73、1976 等都是数组下标。表头只是我自己添加的注释,数组本身是没有的。实线箭头表示指针的指向,虚线箭头是我自己添加的注释。
你看,文件描述符只不过是一个数组下标!
通过文件描述符,可以找到文件指针,从而进入打开文件表。该表存储了以下信息:
- 文件偏移量,也就是文件内部指针偏移量。调用 read() 或者 write() 函数时,文件偏移量会自动更新,当然也可以使用 lseek() 直接修改。
- 状态标志,比如只读模式、读写模式、追加模式、覆盖模式等。
- i-node 表指针。
然而,要想真正读写文件,还得通过打开文件表的 i-node 指针进入 i-node 表,该表包含了诸如以下的信息:
- 文件类型,例如常规文件、套接字或 FIFO。
- 文件大小。
- 时间戳,比如创建时间、更新时间。
- 文件锁。
对上图的进一步说明:
- 在进程 A 中,文件描述符 1 和 20 都指向了同一个打开文件表项,标号为 23(指向了打开文件表中下标为 23 的数组元素),这可能是通过调用 dup()、dup2()、fcntl() 或者对同一个文件多次调用了 open() 函数形成的。
- 进程 A 的文件描述符 2 和进程 B 的文件描述符 2 都指向了同一个文件,这可能是在调用 fork() 后出现的(即进程 A、B 是父子进程关系),或者是不同的进程独自去调用 open() 函数打开了同一个文件,此时进程内部的描述符正好分配到与其他进程打开该文件的描述符一样。
- 进程 A 的描述符 0 和进程 B 的描述符 3 分别指向不同的打开文件表项,但这些表项均指向 i-node 表的同一个条目(标号为 1976);换言之,它们指向了同一个文件。发生这种情况是因为每个进程各自对同一个文件发起了 open() 调用。同一个进程两次打开同一个文件,也会发生类似情况。
有了以上对文件描述符的认知,我们很容易理解以下情形:
- 同一个进程的不同文件描述符可以指向同一个文件;
- 不同进程可以拥有相同的文件描述符;
- 不同进程的同一个文件描述符可以指向不同的文件(一般也是这样,除了 0、1、2 这三个特殊的文件);
- 不同进程的不同文件描述符也可以指向同一个文件。
三、结合文件描述符谈重定向,彻底理解重定向的本质!
《一、Linux重定向》一节讲解了输入输出重定向的各种写法,并提到了文件描述符的概念;《二、Linux中的文件描述符到底是什么?》一节从底层剖析了文件描述符的本质,它只不过是一个数组下标。本节我们就将两者结合起来,看看 Shell 是如何借助文件描述符实现重定向的。
Linux 系统这个“傻帽”只有一根筋,每次读写文件的时候,都从文件描述符下手,通过文件描述符找到文件指针,然后进入打开文件表和 i-node 表,这两个表里面才真正保存了与打开文件相关的各种信息。
试想一下,如果我们改变了文件指针的指向,不就改变了文件描述符对应的真实文件吗?比如文件描述符 1 本来对应显示器,但是我们偷偷将文件指针指向了 log.txt 文件,那么文件描述符 1 也就和 log.txt 对应起来了。
文件指针只不过是一个内存地址,修改它是轻而易举的事情。文件指针是文件描述符和真实文件之间最关键的“纽带”,然而这条纽带却非常脆弱,很容易被修改。
Linux 系统提供的函数可以修改文件指针,比如 dup()、dup2();Shell 也能修改文件指针,输入输出重定向就是这么干的。
对,没错,输入输出重定向就是通过修改文件指针实现的!更准确地说,发生重定向时,Linux 会用文件描述符表(一个结构体数组)中的一个元素给另一个元素赋值,或者用一个结构体变量给数组元素赋值,整体上的资源开销相当低。
你看,发生重定向的时候,文件描述符并没有改变,改变的是文件描述符对应的文件指针。对于标准输出,Linux 系统始终向文件描述符 1 中输出内容,而不管它的文件指针指向哪里;只要我们修改了文件指针,就能向任意文件中输出内容。
以下面的语句为例来说明:
echo "c.biancheng.net" 1>log.txt
文件描述符表本质上是一个结构体数组,假设这个结构体的名字叫做 FD。发生重定向时,Linux 系统首先会打开 log.txt 文件,并把各种信息添加到 i-node 表和文件打开表,然后再创建一个 FD 变量(通过这个变量其实就能读写文件了),并用这个变量给下标为 1 的数组元素赋值,覆盖原来的内容,这样就改变了文件指针的指向,完成了重定向。
Shell 对文件描述符的操作
前面提到,>是输出重定向符号,<是输入重定向符号;更准确地说,它们应该叫做文件描述符操作符。> 和 < 通过修改文件描述符改变了文件指针的指向,所以能够实现重定向的功能。
除了 > 和 <,Shell 还是支持<>,它的效果是前面两者的总和。
| 分类 | 用法 | 说明 |
|---|---|---|
| 输出 | n>filename | 以输出的方式打开文件 filename,并绑定到文件描述符 n。n 可以不写,默认为 1,也即标准输出文件。 |
| n>&m | 用文件描述符 m 修改文件描述符 n,或者说用文件描述符 m 的内容覆盖文件描述符 n,结果就是 n 和 m 都代表了同一个文件,因为 n 和 m 的文件指针都指向了同一个文件。 因为使用的是 >,所以 n 和 m 只能用作命令的输出文件。n 可以不写,默认为 1。 | |
| n>&- | 关闭文件描述符 n 及其代表的文件。n 可以不写,默认为 1。 | |
| &>filename | 将正确输出结果和错误信息全部重定向到 filename。 | |
| 输入 | n<filename | 以输入的方式打开文件 filename,并绑定到文件描述符 n。n 可以不写,默认为 0,也即标准输入文件。 |
| n<&m | 类似于 n>&m,但是因为使用的是<,所以 n 和 m 只能用作命令的输入文件。n 可以不写,默认为 0。 | |
| n<&- | 关闭文件描述符 n 及其代表的文件。n 可以不写,默认为 0。 | |
| 输入和输出 | n<>filename | 同时以输入和输出的方式打开文件 filename,并绑定到文件描述符 n,相当于 n>filename 和 n<filename 的总和。。n 可以不写,默认为 0。 |
【实例1】前面的文章中提到了下面这种用法:
command >file 2>&1
它省略了文件描述符 1,所以等价于:
command 1>file 2>&1
这个语句可以分成两步:先执行1>file,让文件描述符 1 指向 file;再执行2>&1,用文件描述符 1 修改文件描述符 2,让 2 和 1 的内容一样。最终 1 和 2 都指向了同一个文件,也就是 file。所以不管是向 1 还是向 2 中输出内容,最终都输出到 file 文件中。
这里需要注意执行顺序,多个操作符在一起会从左往右依次执行。对于上面的语句,就是先执行1>file,再执行2>&1;如果写作下面的形式,那就南辕北辙了:
command 2>&1 1>file
Shell 会先执行2>&1,这样 1 和 2 都指向了标准错误输出文件,也即显示器;接着执行1>file,这样 1 就指向了 file 文件,但是 2 依然指向显示器。最终的结果是,正确的输出结果输出到了 file 文件,错误信息却还是输出到显示器。
【实例2】一个比较奇葩的重定向写法。
echo "C语言中文网" 10>log.txt >&10
先执行10>log.txt,打开 log.txt,并给它分配文件描述符 10;接着执行>&10,用文件描述符 10 来修改文件描述符 1(对于>,省略不写的话默认为 1),让 1 和 10 都指向 log.txt 文件,最终的结果是向 log.txt 文件中输出内容。
这条语句其实等价于echo "C语言中文网" >log.txt,我之所以写得这么绕,是为了让大家理解各种操作符的用法。
文件描述符 10 只用了一次,我们在末尾最好将它关闭,这是一个好习惯。
echo "C语言中文网" 10>log.txt >&10 10>&-
四、使用exec命令操作文件描述符
exec 是Shell内置命令,它有两种用法,一种是执行 Shell 命令,一种是操作文件描述符。本节只讲解后面一种,前面一种请大家自行学习。
使用 exec 命令可以永久性地重定向,后续命令的输入输出方向也被确定了,直到再次遇到 exec 命令才会改变重定向的方向;换句话说,一次重定向,永久有效。
嗯?什么意思?难道说我们以前使用的重定向都是临时的吗?是的!前面使用的重定向都是临时的,它们只对当前的命令有效,对后面的命令无效。
请看下面的例子:
[mozhiyan@localhost ~]$ echo "c.biancheng.net" > log.txt
[mozhiyan@localhost ~]$ echo "C语言中文网"
C语言中文网
[mozhiyan@localhost ~]$ cat log.txt
c.biancheng.net
第一个 echo 命令使用了重定向,将内容输出到 log.txt 文件;第二个 echo 命令没有再次使用重定向,内容就直接输出到显示器上了。很明显,重定向只对第一个 echo 有效,对第二个 echo 无效。
有些脚本文件的输出内容很多,我们不希望直接输出到显示器上,或者我们需要把输出内容备份到文件中,方便以后检索,按照以前的思路,必须在每个命令后面都使用一次重定向,写起来非常麻烦。如果以后想修改重定向的方向,那工作量也是不小的。
exec 命令就是为解决这种困境而生的,它可以让重定向对当前 Shell 进程中的所有命令有效,它的用法为:
exec 文件描述符操作
在《三、结合文件描述符谈重定向,彻底理解重定向的本质!》一节讲到的所有对文件描述符的操作方式 exec 都支持,请看下面的例子:
[mozhiyan@localhost ~]$ echo "重定向未发生"
重定向未发生
[mozhiyan@localhost ~]$ exec >log.txt
[mozhiyan@localhost ~]$ echo "c.biancheng.net"
[mozhiyan@localhost ~]$ echo "C语言中文网"
[mozhiyan@localhost ~]$ exec >&2
[mozhiyan@localhost ~]$ echo "重定向已恢复" 重定向已恢复
[mozhiyan@localhost ~]$ cat log.txt c.biancheng.net C语言中文网
对代码的说明:
exec >log.txt将当前 Shell 进程的所有标准输出重定向到 log.txt 文件,它等价于exec 1>log.txt。- 后面的两个 echo 命令都没有在显示器上输出,而是输出到了 log.txt 文件。
exec >&2用来恢复重定向,让标准输出重新回到显示器,它等价于exec 1>&2。2 是标准错误输出的文件描述符,它也是输出到显示器,并且没有遭到破坏,我们用 2 来覆盖 1,就能修复 1,让 1 重新指向显示器。- 接下来的 echo 命令将结果输出到显示器上,证明
exec >&2奏效了。 - 最后我们用 cat 命令来查看 log.txt 文件的内容,发现就是中间两个 echo 命令的输出。
重定向的恢复
类似echo "1234" >log.txt这样的重定向只是临时的,当前命名执行完毕后会自动恢复到显示器,我们不用担心。但是诸如exec >log.txt这种使用 exec 命令的重定向都是持久的,如果我们想再次回到显示器,就必须手动恢复。
以输出重定向为例,手动恢复的方法有两种:
- /dev/tty 文件代表的就是显示器,将标准输出重定向到 /dev/tty 即可,也就是 exec >/dev/tty。
- 如果还有别的文件描述符指向了显示器,那么也可以别的文件描述符来恢复标号为 1 的文件描述符,例如 exec >&2。注意,如果文件描述符 2 也被重定向了,那么这种方式就无效了。
下面的例子演示了输入重定向的恢复:
#!/bin/bash
exec 6<&0 #先将0号文件描述符保存
exec <nums.txt #输入重定向
sum=0
while read n; do
((sum += n))
done
echo "sum=$sum"
exec 0<&6 6<&- #恢复输入重定向,并关闭文件描述符6
read -p "请输入名字、网址和年龄:" name url age
echo "$name已经$age岁了,它的网址是 $url"
将代码保存到 test.txt,并执行下面的命令:
[mozhiyan@localhost ~]$ cat nums.txt
80
33
129
71
100
222
8
[mozhiyan@localhost ~]$ bash ./test.sh
sum=643
请输入名字、网址和年龄:C语言中文网 http://c.biancheng.net 7
C语言中文网已经7岁了,它的网址是 http://c.biancheng.net
五、Shell代码块重定向(对一组命令进行重定向)
所谓代码块,就是由多条语句组成的一个整体;for、while、until 循环,或者 if...else、case...in 选择结构,或者由{ }包围的命令都可以称为代码块。
请转到
《八、Shell组命令(把多条命令看做一个整体)》一节了解更多关于
{}的细节。
将重定向命令放在代码块的结尾处,就可以对代码块中的所有命令实施重定向。
【实例1】使用 while 循环不断读取 nums.txt 中的数字,计算它们的总和。
#!/bin/bash
sum=0
while read n; do
((sum += n))
done <nums.txt #输入重定向
echo "sum=$sum"
将代码保存到 test.sh 并运行:
[c.biancheng.net]$ cat nums.txt
80
33
129
71
100
222
8
[c.biancheng.net]$ . ./test.sh
sum=643
对上面的代码进行改进,记录 while 的读取过程,并将输出结果重定向到 log.txt 文件:
#!/bin/bash
sum=0
while read n; do
((sum += n))
echo "this number: $n"
done <nums.txt >log.txt #同时使用输入输出重定向
echo "sum=$sum"
将代码保存到 test.sh 并运行:
[c.biancheng.net]$ . ./test.sh
sum=643
[c.biancheng.net]$ cat log.txt
this number: 80
this number: 33
this number: 129
this number: 71
this number: 100
this number: 222
this number: 8
【实例2】对{}包围的代码使用重定向。
#!/bin/bash
{
echo "C语言中文网";
echo "http://c.biancheng.net";
echo "7"
} >log.txt #输出重定向
{
read name;
read url;
read age
} <log.txt #输入重定向
echo "$name已经$age岁了,它的网址是 $url"
将代码保存到 test.sh 并运行:
[c.biancheng.net]$ . ./test.sh
C语言中文网已经7岁了,它的网址是 http://c.biancheng.net
[c.biancheng.net]$ cat log.txt
C语言中文网
http://c.biancheng.net
7
六、Shell Here Document(内嵌文档/立即文档)
Shell 还有一种特殊形式的重定向叫做“Here Document”,目前没有统一的翻译,你可以将它理解为“嵌入文档”“内嵌文档”“立即文档”。
所谓文档,就是命令需要处理的数据或者字符串;所谓嵌入,就是把数据和代码放在一起,而不是分开存放(比如将数据放在一个单独的文件中)。有时候命令需要处理的数据量很小,将它放在一个单独的文件中有点“大动干戈”,不如直接放在代码中来得方便。
Here Document 的基本用法为:
command <<END
document
END
command是 Shell 命令,<<END是开始标志,END是结束标志,document是输入的文档(也就是一行一行的字符串)。
这种写法告诉 Shell 把 document 部分作为命令需要处理的数据,直到遇见终止符END为止(终止符END不会被读取)。
注意,终止符END必须独占一行,并且要定顶格写。
分界符(终止符)可以是任意的字符串,由用户自己定义,比如 END、MARKER 等。分界符可以出现在正常的数据流中,只要它不是顶格写的独立的一行,就不会被作为结束标志。
【实例1】cat 命令一般是从文件中读取内容,并将内容输出到显示器上,借助 Here Document,cat 命令可以从键盘上读取内容。
[mozhiyan@localhost ~]$ cat <<END
> Shell教程
> http://c.biancheng.net/shell/
> 已经进行了三次改版
> END
Shell教程
http://c.biancheng.net/shell/
已经进行了三次改版
<是第二层命令提示符。
正文中也可以出现结束标志END,只要它不是独立的一行,并且不顶格写,就没问题。
[mozhiyan@localhost ~]$ cat <<END > END可以出现在行首 > 出现在行尾的END > 出现在中间的END也是允许的 > END END可以出现在行首 出现在行尾的END 出现在中间的END也是允许的
【实例2】在脚本文件中使用 Here Document,并将 document 中的内容转换为大写。
#!/bin/bash
#在脚本文件中使用立即文档
tr a-z A-Z <<END
one two three
Here Document
END
将代码保存到 test.sh 并运行,结果为:
ONE TWO THREE
HERE DOCUMENT
1、忽略命令替换
默认情况下,正文中出现的变量和命令也会被求值或运行,Shell 会先将它们替换以后再交给 command,请看下面的例子:
[mozhiyan@localhost ~]$ name=C语言中文网
[mozhiyan@localhost ~]$ url=http://c.biancheng.net
[mozhiyan@localhost ~]$ age=7
[mozhiyan@localhost ~]$ cat <<END
> ${name}已经${age}岁了,它的网址是 ${url}
> END
C语言中文网已经7岁了,它的网址是 http://c.biancheng.net
你可以将分界符用单引号或者双引号包围起来使 Shell 替换失效:
[mozhiyan@localhost ~]$ name=C语言中文网
[mozhiyan@localhost ~]$ url=http://c.biancheng.net
[mozhiyan@localhost ~]$ age=7
[mozhiyan@localhost ~]$ cat <<'END' #使用单引号包围
> ${name}已经${age}岁了,它的网址是 ${url}
> END
${name}已经${age}岁了,它的网址是 ${url}
2、忽略制表符
默认情况下,行首的制表符也被当做正文的一部分。
#!/bin/bash
cat <<END
Shell教程
http://c.biancheng.net/shell/
已经进行了三次改版
END
将代码保存到 test.sh 并运行,结果如下:
Shell教程
http://c.biancheng.net/shell/
已经进行了三次改版
这里的制表符仅仅是为了格式对齐,我们并不希望它作为正文的一部分,为了达到这个目的,你可以在<<和END之间增加-,请看下面的代码:
#!/bin/bash
#增加了减号-
cat <<-END
Shell教程
http://c.biancheng.net/shell/
已经进行了三次改版
END
这次的运行结果为:
Shell教程
http://c.biancheng.net/shell/
已经进行了三次改版
3、总结
如果你尝试在脚本嵌入一小块多行数据,使用 Here Document 是很有用的,而嵌入很大的数据块是一个不好的习惯。你应该保持你的逻辑(你的代码)和你的输入(你的数据)分离,最好是在不同的文件中,除非是输入一个很小的数据集。
Here Document 最常用的功能还是向用户显示命令或者脚本的用法信息,例如类似下面的函数:
usage(){
cat <<-END
usage: command [-x] [-v] [-z] [file ...]
A short explanation of the operation goes here.
It might be a few lines long, but shouldn't be excessive.
END
}















 2245
2245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









