









论文:Generative Adversarial Networks
https://arxiv.org/abs/1406.2661
1.GAN的思想
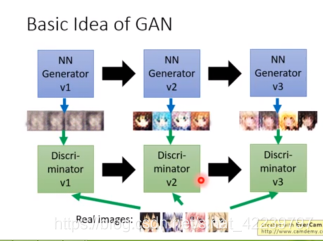
G网络相当于一个学生不断的进行学习,D网络相当于一个老师不断地对学生进行打分和指导,如此一个不断学习不断评估的过程。
如上图所示,
第一次:G学习画动漫人物图像,第一次学习只学到一些简单地轮廓 V1,这个时候D对G的学习进行评估打分,并告诉G动漫人物头像是大眼睛的彩色图片;
第二次:G得到D的指导(他学习的假的图像和真实图像的差距):动漫人物头像是大眼睛的彩色图片
第二次学习时注重了“大眼睛和彩色”这个差距,然后得到第二例的结果V2,这个时候D对G学习的结果进行评估指导,并告诉G这个图像应该是有嘴巴的图片;
第三次:G得到D的指导(他学习的假的图像和真实图像的差距):图像应该是有嘴巴的图片
第二次学习时注重了“图像应该是有嘴巴的图片”这个差距,然后得到第三列的结果V3,这个时候D对G学习的结果进行评估指导,并告诉G这个图像…
…
经过双方的交流使得G学习后的图片和原始图像极为相似。
2.GAN算法
- 首先第一步,固定G更新D。这一步主要是让判别器D有一个很好的判别结果。也就是说,给定一张图片,通过G后,如果是和真实图片极为相似,则给定一个很高的分数,这个分数约等于1(与1极为接近);如果该图片与真实图片不相似,相差很多,则给定一个很小的分数,这个分数约等于0(与0极为接近)。
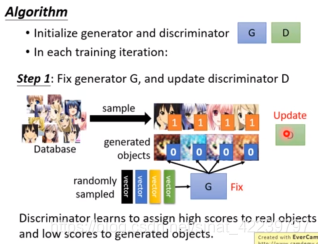
如上图所示:这一步以真实图片和G生成的假的图片作为输入,D网络学习的过程中,不断地告诉自己,真实图片是1,假的图片是0,就是最大化真实图片与G生成的假的图片之间的差距。 - 然后第二步:固定D,更新G。这一步是说,前面的D已经训练的很好了,能够很好的判别图像的真伪了。这个时候训练G,是的G学习的结果作为输入,输入到D时,D能够很好的评估出这个图像是假的,给的分数很低,并反馈给G,这个假的图片和真实图片之间的差距,是的G通过不断地学习,学习后的图像和真实图像极为相似。
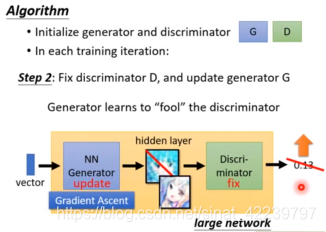
如上图所示,当开始时,G学习后的图像,输入到D中,得到的分数为0.13,这是一个很接近 0 的值,也就是说这个图片太假了,然后D反馈给G真假图片的差距,是的G学习这个差距,经过不断地学习,使得G学习后的图像,输入到D中,得到一个教高的分数(接近1),也就是说,是的G学习到的图片和真实图片极为相似。
损失函数

-
首先学习D的过程。
在真的样本数据集中取m个真实样本(m相当于一个batch size){x1,x2,…,xm}
在随机噪声中随机取m个噪声样本(m相当于一个batch size){z1,z2,…zm}
将随机噪声样本作为输入,输入到G网络中得到G(zi)=x~i
通过不断的学习更新使得V~取最大
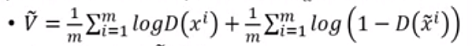
要使得V取最大,也就是两个加和的部分都取最大。
首先前半部分:1/m取最大,则log取最大,也就是D(xi)取最大,这里也就是说真实样本的评价分数越高(接近1)
后半部分:1/m最大,则log取最大,也就是D(x~i)取最小,这里也就是说生成的假样本的评价分数越低(接近于0)
这个式子其实很好的解释了D训练的最后结果,就是让判别真假的能力达到最高。 -
学习G的过程
在随机噪声中随机取m个噪声样本(m相当于一个batch size){z1,z2,…zm}
将随机噪声样本作为输入,输入到G网络中得到G(zi)=x~i;然后G(zi)作为D网络的输入,进过D网络得到输出D(G(zi)),然后通过不断地学习D网络反馈给的真假样本之间的差距,使得最终G生成的图像与真实图像相似,也就是说D给的评价分数接近于1
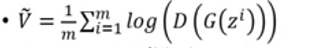
这里可以看出,要使得最后的结果最大,则D(G(zi))最大,也就是G(zi)接近于真实图片。
这篇博客主要参考的是李宏毅的讲解视频。大家不清楚的可以观看,我觉得讲的蛮详细的。

















 1374
1374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









