







cGAN
论文地址:cGAN
cGAN 即条件GAN,条件GAN其实理解起来非常的简单,其实就是对原来的G 和D 多加了一个label 的输入,这样就从无监督,变为了有监督。直接上公式,cGAN中,把公式由1)变为了2):
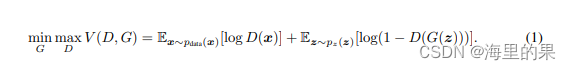
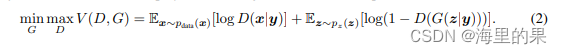
这里扩充,也不仅仅是class label ,可以是多种多样的信息,从这个角度看,后面GAN的许许多多变种都借鉴了cGAN。核心图如下:
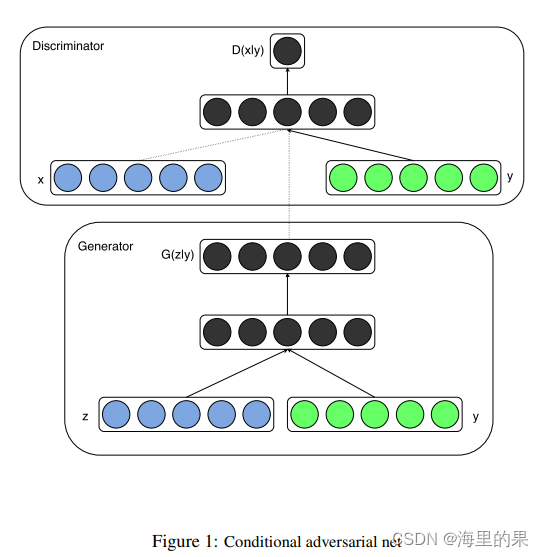
其实没太多可讲的,下面来看下实现。
cGAN实现
在上篇GAN的代码实现的基础上,做一丢丢修改即可。
G 需要加上一个embedding层,embedding层可以理解为没有bia的线性层,权重也是可学习的。 BTW,embedding层一开始输入的都是one-hot的向量,这样就相当于一种查表,如1-10 one-hot后, 每个数字查出来的就是embedding层的每一行,维度为label_embed_dim的向量。
class Generator(nn.Module):
def __init__(self, z_dim) -> None:
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(z_dim+label_embed_dim, 256),
nn.BatchNorm1d(256),
nn.GELU(),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.GELU(),
nn.Linear(512, 28*28),
nn.Sigmoid()
)
self.embedding = nn.Embedding(10, label_embed_dim)
def forward(self, z, labels):
# z (b, z_dim)
label_embedding = self.embedding(labels)
z = torch.cat((z, label_embedding), axis=-1)
out_put = self.mlp(z)
img = out_put.reshape(z.shape[0], *image_size)
return img
D的添加是类似的,也是搞一个self.embedding 出来,过该层得到的label_embedding简单就是concatenate 起来使用。
使用环节,generator, discriminator 做相应修改即可。
lsGAN
文章地址: lsGAN
lsGAN 即Least Squares Generative Adversarial Networks 是2016年的一篇文章。 lsGAN 可以比原始的gan 生成更为清晰的,高分辨率的图片,而且稳定性更强,这里其实仅仅是更改了loss。原始的GAN中,用的是cross entropy,它容易带来梯度消失问题,尽管它能够做出正确的选择(分类),但是还是达不到正确的值(意指生成方向正确,但是清晰度不行)。 原因可以用下图解释,传统GAN在越过决策边界之后,梯度接近消失,很难在对的决策边界内进行学习(x=1是真值),b图确有良好的特性:
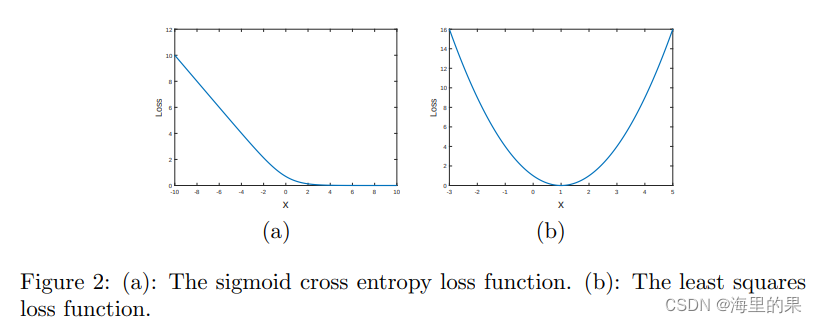
上图可以用一下的代码画出:
logits = torch.linspace(-10, 10, 200)
bce_fn = nn.BCELoss()
msc_fn = nn.MSELoss()
loss1 = []
loss2 = []
for logit in logits:
loss1.append(bce_fn(torch.sigmoid(logit), torch.ones_like(logit)))
loss2.append(msc_fn(logit, torch.ones_like(logit)))
plt.plot(logits, loss1, label="BCELoss")
plt.plot(logits, loss2, label="MCELoss")
plt.xlim(-10,10)
plt.ylim(0,16)
plt.legend()
plt.show()
图片为:

。ls GAN核心公式为:
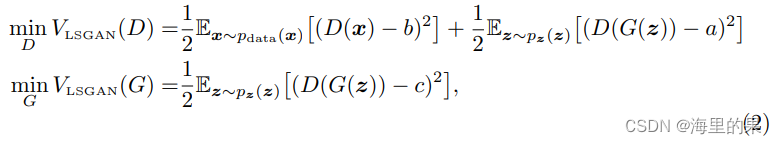
推导
lsGAN的优化公式,可以写成:
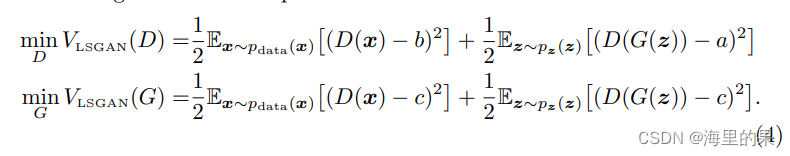
第二行G的多了一项,但是无关紧要,因为它是一个常数,不影响最优值。
仿照GAN,同样地,固定G下,最优的D的参数,服从:
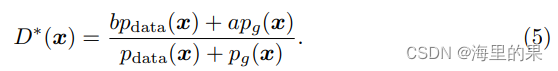
则(4)式中的G可以带入5式化简,得:
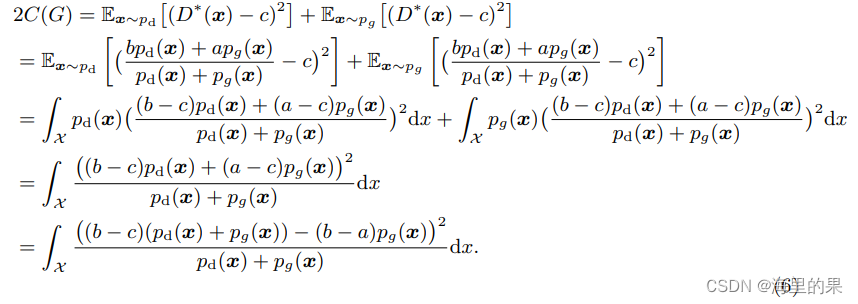
这里面变换不是特别复杂,(6)式子的最后,正好当b-c=1,b-a=2时候,优化的目标正是优化一个皮尔逊平方散度:
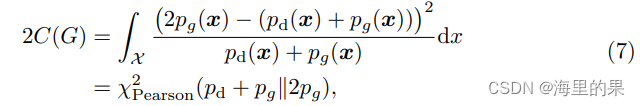
这是说,此时,pg优化的目标还是pd,学习起来完全没有问题。
常用取值,文章中给出了两种:
a=-1, b=1, c=0, 这个是按照 b-c=1,b-a=2 设定出来的。
另外一种是 c=b=-1, a=0设置,这种设置的考虑是,很多情况下,输出的值是0-1之间的数,且希望G生成的尽可能真,也就是D对真正的x,和G生成的x’ , 也就是G(z)打一样的分。实践中,这种收敛效果和上面的非常相似。
lsGAN实现
代码里面的改动,只需要 criterion = nn.MSELoss() 一行即可。
DC GAN
论文链接: DC GAN
DC GAN 是GAN系列里重要的奠基之作,解读的博客简直不要太多。上面的两篇,算是小细节的修改,而DCGAN几乎奠定了GAN的标准架构(当然GAN是开山鼻祖),文章的主要内容有以下几点:
- CNN在有监督学习中效果非常不错,因此想结合CNN来做GAN。
- 因为用了CNN,所以可以可视化一些filter,确实学到一些特定的东西。
- 原来的GAN是比较不稳定的,这里面作者也做了不少尝试和设计,总结了在GAN里面使用CNN的有用的经验。
- 生成器具有向量计算属性,这是说可以通过向量的操作,对应操作一些语义属性,这点也非常有用。
文章说 DC GAN 的结构指导经验是:
模型结构:
• 所有的pooling层使用strided卷积(判别器)和反卷积(生成器)进行替换
• 使用Batch Normalization
• 移除全连接的隐层,让网络可以更深
• 在生成器上,除了输出层使用Tanh外,其它所有层的激活函数都使用ReLU
• 判别器所有层的激活函数都使用LeakyReLU
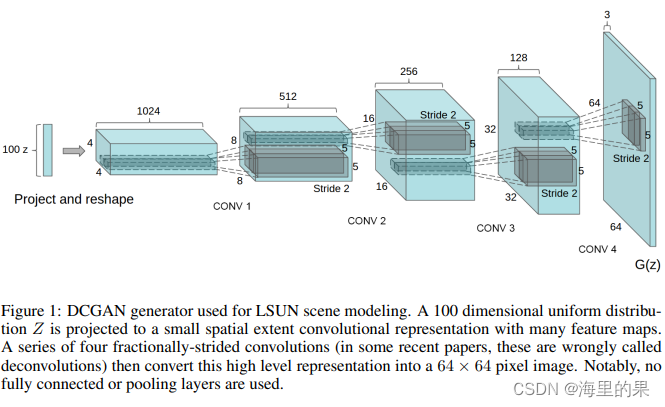
上图的是G的设计,100维度的z,线性变换后,reshape 441024 反卷积得到 88512 -> 1616256 -> 3232128 -> 64643。
D的设计就是卷积,以及提到的一些细节。
一些训练的细节:
- 没有对图片进行预处理, 除了将G的输出变换到[-1,1]。
- 训练使用mini-batch SGD, batch size = 128。
- 所有的参数都采用0均值,标准差为0.02的初始化方式。
- leaky relu。leaky relu 的 α 的取值为0.2。
- optimizers。Adam optimizer, 发现默认的学习率为0.001,太高调整为了0.0002。Adam中的momentum term β1 =0.9太高了,会使得训练过程震荡,不稳定,将其调整为0.5发现可以使训练过程更加稳定。
DC GAN 一些可视化结果
-
连续隐变量下的变化
就是对z进行插值,观察图片的变化,基本上都像bedroom。第六行,窗户逐渐出现,最后一行,TV逐渐消失变成窗户,还是挺有意思的。

-
特征图的可视化
这个就不放图了,就是看到特征图在一些filter作用下,学到了窗户,床等一些结构。 -
忘记画特定物体实验
作者做了一个小实验,从选出150个样本中,手动标注了52个窗口的bounding box,在倒数第二个卷积层,用LR拟合学习是否特征中有窗户,学习时候,bounding box外部的为正值,外部的为负值。这样就得到了一个对一个feature map 判断哪些像素是窗户的LR模型。生成时候,我们就可以选择移除,或者不移除feature map上有窗户的位置的特征,继续往下生成图像,得到下面的对比图,第一排是有窗户的,第二排是处理后生成的图片,网络删去了窗户,或者替换为了其他物体,这说明学到了窗户的特征。(ps 这个有点 patchGAN 的味道了 )

- VECTOR ARITHMETIC ON FACE SAMPLES
这块的意思,可以用vector(“King”)-vector(“Man”)+vector(“Woman”)的结果和向量Queen接近。向量的操作能带来语义上的改变,也能反应到图像上。文章指出,对单个样本进行操作的结果不是很稳定,而如果使用三个样本的平均值,结果就会好很多。

DC GAN 的实现
DC GAN 的实现,改造其实蛮简单的,可以参考这篇博客,GAN优化方法-DCGAN案例
自己参考着实现了一下,但是这边就不贴自己的代码了,文章已经写得太长了,到此为止啦。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









